

In the first article in this series, I referenced Jeff Moden's excellent article on the Tally table. Here's a second way the concept really helped me out.
What's really in that text?
I was setting up some look-up tables for out databases and figured I should use the international standards for country/country abbreviation and money/money abbreviation. I found the list for countries on Wikipedia. I copied the first 4 columns of the table, dropped them into Excel to clean them up and imported the result into a SQL Server table. I created the table and used the wizard to pull the data in.
The table for countries looks like this
CREATE TABLE Country (CountryAlpha char(2) NOT NULL PRIMARY KEY, LongAlpha char(3) NULL, NumberCode char(3) NULL, CountryName varchar(45) NULL)
I then found the list of Currency standards directly from the ISO and performed similar cleaning and import processes.
The table for currencies looks like this
CREATE TABLE Currency (CurrencyCode char(3) NOT NULL PRIMARY KEY, CurrencyName varchar(34) NULL, CurrNumberCode char(3) NULL)
However, I created a table for the raw currency data so I'd still have the countries for the association I'd perform later. I like to keep raw data that I may need to reference later in its own schema, in this case one called "Reference".
CREATE TABLE Reference.TempCurrency (Entity varchar(255), Currency varchar(34), AlphabeticCode char(3), NumericCode char(3))
Nice, simple tables. Note that NumberCode in the Country table and CurrNumberCode in the Currency table are both Char(3). The ISO apparently likes leading zeroes in their numbers. Not the way I'd go, but then I'm not an international standards commission. This has nothing to do with the tally table or the problem I was about to face, it is just an oddity.
Now that I had both tables, I figured I should normalize them. Some countries use multiple currencies and some currencies are used by multiple countries. This looked like a nice simple interim table to associate rows from each of the main tables.
My interim table is
CREATE TABLE CurrencyCountry (CountryAlpha char(2), CurrencyCode char(3), CONSTRAINT FK_CurrencyCountry_Country FOREIGN KEY (CountryAlpha) REFERENCES Country(CountryAlpha), CONSTRAINT FK_CurrencyCountry_Currency FOREIGN KEY (CurrencyCode) REFERENCES Currency(CurrencyCode) )
To populate it, I'd simply make a distinct list of currency types and then match on country name. I'd do a preliminary join on country name to see how close the names were and if there were a few that didn't match, I'd do a manual clean-up.
I created the query, ran it and got... nothing. No matches at all.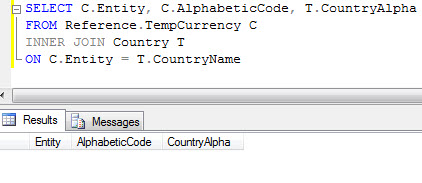
OK, I figured, there's probably trailing or leading spaces on one of the columns, I'll take care of that. I set up a RTrim(LTrim()) on the country columns and ran it again. This time I got... nothing. Again.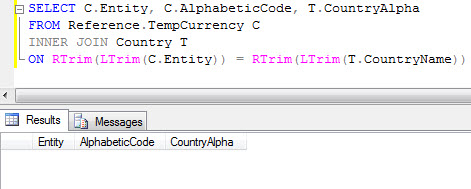
I looked at the columns and couldn't see why they weren't matching, it didn't look like there were any extra characters. I took out the possible leading and trailing spaces. Maybe there was something about case? Shouldn't be, but I've found "shouldn't be"s to be a problem before in many languages and systems. I dropped UPPER()s on the columns, ran it again and still got... nothing. I expected that this time, this was a shot in the dark.
I realized I needed a better tool to see what was really in the columns. I should look at every single character in the field so I can see what the problem is. I should also look at all the rows so I can see if it is a standard problem or if it is a varying problem that just happens to display in a similar way. Aha! The Tally Table. If it can parse the strings, it should be just as good at analyzing the strings.
In case you haven't read the first part in this series, lets create the Tally table again.
SELECT Top 20000 IDENTITY(INT,1,1) as N INTO Tally FROM master.dbo.syscolumns SC1, master.dbo.syscolumns SC2
Then add a primary key to the table
ALTER TABLE Tally ADD CONSTRAINT PK_Tally_N PRIMARY KEY CLUSTERED (N) WITH FILLFACTOR=100
This is the method shown by Mr. Moden in the article referenced at this beginning of this article. You really should read it. This is blazing fast. Details for this iteration are in my first article, and for his iteration (he gets 11000 rows) in his article. As I pointed out before, 11000 really is likely enough for most uses.
As I stated above, I wanted to look at every character in every row. I suppose I could use a cursor to loop through the rows and use the tally table to check each row, but that kind of defeats the purpose! My first thought was to create a variable, populate it and parse it, but this only gets one row. Fortunately, Mr. Moden had already provided me with the answer right in the query to create the Tally table: A Cross Join.
The statement
FROM table1, table2
Is an implied cross join. It will join every row to every row, perfect.
I created the query
SELECT N as position, SUBSTRING(CountryName, N, 1) as letter FROM Tally, Country
And it worked great! Except for one thing, I was getting 20,000 rows back for each country. Try again, adding a Where clause to stop each listing when the value from CountryName = ''
SELECT N as position, SUBSTRING(CountryName, N, 1) as letter FROM Tally, Country WHERE SUBSTRING(CountryName, N, 1) < >'' ORDER BY CountryName
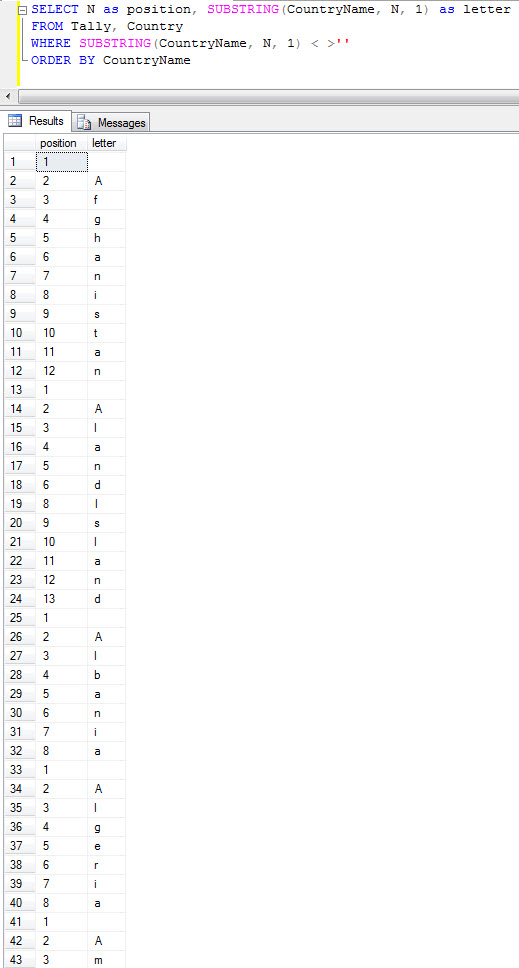
Much better, now I could see each country after the other, one letter at a time. Sure enough, there was something at the beginning of each row! What was it? Let's add a column to our query and check the ASCII values of each position.
SELECT N as position, SUBSTRING(CountryName, N, 1) as letter, ASCII(SUBSTRING(CountryName, N, 1)) as asciival FROM Tally, Country WHERE SUBSTRING(CountryName, N, 1) < >'' ORDER BY CountryName
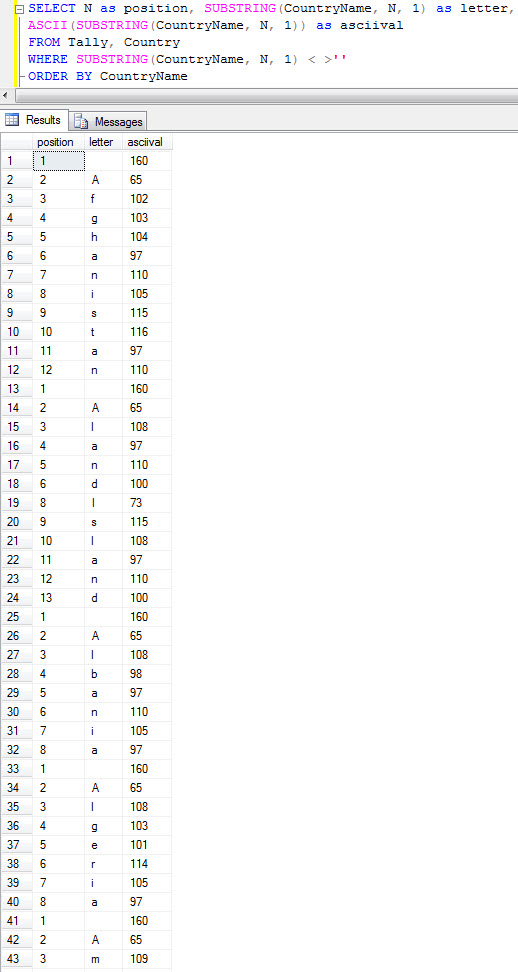
And there is it. Value 160. I had to go look up what it was. At this link: scroll down to the third table and you'll see the culprit. A non-breaking space. Other sites (At that previous link) list char 160 as á, but a non-breaking space fits better with the visual evidence, the ASCII equivalent shown in Word and   is pretty common in web coding.
I ran another check to make sure that was the case for every row
SELECT N as position, SUBSTRING(CountryName, N, 1) as letter, ASCII(SUBSTRING(CountryName, N, 1)) as asciival FROM Tally, Country WHERE N = 1 ORDER BY CountryName
And it was
Now that I knew the character, I could get rid of it with a scalpel instead of a sledgehammer.
UPDATE Country SET CountryName = REPLACE(CountryName, CHAR(160), '')
And suddenly, everything works!
