

Since the day I wrote my first blog. My friends are eagerly waiting for just one topic. The Indexing. I was trying to avoid this one, as I believe there is lot already written about it. But I cant anymore, after all my life is at stake. :p
Indexing is the most important thing to look after in a database. It is very unpredictable but with correct knowledge of your data and the how user is interacting with data can make wonders for you.
Before starting straight upto indexing. It is very important to know a basic about two very important data structure. Heap and B-tree.
Heap : A heap in most simplest way I can define as untidy or unordered way of storing data. It follow just one rule. Either parent will be greater (Known as max heap) or it will be smaller (min heap). Below tree is a max heap. Closely notice that root level is the largest of all. Also every parent is greater than the child.

Let’s say if i want to add a value 6. There is no specific rule of adding a 6. I can place it anywhere by just making sure that parent should be larger. There is two appropriate place for 6.

B-Tree – Now think about the above heap. And apply one simple rule. Larger value will go at right and smaller values will go at left. So your btree will look like something below. (This is a very rough example of a B-Tree of order 2, If require read more about B-Tree on Web. This example is just for a rough idea). Also B-Tree have one rule, All Leaf should lie at same level.

Now, let me ask you one question. You have to search 7. Which one is easier to traverse. A heap or btree. Obviously its a btree for me. As I know I need to search at specific direction only. Well if in case you thought heap and if you can prove it then boy you have my respect.
I hope we have at least basic idea about heap and binary tree. In short time you will come to know why it they are important in term of indexing.
What is indexing?
I won’t go with the text book definition. In my language, Indexing is a structure which can help you identify the exact position of your data. For example if I am searching for customer name by using customer id. Index should know where exactly the data for this customer id lies and it should take minimal amount of time to fetch me the result.
Types of indexing in SQL?
Broadly we have two classifications clustered and non clustered. There are more sub categories like ColumnStore, XML Indexes, Spatial etc. But we will be discussing about the major category as of now.
Cluster index :
Let’s create two table, one with Clustered Index(I will call it CI in further references) and other the usual table without any indexing.

Now insert these both tables with unordered id data. See below snapshot.

Now let us check how data is stored in the table.

Did you noticed. Table having no CI, stored the data exactly in an unordered way. While, Table with CI Sorted it automatically. Does not my above phrase seems similar to the definition of heap. Yes, A table without any indexes is a HEAP. As soon as you apply CI on your table it becomes a BTree.
Now few questions about CI
1. Which column should be the best candidate for clustered index?
Column which is most queried with operator < or > should be the one. For ex. Date, Salary etc.
What! Do not believe it? Because you have been doing it on your id column. And you always search an id with =.
So it either make me wrong or you guys have been doing it wrong all the time.
Let take this discussion forward. And let me prove what my theory is.
Consider my CI is on Salary and I am searching salary>50000. SQL will traverse till 50000 and take all the nodes which are at right.
On the other hand, if my CI was on EmployeeId. There was no use of it. Because ultimately sql will still have to scan your complete row one by one for each record and then check if that EmployeeID satisfies Salary>50000.
I hope it clears a bit. (If you are thinking about Non CI on Salary, Rethink about how it store your data)
Then, why on earth someone will take CI on id. Hmmm… Relax! They are not doing it wrong but there can be multiple reason for it.
First, Ordering your table on basis of ID make it much more comfortable for users.
Second, Having a CI on column having Duplicate Values can be a performance hit in case of OLTP environment, Where there is lot of Insert/Delete is happening. Actually, for very duplicate value in a CI, SQL server will provide a Unique Identifier for each value. To make them unique internally. It will be an extra effort for SQL Server if lot of values are getting inserted and Deleted.
Other most important reason is, there are certain limitation for which you need to have an unique clustered index on a table. Like in case if you are using XML index etc. in such cases, you cannot apply a Unique CI on columns such as salary.
Conclusion : CI will make your table in a proper order. And it totally depend on situation and circumstances where you want to put your clustered index. One which is more searched about or the one which you want to put in order.
2. Can we have more than one CI in one table?
No. You cannot. See the below snapshot where i tried to make another CI on column [Name] and SQL Server throws an exception.

However you can have more than one column under one CI. In such cases. Table will be sorted on the basis of first column if CI and then second and so on( like dictionary). See below Snapshot.

3. Can CI be added to a column having duplicate or null values?
YES. As I explained above in question 1. yes you can. Giving the condition it is not a unique clustered index. Check below snapshots.
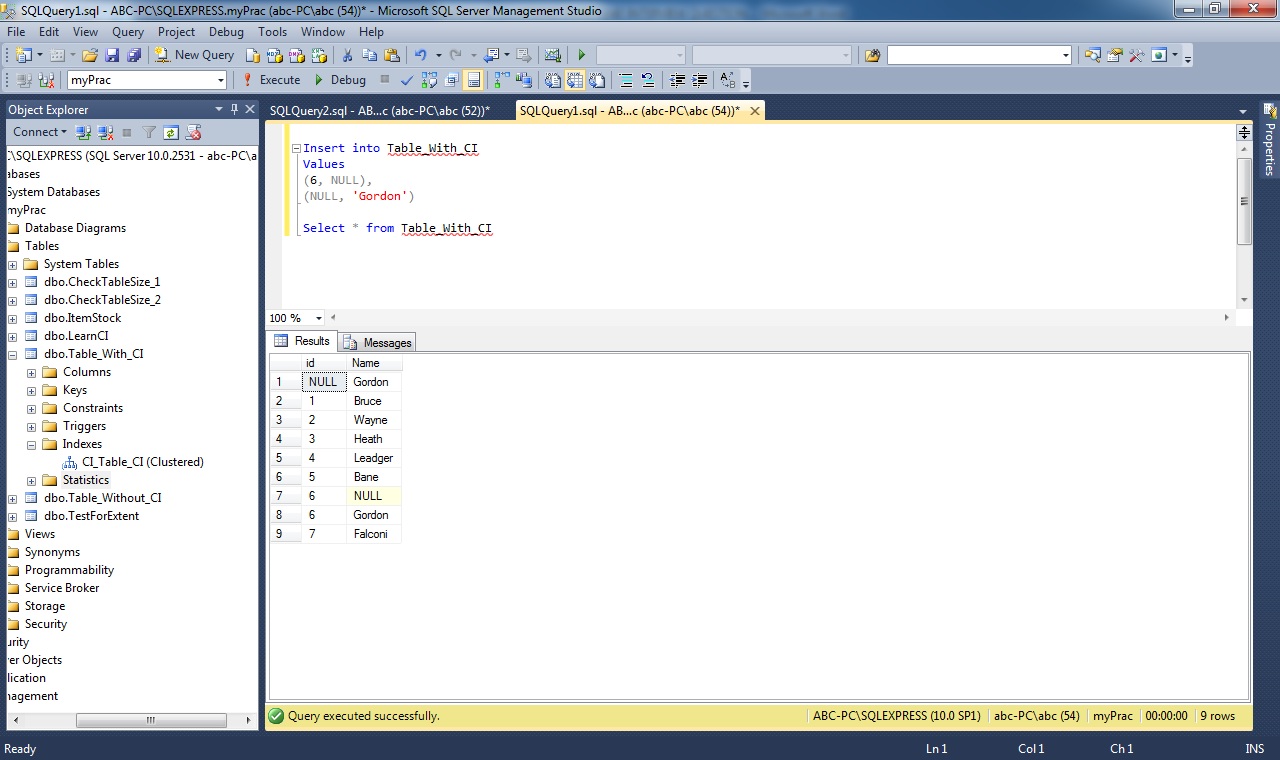
4. If no clustered index is define how table is sorted?
If you have defined a primary key. Then by default it will act as a CI. If there is no pkey as well then it will act as heap. It is impossible to predict the order of a heap.
5. Can we have a Primary Key and CI on separate columns?
Yes. P.key is to enforce a constraint whereas CI is way to enhance the searching mechanism.
6. Does inserting, updating and deleting records affect the performance in case of ci?
I believe in case of update it should not because we are not manipulating the btree structure. (Unless we are updating the same column on which CI is applied.)
But for insert and delete it should take some performance hit. Reason, B-Tree need to keep its leaves at same. So whenever any insert or delete affect this order. SQL server will take some extra effort to make restructure the B-Tree.
*NOTE – This will not happen with each insert or delete.
This is it from my side on CI. Now its your turn to share your views on CI.
We will discuss about NCI in my next post.

![]()
