

Two Useful Hierarchy Functions
Common Table Expressions (CTEs) are wonderful things when you need to deal with hierarchical data, because they are able to recurse conveniently. There are, however, two shortcomings to their direct use for this.
First, they can look awfully complex at the top of an otherwise simple query, making what should be straightforward code harder to read:
| with subordinates( ... ) as ( -- several lines -- of recursive logic -- appear -- at the top -- of every -- query needing the CTE ) select * from subordinates |
What you really want to do is encapsulate that recursive logic away so that you only have to look at it when you are working directly on it, and just use it otherwise.
Second, when working with very large or deep hierarchies, you'd like to restrict yourself to just the relevant portion of the hierarchy for performance reasons. Why recalculate the entire hierarchical structure every time on the fly when only a small sub-hierarchy is needed?
It turns out that a simple user-defined function wrapping a CTE can rectify both these shortcomings.
Our Working Example
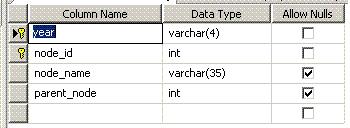
The code below creates and populates a simple, fairly generic Hierarchy table with this structure:
[Figure 1]
The year column allows the hierarchy to vary by year (and I wanted to show how you'd work that extra bit of complexity into the CTE below). The node_id column identifies the entry in the node (whether it's a person, a department, a book chapter, a huge component-assembly tree, etc). The node_name is a description of the node/entry. And the parent_node recursively points back into this table with the node_id of the parent (the supervisor, or the book section, or the assembly, etc).
Here's the code to set up the working example:
----- create example table |
The Subordinates Function
The subordinates function is a simple way to find all the subordinate nodes of a given node for a given year:
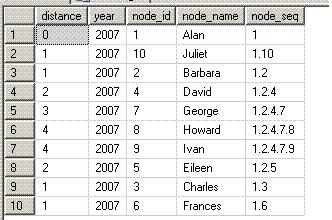
| select * from subordinates( 2007, 1 ) |
This pulls all hierarchy information for 2007 underneath node_id 1 (Alan). The distance column indicates how far down the hierarchy each subordinate node is from Alan - distance 1 nodes work directly for Alan, distance 2 nodes work for Alan's direct subordinates, and so on. The year and node_id identify the node in the Hierarchy table. And the node_seq column indicates the parent-child sequence from the given node (Alan) to that node in a dotted notation. For instance, Howard has a node_seq of "1.2.4.7.8" below - this indicates that Alan (node_id 1) is at the top of this hierarchy, then Barbara (node_id 2), then David (node_id 4), then George (node_id 7), and finally lowly Howard (node_id 8).
[Figure 2]
The same function can be called to produce information on just a sub-hierarchy:
| select * from subordinates( 2007, 2 ) |
In this case, we will just see just the direct and indirect subordinates to Barbara (node_id 2, as specified in the function call).
Here's the code to create the subordinates function:
----- create Subordinates function using CTE |
The Superiors Function
The superiors function is a simple way to traverse in the opposite direction, back up the hierarchy from a given node during a given year:
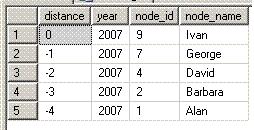
| select * from superiors( 2007, 9 ) |
This pulls each superior node for 2007 for Ivan (node_id 9). The distance column indicates how far up the hierarchy the node is from Ivan (and it is negative as an additional reminder that we are moving up the hierarchy) - distance -1 is Ivan's immediate supervisor, distance -2 is that supervisor's supervisor, etc. The year and node_id identify the node in the Hierarchy table.
[Figure 4]
Here's the code to create the superiors function:
----- create the Superiors function using CTE |
Uses
Being able to collect all the subordinates of a node from a hierarchy quickly is useful for many purposes. Rolling up summary numbers to a parent node is one such case:
select |
This creates Barbara's (node_id 2) sub-hierarchy on the fly, grabs the associated salaries and FICA costs and totals them for her sub-organization.
Authorization rules can also be enforced using these on-the-fly sub-hierarchies:
select * |
This pulls budget edits, filtering them down to just those that the user has visibility to by inner joining with that user's sub-hierarchy.
There are many other potential uses for these functions.
Summary
Where hierarchical information is stored in a table with recursive "parent" links, it is often convenient to pull all direct and indirect subordinates of a node. CTEs permit this, but may be made more readable and more efficient by wrapping them in a T-SQL user function.
CTEs - with proper indexing (note in particular the index on the year and parent_id in the working example code above!) - perform quite efficiently. I have worked with hierarchical data of up to 12 hierarchical levels among some 24,000 nodes, and the functions above execute in less than a second.
By default, CTEs limit recursion to 100 levels. If you need more than that many levels in your hierarchy, that default can be adjusted with a MAXRECURSION hint (see article at http://msdn2.microsoft.com/en-us/library/ms181714.aspx).
Hopefully, this article has shared two functions that you will find useful in your toolbox for dealing with hierarchical information!
