

Time bomb coding
At some point in your career you will be asked to get involved in diagnosing performance problems with a database application. Sometimes the diagnosis is simple but in other cases the causes of poor performance are subtle. From my own experience I have noticed that subtle performance bugbears conform to a pattern and I refer to this pattern as "Time Bomb Coding". The pattern I am referring to has the following properties
- The system is well established
- There has been no significant alterations to the system for some considerable time
- Statistics and indexes are kept up-to-date
- Execution plans appear reasonable at first glance
- The database design appears to be simple and clean
- Traffic has not changed much over time
Despite this the system performance has been steadily degrading!
If this seems familiar to you then you are probably a victim of time bomb coding. In this article I should like to give a few of the many examples of this phenomenon I have come across.
A simple example
I've lost count of the number of times I have come across code similar to the snippet shown below.
IF ( SELECT COUNT(*) FROM .... WHERE ...) > 0 BEGIN ...etc END
The code is simple and clear in its intent. It may even have got through some rudimentary stress testing during development but a few years on that SELECT COUNT(*) is being carried out against a multi-million row table!
An accurate value for COUNT(*) simply isn't relevant, the mere existence of records satisfying the WHERE clause is. If you are lucky the WHERE condition will be covered by an index and result in an index seek but the chances are it will result in an index scan, or worse. Simply changing the condition to
IF EXISTS(SELECT 1 FROM ... WHERE...)
May be sufficient to get the application performing again.
Timeliness when providing counts
Another cause of time bomb coding is the failure to consider when it is necessary to provide an aggregate
value such as a count, sum or average.
- Should it be calculated on the fly?
- Is it more appropriate to calculate it by some sort of batch process?
If you look at the the SSC home page you will see that articles have an overall rating and a count of the number of reads
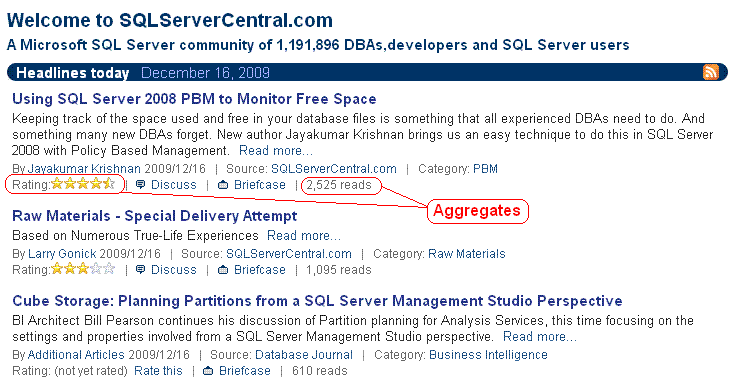 |
If an article is popular then the number of visitors reading and rating that article could be very high.
If the aggregate is calculated on the fly then as time goes on the amount of activity necessary to perform the calculation will increase.
Pages such as the home page that display multiple aggregates will get progressively more expensive to service.
By considering WHAT events cause these aggregates to change we can evaluate WHEN
the calculation of aggregates should take place.
| Aggregate | Change Event |
|---|---|
| Rating | When a site visitor rates an article. A site visitor may only rate an article once. |
| Reads | When a site visitor access the article |
By taking into account these change events we find that we can produce a summary table for the aggregate values with ArticleID as the primary key. We update a record when a suitable event takes place.
We can take this one step further so even though we only calculate the aggregates when triggered by appropriate events we don't
recalculate from scratch. If we aggregate the scores by day then once the day is ended the aggregate for the day
cannot change! This means that we can have an overall aggregate for all activity prior to today and recalculate the aggregate
scores for the current day.
| ArticleID | DateCreated | TotalReads | NumberOfRatings | TotalRatings |
|---|---|---|---|---|
| 1 | 2000-01-01 | 5000 | 400 | 1800 |
| 1 | 2009-12-24 | 1000 | 50 | 200 |
For any given article there will only ever be a handful of values to provide the required aggregate values
no matter how many people read the article or rate it.
The dreaded BIT field problem
I once worked on a content migration project that required documents in various formats to be processed into a unified format.
The database had to keep a record of the original documents and identify those that had been processed or were awaiting processing. This table was called dbo.DocumentList
The dbo.DocumentList table had a clean and simple design
| Field name | Data type | Purpose |
|---|---|---|
| DocumentID | BIGINT NOT NULL | Primary key for the document record |
| OriginalFileLocation | VARCHAR(1000) NOT NULL | The fully qualified file name and location of the input file. |
| ProcessedFileLocation | VARCHAR(1000) NULL | The fully qualified file name and location of the reprocessed file |
| IsProcessed | BIT NOT NULL | Flag to indicate that the file has been successfully processed |
| IgnoreForProcessing | BIT NOT NULL | Flag to indicate that no further attempts should be made to process the file. |
| DateTimeCreated | DATETIME NOT NULL | Timestamp for record creation. |
When a new document was received a record containing its path and filename was created with the BIT flags set to FALSE. The application would retrieve any records with the BIT flags in this state and attempt to process the associated document.
- If successful then both BIT flags were set to TRUE.
- If unsuccessful then only the IgnoreForProcessing flag would be set to TRUE
As an indicator as to the state of the documents there is nothing wrong with the table design. It clearly shows the state of the documents.
As a method of selecting the documents to be processed it is awful.
Processing would be started as a batch run over night. The person kicking off the batch would invariable see the migration
process start and be rocketing through the documents and go home. By 07:00 the next morning the first person in would check
on the migration process only find that it was nowhere near complete and crawling rather than running.
With the benefit of hindsight the reason is obvious. The selectivity of the BIT fields is poor resulting in table scans.
The power of the hardware was such that initially the speed simply wasn't an issue but as the night wore on and the
number of documents built up the time taken to scan the records built up and up until the conversion application ground to a halt.
The solution was fairly simple. Create a table for the express purpose of holding records to be processed which
had a one to one relationship with the original dbo.DocumentList table.
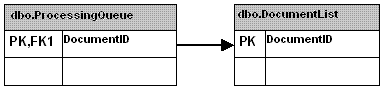 |
The dbo.ProcessingQueue table held only those records that had not yet been considered for processing so it was sufficient for each run to grab the TOP 5000 records out of dbo.ProcessingQueue and attempted to process them.
The same logic as before was applied to the BIT flags in the dbo.DocumentList table but in either case the records were removed from the dbo.ProcessingQueue table. This meant that no matter how large the final dbo.DocumentList table grew ongoing conversion work meant that only the dbo.ProcessingQueue table needed to be read.
This queue table approach is quite a common solution to such a problem.
A possible alternative?
In theory we could have done the following to the ProcessedfileLocation field.
- Shrunk to a VARCHAR(900) to allow for indexing
- Changed to a NOT NULL field with an empty string default
- Indexed which, by definition would be highly selective.
In practise this has several disadvantages over the use of a queue table approach.
- The index would be 900 bytes per record in the dbo.DocumentList table rather than 8 bytes in the dbo.ProcessingQueue table.
- Only the unprocessed records are relevant therefore the majority of the index is wasted storage
- If we have a large batch of documents to process, or statistics on the dbo.DocumentList table become out of date then there
is the risk that the query will start scanning rather than seeking
As if this was not enough there were genuinely documents with fully qualified names in excess of 900 bytes
and this would breach the allowed limit for indexing a VARCHAR field.
The Top 'n' products example
A common business requirement is to display the most popular products to a customer. It is quite common to find that a developer has simply tagged a TopProductPosition to the product table as shown below.
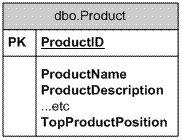 |
There are a number of problems with this approach.
- Every product has a TopProductPosition field attached to it even though it is only relevant to a handful of products
- There is no simple way to enforce any limits on the field for example how would you enforce a top 10 rule?
- For this design to perform the TopProductPosition field would have to be indexed so you would end up with a storage penalty both for the field and the associated index.
I would place money on the developer having defined the TopProductPosition field as an INT field allowing for
232 (4 billion) values. Even if it was defined as a TINYINT a million product catalogue would require
megabytes of storage to implement this solution.
A Top 'n' products solution
I find that people new to databases take some time to grasp the concept of a 1 to 1 relationship.
Once you grasp such a concept the solution is simple.
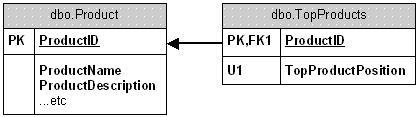 |
This design solves a number of problems
- A product can only appear once in a top 'n' list.
- Products cannot share a position
- If we have a Top 10 rule then we can even put a CHECK constraint on the TopProductPosition field to enforce the rule.
- We don't need any additional indexes on our large product file so the additional storage requirement for the
functionality is measured in bytes rather than megabytes.
- We have not corrupted the design of our dbo.Product table in order to satisfy what is effectively a business logic rule.
The one true lookup table problem
This subject has been much written about and discussed over the past two decades. The problem is that it looks like such an elegant solutions.
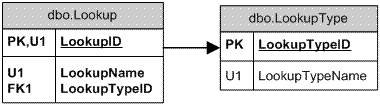 |
At some point in your career (if you haven't already) you will look at the design and think
"that's a pretty cool idea". It happens to all of us, like falling off your bike or experiencing an unspeakably
embarrassing incident on a first date. Phil Factor described it pretty well. http://www.simple-talk.com/community/blogs/philfactor/archive/2008/05/29/56525.aspx
My own brush with this was when facing a very tight deadline and needing to put together a demo for a customer. The demo made it through to production and was the genesis of a lot of support calls.
- You can't enforce proper data referential integrity with this design, you can only say that the record in your main table has to have a value in the lookup table.
- It forces a one size fits all approach on your look up tables.
- Delete a record from your lookup table and the database will have to check that every single field referencing LookupID does not violate DRI.
- Insert a record into a main table and it is going to be fighting with every other table for which an insert has taken place.
Given how notorious the "one true lookup table" design is and the amount that has been written about it you could
be forgiven for thinking that no-one is still creating such designs. Unfortunately they do still crop up in their purest form and
sometimes in commercially available applications.
The same problems afflict entity-attribute-value designs. Even when the application code is bug free and captures all possible
user errors that can occur for data entry the design is ultimately not scalable.
Variations on OTLT
In some cases OTLT designs are hidden or there is a design which suffers from precisely the same problems as OTLT. These are usually caused by trying to apply an object orientated approach to a relational database.
Any time you find yourself saying "entity 'x' is a type of ...." you are at risk from generating a problem similar to OTLT.
For example you may have supplier addresses and customer addresses. You should consider very carefully whether or not these should be treated as completely separate entities from the database perspective or whether there is a good case for holding them in a single table.
In many cases (but by no means all cases) we find that having separate entities makes more sense and if we want to present a unified view of similarly structured entities then a database view provides that facility.
Row by row processing
Jeff Moden calls this RBAR - Row by agonising row. Mostly it is easy to spot but occasionally something slips under the wire.
The one that caught me out was when someone used a pre-existing stored procedure in an inappropriate manner.
The characteristics of the stored procedure were as follows
- The stored procedure in question was to remove a customer's details
- For a single customer account the related records were spread across eleven tables
- The procedure was optimised and correctly wrapped in a transaction with a suitable isolation level
.
The problem came later when someone decided that customer details should be removed in batches. Rather than write a
separate stored procedure that would handle the batch criteria the developer was lazy and tried to reuse the existing single
customer purge stored procedure.
The resulting code involved a job that would iterate through all the relevant customers making a call to the single customer
delete stored proc for each of the customers in the batch. For 6,000 customers this meant that 66,000 calls were made to the database rather than eleven!
Time bomb by omission
Sometimes poor performance is simply down to the sheer amount of data the database holds.
Andy Warren wrote Worst practice - Not having an archive plan for each table back in 2002. In the first line he writes "Every time you build a table you need to decide right then if and when data should be removed from it..."
On the back of Andy's article I wrote Data archiving - Problems and solutions which
gave a real world example of the problems of plugging in a solution at a later stage.
Backups, purging/archiving and re-indexing are standard practise so there is no excuse not to design them into a solution from day one.
Consider the consequences of holding too much data in a single partition of an active table
- Reindex jobs take too long and the resulting locking causes service interruption.
- Backup jobs consume excessive space and eat into the window for out-of-hours maintenance activities.
- An accidental reinitialisation of a publication results in massive traffic through the distributor and on to the subscribers.
- The sheer number of records in a table means that statistics are not used efficiently on the table.
Let us suppose that you have written a purge job with the following characteristics
- It is robust and bug free
- It is going to run as a scheduled job every night
- It purges records that are over 3 days old
You retro fit it into your live environment and on the first night it runs the support phone doesn't stop ringing.
The problem is that there is too much data to purge within the allowed time frame. You need to nurse your data down to the point where a 3 day
purge strategy is safe to implement.
Conclusion
While I was a DBA I came across time bomb coding frequently and came to recognise the patterns that indicated that such problems
existed.
There are defined measures of data quality the violation of which I now recognise as being the root cause of time bomb coding.
DBAs probably don't think of these measures on a day to day basis but cater for them subconsciously.
- Accessibility - Can everyone who has genuine need to access the data do so easily.
- Accuracy - How accurate does the data need to be? Do we need a timestamp accurate to 3 milliseconds or will a simple date do?
- Completeness - How complete does the data need to be? Do we need an accurate count or will a test of existence do?
- Consistency - Is the data always calculated the same way and does a term always mean the same thing?
- Integrity - Are there broken relationships in the data?
- Relevance - Is the data useful?
- Timeliness - Can the data be delivered in a form sufficient for its intended purpose within a timeframe that allows the data to be useful?
By carefully considering these measures, in particular timeliness, accuracy and relevance time bomb coding and design should be avoidable.
In the mean time I should be interested to hear of your experiences.