

Understanding and Using APPLY (Part 2)
Introduction
This is the second, and concluding part, of a series of articles looking at the APPLY operator. The first part examined the basic operation of APPLY, discussed query design, worked through a detailed example, and looked briefly at table-valued functions. This part compares APPLY with the familiar JOIN operator, examines the operation of APPLY in more detail, and presents some more complex examples.
One quick note: As explained in Part 1 of this series of articles, the function side of the APPLY can be a user-defined table-valued function or just about any expression that returns rows and columns. For the sake of brevity, all possible forms will be referred to simply as a function throughout this article.
Comparing APPLY with JOIN
Logical comparison
The JOIN operator works by matching rows in two sets. The result of the JOIN contains the columns from both sets. APPLY calls a function for each member of a set, building up the output in stages. The result of the APPLY contains columns from both the input set and the function. There is a logical left-to-right order of processing with APPLY, from the input set to the function. By contrast, a JOIN can be processed in any order by SQL Server.
CROSS and OUTER APPLY
Some readers might have wondered what happens if the function does not produce any rows for a particular input. The answer depends on which form of APPLY is used.
CROSS APPLY behaves similarly to an INNER JOIN: it excludes rows from the input set where the function fails to produce a result.
OUTER APPLY behaves more like a LEFT JOIN. Where the function does not return a row, the input row is still included in the final output, with NULLs in the columns provided by the function.
An example may help to illustrate the difference. Say we are asked to produce a list of students and scores, where the score was at least 80. Thinking about an APPLY solution; it is apparent that the input set is the set of all students, and the function needs to return scores over 80 for a given student.
The solution using CROSS APPLY looks like this:
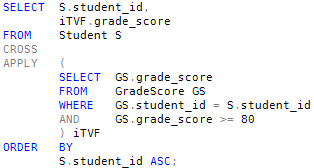
That query produces the following results:
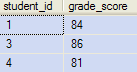
There is no result for student #2, because she did not score 80 or above in any subject. If we change the query to use OUTER APPLY, we get this:
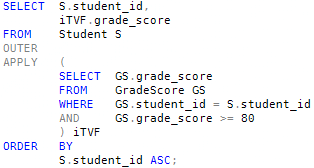
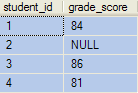
The function still returns no rows for student #2, but this time the final output does include a row, with NULL inserted into any columns contributed by the function.
Implementation and Optimization
SQL Server will always use the Nested Loops logical operator to implement an APPLY operation. This is a consequence of left-to-right processing, and use of column values from the input set within the function. Hash and Merge operators do not support the behaviour required to work with APPLY.
The exception to this rule is if the APPLY is logically equivalent to a JOIN. The query optimizer in SQL Server is clever enough to recognise those occasions when we use the APPLY keyword (perhaps to make the query design easier), but the logical effect of the query is a type of JOIN.
If an APPLY query can be safely transformed to a JOIN, the optimizer might be able to consider a wider range of options to perform the logical operation. (Recall that the APPLY operator is limited to Nested Loops, whereas other JOIN types might use a Hash or Merge operation).
If the optimizer does transform the query, the execution plan produced will be identical to (or trivially different from) the execution plan produced for the equivalent query written as a JOIN.
This is an important point to recognise when working with SQL Server. It is frequently possible to write precisely the same logical query using different syntax. The query optimizer does not normally care too much about the exact keywords we use; the logic of the request determines the execution plan produced.
We might choose to write our query using the APPLY keyword, but SQL Server is still free to transform our request in any way that still produces a provably correct result.
Equivalent Expressions Using APPLY and JOIN
It is frequently possible to write the same logical query using either an APPLY or a JOIN. This section describes two simple examples of this equivalence.
CROSS JOIN
Say we are asked to list every possible combination of student and subject names. The natural way to write the query is with a CROSS JOIN:
The same logical requirement can be expressed as an APPLY:
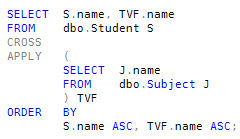
The input set here is the set of all students. The function returns the set of all subjects. There is no link (correlation) between the function and the input set; if we were to write the function explicitly using the CREATE FUNCTION statement, no parameters would be needed.
This is a perfectly valid query; it just happens to be logically identical to a CROSS JOIN operation. SQL Server produces an identical execution plan for both forms.
LEFT JOIN
In the next example, we are asked to produce a list of student names, and the average score for each student (across all subjects). Here is one way to write a solution using a JOIN:

When constructing the APPLY version, we start with the set of all students, and apply a function that calculates the average grade score for a particular student:
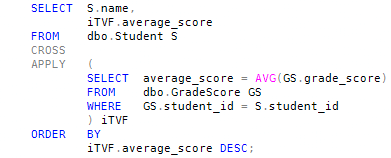
The execution plans produced by the JOIN and the APPLY are only trivially different. This is a good example of being able to write the same logical requirement in different ways.
Extra Credit
Some readers might have noticed that the last example used a CROSS APPLY, whereas the join used a LEFT JOIN. Why was an OUTER APPLY not required?
The answer is reasonably subtle. Consider what happens with APPLY when we call the function for a student that has no grade scores. What is the average value of no scores? It turns out that the answer is NULL.
The AVG aggregate function returns a NULL if no data is passed to it, and this is the NULL returned by the function. Since the function does return a row (containing the NULL), there is no need for an OUTER APPLY.
The SQL Server query optimizer also knows that AVG will return a NULL if it is presented with no data to aggregate, and chooses to implement the wider operation as a Nested Loops operator, running in left outer join mode:
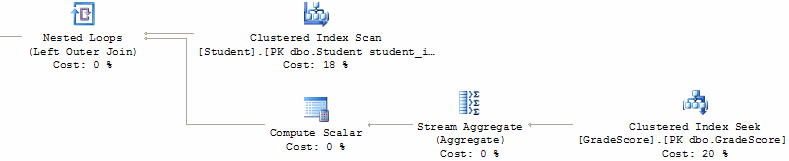
This is just another example of the optimizer transforming a query request into its logical equivalent.
Tricks and Tips
This last section demonstrates some creative uses of APPLY. There are additional details on each of the queries presented here, in the Resources section at the end of the article.
Expression Aliases
We are now asked to find the average grade score, grouped by the first letter of each student's name. Using a JOIN, you might write something like this:
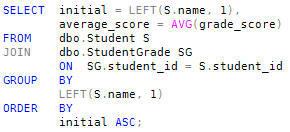
Notice how we can reference the column alias initial directly in the ORDER BY clause, but we are required to repeat the original expression in the GROUP BY clause.
You have probably written queries like this in the past, and perhaps felt frustrated by the need to repeat expressions in this way. It has always been possible to work around this, using a derived table (or, more recently, with a common-table expression):

We will now write an equivalent query with APPLY. The input set is the set of student names and average scores, and the function calculates the first letter of each student's name:

The expression is only written once (inside the function), and can be referred to by its column alias in the SELECT and GROUP BY clauses.
This example also demonstrates the use of column aliases with APPLY. The function itself always has to have a table alias (iTVF in this case). Columns returned by the function can be named either inside the function, or by using the column alias syntax illustrated above. If both are specified, the outside column alias takes precedence.
For all three implementations, the execution plans are identical.
String Concatenation
We are asked to produce a comma-separated list of all the grade scores for each student. Within each list, the scores should be sorted in descending order.
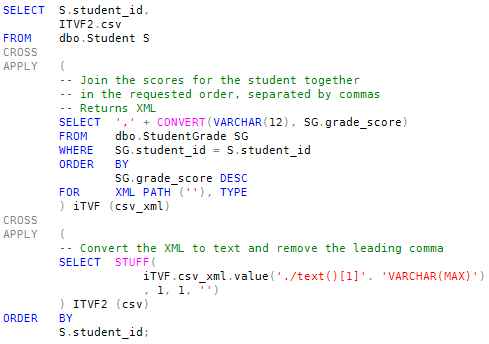
The input set is the set of all student ids. The function is more complex: It needs to find the grade scores for each student, arrange them in descending order, separate each one with a comma, and finally present the result as a string.
The function achieves all that using a trick with FOR XML PATH:
This is the output:
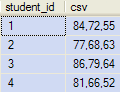
The first APPLY does all the hard work, returning an XML representation of the ordered comma-separated values, with an extra leading comma.
Rather than convert the XML to text and remove the leading comma in the SELECT clause, a second APPLY is used to perform the expression alias trick described previously.
The input set to the second APPLY is the XML result from the previous APPLY. The function part of the second APPLY converts the XML to a string, and removes the leading comma. Notice that the written order of the APPLY clauses is significant.
Shredding XML
The final example here is one seen quite often on the forums. We have received some new data for the school database, in XML format. The task is to extract the new data to a relational form. This is the new data:
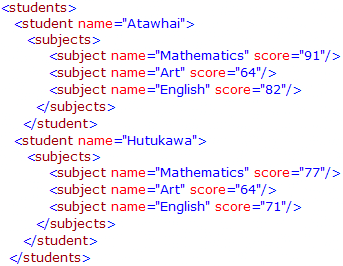
We can use XML data type methods to extract the data. The nodes() method is used to shred the XML to relational form, and the value() method is used to convert individual values to SQL Server data types.
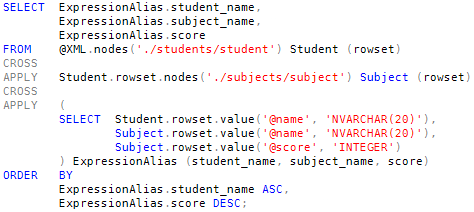
The input set for the first APPLY is the set of XML nodes at the student level. The function returns a set of nodes at the subject level.
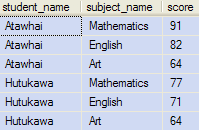
The output from the first APPLY is again the input set for the second. The function in the second APPLY extracts column values for use in the SELECT and ORDER BY clauses, using the expression alias trick.
This is the output:
Conclusion
There is some overlap between the APPLY and JOIN operators, and some real differences too. APPLY lends itself particularly well to a divide-and-conquer approach to designing query solutions.
APPLY enables the SQL Server developer to take full advantage of the benefits of in-line table-valued functions. Creating a library of such functions can do much to promote logical encapsulation, consistency, and code-reuse, while giving SQL Server maximum flexibility in searching for an efficient query plan.
The Resources section below contains heavily annotated versions of the code featured in this part of the article, together with a script to create the sample data used. It also includes some extra code examples that did not fit in the main article.
