

I was looking at the different SQL datatypes in Books Online and something struck me about the different integer types.
| Datatype | Storage | Value range |
|---|---|---|
| SMALLINT | 2 Byte | -32768 to 32767 |
| INT | 4 Byte | -2,147,483,648 to 2,147,483,647 |
| BIGINT | 8 Byte | 9,223,372,036,854,775,808 to 9,223,372,036,854,775,807 |
An INT field has a range of 4294967296 values so why is it so common to see a field definition such as the following
CREATE TABLE dbo.Customer( customerId INT NOT NULL IDENTITY(1,1) CONSTRAINT PK_Customer PRIMARY KEY NONCLUSTERED , ForeName VARCHAR(50) ......etc )
By specifying an identity value starting at 1 the possible number of values that CustomerId can take is halved!
Obviously, in the case of CustomerId the number may be used in correspondance to the customer and a +- sign may be
confusing to the customer but surely the front end application can deal with this?
I wonder just how many times a larger than necessary datatype has been used simply to avoid running out of positive values! How many businesses can claim that they have 4,294,967,296 customers on file?
Possibly the worst use of an INT field that I have seen is for a lookup table to hold values that could be binary if
government rules didn't insist on allowing for the "don't knows".
What impacts are there on choosing the wrong size of integer field?
To test the impact of choosing the wrong integer type I defined 3 tables, each one with a different signed integer type.
| Table name | Integer type | Description |
|---|---|---|
| Byte16 | SMALLINT | 16 bit signed integer |
| Byte32 | INT | 32 bit signed integer |
| Byte64 | BIGINT | 64 bit signed integer |
Into each one I put an identical set of records with id's in the range -32768 to 32767. This range was dictated by the maximum bounds of the SMALLINT datatype.
Storage space
The most obvious impact was on storage space. The table below shows the results for sp_spaceused
on each table.
| Name | Rows | Reserved | Data | Index size | Unused |
|---|---|---|---|---|---|
| Byte16 | 65534 | 776KB | 728KB | 16 | 32 |
| Byte32 | 65534 | 904KB | 856KB | 16 | 32 |
| Byte64 | 65534 | 1160KB | 1112KB | 16 | 32 |
So over 65534 records the difference between a 2 byte integer and an 8 byte integer is 384Kb of storage. When the cheapest budget PC comes with a 160GB hard disk 384Kb does not sound like a lot.
Let us have a look at INT vs BIGINT with 1,000,000 rows.
| Name | Rows | Reserved | Data | Index size | Unused |
|---|---|---|---|---|---|
| Byte32 | 1,000,000 | 13,000KB | 12,880KB | 56KB | 64KB |
| Byte64 | 1,000,000 | 16,904KB | 15,808KB | 88KB | 8KB |
The difference in storage is approximately 4MB which is still not large from a storage perspective.
If you have millions of records and hundreds of fields then a hit on storage capacity is to be expected but from for
most scenarios the difference is relatively trivial.
The storage of fixed length, non-nullable values is very efficient in any case and in most applications it is the size of the text fields that makes up the bulk of the storage requirement.
INSERT performance
I decided to run an experiment performaning 65,534 inserts into each of my three original tables. The experiment was carried out on a stand-a-lone SQL Server using SQL Management Studio as the front end application. The chart below shows the result for 10 itterations for each table.
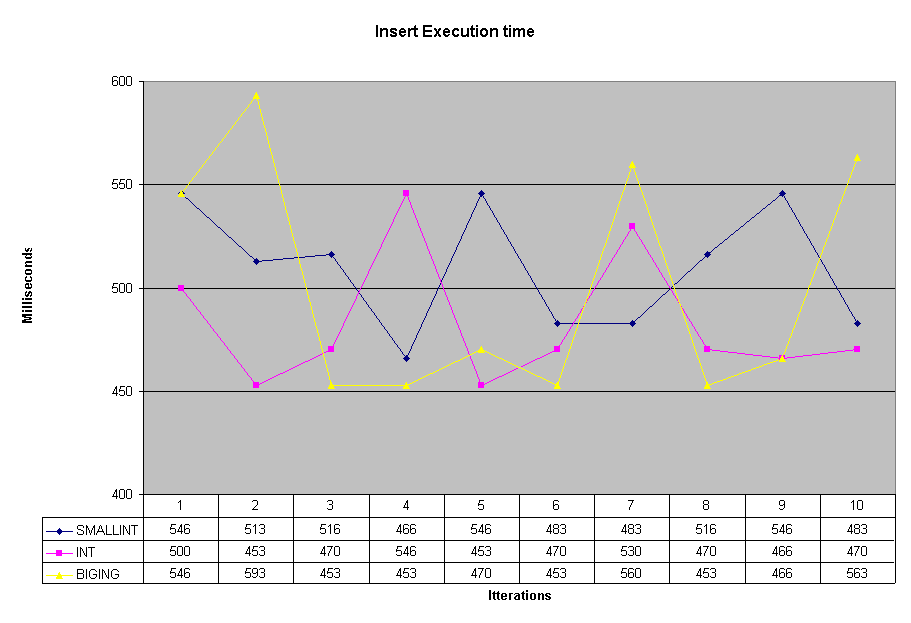
I was expecting the inserts into the table with the BIGINT to be slowest and SMALLINT to be the fastest but as the graph reveals this expectation was not born out in reality.
At this point I feel it is necessary to emphasise that this experiment has taken place on a stand-alone system. The similarities in performance could be due to the load within the system being too low to emphasise the differences.
To use an analogy, if you take 2 cars, one with a small engine and the other with a large engine both will cope with a 60mph motorway/freeway/autobahn journey. Both will cope with an increase in speed to 70mph and the difference in fuel economy between the two speeds won't be much different. Accelerate to 80mph however and the small engine will struggle and its fuel economy will decrease markedly. The larger engine will cope far beyond the 80 and even 90mph. Trying to make a determination of the affects of accelerating from 60mph to 70mph won't reveal as much as accelerating from 70mph to 80mph.
SELECT performance
I ran a similar experiment asking to retrieve all 65,534 values from the table and again I observed similar results. That is no datatype offered a noticeable performance advantage over any other.
Again, if an application runs a query to bring back a large recordset and this data has to be moved across a network I would expect the different datatypes to display noticeable performance differences however in a stand-alone-environent I could see no recognisable pattern to the data.
In OLTP environments there tends not to be a requirement for moving large recordsets around. Such activity is more common in reporting and analytical environments.
Conclusion
I started using SQL Server shortly after SQL6.5 was released. Back in the olden days of which I speak the power and capacity of servers was unimaginably lower than it is today. For example Pentium II 90MHz, 64MB RAM, 4GB Hard Disk.
The importance of capacity planning and the careful matching of datatypes to requirements was hammered into us by senior DBAs and rightly so given the constraints of the day. It wasn't hard to stress a 64Mb system although it was cutting edge at the time.
When I started my experiments I was not expecting massive differences but I was expecting to notice a slight performance benefit from the smaller integer types. My experiments simply did not show this to be the case. Never the less I remain extremely wary of the results I have observed here. I believe that all I have proved is that in low stressed systems you can be far less fussy with correct sizing your datatypes. This is hardly earth shattering news!
I am not sure of the circumstances that would allow me to run a full blown test because by definition a high stressed system is not the sort of system where you want to carry out experiments.
I still wish that Microsoft had included unsigned integers (other than TINYINT) in SQL Server but given the results I have seen in my experiments I suspect that it is a case of why bother?
I will still spend the time designing my databases with the appropriate datatypes. The systems I design may never be so heavily used that the design makes a difference to their performance but good design remains good design.
