

I saw a post recently that discussed performance of a table with no keys or indexes. That’s a recipe for poor performance in queries if this table grows large. In this case, I’ll demonstrate how an index might change the performance of a query. In many cases, a query is a range query looking for a series of records between two dates. This is a common type of query that will be used against this type of table. I'll actually use this as a range from a start date through the ending dates, as an open ended range.
I've seen more than a few people seem confused or surprised by the INCLUDE phrase as a part of the index. This article is intended to show a few basics of how the INCLUDE clause effects on queries and indexing.
NOTE: Please understand indexing is a complex subject and we want neither to avoid new indexes, nor add indexes to cover every situation. We want a limited number of indexes on busy tables, so judiciously decide whether an index you are testing should be added to the table.
Setting Up an Audit Table
In this case, the table was an auditing table with a number of columns. To simplify things, I’ll make a narrow version of this table.
CREATE TABLE AuditLog ( AuditKey INT IDENTITY(1,1) NOT NULL CONSTRAINT AuditLogPK PRIMARY KEY , SourceTable VARCHAR(128) NOT NULL , UserTable VARCHAR(128) NOT NULL , AuditTimestamp DATETIME2 NOT NULL , AuditMessage VARCHAR(5000) NOT NULL , ReferenceKey VARCHAR(100) NOT NULL ); GO
I’ll populate this with 100,000 rows using SQL Data Generator. This is a quick way to randomly add some data that will help me test performance. Once I get the table loaded, I’ll run a query that is looking for records based on a date.
A Basic Query
My table just has a basic clustered index for the primary key. That’s fine, but in this case, it will not be useful. One common query that people often run is based on date, so let’s create an index to support this:
CREATE INDEX AuditLog_IDX_Timestamp ON dbo.AuditLog (AuditTimestamp);
Now, I can run this basic query.
SELECT al.SourceTable,
al.ReferenceKey,
al.AuditTimestamp
FROM dbo.AuditLog AS al
WHERE al.AuditTimestamp > '2019-01-01';
GOIf we run this, I get 2,576 rows back in my test set. Not a small number, but not huge. If I capture the execution plan, I see this:
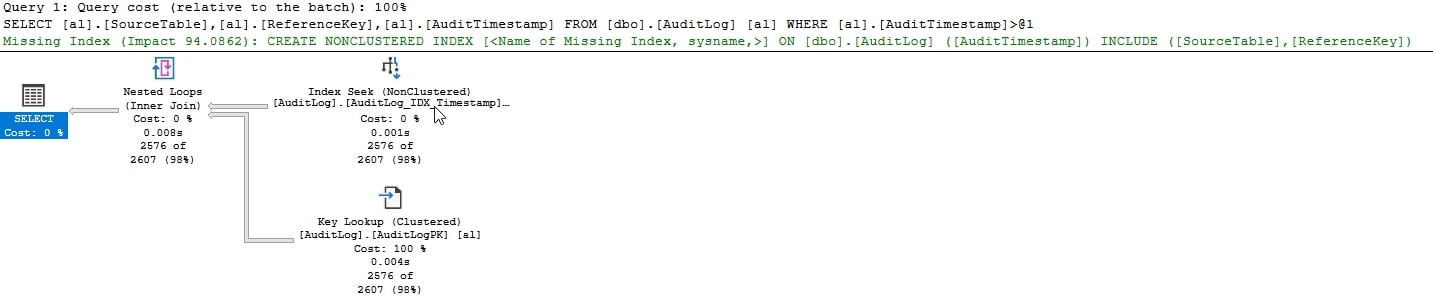
Not bad, I get a seek, and since I need more than just the key column, I'll get a lookup as well. From STATISTICS TIME and IO, we also see:
(2576 rows affected) Table 'AuditLog'. Scan count 1, logical reads 7907, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. (1 row affected) SQL Server Execution Times: CPU time = 16 ms, elapsed time = 125 ms. SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms.
The performance here isn't bad. This is what I'd expect with a good index that matches the query predicate that we're using. Lots of us would stop here with tuning and think this is great. Especially as pre-index, we had 40,000+ logical reads and a clustered index scan.
Let's see if we can improve this.
A Hint
There's actually a hint in the execution plan show above. The missing index hint shows where SQL Server thinks that this query could benefit from an INCLUDE, and it can. Let's try that. First, we drop the existing index, and then we recreate it, but we'll add the INCLUDE clause.
DROP INDEX AuditLog_IDX_Timestamp ON dbo.AuditLog
GO
CREATE INDEX AuditLog_IDX_Timestamp ON dbo.AuditLog (AuditTimestamp)
INCLUDE (SourceTable, ReferenceKey)Now, let's re-run the query. This time, we get a different execution plan:

That's much better, showing a minimal seek for the rows. We see less resources being used as well for reads, with 19 logical reads instead of 7,907.
(2576 rows affected) Table 'AuditLog'. Scan count 1, logical reads 19, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. (1 row affected) SQL Server Execution Times: CPU time = 0 ms, elapsed time = 73 ms. SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms.
That's the improvement you can get with INCLUDE.
Using INCLUDE
The INCLUDE phrase in an index is the chance to add other data columns to the index. However, these columns are not used in the WHERE clause as possible predicate values. They are added to the leaf level of the index and useful for removing the key lookup that we received in the first execution plan.
There are two parts of a query that can impact performance. The first is how quickly can we find the rows we need, which is why we create indexes. In this case, both indexes we tested had the AuditTimestamp column as a key column. This allowed the query execution engine to quickly find the rows that would satisfy the query.
The second part of the query that affects performance is the data from those rows that need to be returned. If the data is in the index, such as the AuditTimestamp, then this is very low cost to return. However, if the data is not in the index, then the engine must go to the clustered index or heap to get the data. This is one reason the SELECT * is a horrible concept in production code.
With an INCLUDE clause, we can add those columns to the index and allow the query to be covered, with all data needed for the query included in the index.
The choice of which columns to include should be made carefully, and with an eye towards balancing the workload on your instance. Every column added increases the width of the index, and therefore the size. This decreases the advantage that the nonclustered index has over the clustered index as well as increasing the amount of resources that maintain the index on each insert/update/delete. Extra columns also increase the number of reads needed to use the index in all queries.
Summary
Using the INCLUDE clause can help you speed up some common queries as the engine doesn't need to access the clustered index or heap for additional data. When columns are often used in the SELECT column list, but not in the predicates, adding them as an INCLUDE can be helpful for reducing the need to add a lookup to the execution plan.
However, adding INCLUDEd columns does increase the size of the index as well as the level of maintenance needed to keep the index up to date. You ought to consider the INCLUDE phrase, but balance this against the other requirements of your workload.
