

The Sequence object was introduced in SQL Server 2012. This is a separate schema object that produces a sequence of numeric values, similar to the way an identity works. A sequence is a separate object, however, and it produces values independent of a table. The next value in the sequence can be retrieved before an insert, and the sequence can be shared by multiple objects. The use and behavior of the sequence is controlled by the application, but the behavior needs needs to be understood and considered by the developer.
This article looks at the basics of the sequence object, how it can be bound to a table as a default and used in insert statements. There are potential unexpected behaviors from using sequences that can be very different from the Identity property, so be sure to test your application with multiple concurrent sessions and a variety of conditions to be sure you understand how this object works.
The Basics of Creating a Sequence
Since a sequence is a first class schema object, we use specific DDL to create one. The minimal code is shown here:
CREATE SEQUENCE dbo.CountByOne
This will create a new object in the dbo schema, called CountByOne. As with other objects, I use CREATE syntax, specifying the type, which is SEQUENCE here. I assign a schema (a best practice) and then give an object name. This object is stored in sys.objects, as we will see below. The name of the object should conform to the naming standards for a SQL Server identifier.
As you might expect, this will count up by one. I can use the NEXT VALUE FOR phrase to retrieve the next sequence value. I use this in a SELECT statement, as I would for a column value. For example, I can run this:
SELECT NEXT VALUE FOR dbo.CountByOne
I give the sequence name and I get the value back. Each time I run this, I get the next value in the sequence. When I run this now, I find the value is unintuitive:
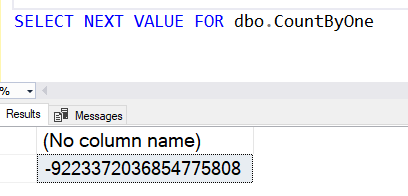
More about that in a minute, but if I re-run this, I get a new result.
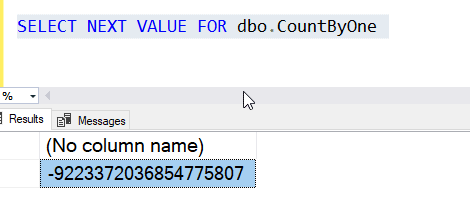
The first value was -9223372036854775808 and the second was one value larger, -9223372036854775807.
This isn't what many of us would want, so what happened?
Sequence Defaults
There are a number of parameters that are available for the DDL for a sequence. However, if you don't choose to add any, you get these defaults:
- Datatype - bigint
- Start value - the minimum value for the datatype. For a bigint, this is -9223372036854775808. For a tinyint, this is 0
- Increment - The default increment is 1
- decimal and numeric values use a scale of 0
- minimum value - 0 for tinyint, negative for other types
- max value - max value for the particular data type
- cycling behavior - the default is no cycling
- Caching - the default behavior is to cache values
We can see the minimal tinyint value with this example, where I just set the datatype:
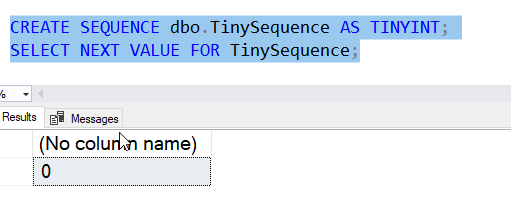
Sequence Options
We've seen the defaults for the various options, but let's actually look at the options available and choices.
The first option that should be specified is the datatype. Almost all numeric data types are available. You can choose from bigint, int, smallint, tinyint, decimal, or numeric. Note that float and real are not valid.
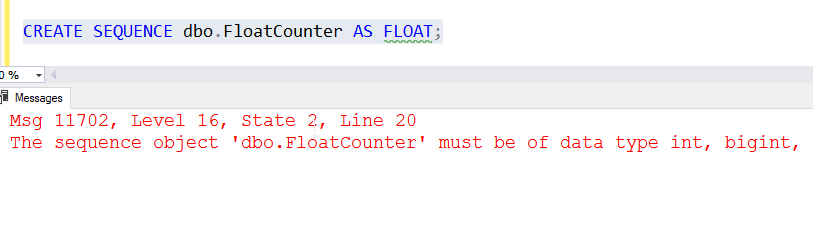
If you choose decimal or numeric, you need to use a scale of 0, as the 1 is not valid. This means we cannot increment by 0.1 or any other fractional amount.
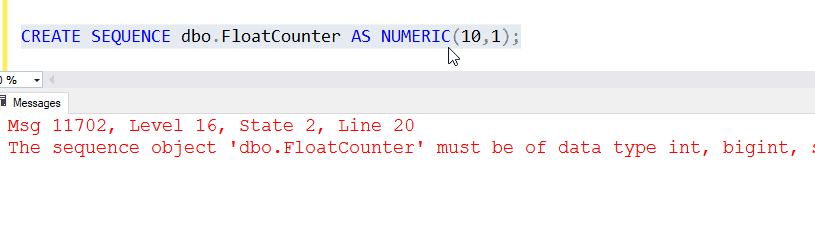
As we saw above, the default starting value is the minimum value for the datatype. This is a large negative number for most datatypes, though you can control the value based on the datatype. If I choose a precision of 1 for a numeric, I see -9 as my value.
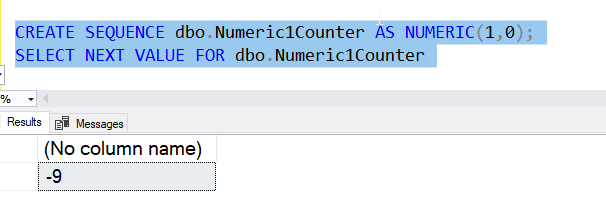
This isn't terribly useful, and it's not what most developers would want to see. Instead, they would want to choose a starting value, often 0 or 1. The START WITH option chooses the first value of the sequence number. This is the first value retrieved, and is similar to the seed for the identity property. Here is an example, where I start with a 0 and then retrieve this value.
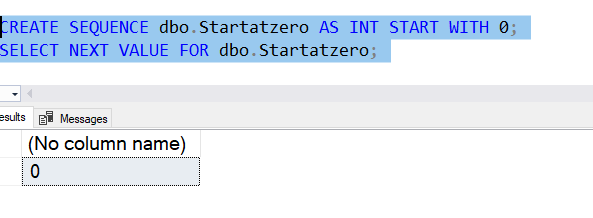
The nice thing here is that I can start with a higher value if I am replacing an identity or other structure.
The next parameter is the increment. This is the amount by which each sequence number increments from the previous one. The default is 1, but you can choose a custom value. This is the same as the identity increment, and it must be a whole number. Since the decimal/numeric scale is 0, this means I can only include whole numbers. I add this syntax without a comma as a part of the syntax.
CREATE SEQUENCE dbo.IntCountBy10 AS int START WITH 0 INCREMENT BY 10;
I can see this in action with this code snippet.
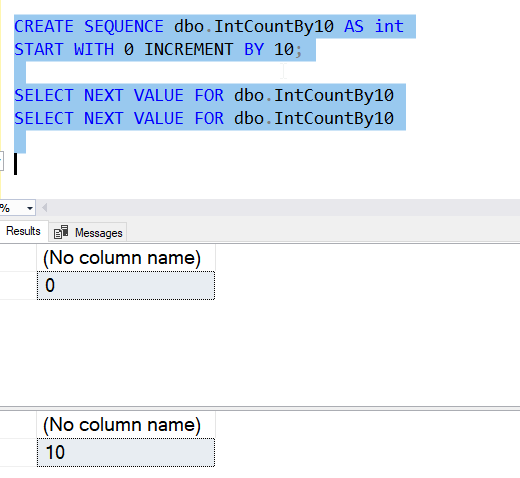
I do have the ability to set bounds with the MINVALUE and MAXVALUE settings. This lets me set the minimum and maximum values, which prevent the value from going out of bounds. For example, I can do this:
CREATE SEQUENCE dbo.OneTwo AS TINYINT START WITH 1 INCREMENT BY 1 MINVALUE 1 MAXVALUE 2 SELECT NEXT VALUE FOR dbo.OneTwo SELECT NEXT VALUE FOR dbo.OneTwo
This code creates a sequence and then selects 2 values. The min and max are set, so if I get another value, I'll get an error.
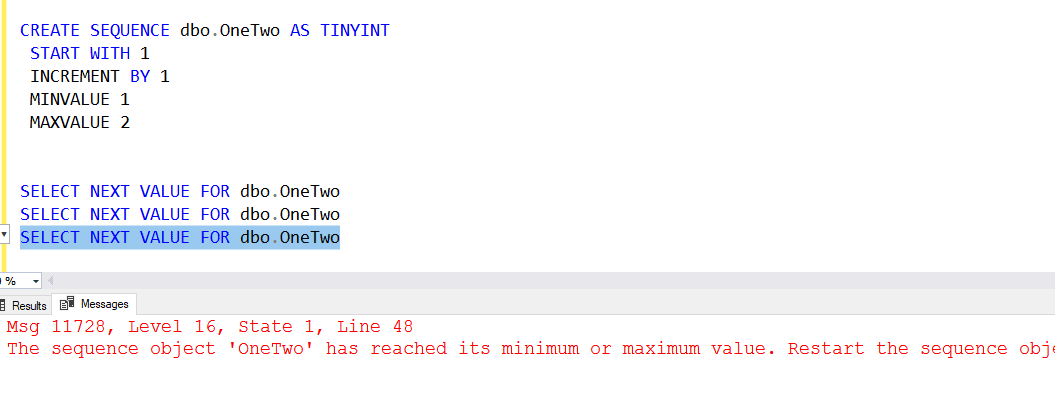
Note there is the ability to restart the sequence, so this is something to think about. I'll look at this in another article, but for now, note that setting a min and max gives you control, but it could cause errors, so be careful about setting these too right.
There is another option. I have another parameter that will allow me to avoid this error. I can set a cycle capability. I do this by choosing the add CYCLE or NO CYCLE to the sequence. The default is above (no cycle), but let's recreate the dbo.OneTwo sequence and add CYCLE to it. Look what happens when I get a number of values.
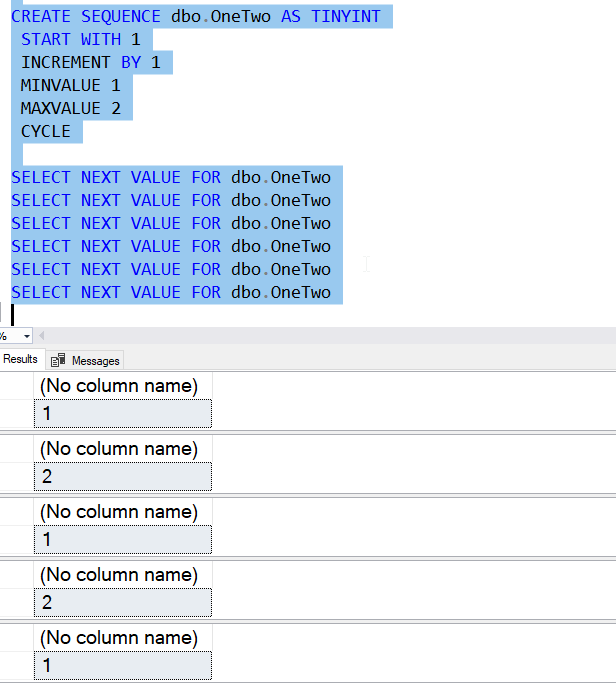
I can get alternating values. I could see this useful in some places where I want a cyclical rotation of things. It's like ROW_NUMBER(), but not bound to a query.
The last option is the CACHE option, which allows SQL Server to keep some values in memory. I can specify a size if I want, or let SQL Server pick one. There is a warning that an unexpected shutdown might mean that some sequence values are lost. The cache dies and the system assumes those values were allocated. That's disconcerting, but if it could be a problem for your application, I might choose the NO CACHE option.
Those are the parameters now, so let's look at how to use a sequence in a table.
Using a Sequence in CREATE TABLE
One of the things that we want to do with sequences is use them as a PK in a table. Greg Low wrote about the advantages, and I added my thoughts, wanting to experiment with this. This is one of the results of my experimentation, finding a few ways to use a sequence. I'll start by creating a sequence for a table that I want to create. I often work in my Simple Talk sample database, and I'm always adding tables. In this case, I'll add the Employee table, but I want to start by creating a sequence object. Let's do that with this code:
CREATE SEQUENCE dbo.EmployeePrimaryKey AS INT START WITH 1 MINVALUE 1 INCREMENT BY 1; GO
Now that I have the object, let's create the table. In this case, I'll use this as the default for my PK.
CREATE TABLE Employee
(
EmployeeKey INT NOT NULL
CONSTRAINT EmployeePK PRIMARY KEY
DEFAULT NEXT VALUE FOR dbo.EmployeePrimaryKey
, EmployeeName VARCHAR(200)
, Active TINYINT
);
GO
NOTE: The sequence doesn't have to be the PK. The auto-incrementing number and a key are two separate concepts.
Now, when I insert values into this table, I can do it like this:
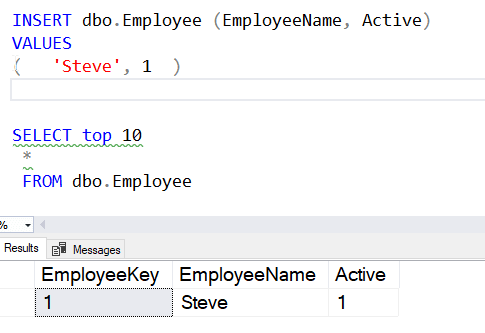
INSERT dbo.Employee (EmployeeName, Active) VALUES ( 'Steve', 1 )
This puts the value in the table for me:
What if I insert multiple rows? This works as well:
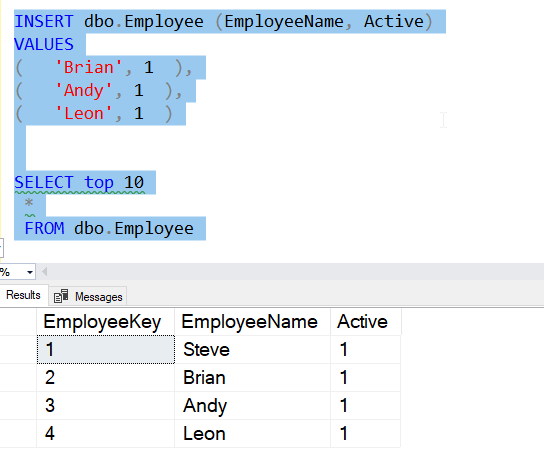
Each row has the value we'd expect here. However, this creates a system named default, which is what we don't usually want. System named objects cause me issues when I try to move code from one environment to the next. When I query my defaults, I see this:
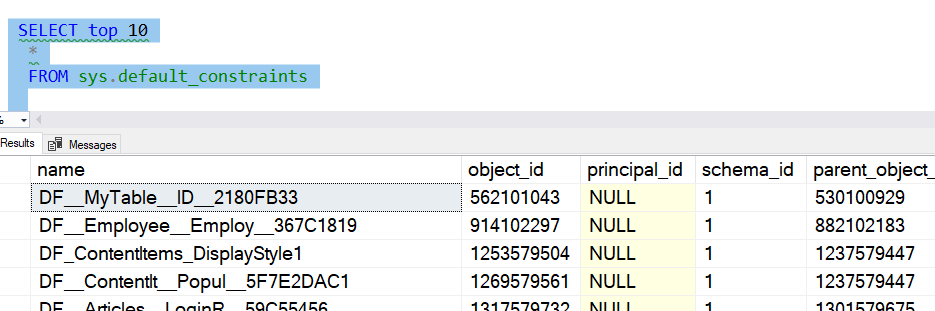
The second item in this list is the default created for this table. That's not what I want, so instead, what I'd want to do is I would redo this work. Changing this in a live system is another article, but in a development system, I'd recreate the table like this:
CREATE TABLE Employee
(
EmployeeKey INT NOT NULL
CONSTRAINT EmployeePK DEFAULT NEXT VALUE FOR dbo.EmployeePrimaryKey PRIMARY KEY
, EmployeeName VARCHAR(200)
, Active TINYINT
);
GOI now see what I want for a PK.
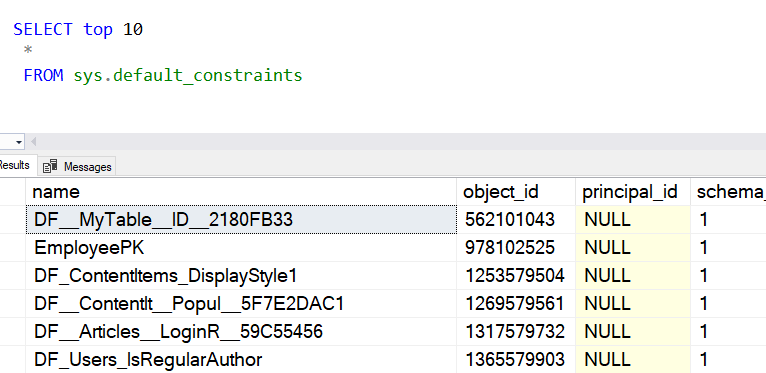
It appears I need the default next to the constraint to get the naming set.
If I already have a table, then the ALTER TABLE statement is flight different. For example, I have a table with a primary key already set.
CREATE TABLE StatusLookup
(
StatusKey INT NOT NULL
CONSTRAINT StatusPK PRIMARY KEY
, StatusValue VARCHAR(20)
, Active TINYINT
);
Now I want to make a default for this StatusKey, ensuring that new values will have the proper value. There are already four rows in the table, so I can set the sequence to start at the right time.
CREATE SEQUENCE dbo.StatusPKSequence AS INT START WITH 5 INCREMENT BY 1
Now I want to create a default for this existing table with that sequence. I use the ALTER TABLE with the ADD CONSTRAINT DDL to do this. As with the statement above, I'll add the default name and point this to my existing sequence.
ALTER TABLE dbo.StatusLookup
ADD CONSTRAINT df_StatusPrimaryKey
DEFAULT NEXT VALUE FOR dbo.StatusPKSequence FOR StatusKey;
Now if I insert a new value, I'll see the proper sequence.
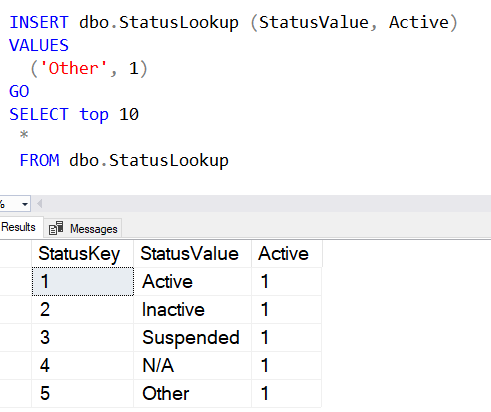
I have the values I want as a default for this existing table.
A Few Note About Sequences
These are the basics of binding a sequence to your columns, depending on whether you are creating a new table or altering an existing one. Since these are separate objects from the table, their binding can be a bit hidden, so I have a few random notes on things to consider when using sequences.
Finding Sequences in SSMS
One of the first things that you might want to know is what sequences are in my database. There is a folder in the Object Explorer in SSMS that displays the sequences. Under the Programmability folder, there is a Sequences folder. This is shown below, with all the of the test sequences I've been experimenting with listed.
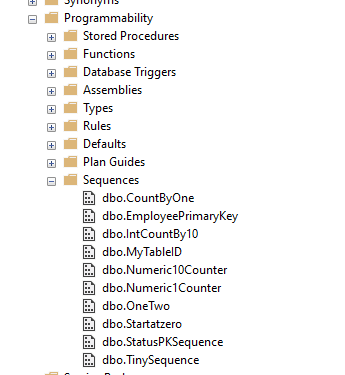
As with many other objects, these are listed alphabetically by schema and object name. If I right click any of these, I can get the properties of the object itself. While I see many of the parameters used to create the sequence, and the current value, I don't see where the schema is being used.
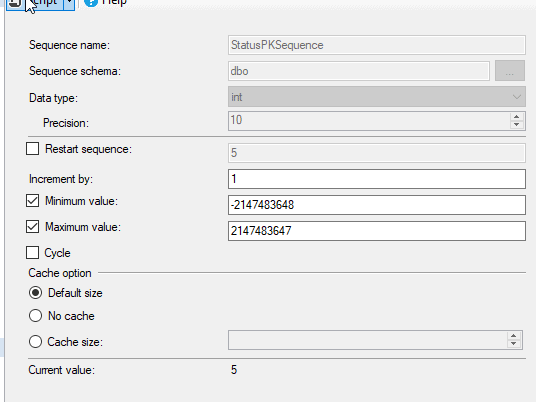
I can look at my table, and I see the primary key and constraints, but I don't see any properties. I need to script out the constraint to see the sequence binding, a somewhat cumbersome task.
Querying DMVs for Sequences
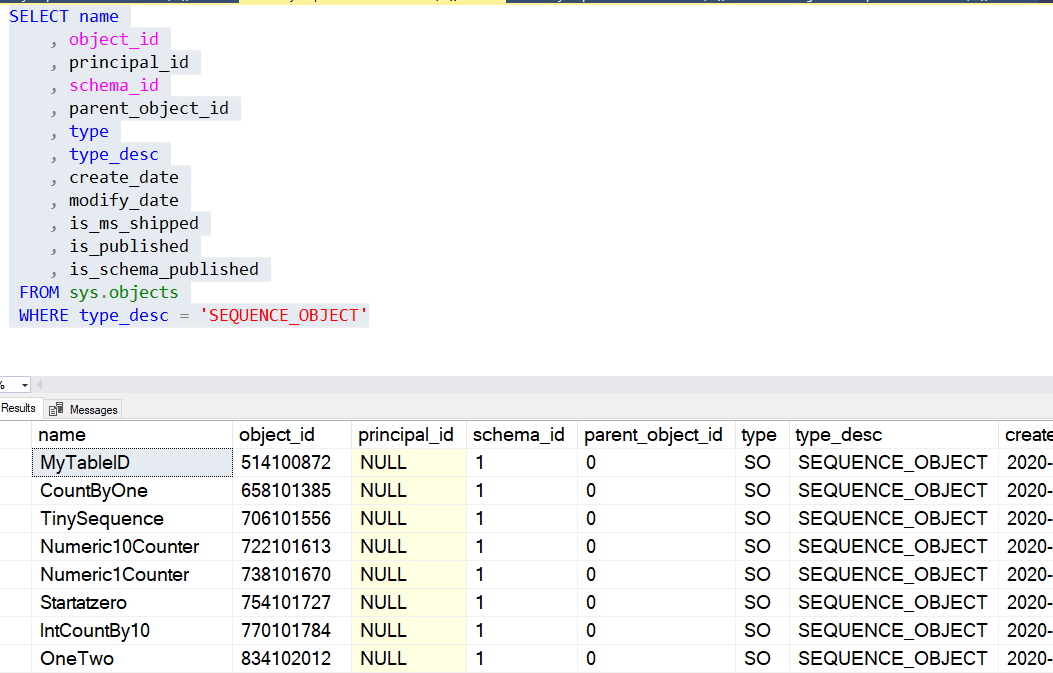
There are a number of ways to query for sequences in the system DMVs. First, this is an object, and appears in sys.objects. I can query for sequences with this code:
SELECT name
, object_id
, principal_id
, schema_id
, parent_object_id
, type
, type_desc
, create_date
, modify_date
, is_ms_shipped
, is_published
, is_schema_published
FROM sys.objects
WHERE type_desc = 'SEQUENCE_OBJECT'I will see all my test sequence objects in the results.
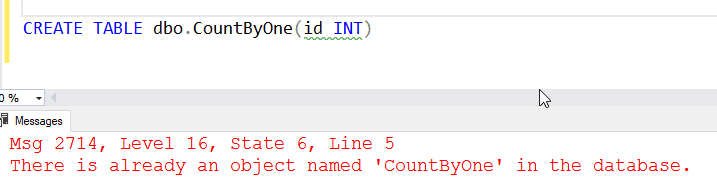
This also means that if I try to create another object with the same name, I see an error.
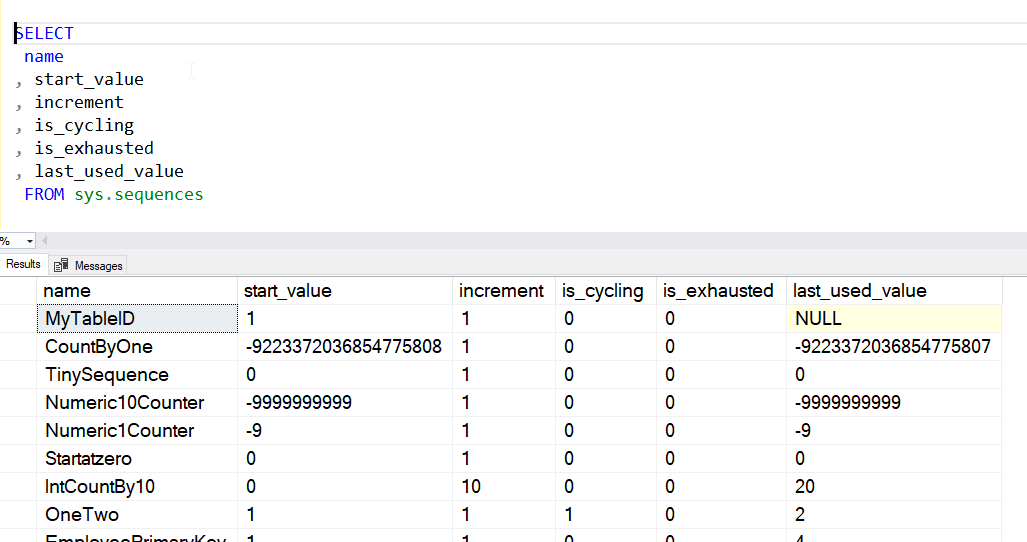
There also is a sys.sequences, which seems to be the basis for populating the properties in SSMS. This inherits from sys.objects, so it has the same columns as that DMV with some additional items added.
If I look at the results, I see the start value, increment, and other parameters I can use in the DDL. I also get the data type precision and scale (always 0), as well as the current value. This is the last value assigned with the NEXT VALUE FOR call, or the sp_sequence_get_range procedure. There is a "is_exhausted" column that is set if there are no more values. You can also get the last_used_value in SQL 2017 (14x.)+. In the image below, I only return a few columns.
Naming and Keeping Sequences Organized
Sequences can quickly become numerous in your environment if you are using them as ways to populate columns. Since these objects are not tied or linked to any other object in an obvious way, it becomes important that you have some documentation for how the sequences fit in your application. These can be used with tables, or with calls in queries to generate a sequence of numbers, so it behooves you to ensure all developers understand their usage.
Naming is one of the first recommendations I have. My suggestion is that you name the sequence with a few pieces of information. We have a long string for an identifier, so take advantage of that. If this will be an identity replacement, then use the table name and some indicator of this as a PK. Note that this name cannot collide with the PK constraint name, so develop a naming standard for both of these early when you use them. If this sequence is used for some specific purpose in application queries (or procs, functions, etc.), then use a descriptive name. The value from information transfer outweighs any small issue in typing a long name.
The second recommendation I have is that you take advantage of extended properties for sequences. You have the ability to add extended properties to the object, as you do with many other objects. I would suggest using the MS_Description as that has become a standard place to document purposes and is picked up by many third party tools. If you have other information you would like to add, you can apply additional properties, but I would keep this to a minimum as the more work required when creating an object, the more likely someone will skip steps. I highly suggest you use templates or SQL Prompt snippets to keep the sequence creation code, as well as the extended property call to make the documentation easy for developers.
Summary
This is a basic look at how sequences work and how they can be applied to a table as a replacement for the identity property. This isn't a recommendation to do so, as there can be lots of reasons to use, or not use, sequences. They do provide an easy way to control what values are applied, and even to limit or cycle values if that is something you need.
A future article will look at some of the implications and issue with using sequences and more complex interactions between the sequence and your data.
Resources
- SQL Server Sequence Basics - https://www.red-gate.com/simple-talk/sql/learn-sql-server/sql-server-sequence-basics/
- Sequences in SQL Server 2012 - https://www.sqlservercentral.com/articles/sequences-in-sql-server-2012
- Sequence Numbers (BOL) - https://docs.microsoft.com/en-us/sql/relational-databases/sequence-numbers/sequence-numbers?view=sql-server-ver15
- CREATE SEQUENCE (BOL) - https://docs.microsoft.com/en-us/sql/t-sql/statements/create-sequence-transact-sql?view=sql-server-ver15#arguments
- ALTER SEQUENCE (BOL) - https://docs.microsoft.com/en-us/sql/t-sql/statements/alter-sequence-transact-sql?view=sql-server-ver15
- sys.sequences (BOL) - https://docs.microsoft.com/en-us/sql/relational-databases/system-catalog-views/sys-sequences-transact-sql?view=sql-server-ver15

