

I've been working on data projects recently in which a lack of understanding of the source data frustrated decision support and stalled progress. I’ve shared some simple techniques here which I used to help us get clarity on our source data and move forward.
One project involved the conversion of around 150,000 contact records to a new system. The legacy system did not include strong reporting or analysis tools, so I obtained an export and imported everything into SQL tables for further work.
Soon after, I found myself running ad hoc queries to answer questions from the project team, all on very similar topics - how many records of this type do we have, how useful or reliable is the data in these columns, and so on. At some point, to avoid further repetition, I refined my methods to produce the data below. These are all very simple measures, but they provide an excellent starting point for further analysis.
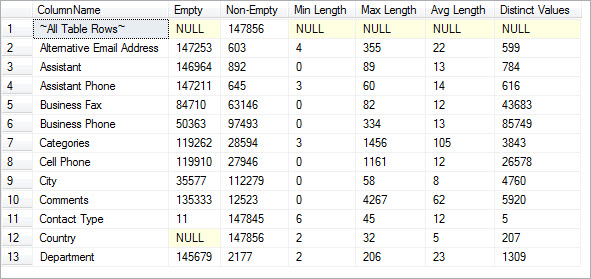
The first two columns, “Empty” and “Non-Empty” are self explanatory. With over 70 columns in the source data, these statistics helped us quickly focus on which of the 70 were worth our time and effort to clean up and convert. (Row 1 above is simply a count of all rows in the source table.)
The “Min Length”, “Max Length” and “Avg Length” provide helpful details in assessing how consistent column data is across all rows, and in identifying often important outliers. I would expect “Business Phone” data (Row 6) to be fairly consistent, and the average suggests it is, for a collection of predominately North American phone numbers. However, the “Max Length” for that row shows at least one serious outlier at 334 characters, which could indicate an import problem. In this case, we determined that the legacy system employed almost no data entry controls or limits, and many users had simply entered extraneous data into this field.
Finally, the “Distinct Values” column indicates how variable the data within each column is. Row 11, the “Contact Type” source field, draws my attention immediately. With so few distinct values, this was almost certainly a “selection list” field in the legacy system, one which constrained available choices for data in the field. This column, and any others like it, will very likely be useful in segmenting the data for further analysis.
The summary data above can be produced by brute force – for each source column, query for each of the measures above, store the results in a summary table, and use a PIVOT query to produce the report above. The challenge I had was to make the process repeatable, reasonably fast, and, if possible, generic, so that it could be used against any SQL table. The technique I arrived at is a master query that generates its own list of queries which perform all the work.
My master query generates a list of queries against the table being analyzed (Analysis Table), using the sys.columns table as a data source for column names. Each of the generated queries compiles a measurement on each of the Analysis Table’s column data into a summary table (“AnalysisTable_ColumnSummary”), per the example below:
--Query to produce select statements to update DISTINCT VALUE tallies for each column
SELECT 'INSERT INTO [dbo].[##TABLE##_ColumnSummary]
SELECT ''' + sc.Name + ''' AS [ColumnName],
''Distinct Values'' AS [Measure],
COUNT(DISTINCT [' + sc.Name + ']) AS [Value] FROM ##TABLE##
ORDER BY [ColumnName], [Measure]'
FROM dbo.sysobjects so
INNER JOIN dbo.syscolumns sc ON so.id = sc.id
WHERE so.xtype = 'U'
AND so.name = '##TABLE##'
ORDER BY sc.colorderThe master query includes all necessary queries to
- drop and recreate the “_ColumnSummary” table
- add rows of summary data to the “_ColumnSummary”
- PIVOT the results to produce the friendly summary shown above
When using this query, I begin by replacing the string ##TABLE## in the master query with the name of the Analysis Table I’m working with. (I have set this query to be read only in the file system, to prevent me overwriting the master.) I run these from SSMS, and note in the script comments that you should set results to Text (instead of Grid), with max characters per line to 999 in order to avoid any truncation problems. With NOCOUNT set to ON, you can simply copy the master query’s results into a new query window and execute to produce everything else.
Those more skilled in SQL than I am will no doubt recognize limitations and possible complications with these methods. I’m not a seasoned SQL developer or DBA, and I’ve found my own way into methods that work for my requirements, which are primarily for analysis. The results they produce are effective, and their simplicity makes them useful provided the source table is reasonably small. The ‘expense’ of these methods may well overwhelm their utility when working with extremely large tables.
I should also note that I am running these queries from a local instance of MS SQL Server 2008 R2 (dev edition), on a Dell E6410 laptop with an Intel SSD. The SSD was a life-changing upgrade which has largely removed any concerns I may have had about the 'expense' of a local query or how long it might take. I recognize that this is both good and bad, but it works so well for my purposes that it outweighs any potential down-sides. For example, producing the above summary from a source table with 73 columns and just under 150,000 rows took 31 seconds on my system, from start to finish.)
I use this query and its underlying methods often, and plan to improve on it in future. At present, the queries assume that all table columns are some variant of a text type, as I wrote it primarily to deal with imported data of varchar type, but this limits its usefulness in other situations. I would also like to amend it to include the creation of a separate schema which would help categorize this and other tables used for analysis (i.e. “stats”), and also avoid the danger (slim though it is) of affecting existing tables in the operation of these queries. I’d also very much like to encapsulate the whole thing into a function which would accept a [schema]. identifier as a parameter, returning the generated queries as a result.

