

Once upon a time I was employed by a large financial institution, who in true British fashion shall remain nameless. This is the story of how I used the OVER() clause, along with its constituent PARTITION BY and ORDER BY components, to fix a problem that really should never have existed. Read on…
The Design
The financial institution had a large resource planning system with SQL Server at the backend, which had been developed to use an attribute-based model instead of the traditional row model. So instead of something like:

There were two tables, one to store the types of attribute (Field Types), and one to store the values (Contact Fields).
Field Types (the available fields)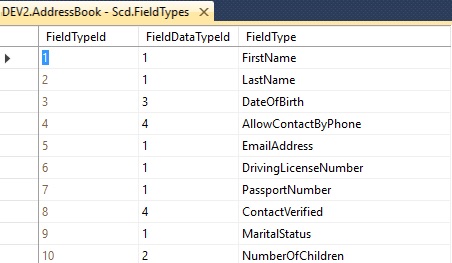
Contact Fields (the field values, linked to their type by FieldTypeId)
The Problem
The idea was that a full history of the data could be kept, e.g. when somebody moves house, the old versions of the address fields would be closed off, and the new versions made active. The other theoretical benefit of this approach was the system became dynamic, as new attributes/field types could easily be added by inserting a new record into the Contact Fields table.
This feature didn’t quite work, and that’s when I was brought on to the project – a data specialist was needed to fix up the data and solve the root cause (yes folks, we’re talking about another project with no database developers on it!). There were a few problems, but the biggest was inconsistent version numbers. Many records had multiple attribute values with the same version number or gaps in the version number, just like in the image below.
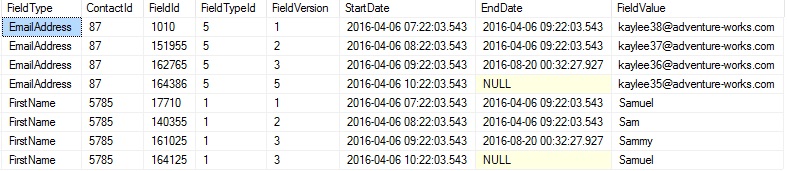
The image shows two sets of data. The first four rows show EmailAddress for ContactId 87. This should have FieldVersions numbered 1 to 4, but instead we have 1 to 3 followed by 5. The second set (the last four rows) shows FirstName for ContactId 5785. Here, we have two rows with FieldVersion number 3.
Why is the version number so important, I hear you ask? Because it was used to identify the current version of the field, by using a MAX(FieldVersion) clause in queries. The bug was first noticed when users started complaining that changes they’d made to the system were not appearing on-screen, or worse, where appearing on occasion. The root cause was identified and repaired – but what to do about the existing, incorrect data? A quick fix was needed!
Using OVER() to Fix the Problem
The OVER() clause can be used to rescue the situation. The solution was to write a query using OVER() to assign a new version number to each bad row, then use this to update the row.
To do this, the code needed to:
- Split each individual field into its own mini-set of data, using ContactId and FieldTypeId
- Order the records by their StartDate to figure out the version number order
- Use ROW_NUMBER() with the OVER() clause to apply the correct version numbers
Sound simple? Let’s take a look!
Identifying the Bad Rows
The system in question had millions of these rows, so I wanted to avoid all the good rows (there were quite a few, believe it or not!). Here is the query used to identify the bad rows, which also returns the correct FieldVersion value.
; WITH BadVersions (ContactId, FieldId, FieldTypeId, FieldVersion, CorrectVersion, StartDate, EndDate) AS ( -- Records that have inconsistent versions, e.g. 1 to 3, 2 to 4 SELECT BAD.ContactId, BAD.FieldId, BAD.FieldTypeId, BAD.FieldVersion, BAD.CorrectVersion, BAD.StartDate, BAD.EndDate FROM ( SELECT CF.ContactId, CF.FieldId, CF.FieldTypeId, CF.FieldVersion, CF.StartDate, CF.EndDate, ROW_NUMBER() OVER (PARTITION BY CF.ContactId, CF.FieldTypeId ORDER BY CF.ContactId, CF.FieldTypeId, CF.StartDate) AS CorrectVersion FROM SCD.ContactFields CF INNER JOIN ( SELECT ContactId, FieldTypeId FROM SCD.ContactFields GROUP BY ContactId, FieldTypeId HAVING COUNT(*) > 1 ) MULTIPLES ON CF.ContactId = MULTIPLES.ContactId AND CF.FieldTypeId = MULTIPLES.FieldTypeId ) BAD WHERE BAD.FieldVersion != BAD.CorrectVersion ) SELECT ContactId, FieldId, FieldTypeId, FieldVersion, CorrectVersion, StartDate, EndDate INTO #BadRecords FROM BadVersions BV;
Quite a bit to take in here! Let’s walk through this in steps.
A CTE (Common Table Expression) is declared. This is a temporary result set which we have named BadVersions. It stores the current version of the attribute in the FieldVersion column, and the new proposed version in the CorrectVersion column.
; WITH BadVersions (ContactId, FieldId, FieldTypeId, FieldVersion, CorrectVersion, StartDate, EndDate)
A SELECT statement is executed to populate the CTE. This uses a nested sub-query, which grabs the attribute values along with the new version number (using ROW_NUMBER() OVER()).
-- Records that have inconsistent versions, e.g. 1 to 3, 2 to 4 SELECT BAD.ContactId, BAD.FieldId, BAD.FieldTypeId, BAD.FieldVersion, BAD.CorrectVersion, BAD.StartDate, BAD.EndDate FROM ( SELECT CF.ContactId, CF.FieldId, CF.FieldTypeId, CF.FieldVersion, CF.StartDate, CF.EndDate, ROW_NUMBER() OVER (PARTITION BY CF.ContactId, CF.FieldTypeId ORDER BY CF.ContactId, CF.FieldTypeId, CF.StartDate) AS CorrectVersion FROM SCD.ContactFields CF
Let’s look at the ROW_NUMBER() OVER statement in more detail:
ROW_NUMBER() OVER (PARTITION BY CF.ContactId, CF.FieldTypeId ORDER BY CF.ContactId, CF.FieldTypeId, CF.StartDate)
ROW_NUMBER() is one of SQL Server’s numerous windowing functions, and will assign a number to the row, based on the criteria given to it by the OVER() clause. The OVER() clause specifies two sub-clauses:
- PARTITION BY
This breaks the data set down into sub-groups. In the example shown here, row numbers are assigned to each group of unique ContactID and FieldTypeID combinations. So ContactID: 87 and FieldTypeID: 5 will constitute a unique partition group, and so will ContactID: 5785 and FieldTypeID: 1.
- ORDER BY
A standard order by clause. The internal data set used by OVER() will be ordered by ContactId, FieldTypeId, and StartDate. We can’t use FieldVersion as this may be incorrect. This ensures the correct order will be returned, as the StartDate values will ensure correct ordering.
Strictly speaking, ContactId and FieldTypeId aren’t needed, but having them here makes it easier for us to look at the data when assessing if it is correct.
This first part of the query will pick up all of the records in SCF.ContactFields. What we want to do now is limit the set to just the bad rows. Firstly, we find the record groups which have more than one version. They are identified by looking for ContactId/FieldTypeId combinations with multiple versions (the GROUP BY sub-query).
INNER JOIN ( SELECT ContactId, FieldTypeId FROM SCD.ContactFields GROUP BY ContactId, FieldTypeId HAVING COUNT(*) > 1 ) MULTIPLES ON CF.ContactId = MULTIPLES.ContactId AND CF.FieldTypeId = MULTIPLES.FieldTypeId
The WHERE clause then checks if the current field version value doesn’t match the proposed new value. If it doesn’t, the row is included in the set.
WHERE BAD.FieldVersion != BAD.CorrectVersion
Finally, we select out the identified rows returned by the CTE into a temporary table.
SELECT ContactId, FieldId, FieldTypeId, FieldVersion, CorrectVersion, StartDate, EndDate INTO #BadRecords FROM BadVersions BV;
Which returns the following for the rows shown in the earlier example:

Perfect – the old FieldVersion values can be seen (5 and 3, respectively), alongside the proposed (and correct) new versions – 4 in both cases. All that’s left to do is write an update statement to set the correct values:
UPDATE F SET F.FieldVersion = BR.CorrectVersion FROM SCD.ContactFields F INNER JOIN #BadRecords BR ON F.FieldId = BR.FieldId;
Now we can inspect the values again. This time, everything is as it should be.
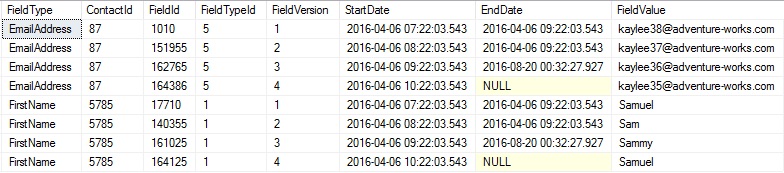
Wonderful – the field versions are now nicely ordered, exactly how they should be. Both versions show 1 to 4. ROW_NUMBER() and OVER() make this kind of thing a cinch!
Summary
We’ve shown how ROW_NUMBER() can be used with the OVER clause to solve a real-world problem. It’s the PARTITION BY sub-clause which is the real solution to this problem. By breaking the recordset into internal groups via partitioning on the ContactID and FieldTypeID columns, we make the solution trivial.
SQL Server’s windowing functions, when used correctly with the OVER() clause, can make seemingly difficult problems easy to solve. Head over to MSDN and read up if you don’t know about them already – they may just save your bacon one day!
