

Introduction
This is Part 1 of a 6-part series on N-Grams. The concept of N-Grams is very important for data professionals such as SQL and BI Developers, DBAs, and Data Scientists interested in staying ahead of the curve. N-Grams functions are used for data cleansing, text mining, text prediction, sentiment analysis, machine learning (e.g. Cortana Intelligence,) statistical natural language processing and developing language models. Even Microsoft Data Quality Services includes an N-Grams CLR function. There’s a lot of information about N-Grams in R and Python but virtually nothing about the subject in SQL Server (or any RDBMS for that matter). The primary objective of this series is to change that.
This article is about a T-SQL character-level N-Grams function but I’ll also make a distinction between character-level and word-level N-Grams. We’ll review what the function does and how it works. I’ll show you how to use it against a table by leveraging APPLY, provide usage examples and conclude with some basic performance testing.
Part 2 of this series will be entirely devoted to real-world examples of N-Grams8K in action by splitting strings into unigrams and performing some basic data cleansing, text analysis and string manipulation. In Part 3 we’ll do a deep-dive into performance as we examine parallelism and a CLR version of the function. In Part 4 we’ll shift the focus to tokens longer than unigrams (AKA character-level bigrams, trigrams, 4-grams, etc.). In Part 5 we’ll explore word-level N-Grams as I introduce a word-level N-Grams iTVF and in Part 6 I’ll introduce a concept I call N-Gram Indexing.
Disclaimer
The T-SQL N-Grams function discussed herein uses a Tally Table. If you’re not familiar with Tally Tables or why people love them, I encourage you to read The "Numbers" or "Tally" Table: What it is and how it replaces a loop by SQL Server MVP Jeff Moden. It’s an easy read and vital for people who want to develop high-performing SQL code. For even more details about Tally Tables, see Tally Tables in T-SQL by Dwain Camps.
Introducing NGrams8K
NGrams8K is an inline tabled valued function (iTVF) that accepts a varchar input string up to 8,000 characters long and splits it into N-sized substrings, AKA tokens. It works on SQL Server 2008+ and can be used for tasks as simple as counting characters and words, or for things as complex as performing a comparative analysis of whole-genome protein sequences. I developed a varchar(8000) version because it was best suited for my needs. Attached at the end of this article are a couple variations of the function: one that supports varchar(max) and one compatible with SQL Server 2005.
What is an N-Gram?
The best definition I’ve seen is actually on the Wikipedia N-Gram page:
…an n-gram is a contiguous sequence of n items from a given sequence of text or speech. The items can be phonemes, syllables, letters, words or base pairs according to the application... An n-gram of size 1 is referred to as a "unigram"; size 2 is a "bigram"; size 3 is a "trigram". Larger sizes are sometimes referred to by the value of n, e.g., "four-gram", "five-gram", and so on.
The two most common types of N-Grams, by far, are (1) character-level, where the items consist of one or more characters and (2) word-level, where the items consist of one or more words. The size of the item (or token as it’s often called) is defined by n; moving forward I’ll use the term, token. Throughout this article I use the terms unigrams, bigrams, trigrams, 4-grams, etc.; remember that these are types (sizes) of N-Grams.
Character-Level N-Grams
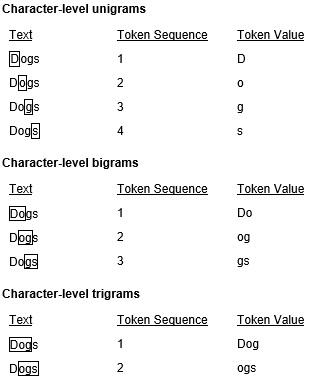
The concept of character-level NGrams is best explained through example so let’s split the word, “Dogs” into character-level unigrams, bigrams and trigrams.
Figure 1: Character-level unigrams, bigrams and trigrams
Word-Level N-Grams
We don’t cover word-level N-Grams until Part 5 of this series but I should make a distinction between character-level and word-level N-Grams now so as to avoid confusion moving forward. The “dogs” example above demonstrates what character-level N-Grams are, now let’s split the text, “One Two Three Four” into word-level N-Grams:
Figure 2: Word-level unigrams, bigrams and trigrams

These examples should demonstrate the difference between character-level and word-level N-Grams.
What NGrams8K does
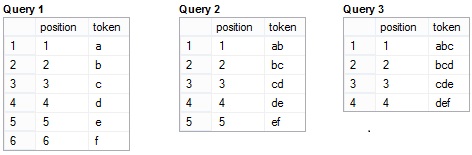
NGrams8K takes two parameters: an input string (@string) and a requested token size (@N). It then splits the value of @string into a contiguous sequence of @N-sized tokens. Let’s use the function to split the text “abcdef” in to unigrams, bigrams and trigrams:
Unigrams, Bigrams and Trigrams
SELECT position, token FROM dbo.NGrams8K('abcdef',1); --Query 1 (unigrams)
SELECT position, token FROM dbo.NGrams8K('abcdef',2); --Query 2 (bigrams)
SELECT position, token FROM dbo.NGrams8K('abcdef',3); --Query 3 (trigrams)Figure 3: NGrams8K unigram, bigram and trigram results for “abcdef”
How it works
At a high level NGrams8K does three things:
1. Generates a CTE Tally Table with exactly enough rows to return the correct number of tokens
2. Uses the CTE Tally Table to step through the input string returning each token and its position in the string
3. Provides protection against bad parameter values
The CTE Tally Table (iTally)
In the article Tally Tables in T-SQL Dwain Camps demonstrates how to create a CTE Tally Table using the Table Value Constructor (note the Tally Tables in SQL 2008 section). I also use the Table Value Constructor but do so a little differently. I start with 90 dummy values and perform only one CROSS JOIN to generate 8100 values (enough to handle 8,000 characters or less). This reduces the number of “Nested Loops” operators in the execution plan making it easier to read and analyze. Here’s my CTE Tally Table logic:
WITH L1(N) AS
(
SELECT 1
FROM (VALUES
(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),
(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),
(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),
(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),
(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),
(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),
(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),
(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),
(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL)
) t(N)
),iTally(N) AS
(
SELECT TOP (<required number of rows>) ROW_NUMBER() OVER (ORDER BY (SELECT NULL))
FROM L1 a CROSS JOIN L1 b
)… Understanding the TOP clause
For optimal performance our CTE Tally Table (mine is named iTally) should only return enough rows to satisfy our query. If X is the length of the input string and N is the requested token size, the formula to calculate the correct number of tokens is: X-(N-1). That’s why splitting “abcd” into unigrams (N=1) creates four tokens: a,b,c,d; for bigrams (N=2) we get three tokens: ab, bc, cd; and for trigrams (N=3) we get two: abc, bcd.
The number of rows returned by iTally is determined by a TOP clause. Applying the X-(N-1) formula we start with: DATALENGTH(@string)-(@N-1). Then we convert the expression to bigint to avoid an implicit conversion. Now we have: CONVERT(BIGINT,(DATALENGTH(@string)-(@N-1)),0). Next we add ISNULL logic to the @string and @N parameters to handle NULL inputs.Now we have: CONVERT(BIGINT,(DATALENGTH(ISNULL(@string,''))-(ISNULL(@N,1) -1)),0). If @N is greater than the length of @string then a negative value will get passed to the TOP clause causing an error; to prevent this we wrap the expression in an ABS function to guarantee a positive number. Now our TOP clause looks like this: ABS(CONVERT(BIGINT,(DATALENGTH(ISNULL(@string,''))-(ISNULL(@N,1)-1)),0)).
Inside iTally the TOP clause looks like this:
…,iTally(N) AS
(
SELECT TOP (ABS(CONVERT(BIGINT,(DATALENGTH(ISNULL(@string,''))-(ISNULL(@N,1)-1)),0)))
ROW_NUMBER() OVER (ORDER BY (SELECT NULL))
FROM L1 a CROSS JOIN L1 b
)…If you’re asking, “wait, if @N is greater than the length of @string, the ABS function will prevent an error but return bogus results instead; how’s that better?” Great question! We’ll come back to that.
Retrieving each token and its position
In Jeff Moden’s aforementioned Tally Table article he demonstrates how to “split” a delimited string using a Tally Table instead of a loop. Part of this involves using the Tally Table to “step through” each character in the input string and identify the location of the delimiters. This information is then used to “split” the string into tokens (which he refers to as items). The items are retrieved based on the location of the delimiters.
With NGrams8K, iTally splits the input string into a contiguous series of @N-sized tokens. Think of NGrams8K as a different type of “splitter”; it doesn’t see a string as a series delimiters and elements but rather as only a series of @N-sized elements retrieved based on each elements’ location in the string.
T-SQL SUBSTRING accepts three parameters: an input string, a start position and length. To retrieve each token and it’s position NGrams8K uses this expression: SUBSTRING(@string,N,@N). @string represents the input string, N represents the start position and @N represents the length. iTally returns the numbers 1 through (DATALENGTH(@string)-(@N-1)) as N. For each row that iTally returns, @string and @N remain the same but N always starts at 1 and increases by 1. Here’s how we use iTally to split the input string “abcd” into unigrams, bigrams and trigrams.
DECLARE @string varchar(100) = 'abcd', @N int = 1; -- @N = 1 for unigrams … SELECT Position = N, token = SUBSTRING(@string,N,@N) FROM iTally;
Figure 4a: SUBSTRING(@string, N, 1) Results
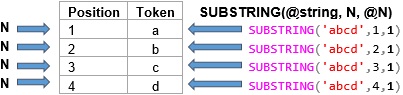
If we change @N to 2 for bigrams...
Figure 4b: SUBSTRING(@string, N, 2) Results

If we change @N to 3 for trigrams:
Figure 4c: SUBSTRING(@string, N, 3) Results

This is how a CTE Tally Table and SUBSTRING function work together to split a string into @N-sized tokens. There’s just one last thing to address before we create the function and look at examples…
Protecting against bad parameter values
As mentioned earlier, the DATALENGTH(@string)-(@N-1) formula only works when @N is between 1 and the length of @string. If @N is 0 or less, the function returns incorrect data or throws an “A TOP N value may not be negative…” error. If @N is greater than the length of @string (e.g. @string = “xxx” and @N = 20), the function also returns bad results. That’s why we include this filter: WHERE @N > 0 AND @N <= DATALENGTH(@string). Now, when @N is 0 or less, greater than the length of @string, or NULL, nothing is returned. Our WHERE clause acts like an On/Off switch and only allows the function to continue processing when our @N and @string parameters are acceptable.
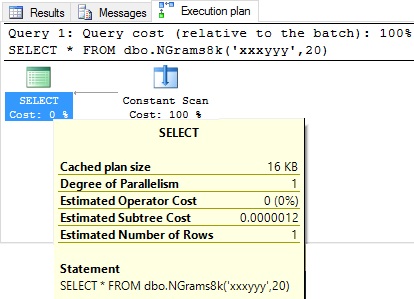
This also resolves the problem raised earlier with the ABS function causing a bogus value to be passed to our TOP clause. Logical Query Processing dictates that WHERE clauses are processed before TOP clauses and, unless @N is between 1 and the length of @string, the TOP clause is never evaluated. Check out the very inexpensive execution plan produced by this query: SELECT * FROM dbo.NGrams8k('xxxyyy',20);
Figure 5: Bad parameter input query plan
Note that, if @N or @string are NULL the function returns 0 rows. In the function’s comments I include code you can add if you prefer that it return a single NULL value for NULL inputs.
The Function
Now that you know how it works, let’s wrap it up in an iTVF. Without further ado, NGrams8K…
CREATE FUNCTION dbo.NGrams8k
(
@string varchar(8000), -- Input string
@N int -- requested token size
)
/****************************************************************************************
Purpose:
A character-level N-Grams function that outputs a contiguous stream of @N-sized tokens
based on an input string (@string). Accepts strings up to 8000 varchar characters long.
For more information about N-Grams see: http://en.wikipedia.org/wiki/N-gram.
Compatibility:
SQL Server 2008+, Azure SQL Database
Syntax:
--===== Autonomous
SELECT position, token FROM dbo.NGrams8k(@string,@N);
--===== Against a table using APPLY
SELECT s.SomeID, ng.position, ng.token
FROM dbo.SomeTable s
CROSS APPLY dbo.NGrams8K(s.SomeValue,@N) ng;
Parameters:
@string = The input string to split into tokens.
@N = The size of each token returned.
Returns:
Position = bigint; the position of the token in the input string
token = varchar(8000); a @N-sized character-level N-Gram token
Developer Notes:
1. NGrams8k is not case sensitive
2. Many functions that use NGrams8k will see a huge performance gain when the optimizer
creates a parallel execution plan. One way to get a parallel query plan (if the
optimizer does not choose one) is to use make_parallel by Adam Machanic which can be
found here:
sqlblog.com/blogs/adam_machanic/archive/2013/07/11/next-level-parallel-plan-porcing.aspx
3. When @N is less than 1 or greater than the datalength of the input string then no
tokens (rows) are returned. If either @string or @N are NULL no rows are returned.
This is a debatable topic but the thinking behind this decision is that: because you
can't split 'xxx' into 4-grams, you can't split a NULL value into unigrams and you
can't turn anything into NULL-grams, no rows should be returned.
For people who would prefer that a NULL input forces the function to return a single
NULL output you could add this code to the end of the function:
UNION ALL
SELECT 1, NULL
WHERE NOT(@N > 0 AND @N <= DATALENGTH(@string)) OR (@N IS NULL OR @string IS NULL)
4. NGrams8k can also be used as a Tally Table with the position column being your "N"
row. To do so use REPLICATE to create an imaginary string, then use NGrams8k to split
it into unigrams then only return the position column. NGrams8k will get you up to
8000 numbers. There will be no performance penalty for sorting by position in
ascending order but there is for sorting in descending order. To get the numbers in
descending order without forcing a sort in the query plan use the following formula:
N = <highest number>-position+1.
Pseudo Tally Table Examples:
--===== (1) Get the numbers 1 to 100 in ascending order:
SELECT N = position
FROM dbo.NGrams8k(REPLICATE(0,100),1);
--===== (2) Get the numbers 1 to 100 in descending order:
DECLARE @maxN int = 100;
SELECT N = @maxN-position+1
FROM dbo.NGrams8k(REPLICATE(0,@maxN),1)
ORDER BY position;
5. NGrams8k is deterministic. For more about deterministic functions see:
https://msdn.microsoft.com/en-us/library/ms178091.aspx
Usage Examples:
--===== Turn the string, 'abcd' into unigrams, bigrams and trigrams
SELECT position, token FROM dbo.NGrams8k('abcd',1); -- unigrams (@N=1)
SELECT position, token FROM dbo.NGrams8k('abcd',2); -- bigrams (@N=2)
SELECT position, token FROM dbo.NGrams8k('abcd',3); -- trigrams (@N=3)
--===== How many times the substring "AB" appears in each record
DECLARE @table TABLE(stringID int identity primary key, string varchar(100));
INSERT @table(string) VALUES ('AB123AB'),('123ABABAB'),('!AB!AB!'),('AB-AB-AB-AB-AB');
SELECT string, occurances = COUNT(*)
FROM @table t
CROSS APPLY dbo.NGrams8k(t.string,2) ng
WHERE ng.token = 'AB'
GROUP BY string;
----------------------------------------------------------------------------------------
Revision History:
Rev 00 - 20140310 - Initial Development - Alan Burstein
Rev 01 - 20150522 - Removed DQS N-Grams functionality, improved iTally logic. Also Added
conversion to bigint in the TOP logic to remove implicit conversion
to bigint - Alan Burstein
Rev 03 - 20150909 - Added logic to only return values if @N is greater than 0 and less
than the length of @string. Updated comment section. - Alan Burstein
Rev 04 - 20151029 - Added ISNULL logic to the TOP clause for the @string and @N
parameters to prevent a NULL string or NULL @N from causing "an
improper value" being passed to the TOP clause. - Alan Burstein
****************************************************************************************/RETURNS TABLE WITH SCHEMABINDING AS RETURN
WITH
L1(N) AS
(
SELECT 1
FROM (VALUES -- 90 NULL values used to create the CTE Tally Table
(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),
(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),
(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),
(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),
(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),
(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),
(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),
(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),
(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL)
) t(N)
),
iTally(N) AS -- my cte Tally Table
(
SELECT TOP(ABS(CONVERT(BIGINT,(DATALENGTH(ISNULL(@string,''))-(ISNULL(@N,1)-1)),0)))
ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) -- Order by a constant to avoid a sort
FROM L1 a CROSS JOIN L1 b -- cartesian product for 8100 rows (90^2)
)
SELECT
position = N, -- position of the token in the string(s)
token = SUBSTRING(@string,CAST(N AS int),@N) -- the @N-Sized token
FROM iTally
WHERE @N > 0 AND @N <= DATALENGTH(@string); -- Protection against bad parameter values
GOUsing NGrams8K with APPLY
To use NGrams8K against values in a table you need to understand the APPLY table operator. For an excellent overview of APPLY see Understanding and Using APPLY Part 1 and Part 2 by SQL Server MVP Paul White. For a quick NGrams8K specific overview let’s look at the examples below. In these examples we’re splitting strings from a table into unigrams. Each string has an associated StringID which allows us to identify where the token came from.
-- Sample data DECLARE @strings TABLE (StringID int, String varchar(10)); -- table to hold sample values INSERT @strings VALUES (1,'abc'),(2,'xyz'),(3,''); --sample values (note the empty 3rd string) -- Passing String values to NGrams8K from the @strings table variable using CROSS APPLY SELECT StringID, position, token FROM @strings s CROSS APPLY dbo.NGrams8K(string,1); -- @N=1 for unigrams. -- Passing String values to NGrams8K from the @strings table variable using OUTER APPLY SELECT StringID, position, token FROM @strings s OUTER APPLY dbo.NGrams8K(string,1); -- @N=1 for unigrams.
Figure 6: CROSS APPLY and OUTER APPLY Results

Unlike CROSS APPLY, OUTER APPLY returns a NULL value for the empty string (where StringID = 3).
Basic NGrams8K examples
Below are a few basic examples of NGrams8K in action. These examples build off of each other in a way that should help you appreciate the power of a good N-Grams function. I won’t go into extensive detail on how each solution works, instead I encourage you to play around with and reverse engineer my code. Many more useful real world examples will be included in Part 2 and Part 4 of this series. Note that NGrams8K is not case sensitive and, for brevity, I hold off on this topic until Part 2.
Counting characters
The ability to “tokenize” text allows you to analyze it new ways. In the example below we’re retrieving a count of all alphabetical characters in a string.
DECLARE @string varchar(100)='The quick green fox jumps over the lazy dog.'; SELECT token, COUNT(token) AS ttl -- get each alphabetical token & the # of occurrences FROM dbo.NGrams8K(@string,1) -- split @string into unigrams (@string,1) WHERE token LIKE '[a-z]' -- only include alphabetical characters GROUP BY token ORDER BY token; -- not required, included for display & learning purposes
This tells me how many times each alphabetical character appears in the string (a=1, c=1, d=1, e=5, etc.)
Filtering rows based on a character count
Building off the previous example let’s say we needed to only return records that contained 3 to 5 instances of the letter ‘b’. Furthermore, we’re required to rank each string based on the how many times the letter ‘b’ appears (the more times the letter ‘b’ appears, the better the ranking.) Here’s how we’d do it using NGrams8K.
-- Sample data:
DECLARE @Strings TABLE (StringID int identity primary key, String varchar(20));
INSERT @Strings(String)
VALUES ('abc123bb'),('xxxx'),('bbbbb'),('ababcabcab'),('aabbxx'),('bbb');
-- Solution:
SELECT StringID, String, Ranking = DENSE_RANK() OVER (ORDER BY COUNT(*) DESC)
FROM @Strings s
CROSS APPLY dbo.NGrams8k(s.String,1)
WHERE token = 'b'
GROUP BY StringID, String
HAVING COUNT(*) BETWEEN 3 AND 5;Figure 7 – Filtering rows based on a character count results:
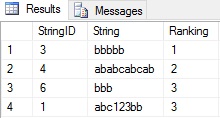
Notice that StringID 3 has the most b’s (five total) and is therefore ranked #1. StringID 4 has four b’s and is therefore ranked #2. Both StringID 6 & 1 have 3 b’s so their rankings are tied at #3.
Basic text analytics on resumes stored in a table
For this example, we have a table (@Candidates) which contains job candidate information including an ASCII text version of their resume. The requirement is to enable a recruiter to enter a keyword (@SearchString) and, along with the candidateID, return:
- How many times the keyword was found
- The position where the keyword occurs first
- A ranking of each candidate based on how many times the keyword is found. When two candidates have the same number of occurrences, the tie-breaker will be the earliest instance of the keyword in their resume.
This example builds off of the previous two but warrants some additional explanation. First, to find where @SearchString exists in the sample text, we use the length (LEN) of @SearchString as the NGrams8K @N parameter. Here, @SearchString is “SQL”; the query below will return the location of each instance of “SQL”.
DECLARE @SearchString varchar(100) = 'SQL',
@SampleTxt varchar(100) = '.. SQL this and SQL that...';
SELECT position
FROM dbo.NGrams8k(@SampleTxt, LEN(@SearchString))
WHERE Token = @SearchString;Now let’s take a sample table and APPLY the same logic to each record.
DECLARE @Candidates TABLE (CandidateID int identity primary key, ResumeTxt varchar(8000));
INSERT @Candidates(ResumeTxt) VALUES
('Joe Doe - Objective: To use my many years of SQL experience... blah blah SQL...
blah SQL this & SQL that...'),
('John Green, PMP, MSM - SQL Guru... yada yada SQL... blah blah blah...'),
('Sue Jones Objective: To utilize my awesome skills and experience... yada SQL...
blah SQL this & SQL that... more experience with SQL');
DECLARE @SearchString varchar(100) = 'SQL';
SELECT CandidateID, position
FROM @Candidates c
CROSS APPLY dbo.NGrams8k(ResumeTxt, LEN(@SearchString))
WHERE token = @SearchString;Using the same sample table, we’ll group by CandidateID. Now we can get the number of times @SearchString was found using COUNT(*) and the first occurrence of @SearchString using MIN(Position). For the candidate ranking we’ll use this expression: RANK() OVER (ORDER BY COUNT(*) DESC, MIN(Position)). Here’s the final solution:
-- sample data
DECLARE @Candidates TABLE (CandidateID int identity primary key, ResumeTxt varchar(8000));
INSERT @Candidates(ResumeTxt) VALUES
('Joe Doe - Objective: To use my many years of SQL experience... blah blah SQL...
blah SQL this & SQL that...'),
('John Green, PMP, MSM - SQL Guru... yada yada SQL... blah blah blah...'),
('Sue Jones Objective: To utilize my awesome skills and experience... yada SQL...
blah SQL this & SQL that... more experience with SQL');
-- Keyword parameter (a variable in this example)
DECLARE @SearchString varchar(100) = 'SQL'
-- The solution:
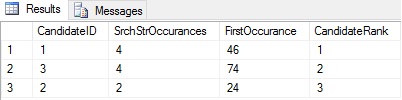
SELECT
CandidateID,
SrchStrOccurances = COUNT(*), -- How many times was @SearchString found in ResumeTxt?
FirstOccurance = MIN(Position), -- Location of the 1st occurance of @SearchString
CandidateRank = RANK() OVER (ORDER BY COUNT(*) DESC, MIN(Position))
FROM @Candidates c
CROSS APPLY dbo.NGrams8k(ResumeTxt, LEN(@SearchString))
WHERE token = @SearchString
GROUP BY CandidateID;Figure 8 – Filtering rows based on a character count results:
Performance
In Part 3 we’ll examine the performance of NGrams8K in greater detail including how it’s impacted by parallelism and how it compares to an N-Grams CLR. Until then, let me spare you the suspense, NGrams8K is the fastest character-level SQL N-Grams function available today (unless someone has a faster one?) For now, a basic test should suffice. Here we compare NGrams8K against functions which produce the same results developed using a loop and a recursive common table expression (rCTE). I did two 1,000 row iterations: first against strings 360 characters long, then against 1,800 characters. The performance test code is included as an attachment. The results speak for themselves.

Conclusion
We’ve been introduced to the topic of N-Grams and looked at why you should have a good N-Grams function at your disposal. We developed a set-based character-level N-Grams function without any loops, recursion, other iterative methods, or non-SQL language. We’ve seen how to use the function against a table using APPLY along with a few examples of NGrams8K in action. Another win for set-based programming has been recorded as we’ve again watched a function designed using a Tally Table make short work of it’s RBAR2-style counterparts …and we’re just getting started. Thank you so much for reading.
Resources
SQL Concepts:
The "Numbers" or "Tally" Table: What it is and how it replaces a loop – Jeff Moden
Tally Tables in T-SQL – Dwain Camps
Understanding and Using APPLY (Part 1) and Part 2 – Paul White
Logical Query Processing: What It Is And What It Means to You – Itzik Ben-Gan
N-Grams concepts:
Interesting Examples of N-Grams Functions in use:
Comparative ngram analysis of whole-genome protein sequences
Intrinsic Plagiarism Detection Using Character n-gram Profiles
N-Gram-Based Text Categorization
Exploring Web Scale Language Models for Search Query Processing
Micropinion Generation: An Unsupervised Approach to Generating Ultra-Concise Summaries of Opinions
Finding trending topics using Google Books n-grams data and Apache Hive on Elastic MapReduce
Footnotes
1 This is not entirely true when using the function with APPLY against a table. I will discuss this in more detail in part 3 of this series
2 RBAR is pronounced "ree-bar" and is a "Modenism" for "Row-By-Agonizing-Row"
