

What is Azure Cosmos DB?
Cosmos DB started as an internal project – “Project Florence” – at Microsoft in 2010. It is a globally distributed, highly scalable and performant multi-model database service built on Azure. It was built ground up with horizontal scalability and global distribution in view, so you can expect seamless geo-replication to Azure regions by clicking on a map and performance to the order of milliseconds.

Why should you use Cosmos DB?
Cosmos DB is the future of storage. Below are some reasons you may want to use it.
- You use Microsoft stack already and find your favourite RDBMS – SQL Server – too slow
- Your applications need to process large amounts of data at blazing speeds
- Your data is not relational anymore, you want to use JSON document store or Graph DB or one of the many popular APIs Cosmos DB supports
- Big Data applications – This is an evolving use case. Many Azure products such as Azure Stream Analytics, HDInsight and Data Bricks integrate with Cosmos DB, making it an ideal choice for persisting big data.
- You are having to “over-provision” specs to cover peak loads on the database server
- Your business spans multiple continents and you want easy and reliable replication
- You trust Microsoft to do a better job with availability using Azure

Hello Collections!
Collections are to Cosmos DB what tables are to an RDBMS. This analogy is for easy understanding; don’t get hung up on details. There are many differences between collections and tables. A more generic term is Container, especially as Cosmos DB has evolved to support more APIs since the Document DB days.
After you create a Database in your Cosmos DB account, you can create your first collection. Below are a few aspects of a collection you need to be familiar with.
1. Request Units / Throughput: Request Unit (RU) is the currency of Cosmos DB.
1 RU = capacity to read* a single 1 KB item consisting of 10 unique property values
*by self-link or id
A collection need not be a set of documents of the same schema. As Cosmos DB is schema-agnostic, you can very well store different document types in the same collection. That said, you may want to store document types that need the same amount of scalability and storage in the same collection. Cosmos DB is cost effective for high volume transaction systems because RU/s for a collection can be ramped up at peak hours and reduced to a minimum during hours of low trade.
When the provisioned number of RU/s is used up, client requests may experience throttling. Prolonged throttling indicates an insufficient throughput setting.
2. Partition: Each document in a collection has a partition key and an id
Partition key helps to identify the logical partition, and the id field helps to identify a specific document.
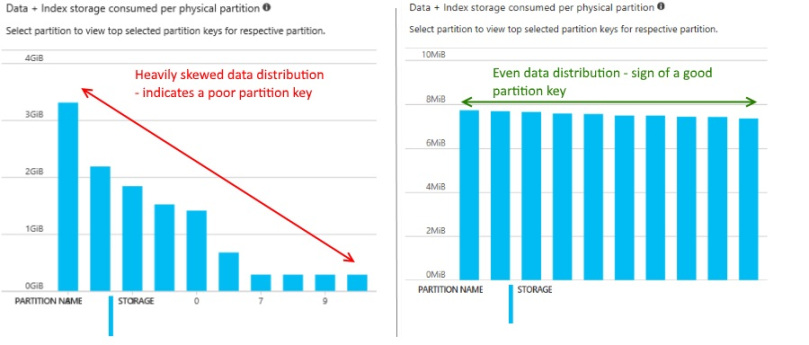
When you create a collection with an initial throughput more than 1000 RU/s, the resulting collection has unlimited scalability. Depending on the initial throughput assigned, Cosmos DB computes the number of physical partitions required to support the provisioned throughput. Logical partitions have a storage limit of 10GB. Due to this, a single logical partition (housing documents having a certain partition key value, such as Product Type = ‘Motorbike helmet’) should not amount to more than 10GB. Theoretically, the number of partitions in a collection can be infinite. Therefore, a good partition key must be a field having a suitable cardinality. With a bad partition key, you are bound to have uneven distributions of data and are likely to hit the 10 GB storage limit per partition.
 3. Time to Live: TTL can be set at a collection or document level. Document level TTL takes precedence, obviously.
3. Time to Live: TTL can be set at a collection or document level. Document level TTL takes precedence, obviously.
Simply put, if TTL for a document is set to 3600 seconds, the document expires when it is older than 3600 seconds. System field _ts (_ts or timestamp is set to Epoch time) indicates the last modified time of a document. Be careful when you set this at collection level. However, this feature helps to implement a sound purge policy.
Global Distribution:
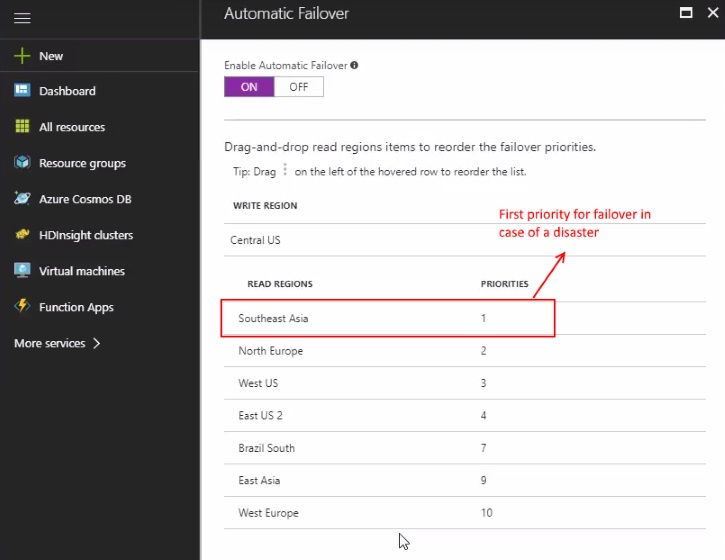
Geo-replication becomes as simple as clicking on a graph with Cosmos DB’s global distribution feature. With more than 50 Azure regions, you could not only set multiple Read regions for global customers, but also specify several failover regions to help with disaster recovery.
There is a lot more to Cosmos DB than can be covered in a single post. With a whole heap of new Azure features that it can easily integrate with, such as SQL Managed Instance, SQL Data warehouse, HDInsight, Data bricks and Data lakes, Cosmos DB is here to stay.
Check out my post about Cosmos DB migration tool if you are migrating data to or from Cosmos DB.
