

Introduction
While working in Azure Data Factory, sometimes we need to retrieve metadata information, like the file name, file size, file existence, etc. We can use the Get Metadata activity to retrieve metadata information from the data set and then we can use that metadata information in subsequent activities. This article will give an example of how to do gather metadata from files and use it in the pipeline.
Solution
In this scenario, I will retrieve the metadata information of a file that is stored in a data lake folder. Once we get the metadata, it will be inserted in a SQL table using a stored procedure.
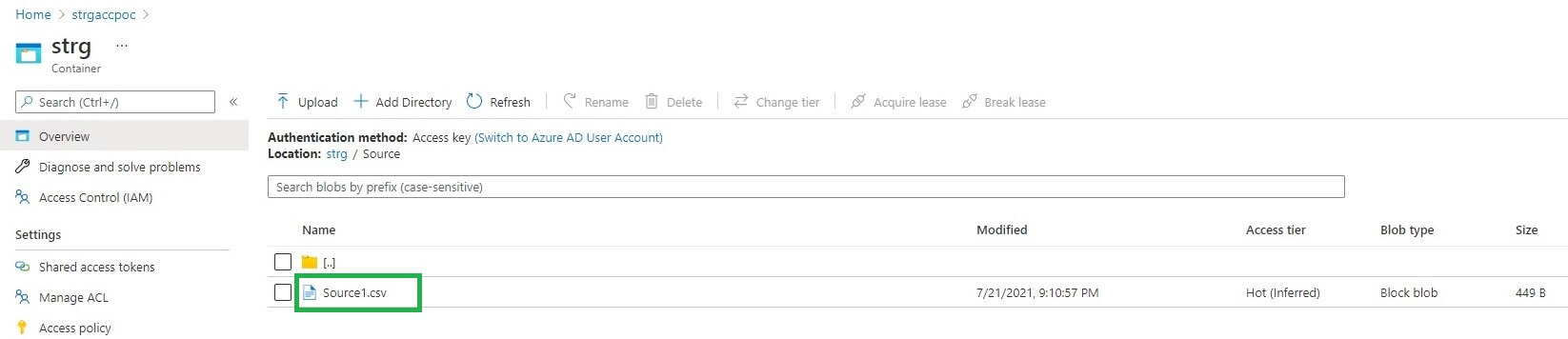
To start, I put a file Source1.csv in the data lake folder. We can see the file below in my container.
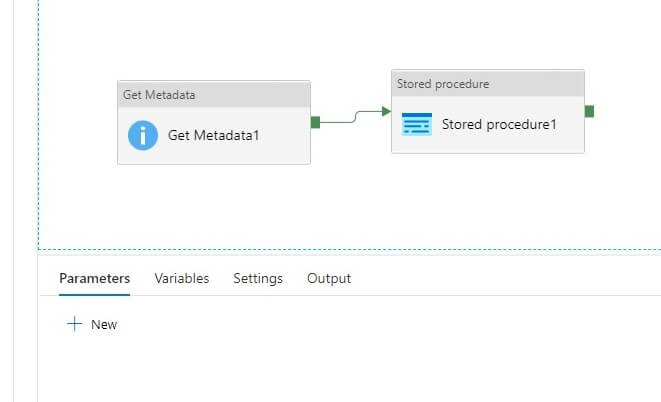
Pipeline design
In the pipeline, I am using a Get Metadata activity and a Stored Procedure activity. These are linked together as you can see below.
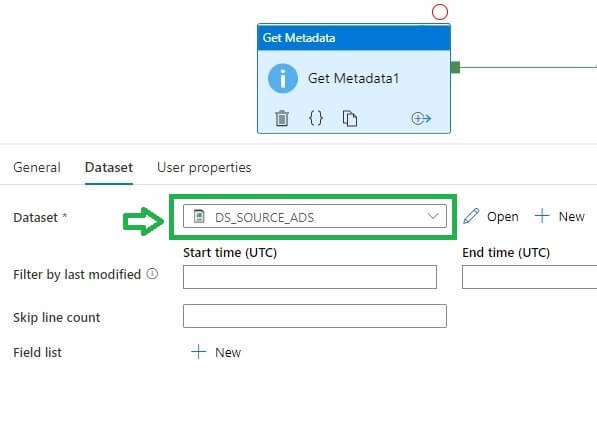
Now I will edit get metadata activity. In the data set option, selected the data lake file dataset.
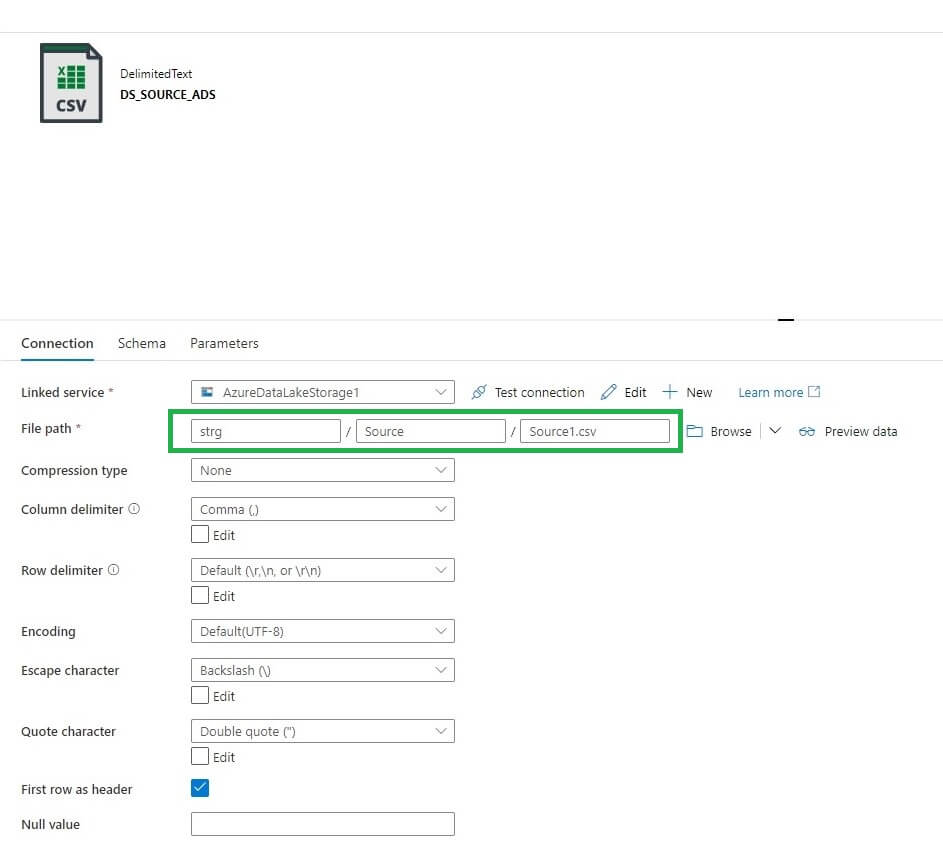
Let’s open the dataset folder. In the file path, I specified the value for the data lake file – strg/Source/Source1.csv. I enter the data as shown below, with the folders separated.
Metadata activity field list
In the drop-down of the field list, we have multiple options available as shown below:
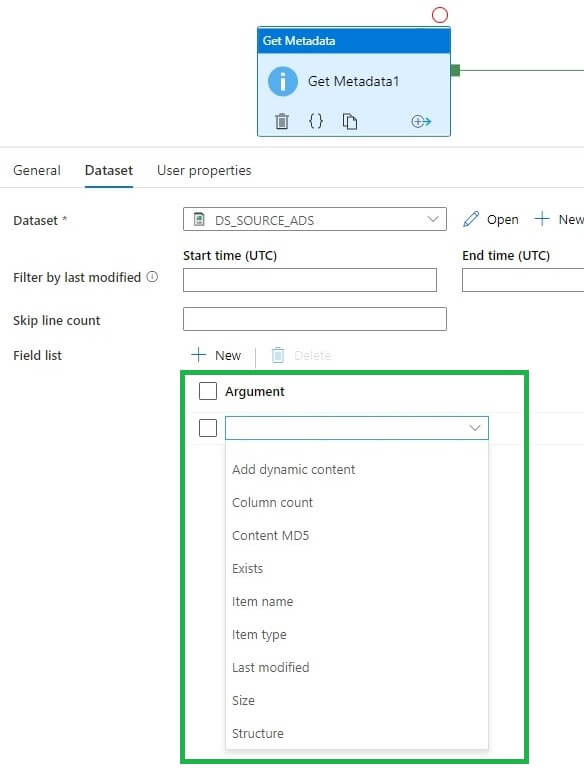
The below table describes the field list and their definition:
| Type | Comments |
| Column Count | A total number of columns in the file or table. |
| Content MD5 | MD5 of the file. |
| Exists | It checks for a file, folder, or a table; if exists then returns true else return false |
| Item Name | Name of a file or a folder |
| Item Type | If the source is a file then returns the File, if it is a folder then returns Folder. |
| Last Modified | Returns DateTime of a last modified file or a folder. |
| Size | Returns size of the file in bytes |
| Structure | Returns list of column names and types for tables and files. |
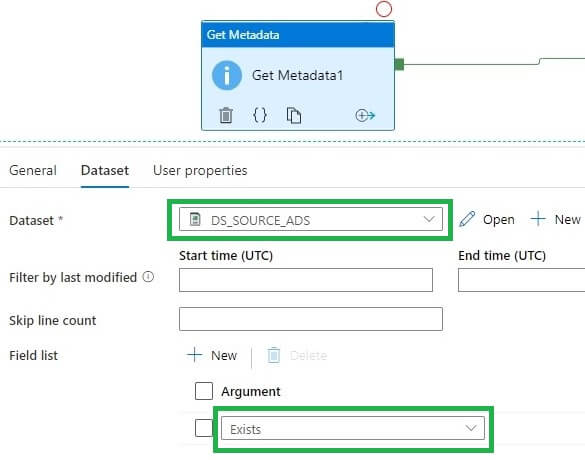
Let’s select the Exists item in the field list:
Storing Metadata
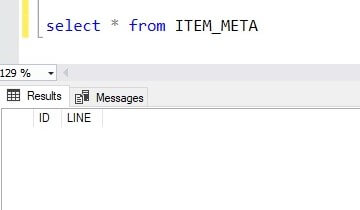
I created a table ITEM_META to insert metadata information. This table will get the data in the LINE column :
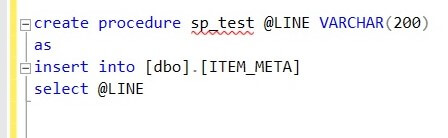
Let’s see the procedure code. As you can see below, I take the metadata value as a parameter and then insert the data into the ITEM_META table:
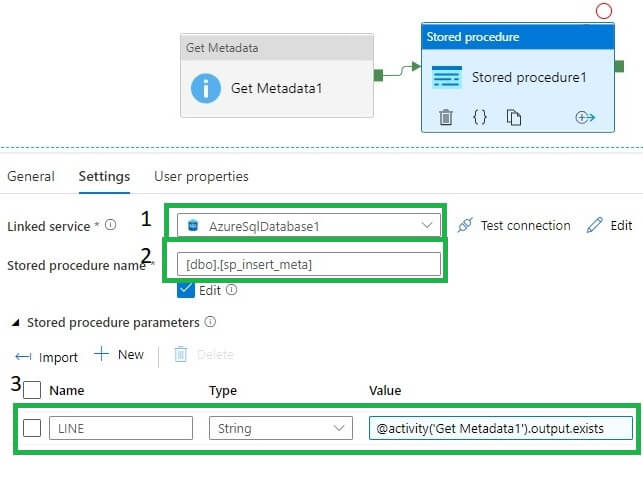
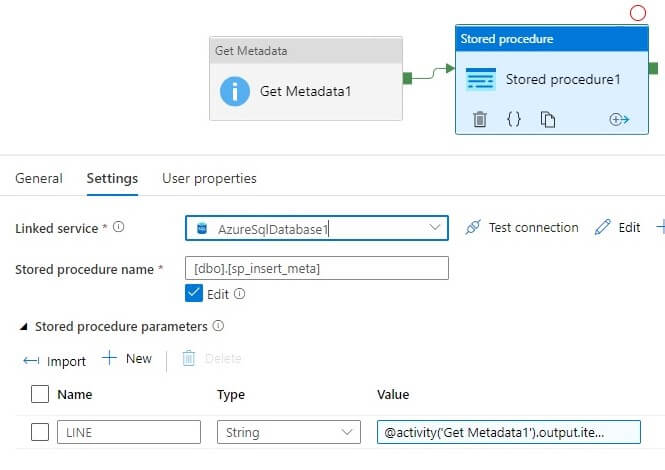
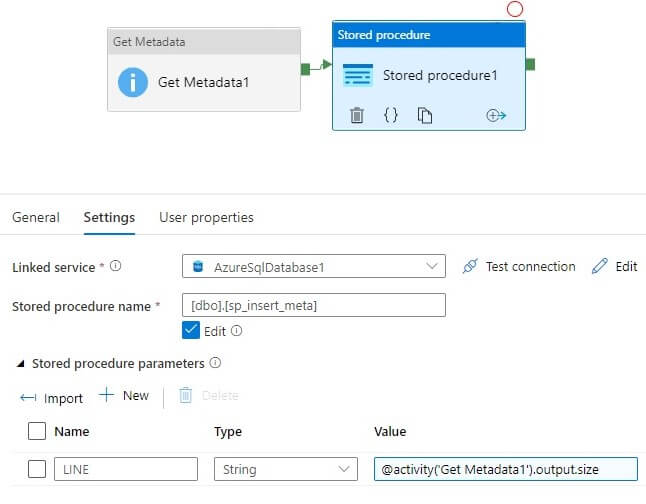
Let’s edit the Stored Procedure activity. We first select the Linked service as an Azure SQL database. This is in the top drop down in the image below.
Next, we pick the stored procedure from the second dropdown. You can see I've picked sp_insert_meta in the image.
Last, we added a new parameter, noted in the third box in the image. Click the "+ New" button to add a parameter. Once you do, you need to configure it. The values for this parameter are shown here:
- Name – LINE
- Type – String
- Value - @activity(‘Get Metadata1’).output.exists
Execute the Pipeline
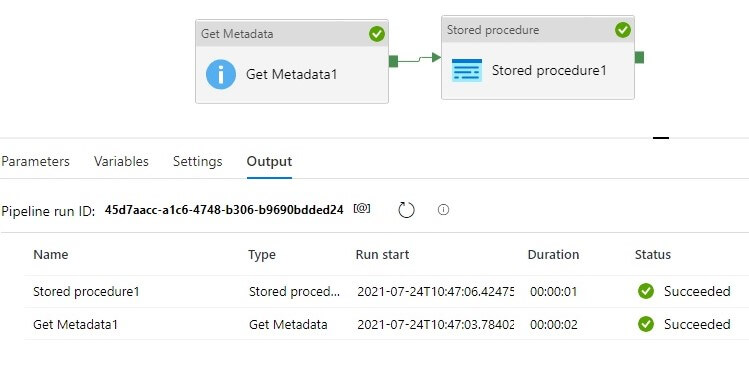
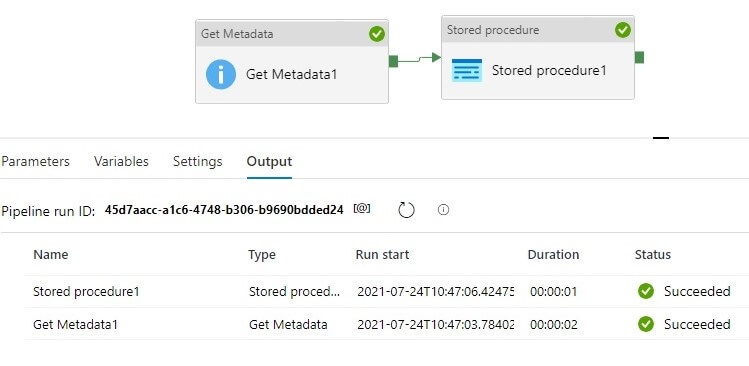
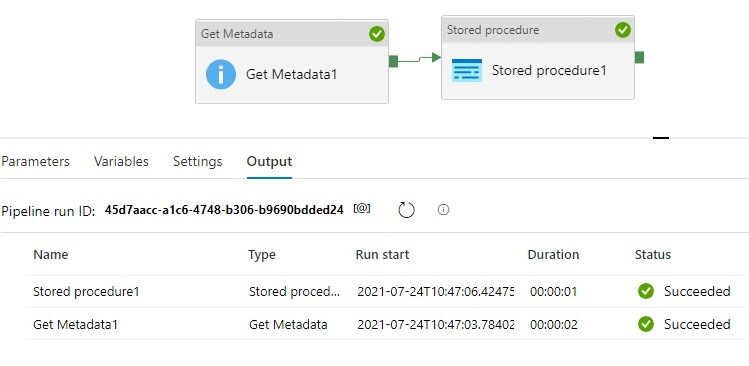
Let’s run the pipeline. The green ticks show that all activities succeeded.
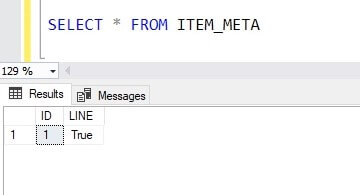
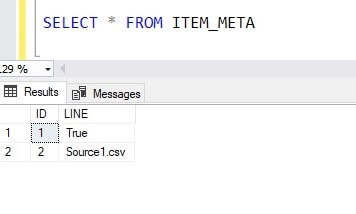
Now I will check the result in the Azure SQL database. As expected I received true value in the table because the file does exist.
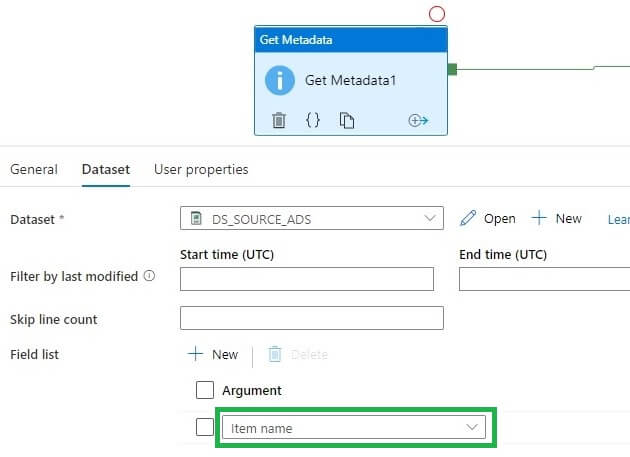
Now I will change the metadata type to the Item name. I do this in the Dataset properties, as shown below.
I need to change the stored procedure parameter value as well. I set this to "@activity(‘Get Metadata1’).output.itemname":
Running the pipeline again, it succeeds.
Let’s see the result from the database. We see the filename, Source1.csv, in the table:
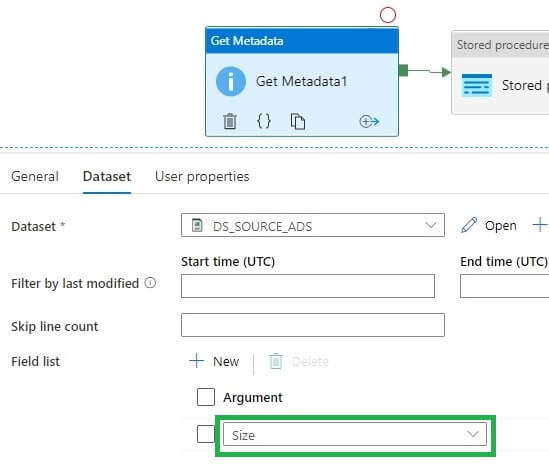
Now I will change the field list value to get the size. This is another piece of metadata from the file. As you can see below, I've adjusted the dropdown.
I need to change the stored procedure parameter value to the size value as well:
Running pipeline again, it succeeds.
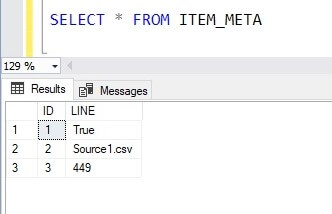
Let’s check the results from the table. We see the file size, 449 bytes.
Conclusion
In this article, we discussed steps to work with metadata activity in Azure Data Factory and received metadata information about the files being processed. We capture the existence, the name, and the size. This is a very useful activity to retrieve metadata information for files and relational tables as a part of your pipeline.