

While researching the solution to a recent performance issue, I came across a curious problem that I could not find referenced in the many excellent resources available online. A combination of views, unions, and data types caused the issue while also providing the solution.
A view that selects data from several archive tables and unions the result sets for return to the client had been in production for several years. Suddenly, this portion of the code began to timeout. After a week of research, including modifying indexes, updating statistics, and the possibility of rewriting the section of code, the culprit as was discovered to be a difference in the data type of the current table and the archive tables.
I have recreated this issue and the resolution as displayed below, using data generated by Red-Gate SQL Data Generator tool. Each step of the process has been broken out to solve the issue and explain what has been changed.
First, two tables need to be created. They are called agents and agents2009. Both tables have the same schema, a single column named accountnumber:
CREATE TABLE [dbo].[agents2009]( [accountnumber] [char](9) NULL ) ON [PRIMARY] CREATE TABLE [dbo].[agents]( [accountnumber] [char](10) NULL ) ON [PRIMARY]
Notice that agents2009 has a length of 9 for accountnumber, and agents has length of 10 for the same column.
A view returning the union two tables is created:
CREATE VIEW [dbo].[vw_agents] AS SELECT accountnumber FROM agents2009 UNION ALL SELECT accountnumber FROM agents
Using Red-Gate SQL Data Generator, a million rows are inserted into each table using an account number length of 9. The script below can be used to generate random account numbers of 3 characters followed by 6 digits also.
---- modified script from Pinal Dave's site www.sqlauthority.com ---- Create the variables for the random number generation DECLARE @Upper INT; DECLARE @Lower INT; SET @Lower = 65 ---- The lowest random number capital A SET @Upper = 90 ---- The highest random number capital Z SELECT CHAR(ROUND(((@Upper - @Lower -1) * RAND() + @Lower), 0)) +CHAR(ROUND(((@Upper - @Lower -1) * RAND() + @Lower), 0)) +CHAR(ROUND(((@Upper - @Lower -1) * RAND() + @Lower), 0)) +CAST(ABS(CHECKSUM(NEWID())) % 900000 + 100000 AS CHAR(6))
After the data is inserted into the table, execute the following t-sql code and view the execution plan.
SELECT accountnumber FROM vw_agents WHERE accountnumber = 'QOT039365' OPTION(maxdop 1)
The literal value in the select statement above should be replaced with a value from your tables. I've included the maxdop hint to simplify the query plan output; the results are the same without the option.
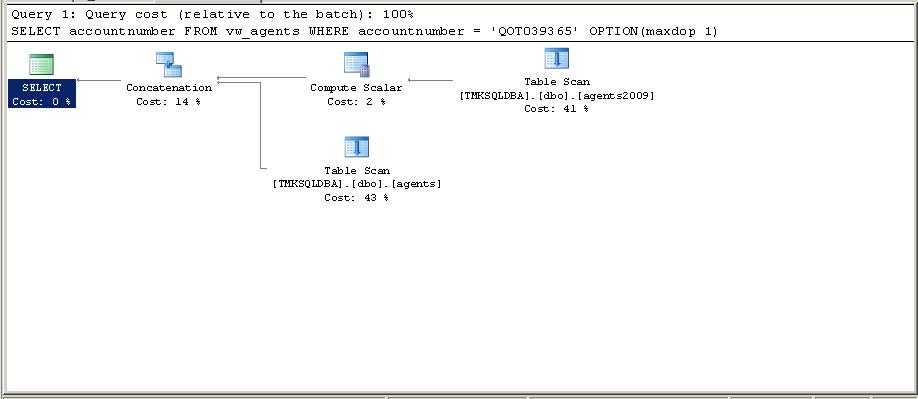
Each of the tables is read using a table scan. This is expected as neither table has an index. A compute scalar is needed to convert the char(9) to a char(10) prior to the union. Data types that can be implicitly converted can be used in views but may require some type of conversion prior to the union.
Now an index is created on each table:
/****** Object: Index [IX_agents2009] ******/CREATE NONCLUSTERED INDEX [IX_agents2009] ON [dbo].[agents2009] ( [accountnumber] ASC ) ON [PRIMARY] /****** Object: Index [IX_agents] ******/CREATE NONCLUSTERED INDEX [IX_agents] ON [dbo].[agents] ( [accountnumber] ASC ) ON [PRIMARY]
The statement above is executed again.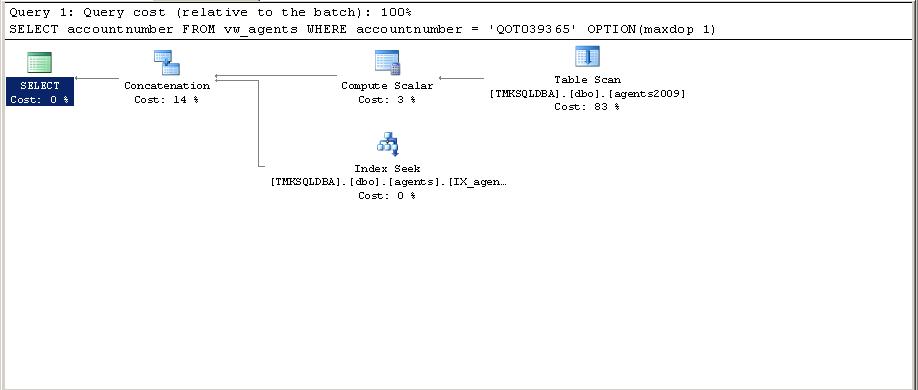
This time an Index Seek is performed on the agents table but a table scan is still being used on agents2009. This behavior is caused because the accountnumber column is a different length between the two tables.
This same statement executed outside of the view uses an Index Seek on both tables.
Now, alter agents2009 accountnumber column to char(10) to match the agents table. Altering the table requires dropping and recreating the index since it references the column.
DROP INDEX dbo.agents2009.IX_agents2009 go ALTER TABLE dbo.agents2009 ALTER COLUMN accountnumber CHAR(10) GO CREATE NONCLUSTERED INDEX [IX_agents2009] ON [dbo].[agents2009] ( [accountnumber] ASC ) ON [PRIMARY]
Execute the original select one more time.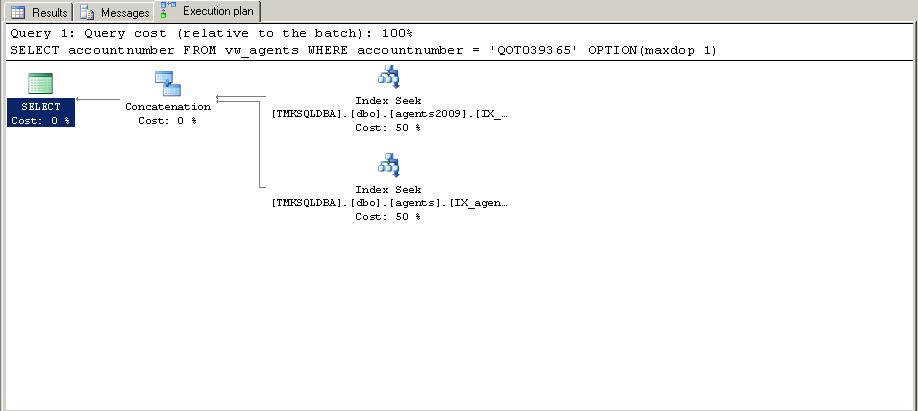
An Index Seek operation is used on both tables and the compute scalar has been removed since all columns are of the same type and length. The same behavior occurred in SQL Server 2000 through SQL Server 2008.
Although SQL can use columns that are implicitly converted in union statements, this experience taught me that the resulting query plan is not what is always expected.
