

Introduction
I enjoy reading the articles published by Red Gate Software under their Simple talk site.
In particular I enjoy the columns by "Phil Factor" and a paragraph in one in particular caught my eye.
Many features that we accept as part of a relational database were put there to defend the integrity of the database against the ham-fisted endeavors of the freelance programmer. Checks on foreign keys and uniqueness are excellent in development but are scarcely necessary if creating, updating and deleting are done through well-tested stored procedures. And, they will certainly slow data throughput in a hard-working production system.
To see the full article see cursors and embedded SQL
As regular visitors to SQLServerCentral will have observed articles advocating a particular approach are usually hotly debated and so in the context of the quoted paragraph in particular I should like to show you the results of some experimentation I carried out with declared data referential integrity.
The basic scenario
For my experiments I considered a hypothetical Web Content Management System (CMS), based around my favourite commercial CMS, using SQL Server 2005 as the database repository.
The system consisted of a number of user editable objects that could be represented by
- A single table to hold the common properties for all objects within the system such as name, hyperlink, creation date, security context
- A separate table to hold the specific properties for each type of object
The basic layout is a star layout as shown below
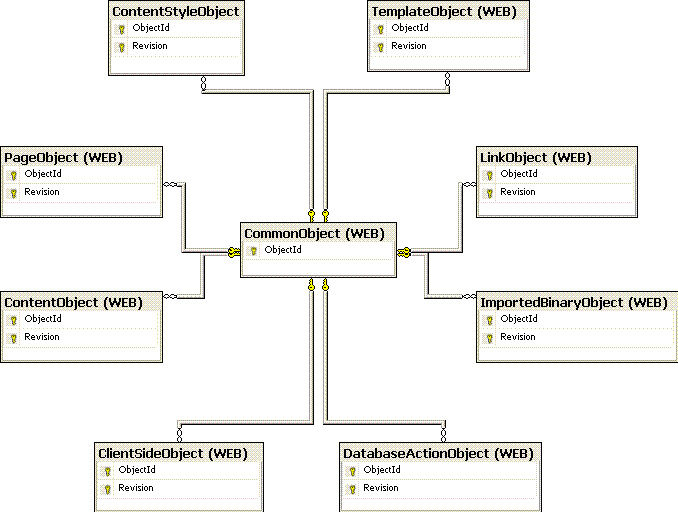 |
The common properties table has an IDENTITY column as the primary key.
With a high end CMS performance is one of the prime considerations. Direct access to database tables is frowned upon especially as all legitemate tasks can be carried out by an API.
I began to ask myself what would be the difference in performance in the above scenario between the schema with a full set of foreign keys and one with DRI enforced purely in the stored procedures used to control the data layer?
Inserts
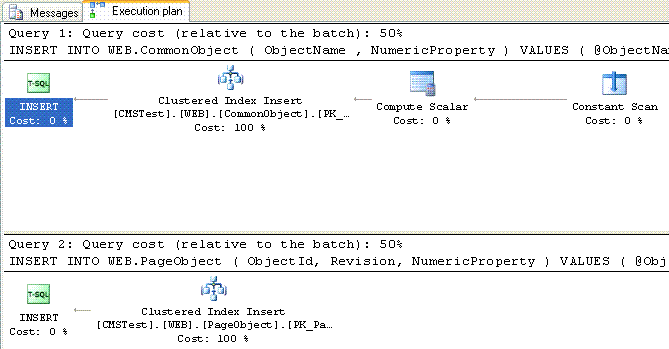
To test inserts I set up a straight forward stored procedure that would
- Populate the CommonObject table
- Take the SCOPE_IDENTITY() from the new record and use it to populate one of the specific object tables
Without DRI the execution plan was as follows
 |
With DRI the execution plan reveals that SQL Server performs an additional index seek to make sure that DRI rules are adhered to.
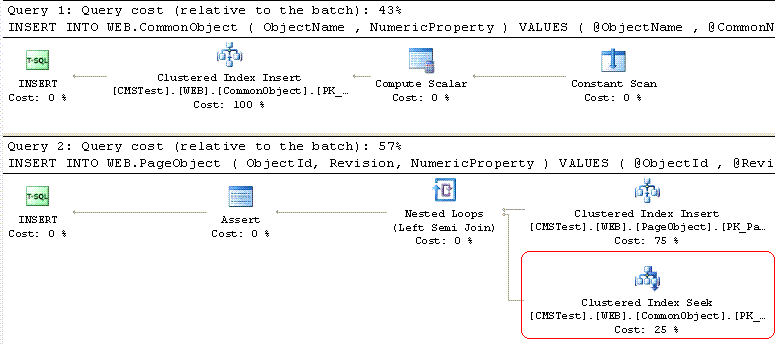 |
In this particular case the cost of an extra index seek is trivial and in SQL 2005 the cost is slightly less than half that for the same operation on a SQL2000 box.
Let us consider a slightly different scenario where we have a customer table supported by several lookup tables. If we were to add foreign keys to the table then each addition into the customer table would require a check against every supporting lookup table to maintain data referential integrity. In small to medium systems even in this situation the cost will be negligible however in high volume systems small costs soon multiply up to reveal a more significant affect.
Deletes
Again a stored procedure was set up to perform the following action
- Remove a record from one of the specific object tables
- Remove the associated common property record
Without DRI the execution plan for the delete is just a couple of simple Clustered Index Deletes.
 |
With DRI enabled the execution plan is dramatically more complex.
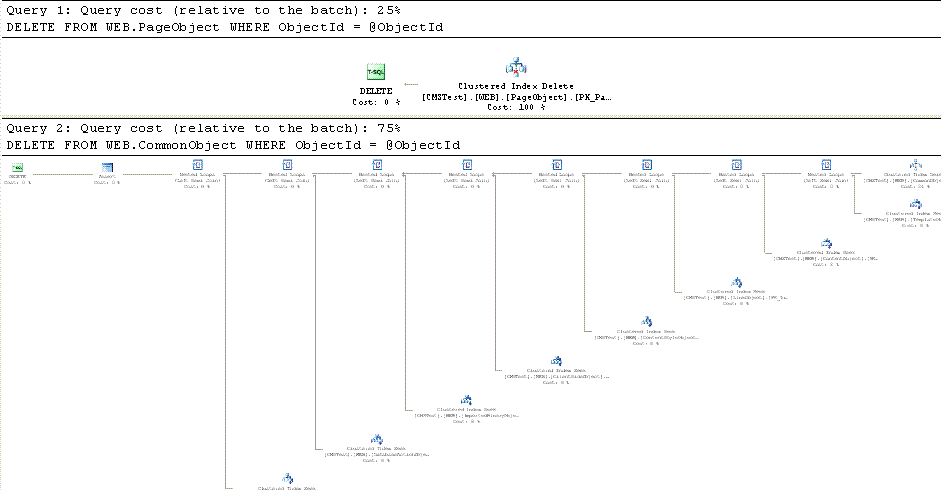 |
Data referential integrity rules mean that deleting a central CommonObject record requires that all the tables that refer to the CommonObject table must be checked to ensure that DRI is not violated. In our example this means that deleting the CommonObject record is 3 times more expensive than a deleting a specific record.
This raises another important consideration. In our example the one CommonObject record can have many entries in one of the specific object tables. Now consider a Customer table attached to various lookup tables.
If we have to delete an entry from one of those lookup tables the Customer table will have to be checked to ensure that DRI rules are not violated. This more or less dicates that the referencing column in the Customer table HAS to be indexed! If it is not indexed then the execution plan will show costly scans or even table scans!
OK my example with a customer table is probably not a good one and lookup tables tend to be fairly static but the point is that your application may never search on the referencing column and therefore you would want to save yourself the overhead of having an index on that column. With DRI enforced you more or less have to place an index on a column to get acceptable performance during a delete.
Updates
In my CMS example update performance was not impacted by DRI. Reverting back to the Customer example, let us suppose that you have a CountyId field and decide that a customer's address has incorrectly been assigned to Lancashire when the customer is clearly a Yorkshireman. The update of the customer record will require a check to be made on the County table to ensure that the new value for the CountyId field is valid. As with INSERTs such operations are trivial until you are dealing with very high volumes of data.
Concluding remarks
It is worth remembering that if a table is referenced by a foreign key constraint you cannot use the TRUNCATE TABLE statement on that table.
Having enforced DRI also affects the order in which inserts and deletes can take place for the various tables. In general this is no bad thing but there are few absolutes in SQL Server. If you are in the habit of archiving data off into history tables the ability to move data in an order not dictated by DRI rules may be desirable. In such a scenario the DRI checking will have been carried out in populating the live tables so it may be possible to get away with little or no DRI checking on the history tables.
Phil Factor's statement that DRI will
"slow data throughput in a hard-working production system"
is true but it will be a hard working system indeed where this becomes apparent, particularly using SQL 2005. The big exception to this is where DELETEs occur.
The over-riding point is that DRI is a design issue. Careful, well thought out design can maximize the advantages of DRI while minimising the disadvantages.
I am in two minds about his comment that DRI is
"scarcely necessary if creating, updating and deleting are done through well-tested stored procedures".
It sounds a perfectly logical statement to make however my experience has been that large projects often become subject to compressed delivery schedules towards their completion. In consequence test cycles are cut in the belief that any serious errors will show up in user acceptance testing. My experience is that this is not always true and large complex systems are able to hide large complex bugs.
In the real version of my hypothetical CMS example there was no declared DRI, but the package did have a suite of specific repository checking and repair routines to cater for orphaned data. The developers had also realised that delete activity was potentially a bottle neck and so their approach was to have a flag to indicate that an object should be considered deleted. True deletion could be carried out at scheduled times to avoid impacting on either the users of the system or the visitors to the site served by the system.
