

Introduction
In this new SQL-On-Hadoop series of articles, we will continue exploring the benefits of distributed computing using your SQL Skillsets. We will learn how to run interactive and batch SQL queries on structured and semi-structured Big Data stored on Hadoop and other file storage systems using HiveQL,T-SQL and other Structured query options like Spark SQL.
In a previous article we learned that Hadoop is the most popular and cost-effective of the distributed computing systems designed to handle Big Data storage and computations. The Hadoop ecosystem runs on an efficient distributed file storage system known as HDFS. Hadoop however have some limitation;
- Distributed data means distributed computing which is tricky. Hadoop's MapReduce programing paradigm designed for such computations on HDFS is complicated.
- Besides the complexity of MapReduce, one have to be able to program in Java in other to write and implement native MapReduce jobs.
Led by Jeff Hammerbacher, the Facebook data team realized these limitations, they also realized their huge volumes of data that they were producing every day from their burgeoning social network for the most part had some structure, which meant that they could leverage SQL to do a chunk of value-driven analytics on this data. Therefore, to enable their analysts with strong SQL skills but limited or no Java programming skills to analyze this data on Hadoop, they built a data warehouse system called Hive and a SQL query dialect called HiveQL on top of Hadoop.
The same reasons that sparked Hive also gave rise to the many other commercial and open source SQL-On-Hadoop endeavors like Impala, Drill, Presto, etc. Today, SQL Server Polybase is one such system that enables Analysts, Developers and Data Scientist to query external Big Data files on HDFS using T-SQL.
In the next of the SQL-On-Hadoop series we will look at SQL Server Polybase, but in this two-part series we will explore Hive which was built directly on top of HDFS and the MapReduce framework.
- In Part I we will look at Hive architecture and its relational database features.
- In Part II we will look at HiveQL Queries and other advanced features.
Part I
In this part we will look at the internal relational database in the Hive architecture and how it interacts with Hadoop. We will also look at Hive Database objects data types and how to load data into Hive Tables.
Apache Hive
Hive was built as a data warehouse-like infrastructure on top of Hadoop and MapReduce framework with a simple SQL-like query language called HiveQL. While HiveQL is SQL, it does not strictly follow the full SQL-92 standard.
Hive Architecture
As you write HiveQL queries, under the hood, the queries are mostly converted to MapReduce jobs and executed on Hadoop.
Figure 1 below shows a high level view of Hive architecture and how it ships HiveQL queries to be executed as mostly as MapReduce jobs on Hadoop.
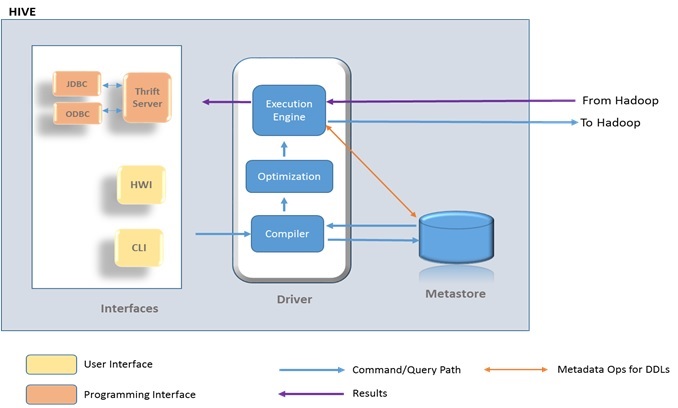
Figure 1: Showing a high level view of Hive architecture
Within Hive is a driver, which receives the queries/commands and then implements the notion of session handles and ultimately exposes execute and fetch APIs.
The Hive Metastore as indicated on Figure1 is a logical system consisting of a relational database (metastore database) and a Hive service (metastore service) that provides metadata access to Hive and other systems. By default, Hive uses a built-in Derby SQL Server database. This Database is normally sufficient for single process storage, however for clusters, MySQL or a similar relational database is required. You have the option of using SQL Server or other relational database as the metastore database.
Within the driver, the compiler component generates an execution plan by parsing queries using table metadata and necessary read/write information from the Metastore. The plan is optimized and then passed to the engine to execute the initial required steps and then sends other MapReduce to Hadoop. The execution engine delivers results (received from Hadoop and/or prepared locally) to the selected client interface.
Running Hive
Hive was primarily develop to run on Hadoop therefore to be able to run the SQL statements in the exercises that follows will require Hadoop set and Hive installation, however, except for some schema-on-read feature, most of the queries and techniques we explore should be familiar to folks on this forum so you can just tag along. To install Hive, you can download a release at http://hive.apache.org/releases.htm.
Most Hive distributions today may come with a command line Interface (CLI), a Hive Web Interface (e.g. Beeswax), and also a programmatic access through JDBC, ODBC and a Thrift server, which could be used to submit queries or commands.
You may use any of the interfaces that comes with your Hive distribution, but in the examples following, I will run all queries and commands interactively using the Hive CLI on my local Hadoop (The Microsoft HDInsight emulator distribution) installed on windows on my local machine. Hive may be configured to run against various versions of Hadoop and your local file system. Depending on your Hadoop and Hive distribution and OS (window or linux), the Hive and Hadoop command syntax might be slightly different.
To launch Hive, first I launch the Hadoop command prompt and then change the current directory to Hive_Home\Bin where I installed Hive, as shown in the step below.
C:\hdp\hadoop-2.4.0.2.1.3.0-1981\bin>cd C:\hdp\hive-0.13.0.2.1.3.0-1981\bin
Next, I type hive to launch the Hive client as below:
C:\hdp\hive-0.13.0.2.1.3.0-1981\bin>hive
Hive Databases
Like many RDBMs, Hive supports many databases with namespaces enabling users and applications to be separated into different databases or schemas. To display all the databases currently on Hive, you type "SHOW DATABASES;" as shown below. In Hive ";" marks the end of a complete statement.
hive> SHOW DATABASES;
Figure 2: Showing Hive command and results on the CLI .
Result: OK Default Sql_on_hadoop sqlonhadoop Time taken: 0.057 seconds, Fetched: 3 row(s)
The results (original screen shown on Figure2 shows that I have 3 databases on my Hive: default, Sql_on_hadoop and sqlonhadoop. If you have not created any databases yet, then you should see only the default database which comes with Hive installation.
To create the Sqlonhadoop Database that we will use in the exercises going forward, run the statements below;
hive> DROP DATABASE IF EXIST Sqlonhadoop; hive> CREATE DATABASE Sqlonhadoop; hive> SHOW DATABASES;
After running the last statement, the results should show the default and sqlonhadoop databases as shown below.
Result: OK Default sqlonhadoop
Hive Tables
For the initial exercises, I will use data in csv text files that I generated using data from DimGeography tables from Adventureworks. All the text files that will be used in the exercises can be found in the attached SQL-On-Haddop.zip file.
To get a feel of HiveQL, in the next few steps, we will create a table in the sqlonhadoop database that we created above and load the table with data from a csv file.
First, let’s change the database context to sqlonhadoop and drop the DimGeography table if one exists.
hive> USE sqlonhadoop; hive> DROP TABLE IF EXISTS DimGeography;
Next we create the new table called DimGeography as below.
hive>
CREATE TABLE DimGeography(
GeographyKey INT
,City STRING
,StateProvinceCode STRING
,StateProvinceName STRING
,CountryRegionCode STRING
,EnglishCountryRegionName STRING
,PostalCode STRING
,SalesTerritoryKey INT
,IpAddressLocator STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n';The next step below uses the LOAD DATA LOCAL command to load the DimGeography.csv file from a local file system into the Hive DimGeography table we created above.
hive> LOAD DATA LOCAL INPATH 'C:\Temp\DimGeography.csv' INTO TABLE DimGeography;
Next, let’s select some records from the DimGeography table using the LIMIT keyword to specify the number of records that should be returned.
hive> SELECT * FROM dimgeography LIMIT 3;
Results: OK NULL Alexandria NSW New South Wales AU Australia 2015 9 198.51.100.2 2 Coffs Harbour NSW New South Wales AU Australia 2450 9 198.51.100.3 3 Darlinghurst NSW New South Wales AU Australia 2010 9 198.51.100.4 Time taken: 2.025 seconds, Fetched: 3 row(s)
The results above shows the 3 records returned by the SELECT statement.
Going back to the CREATE TABLE statement above, we will notice that with the exception of a ROW FORMAT clause the Hive create table statement is quite similar to that of T-SQL. Those familiar with External Files in SQL Server 2016 should be familiar with the ROW FORMAT feature specification. In the next sections we will explore how Hive uses this feature to read table rows.
Hive SerDe
Unlike tables in typical RDBMs, Hive table storage is govern by ROW formatting that dictates how rows, and the fields in a particular row, are stored and terminated. In Hive, the defined format is captured by SerDe (short name for "Serializer and Deserializer"), a built-in Library that instructs Hive on how to process a record or a row at execution time. A SerDe allows Hive to read in data from a table, and write it back out to HDFS in any custom format based on formats specified during the creation of the table.
This flexible customization option means that anyone can write their own SerDe for their own data. This feature enables Hive to use files created by other tools and various standard storage formats. In the example above, we conveniently loaded a CSV file into the above table because there is a built-in SerDe for CSV. Other built-in SerDes in Hive include: Avro, ORC, RegEx, Thrift, Parquet.
Some other popular third party ones include the JSON SerDe for JSON files provided by Amazon at: s3://elasticmapreduce/samples/hive-ads/libs/jsonserde.jar, a format also supported by SQL Server 2016. You may check this site on how to write your own SerDe ; How to Write Your Own SerDe
Schema-On-Read
When you create a Hive table, the schema is stored in the relational database Metasore, however, unlike RDBMS, when you load data into a Hive table the data is not stored directly in the table. Hive is a Schema-On-Read database, which means that when you load a file into a table with the LOAD DATA command, Hive moves or copies the file(s) (in their original format) into a subfolder in a specific directory. When you later run a SELECT statement on the table, Hive knows what particular table schema to apply to file(s) in the specific subfolder(s) created and assigned to the table by Hive. In other words, table creation and data loading processes are mostly file system operations.
Hive creates a database-subfolders for each database you create in Hive in its warehouse directory controlled by the hive.metastore.warehouse.dir property in the Hive hive-site.xml configuration file. This defaults to the /user/hive/warehouse folder location of Hive installation directory. Each table you create in a particular Hive database is also assigned a table-subfolders under the database-subfolder and files loaded into the table are stored in the table-subfolder. The only exceptions are operations on the default database.On the default database, tables do not get their own directory.
To check how Hive implements these folders and file structures, let’s inspect the Hive table we created above. Note that Hive automatically appends .db to database-subfolder names therefore we can run the statement below to list the table-subfolders currently under the sqlonhadoop database.
hive>dfs -ls /hive/warehouse/sqlonhadoop.db/;
Results:
Found 1 items drwxr-xr-x - fadje_000 hdfs 0 2015-10-09 12:07 /hive/warehouse/sqlonhadoop.db/dimgeography
The result shows that there is only one subfolder dimgeography corresponding to the table we created above. Let’s proceed to list any subdirectories or files under the dimgeography table-subfolder as shown below.
hive>dfs -ls /hive/warehouse/sqlonhadoop.db/dimgeography/;
Results:
Found 1 items -rw-r--r-- 1 fadje_000 hdfs 41881 2015-10-09 12:05 /hive/warehouse/sqlonh adoop.db/dimgeography/DimGeography.csv
The results shows that the LOAD DATA command copied the DimGeography.csv file from the local directory into the new dimgeography table-subfolder created and managed by Hive. As opposed to copying files from local files system, files loaded from HDFS are moved from their location into the Hive managed folders.
Loading Data into Hive Tables
Let's assume we have numerous 500GB files coming into a folders daily, we may want to move these data files into HDFS, ideally because Hadoop will scales to distribute the large files onto different nodes on different machines, enabling us to efficiently interact and do batch processing on them. If the files are regular delimited text files or have a built-in Serde, we can create a Hive table and "load" the entire content of the folder into the table and seamlessly query all the files. If the files are say RSS feeds, we can write a custom SerDe based on XML structure of the RSS and have Hive load and query the files in the original format, all at the same time.
In the following steps, we will create a table called DimGeographyUSA with a comma delimited ROW FORMAT.
hive> DROP TABLE IF EXISTS DimGeographyUSA; hive> CREATE TABLE DimGeographyUSA( GeographyKey INT, City STRING, StateProvinceName STRING, CountryRegionCode STRING, EnglishCountryRegionName STRING, PostalCode STRING, SalesTerritoryKey INT, IpAddressLocator STRING ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n';
This time we will load the entire content of an HDFS folder with a couple of csv files into the table above. First, we use the HDFS file system command to put a copy of the DimGeographyUSA folder and its contents from a local dive onto HDFS.
hive>dfs -put c:/Temp/DimGeographyUSA /user/HDIUser;
Next is to use the Hive LOAD DATA command to load the entire contents of a folder from the HDFS into the DimGeographyUSA table we created above. Note that here the command to load the table did not include the LOCAL keyword like before, because we are loading the files from HDFS and not a local drive.
hive> LOAD DATA INPATH '/user/HDIUser/DimGeographyUSA’ OVERWRITE INTO TABLE DimGeographyUSA;
The last statement instructs Hive to move the four CSV files from the HDFS folder into a table-subfolder called dimgeographyusa created by Hive during the CREATE TABLE process. The OVERWRITE keyword in the statement tells Hive to delete any existing files in the table-subfolder.
Note that Hive does not enforce the table schema when loading these files into the table-subfolder, therefore it is incumbent on you to make sure that files matching the table schema are loaded into the table-subfolder.
Once again we can check the implementation of the file system operations in Hive by listing the content of the database-subfolder and the table-subfolder created by Hive, as indicated in the following steps.
The next step below lists all table-subfolders under the sqlonhadoop.db database-subfolder;
hive>dfs -ls /hive/warehouse/sqlonhadoop.db/;
Results:
Found 2 items drwxr-xr-x - fadje_000 hdfs 0 2015-10-09 12:07 /hive/warehouse/sqlonhadoop.db/dimgeography drwxr-xr-x - fadje_000 hdfs 0 2015-10-09 13:30 /hive/warehouse/sqlonhadoop.db/dimgeographyusa hive>
The results above shows that Hive created a new subfolder called dimgeographyusa under the sqlonhadoop.db database- subfolder during the table creation process.
Now, let’s list the items in the dimgeographyusa table-subfolder.
hive>dfs -ls /hive/warehouse/sqlonhadoop.db/dimgeographyusa/;
Results:
Found 4 items -rw-r--r-- 1 fadje_000 hdfs 8292 2015-10-09 13:57 /hive/warehouse/sqlonhadoop.db/dimgeographyusa/DimGeographyUS_CA.csv -rw-r--r-- 1 fadje_000 hdfs 632 2015-10-09 13:57 /hive/warehouse/sqlonhadoop.db/dimgeographyusa/DimGeographyUS_CO.csv -rw-r--r-- 1 fadje_000 hdfs 901 2015-10-09 13:57 /hive/warehouse/sqlonhadoop.db/dimgeographyusa/DimGeographyUS_IL.csv -rw-r--r-- 1 fadje_000 hdfs 1105 2015-10-09 13:57 /hive/warehouse/sqlonhadoop.db/dimgeographyusa/DimGeographyUS_NY.csv hive>
The results shows that Hive moved the four csv files from the HDFS folder into the dimgeographyusa table-subfolder in Hive managed environment during the load process. The next step queries this new table as below.
hive> SELECT u.StateProvinceName, u.City FROM dimgeographyusa u WHERE StateProvinceName <>'New York' LIMIT 3;
Results:
OK California Alhambra California Alpine California Auburn Time taken: 10.645 seconds, Fetched: 3 row(s)
The results above shows that the SerDe is able to return the result across all four files in the table.
Managed Tables
All the tables we have created thus far are called Managed Tables because Hive manages all the folder creation and file copying or movement operations. For instance when you drop a managed table, the data file(s) associated with the table are deleted from the Hive file system. We will look at some other Managed Table creation options and properties below.
In the following steps we will create and load some smaller set of Managed Tables called Gamblers and Winnings that we will be using for some queries going forward.
hive> CREATE TABLE IF NOT EXISTS sqlonHadoop.gamblers (Id INT, First STRING COMMENT 'First name', Last STRING COMMENT 'Last name', Gender STRING, YearlyIncome FLOAT, City STRING, State STRING, Zip STRING ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n';
hive> LOAD DATA LOCAL INPATH 'C:\temp\Gambling\Gamblers\Gamblers.csv' OVERWRITE INTO TABLE sqlonHadoop.Gamblers;
The statements above created and loaded the gamblers table adding some comments on some of the columns. Note also that the table name is prefixed with the database name, which will ensure the table is associated with the sqlonHadoop database, especially if you not sure of the current database context. You can also reference a table in that manner if you are not currently in the context of that particular database.
Create Table As Select (CTAS)
Tables can also be created and populated by the results from a query in one Create-Table-As-Select (CTAS) statement as shown below.
hive> CREATE TABLE gamblersNY AS SELECT g.* FROM gamblers g WHERE g.state='NY';
Create Table Like
Another way to create a table by copying an existing table definition exactly (without copying the associated data) is by using the LIKE Statement as shown below.
hive> CREATE TABLE gamblers_CA LIKE gamblers;
External Tables
External tables are created with the EXTERNAL keyword and the table may point to any HDFS location specified with the LOCATION Keyword, rather than being stored in a folder managed by Hive as we saw with Managed Tables above. Unlike Managed Tables, External Tables does not depend on LOAD DATA statements to load the tables. You have to make sure that the data files in the folder specified with the LOCATION keyword contains data file(s) that matches the format specified in the CREATE statement. When you drop an external table, data in the table is not deleted from the file system, Hive Just drops the table schema. Here, Hive does not manage any file, it manages only the table schema and just knows what external folder to apply it to.
The example below creates the Winnings table which points to a winnings folder on HDFS containing data file matching the specified ROW FORMAT.
DROP TABLE IF EXISTS winnings; CREATE EXTERNAL TABLE winnings ( Id INT, WinDate DATE, Amount FLOAT ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n' STORED AS TEXTFILE LOCATION '/user/HDIUser/Winnings';
Remember that the winnings folder on the HDFS location specified in the statement should contain data file that matches the table format. After that querying the table should return results from the files in that folder as below.
hive> SELECT * FROM winnings LIMIT 3;
Results:
OK NULL 2004-05-07 40000.0 15324 2004-06-19 40000.0 16668 2003-10-23 30000.0 Time taken: 0.434 seconds, Fetched: 3 row(s)
Using SQOOP to transfer bulk data between Hive and SQL Server
Instead of creating schemas and loading data into Hive, Sqoop can be used to import tables (schema and Data) directly from SQL database into Hive. Sqoop is a tool designed to efficiently transferring bulk data between Hadoop and SQL Server.
Import SQL server table into a Hive database
In the next steps below we will import the DimGeography table from AdventureWorks database into a table called DimGeography1 in the sqlonhadoop Hive database.
First, I launch sqoop as below.
C:\hdp\hadoop-2.4.0.2.1.3.0-1981>cd C:\hdp\sqoop-1.4.4.2.1.3.0-1981\bin C:\hdp\sqoop-1.4.4.2.1.3.0-1981\bin>sqoop
This step will Import the table:
C:\hdp\sqoop-1.4.4.2.1.3.0-1981\bin>sqoop import --connect "jdbc:sqlserver://SHINE-DELL\MSSS2012;databaseName=AdventureWorksDW2012;user=sa;password=xxxx" --table DimGeography --hive-table Sqlonhadoop.DimGeography1 -create-hive-table --hive-import -m 1
Remember to prefix the Hive table name with the database name if not the table may be imported into the default data base. Note that to use this option the SQL server instance must be running in SQL Server authentication mode.
Export Table from Hive to SQL Server
Similarly, you can export your Hive table to SQL server, as shown in the example below.
C:\hdp\sqoop-1.4.4.2.1.3.0-1981\bin>sqoop export --connect "jdbc:sqlserver://SHINE-DELL\MSSS2012;databaseName=HadoopDWH;user=sa;password=xxxxxx" --table DimGeography --export-dir /hive/warehouse/sqlonhadoop.db/dimgeography1 -m 1 -input-fields-terminated-by " "
Import data from SQL Server to HDFS
As shown below you can also import data directly from SQL Server into HDFS. This is convenient for building external tables as we discussed above.
C:\hdp\sqoop-1.4.4.2.1.3.0-1981\bin>sqoop import --connect "jdbc:sqlserver://SHINE-DELL\MSSS2012;databaseName=AdventureWorksDW2012;user=sa;password=xxx" --table DimEmployee -m 1 --target-dir /user/HDIUser
Hive Collection (Complex) Data Types
Hive data types are mostly similar to T-SQL data types except some complex data types. In this section we will explore Hivs’s collection data types below.
Syntax:
ARRAY<data_type>
MAP<primitive_type, data_type>
STRUCT<col_name : data_type [COMMENT col_comment], ...>
In the following example we create a table called GamblerWins with some Collection column types and Row formatting indicating how each collection items should be terminated or separated as shown below.
CREATE TABLE GamblerWins ( Id INT, Name STRUCT <fname : STRING, lname : STRING >, Addr STRUCT <Street : STRING, City : STRING, State : STRING, Zip: STRING>, Wins ARRAY <float>, Demographics MAP< STRING, STRING > ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '|' COLLECTION ITEMS TERMINATED BY ',' MAP KEYS TERMINATED BY ':' LINES TERMINATED BY '\n' STORED AS TEXTFILE;
Below is a sample row of data in the text file that fits the schema of the table created above.
ROW:
1|Andy,Capp|56 washington St,New Jersey, NJ, 00011|13500.00,1500.00,1200,50|Gender:M,MaritalStatus:M,HomeOwner:N,age:42
Next, we load the text file GamblerWins.txt into the GamblerWins table.
LOAD DATA LOCAL INPATH 'C:\temp\GamblerWins.txt’ OVERWRITE INTO TABLE GamblerWins;
We can query individual columns to see how they are structured, as shown for the address (STRUCT data type) below.
SELECT Addr FROM GamblerWins LIMIT 2;
Results:
OK
{"street":"56 washington St","city":"New Jersey","state":" NJ","zip":" 00011"}
{"street":"3 Main St","city":"New Jersey","state":" NJ","zip":" 07011"}
Time taken: 11.436 seconds, Fetched: 2 row(s)Referencing Collection Elements
All collection types implemented by Hive are Java-based, therefore elements can be access using indexing, dot notations and keys for ARRAY, STRUCT and MAPs respectively.
Before we proceed, first let's set the option to print the results header to TRUE as below;
hive>SET hive.cli.print.header=TRUE;
ARRAY
An ARRAY in Java is 0-based, so for instance if we can reference the second winning amounts (2nd element) for each gambler from the wins collection column in the GamblerWins table as below.
hive> SELECT id, wins[1] AS SecWinnings FROM GamblerWins LIMIT 3;
Results:
OK id secwinnings 1 1500.0 2 1001.0 3 21500.0 Time taken: 11.409 seconds, Fetched: 3 row(s)
STRUCT
To reference an element in a STRUCT, we use "dot" notation. The query to reference the city of each gambler from the addr collection column is as below;
hive> SELECT id, addr.city FROM GamblerWins LIMIT 3;
Results:
OK id city 1 New Jersey 2 New Jersey 3 New Jersey Time taken: 11.46 seconds, Fetched: 3 row(s)
MAP
Referencing a MAP element is like referencing an ARRAY element but with key values instead of integer indexes. The example below references the HomeOwner status from the Demographics collection column.
hive> SELECT id, Demographics["HomeOwner"] as hmeOwnerStatus FROM GamblerWins LIMIT 3;
Results:
OK id hmeownerstatus 1 N 2 N 3 Y Time taken: 11.429 seconds, Fetched: 3 row(s)
Note that if you reference a nonexistent element Hive returns NULL.
For the rest of Hive DDLs not covered here, check https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL
Conclusion
We've notice firsthand the similarities between SQL Server and Hive Database objects , DDLs and basic Query statements.
Those familiar with External Files in SQL Server 2016 will also be familiar with the ROW FORMAT feature specification that dictates how rows, and the fields in a particular row, are stored and terminated. In Hive, the defined format is captured by SerDe which instructs Hive on how to process a record or a row at execution time.
All in all we can say that while HiveQL does not strictly follow the full SQL-92 standard and has some complex data structure it is SQL. This means that many folks reading this article can do a lot of value-driven analytics on Big Data today using their SQL skills, as we will especially see in the next and final part of this series.
Next
In the next and final part of the Hive Series, will look at some of the more common HiveQL- ANSI standards like CASE statement and JOINs. We will also explore some more advanced features like Bucketing, Partitioning, Built-in function and Streaming so stay tune.