

Azure Data Explorer (ADX) was announced as generally available on Feb 7th. In short, ADX is a fully managed data analytics service for near real-time analysis on large volumes of data streaming (i.e. log and telemetry data) from such sources as applications, websites, or IoT devices. ADX makes it simple to ingest this data and enables you to perform complex ad-hoc queries on the data in seconds – ADX has speeds of up to 200MB/sec per node (up to 1000 nodes) and queries across a billion records take less than a second. A typical use case is when you are generating terabytes of data from which you need to understand quickly what that data is telling you, as opposed to a traditional database that takes longer to get value out of the data because of the effort to collect the data and place it in the database before you can start to explore it.
It’s a tool for speculative analysis of your data, one that can inform the code you build, optimizing what you query for or helping build new models that can become part of your machine learning platform. It can not only work on numbers but also does full-text search on semi-structured or un-structured data. One of my favorite demo’s was watching a query over 6 trillion log records, counting the number of critical errors by doing a full-text search for the word ‘alert’ in the event text that took just 2.7 seconds. Because of this speed, ADX can be a replacement for search and log analytics engines such as elasticsearch or Splunk. One way I heard it described that I liked was to think of it as an optimized cache on top of a data lake.
Azure Data Explorer integrates with other major services to provide an end-to-end solution that includes data collection, ingestion, storage, indexing, querying, and visualization. It has a pivotal role in the data warehousing flow by executing the EXPLORE step below on terabytes of diverse raw data.
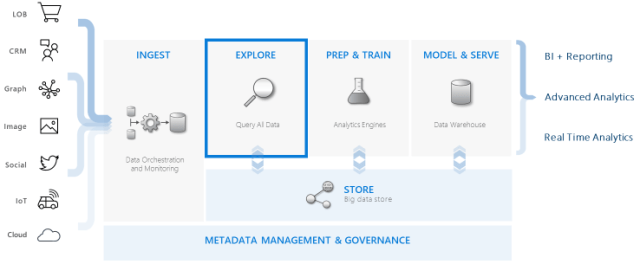
In addition to getting instant feedback from streaming data (via ad-hoc analysis of source data), another way to use ADX is to have it consume large amounts of streaming data, aggregate it, have it land in its internal database, and then have that aggregated data copied to ADLS Gen2 in CSV format via data export or Azure Data Factory. Once there, it can then be transformed and cleaned using another tool such as Databricks (since ADX can’t transform data) and then copied to a traditional data warehouse such as Azure SQL Data Warehouse. This can be much faster than trying to use other tools such as Azure Data Factory to land tons of streaming data into ADLS Gen2 and much less expensive than landing streaming data into Azure SQL Data Warehouse.
The following diagram shows the different aspects of working with Azure Data Explorer:
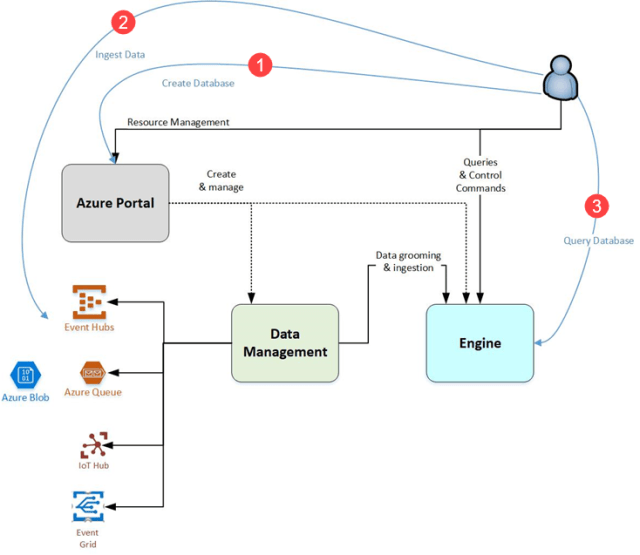
Work in Azure Data Explorer generally follows this pattern:
- Create database: Create a dedicated cluster (currently available VMs are D11_v2, D12_v2, D13_v2, D14_v2, L4, L8, L16) and then create one or more databases in that cluster. See Quickstart: Create an Azure Data Explorer cluster and database. You can scale up the cluster (increasing the size of the node/instance) or scale out the cluster, also known as autoscale (adding more nodes/instances). Note the max number of nodes you can scale out to depends on the VM you have chosen
- Ingest data: Load data from a streaming or a batch source (event hub, iot hub, blob storage or ADLS Gen2 via event grid, Kafka, Logstash plugin, apps via APIs, or Azure Data Factory) into database tables in the database created in step 1 so that you can run queries against it. This is done by creating a target table in ADX and connecting the source such as event hub to this table and mapping the incoming data to the column names in the target table. Supported formats are Avro, CSV, JSON, MULTILINE JSON, PSV, SOH, SCSV, TSV, and TXT. The database is maintenance free so no DBA is needed for it. See Quickstart: Ingest data from Event Hub into Azure Data Explorer
- Query database: Use an Azure web application to run, review, and share queries and results (you can go to the web application directly via dataexplorer.azure.com). It is available in the Azure portal and as a stand-alone application. In addition, you can send queries programmatically (using an SDK to query data from your code) or to a REST API endpoint. The Azure portal-based query builder displays the results in a table where you can filter your data and even apply basic pivot table options. It also includes tools for basic visualization, and you can choose from a range of chart types. ADX uses a different query language called Kusto Query Language (KQL) that is for querying only (you can not update or delete data using KQL) but is a very robust and powerful language that has 400+ operators (filtering, aggregation, grouping, joining, etc as well as full-text indexing and time series analysis) and has built-in machine learning features such as clustering, regression, detecting anomalies or doing forecasting. KQL can also query data from a SQL Database and Cosmos DB. KQL is the same language used in Azure Log Analytics and Application Insights. You can find more information about the query language here. You can also take an online PluralSight course. See Quickstart: Query data in Azure Data Explorer
- You can also visualize your analysis in ADX either through the ‘render’ command in KQL or via three options for connecting to data in Power BI: use the built-in connector, import a query from Azure Data Explorer, or use a SQL query. Finally, there is a Python plugin so you can start using tools like the Anaconda analytics environment and Jupyter Notebooks with saved trained ML models that work with your Azure Data Explorer data sets
All the products and tools that can interact with ADX:
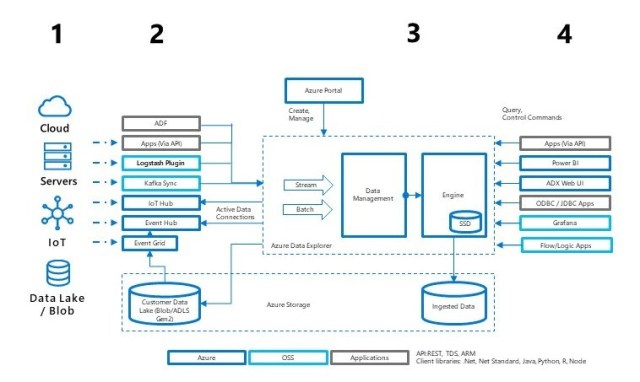
- Capability for many data types, formats, and sources
Structured (numbers), semi-structured (JSON\XML), and free text - Batch or streaming ingestion
Use managed ingestion pipeline or queue a request for pull ingestion - Compute and storage isolation
– Independent scale out / scale in– Persistent data in Azure Blob Storage
– Caching for low-latency on compute
- Multiple options to support data consumption
Use out-of-the box tools and connectors or use APIs/SDKs for custom solution
Kusto stores its ingested data in reliable storage (Azure Blob Storage), away from its actual processing (e.g. Azure Compute) nodes. To speed-up queries on that data, Kusto caches this data (or parts of it) on its processing nodes, SSD or even in RAM. Kusto includes a sophisticated cache mechanism designed to make intelligent decisions as to which data objects to cache. The Kusto cache provides a granular cache policy (set when creating a database in step #1 above) that customers can use to differentiate between two data cache policies: hot data cache and cold data cache. The Kusto cache will attempt to keep all data that falls into the hot data cache in local SSD (or RAM), up to the defined size of the hot data cache. The remaining local SSD space will be used to hold data that is not categorized as hot.
The main implications of setting the hot cache policy are:
- Cost: The cost of reliable storage can be dramatically cheaper than local SSD (for example, in Azure it is currently about 45x times cheaper)
- Performance: Data can be queried faster when it is in local SSD. This is particularly true for range queries, i.e. queries that scan large quantities of data
For more details on why ADX is so fast, check out Azure Data Explorer Technology 101 and Azure Data Explorer whitepaper.
Note that Azure Time Series Insights (TSI) is built on top of Azure Data Explorer. TSI is a SaaS offering as part of the IoT product suite and ADX is a PaaS offering, part of the Azure data platform, powering TSI and other SaaS apps. So, using ADX allows us to get a layer deeper than TSI and build a custom solution. Products like TSI, Azure Monitor Log Analytics, Application insights, and Azure Security Insights are pre-built solutions for a specific purpose, where ADX is used when you are building your own analytics solution or platform and need full control of data sources, data schema and data management, the powerful analytics capabilities of KQL over time series and telemetry data, and a reserved resources cost model.
To sum up in one sentence, Azure Data Explorer is a big data analytics cloud platform optimized for interactive, ad-hoc queries on top of fast flowing data. To get an idea of the cost, check out the cost estimator and note that your cluster can be stopped (you only pay for when it is running).
More info:
Azure Data Explorer Technology 101
Azure Data Explorer whitepaper
What is Azure Data Explorer and Kusto Querying Language (KQL)?
Time series analysis in Azure Data Explorer
How to save $$$ when using Azure Data Explorer
How to use Azure Data Explorer for large-scale data analysis
Video An overview of Azure Data Explorer (ADX)
Video Azure Data Explorer – Query billions of records in seconds!

![]()
