

Introduction
Today Hadoop still remains the dominant technology for storing and processing Big Data as I explained in this article two years ago. With its continued growth in scope and scale of analytics applications in its ecosystem, it is also pioneering a new enterprise data architecture referred to as Data Lake that seeks to integrates enterprise Hadoop, enterprise data warehouse (EDW) and other existing data systems. However, it is Hadoops role in powering the Internet of Things (IoT) in many respects that I see as consolidating this ecosystem.
In this article, we will have a comprehensive look at the Hadoop architecture and also try and understand the whole MapReduce paradigm from a SQL perspective. We will also look at how some of these new technological developments are helping shape and position Hadoop.
Subsequently in this series, we will look at SQL-On-Hadoop and other applications that provides faster and more extensive SQL querying capabilities on Hadoop, and also see why some more recent Hadoop in-memory processing alternatives like Spark may be better alternatives in both cloud and on-premise Hadoop Infrastructure.
Hadoop & MapReduce
To understand Hadoop and Map Reduce, we are going to look at a typical job that could be accomplished by SQL using a small set of data and then later by Hadoop. Let's say we want to count the number of words in some text, for example the small sample text below (which in this case are just the tags from my recent SQLServerCentral articles )
" Data Mining, Data Science, Predictive Analytics, Statistical Modeling, Analytics, Hadoop, NoSQL, Unstructured Data, ETL …"
In the SQL world there would be arguments about whether the appropriate solution should be set-based, recursive CTE, XML or whether in this case looping would be OK. There are a wide varieties of solutions to split spaced and delimited text in SQL as documented here but this is not the objective of this exercise.
Regardless of the approach you choose, in the end the solutions will pretty much perform the same tasks one way or the other as outlined below and shown on figure 1 :
- Apply SQL Split function to remove delimiters and whitespace.
- Count the unique words
- Aggregate the count
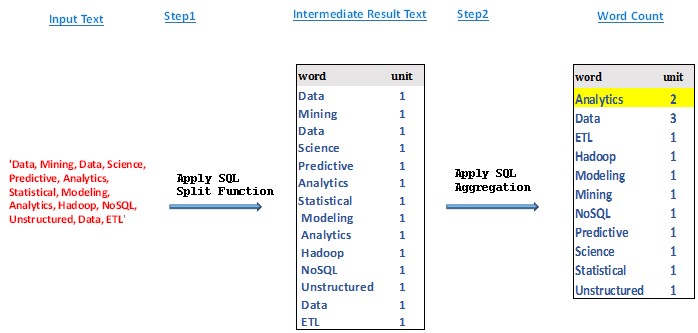
Figure 1: Showing logical steps in a typical word count process in SQL.
Before we move on, first of all let's try to understand why anyone will want to count words, say in a bunch of text. To do that let's look at the results from counting the tags above. As shown after step 3 in Figure 1, we can see that the word "Analytics" occurred 2 times and the word "Data" occurred 3 times in the text. Being that the word "data" could be considered as a common word on this forum, we can conclude that my recent articles has been more about "Analytics" or "Data Analytics" if you may.
This exercise may be trivial, but counting words in large texts (or corpus) forms the bases of many Text Mining and Text Analytics using natural Language processing (NLP). For those new to these terms Wikipedia provides excellent definitions. Also, through Collective Intelligence, a lot of information could be derived from huge amount of text, for instance from the internet. Collective Intelligence is defined as the ability to collect and combine behavior, preferences, or ideas and other information from numerous groups of people on the web to create novel insights (source: Programming Collective Intelligence). Some examples include:
- Recommendation: Using preferences of a group of people to make recommendations to other people.
- Searching and ranking: Many search engine (eg. Google's) rate web pages based on how many other pages link to them. This method of rating takes information about what sites numerous people have visited and what they've said about the web pages and uses that information to rank the results in a search.
- Document filtering : uses what has been reported as spam to filter Spam and signatures of earlier detected fraud to create fraud detection applications.
- Sentiment Analysis: It determine opinions (sentiments) expressed through various media on objects, features and entities ( e.g. cell phone, car, banks, websites, elections etc.). Thess opinions are captured in the form of the emotional effect individuals or groups wishes to have on readers whether positive, negative or neutral.
Bottom line is, counting, ranking, searching and classifying text has made and continues to make many companies fortunes, that is why this is serious business.
There are other very important notes, terminology and conclusions that we can also draw from this simple word count exercise. From the exercise:
- The simple delimited text we analyzed is typical of the content of Unstructured Data (lines of delimited text found in log files, scrapped web content, manufacturing and other equipment sensor data etc. ).
- If we had say huge amount of such text (terabytes of zipped text files) to be analyzed or to be counted like we did above, in most environment this will represent Big Data. Why? Let's just say for the simple fact that if you probably try to loop through the huge files with any conventional file system and any procedure language it might take forever. That is why in certain situations like you may need Hadoop the de-facto Big Data processing engine.
- From Figure 1, note that the intermediate result after the first step is Structured Data, which can be handled by RDBMS in most cases. This means that, not everything has to be done on Hadoop, i.e. depending on the size of your data, or what your objectives are you can do voluminous processing on Hadoop and the rest on RDBM where possible. This last point is more important because storing and processing in cloud based Hadoop subscriptions could be expensive.
Hadoop Ecosystem
The Apache Hadoop software library is an open-source framework that implement a special versions of the Distributed File System called Hadoop Distributed File System (HDFS). The protocol used by this file system is such that it enables Hadoop to store and replication huge amounts of data easily. The architecture which is possible to be built entirely on commodity hardware enables applications to reliably process multi-terabyte of data in-parallel and in a fault tolerant manner. The ecosystem include many other tools including frameworks for managing client jobs and the Hadoop Environment itself. You can read more about the emergence and how the engine became the defacto Big Data processing engine in this article Big Data for SQL folks: The Technologies (Part I).
Data Storage and Processing
The Hadoop Distributed File System (HDFS) the life blood of Hadoop offers a way to store large files across multiple machines. Clusters in HDFS are actually miniature servers each of which runs a Java virtual machine (JVM). To understand HDFS and how it processes data, it is important to understand how it operates unlike the normal Network File System (NFS) that we are used to. At a high level, Figure 2 below shows how the two system (HDFS and NFS) will handle a client application that say counts some text in a large file.
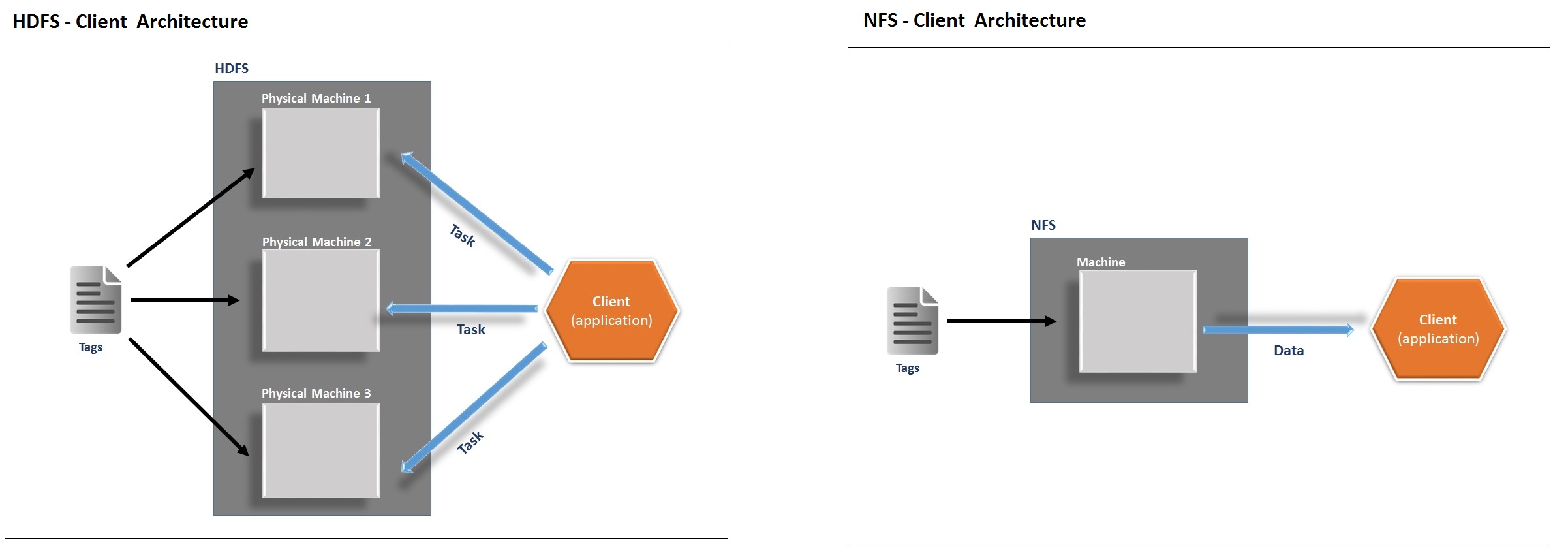
Figure 2a (left): Distributed Data storage and processing enables parallel processing
Figure 2b (right): Distributed Data storage and processing enables parallel processing
On HDFS as shown on Figure 2a, the content of the file is distributed over multiple machines. Each chunk on a machine is normally further replicated to other servers. As appose to Network File System a client application Processing occur where the data is located. The distributed nature of HDFS enables applications to scale to petabytes of data employing commodity hardware and enables Hadoop’s MapReduce API that manages Jobs consisting of various tasks to implement work parallelization.
On the other hand, on the normal Network File System as shown on Figure 2b the text file will reside on a single machine and therefore will not provide significant reliability guarantees should that machine fail. Secondly, because the data is stored on a single machine, all the clients must go to this machine to retrieve their data, as result the can could be overloaded if a large number of clients are involved. Also, on these setups clients must always copy the data to their local machines before applying application processing.
HDFS
Let's now assume the tags from my article we counted above were a part of a larger file called Tags.txt and let's see how the content of the file could be stored and manage on HDFS.
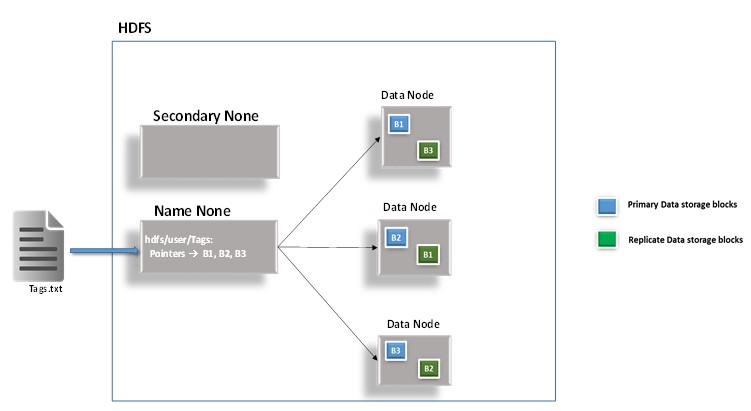
Figure 3: Shows how the content of a text file is stored on HDFS with a replication factor of one.
In the example shown on Figure 3, the content of the text file is splitted into 3 blocks (B1, B2, B3). The blue blocks represent the primary storage blocks and the green blocks are replications. Note that in a production Hadoop installation the block would be replicated three times. This seemingly redundancy ensures reliability enabled by this fault-tolerant design. Hadoop engine's ability to replicate means that it is able to detect task failure on one node on the distributed system and restart the task on another healthy node. HDFS clusters has two types of nodes that operates in a master-lave pattern: a NameNode (the master) and a number of DataNodes (slaves).
NameNode: The NameNode is responsible for managing the filesystem namespace. The NameNode is always aware of the DataNodes on which all the blocks for a given file are located. The Name Node in HDFS does not store any of the data, it stores only metadata. It stores the information that maps the file Names onto the Block ids. It monitors where the various data nodes are and where the various data blocks distributed on them.
Secondary NameNode: The Secondary name node is a new concept in Hadoop that provides High availability against the name node. Prior to their introduction if the name node were to fail the whole cluster would fail.
DataNode: DataNodes are the worker bees of the HDFS. They are responsible for storing and retrieving data blocks when they are told to by the clients or the NameNode. They also report back to the NameNode periodically with lists of blocks that they are storing.
MapReduce Paradigm and Framework
MapReduce is a programming paradigm and framework that Hadoop uses for processing data with a parallel and distributed algorithm on an HDFS cluster. To understand the framework and how jobs are processed, let's see how a typical Hadoop MapReduce job will count the tags we counted above, assuming now that the tags are part of a larger set stored in a text file called Tag.txt.
In Hadoop, the framework that will handle such a job is the MapReduce API. Figure 4 below illustrates the various phases the MapReduce job may go through in the word count process.
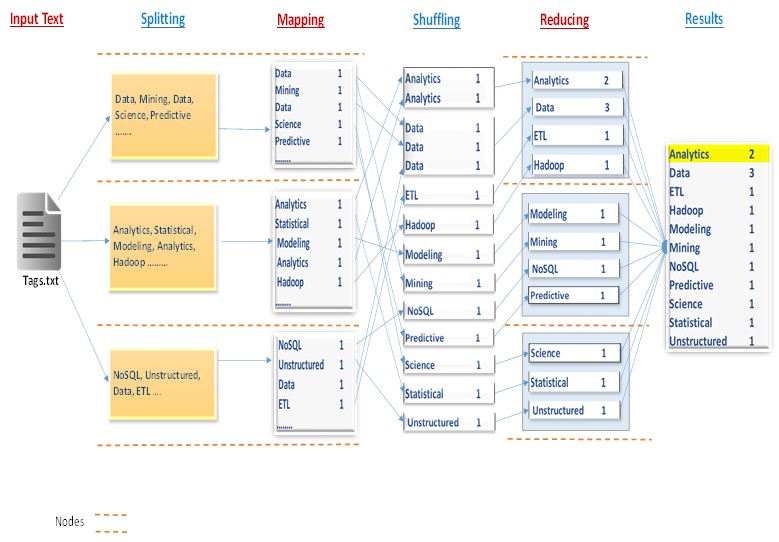
Figure 4: Showing logical steps in a typical word count process in a Hadoop MapReduce Job.
The various processing phases are explained below:
Splitting: Hadoop split the input files into chunks (typically sizes of HDFS blocks of 64MB) across your network.
Mapping: The mapping phase represent a user defined function equivalent to step 1 on Figure 1. Here, Hadoop creates a separate mapper for each of the split with an instance of a mapper function written by a user. This mapper operates locally, where the chunk is physically located (for multiple files, each mapper loads the set of files local to that machine and processes them). Note that the mapper logic/function is computed line by line as a key/value for each data element in the chunk. The mapper emits a key/value pair after its computation. The separate mapper tasks are processed in parallel.
Shuffling & Sort: Internally, Hadoop collects the results from the mappers into different partitions each of which is eventually sent to a single Reducer locally, but before then it sorts the mapper results by the keys.
Reducing: The Reducing phase also represent a user defined function equivalent to step 2 on Figure 1. Several instances of the reducer function are also instantiated on the different machines. The reducer computes its logic on the aggregated (combined) partitions and then emits key/value pair after its computation to HDFS.
Note that, even though, large documents might be splitted and each split sent to a separate Mapper, there are techniques for combining many small documents into a single split for a Mapper. Also, note that the nodes indicated on the figure could be on a single or multiple physical machines.
MapReduce framework
Using the file we processed above and the HDFS architecture in Figure 3, let's explore a more complete architecture of a Hadoop cluster including the MapReduce framework.
The base Hadoop clusters have three types of machines (master, slaves, and clients) based the roles they play:
Masters: Consist of HDFS NameNode and MapReduce JobTracker
Slaves: consist of HDFS DataNodes (DN) , MapReduce TaskTrackers
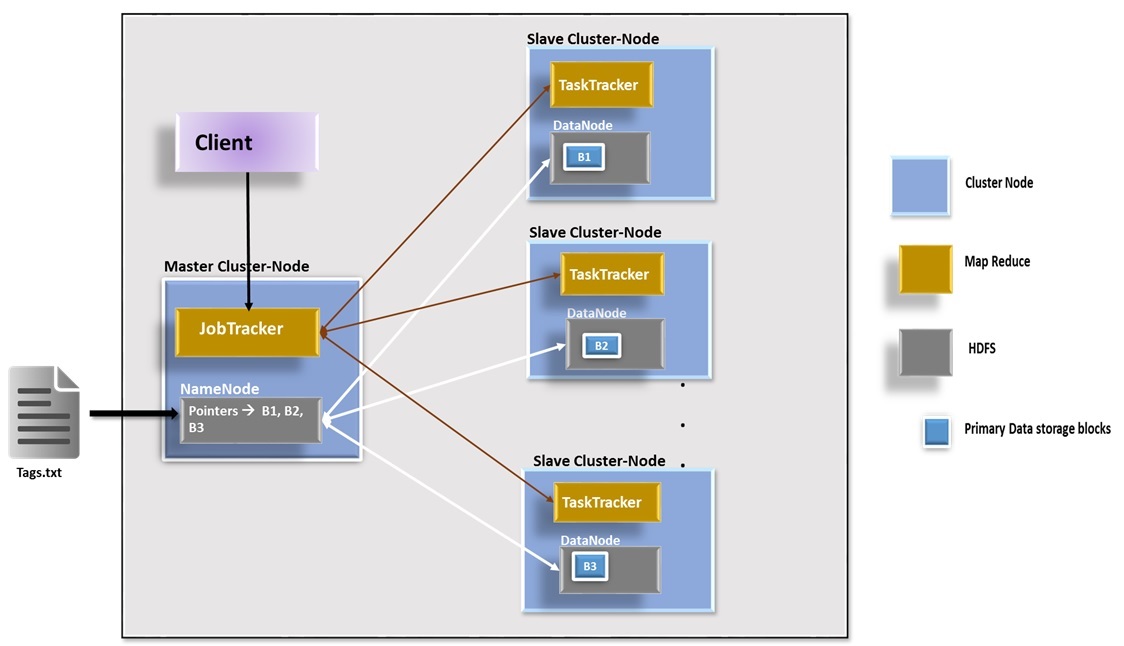
Figure 5: Showing a simple Hadoop cluster architecture (with HDFS and MapReduce framework) and the content of a text file.
HDFS - Physical storage management and Architecture
HDFS consists of a single master NameNode and one slave DataNodes per cluster-node. Note that in real implementations you could have hundreds to 1000s of slave nodes with different configurations. Refer to Figure 3 under HDFS section above for detailed architecture.
Mapreduce framework - Job Management
As shown on Figure 5 above, the MapReduce framework consists of a single master JobTracker and one slave TaskTracker per cluster-node. The master is responsible for scheduling the jobs' component tasks on the slaves, monitoring them and re-executing the failed tasks. The slaves execute the tasks as directed by the master. The framework is responsible for scheduling tasks, monitoring them and re-executes the failed tasks.
New MapReduce Framework
The current Apache MapReduce version is built over Apache YARN resource manger. Unlike the original version the new version has been designed to facilitate the implementation of more generic application programming and arbitrary distributed processing frameworks and applications beyond just MapReduce, allowing real-time and in-memory processing alternatives like Storm and Spark respectively.
Programming MapReduce Jobs
As can be seen from the MapReduce job in figure 4 above, as a developer, besides loading the data unto HDFS, what you control in a MapReduce job is the Mapping and the reducing processes . At a high level, let's see how a typical programming language pseudo code for counting the words as in the above will look like.
Mapper:
mapFunction (lineFeed):
for each word in Split(lineFeed):
yield (word, 1) Reducer:
reduceFunction (word, values):
sum = 0
for each value in values:
sum = sum + value
yield(word, sum)This is a Python implementation of a mapper and Reducer (WordCountMapper.py, WordCountReducer.py) for counting words in a text file and can be found in the attached wordCount.zip file. We will later see how to use them to count words in the content of any text file through Hadoop streaming Jobs.
Running Hadoop Jobs
To run a Hadoop Job, minimally, applications specifies the data input/output locations and also supply map and reduce functions using appropriate interfaces and/or abstract-classes. The Hadoop job client then submits the job and specified configurations to the JobTracker which distributes the information to the slaves. The JobTracker is also responsible for scheduling tasks and monitoring them, providing status and diagnostic information to the job-client.
Java Jobs
Hadoop framework is implemented in Java so the mapper and reducer functions is best programed in Java if you are familiar with that language. When implemented with Java and saved as JAR files, the execution context of the jobs written in Java is seamless as shown on figure 6 below.
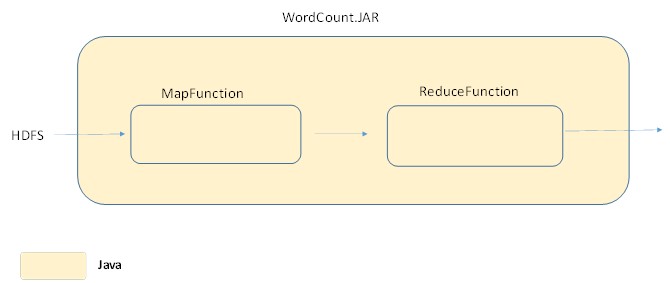
Figure 6: Shows seamless execution of a java mapreduce Job in Hadoop.
For instance, since everything is on the same platform when written I java, in the word count example the map and reduce function could be implemented in one WordCount.java file as in the attached. The Java file is then compiled and then zipped to a JAR(Java Archive) file. The applications specifies the data input/output locations and also supply mapper and reducer functions using the JAR file.
JAR is a package file format typically used to aggregate many Java class files and associated metadata and resources into one file to distribute application software or libraries on the Java platform.
Hadoop Streaming Jobs
The good news is that, although the Hadoop framework is implemented in Java, MapReduce applications can be written in other programming languages (R, Python, C# etc). Hadoop streaming is a utility that comes with the Hadoop distribution which allows you to create and run Map/Reduce jobs with any executable or script as the mapper and/or the reducer. With Hadoop Streaming, you can write Map and Reduce functions in any language that supports reading data from standard input, and writing to standard output.
The layer of communication protocol between the MapReduce framework and the streaming API however makes streaming jobs slower than native Java jobs. The streaming API (implemented in Java) interacts with the map and reduce functions separately. Figure 6 below shows how the streaming API will interacts with a mapper function.
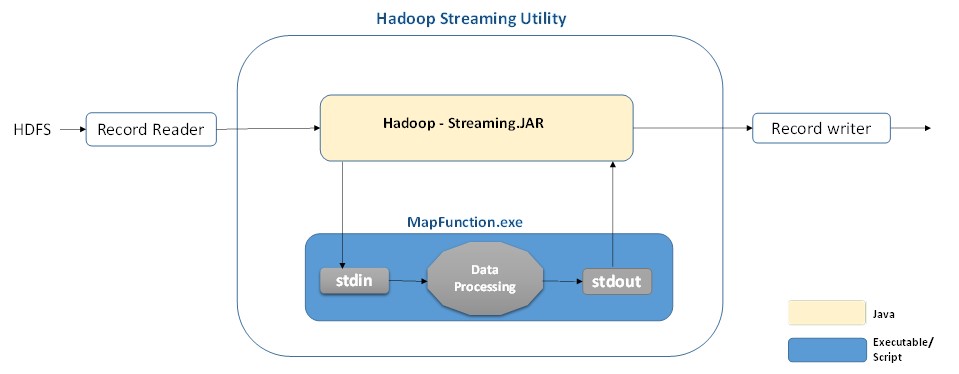
Figure 7: Showing the interaction between Hadoop streaming API and a Mapper executable.
The streaming utility will create a Mapper job, submit the job to an appropriate cluster, and monitor the progress of the job until it completes. As the mapper task runs, it converts its inputs from HDSF into lines and feed the lines to the stdin of the executable. As shown on Figure 7 above for a mapping process, the mapper will read the input records line by line through stdin and emit the output to stdout which converts each line into a key/value pair as the output of the mapper.
Normally, by default, the prefix of each line feed up to the first tab character if available will be used as the key and the rest of the line, excluding the tab character will be used as the value. If there is no tab character in the line, then entire line is considered as key and the value is null. However, this default setup can customized depending on the structure of the data.
Running a Streaming Job
There are many other interfaces to Hadoop, but the command line is one of the simplest and, to many developers, the most familiar. In the example Listing 1 below shows how to run a mapper and reducer implemented in Python in the python files (WordCountMapper.py, WordCountPyReducer.py) from the command line. All the files used in this example can be found in the attached wordCount.zip file.
Listing 1:
hadoop jar c:\hdp\hadoop-2.4.0.2.1.3.0-1981\share\hadoop\tools\lib\hadoop-streaming-2.4.0.2.1.3.0-1981.jar -input /user/HDIUser/Tags.txt -output /user/HDIUser/out2 -mapper c:\hdp\hadoop-2.4.0.2.1.3.0-1981\WordCountPyMapper.cmd -reducer c:\hdp\hadoop-2.4.0.2.1.3.0-1981\WordCountPyReducer.cmd -file c:\hdp\hadoop-2.4.0.2.1.3.0-1981\WordCountMapper.py -file c:\hdp\hadoop-2.4.0.2.1.3.0-1981\WordCountReducer.py
The first line call the java streaming API hadoop-streaming-2.4.0.2.1.3.0-1981.jar by providing the location of the file on my machine.
The second line tells the API where the input text file Tags.txt is located on HDFS.
The third line tells the API where the output file should be placed on HDFS.
the fourth line points Hadoop to the Mapper executable (WordCountPyMapper.cmd ) which tell Hadoop how the mapper should be executed (i.e. by using Python on my machine). The content of the WordCountPyMapper.cmd file is shown below.
@call c:\python27\python.exe c:\hdp\hadoop-2.4.0.2.1.3.0-1981\WordCountMapper.py
The fifth line points Hadoop to the Reducer executable (WordCountPyReducer.cmd) which tell Hadoop how the Reducer should be executed (i.e. by using Python on my machine). The content of the WordCountReducer.cmd file is shown below.
@call c:\python27\python.exe c:\hdp\hadoop-2.4.0.2.1.3.0-1981\WordCountReducer.py
The last two lines tells Hadoop the location of the mapper and reducer python files (WordCountMapper.py, WordCountPyReducer.py) to be passed around to all the nodes in the cluster.
It should be noted that I run this example on HDInsight emulator (a Microsoft version of Hadoop ) installed on windows that is why I had to wrap the mapper and reducer in cmd file. There are various other Hadoop versions (Horton Works,Cloudera, MapR, IBM-infosphere BigInsight etc.) and depending on the OS (window or linux) the job execution parameter syntax might be slightly different.
SQL-on-Hadoop Jobs
Besides the popularity of SQL, there are other reasons why there are developments of abstraction with SQL-like query language that converts queries into MapReduce jobs.
First, Big Data automatically get associated with non-structured data types however a lot of real big data projects involve transactional or log data most of which are easily manipulated with SQL with transformations. For instance on Predictive analytics Job for a manufacturing firm, the terabytes of sensor data they had were in tabular form.
Secondly, besides understanding the MapReduce programming paradigm, ideally one have to be well vexed in Java to write and implement Java mapreduce jobs. For instance there are about 53 lines of Java code in the wordCountJava.txt file in the attached zipped file which represents Java version of the word count. On the other hand Listing 2 below shows the same word count example written in HiveQL, a language that comes with Hive, a data warehouse-like infrastructure in the Hadoop ecosystem. Notice that it is just 8 lines of code, and will not require compilation or the use of “JAR” file or streaming API:
Listing 2
CREATE TABLE Tags(line STRING); LOAD DATA INPATH 'Tags' OVERWRITE INTO TABLE Tags; CREATE TABLE WordCount AS SELECT word, count(1) AS count FROM ( SELECT explode(split(line,'\s')) AS word FROM Tags) w GROUP BY word ORDER BY word;
Today there are many commercial and open source SQL-on-Hadoop products available. Vendors are at this point are just competing on who has the best performance, compatibility, and the ability to scale to support real-world production workloads.
Hadoop Cluster Architecture
In this section we will try and understand the complexities of Hadoop architecture and implementation.
Small Hadoop Clusters
Normally, for evaluation purposes it is possible to deploy Hadoop on a single node (VM/ simple installations), with all master and the slave processes residing on the same machine.
For small clusters, it's more common to configure two nodes, with one node acting as master (running both NameNode and JobTracker) and the other node acting as the slave (running DataNode and TaskTracker) as on figure 5. It is normally recommended to separate master and slave nodes because task workloads on the slave nodes should be isolated from the masters. Also slave nodes could frequently be isolated for maintenance. In the smallest clusters it is also typical to use a minimum of four machines, with one machine deploying all the master processes, and the other three co-deploying all the slave nodes . Clusters of three or more machines typically use a single NameNode and JobTracker with all the other nodes as slave nodes.
Medium-to-large Hadoop Cluster
Typically, a medium-to-large Hadoop cluster consists of a two or three-level architecture built with rack-mounted servers. Here the components within the master and slaves are implemented on a separate rack as shown on figure 6 below, with each role operating on different single server machines. Normally, to maintain the replication factor of three, a minimum of three machines is required per slave node. In relatively smaller clusters, with say 40 nodes, the setup could have a single physical server playing multiple roles, such as both Job Tracker and Name Node.
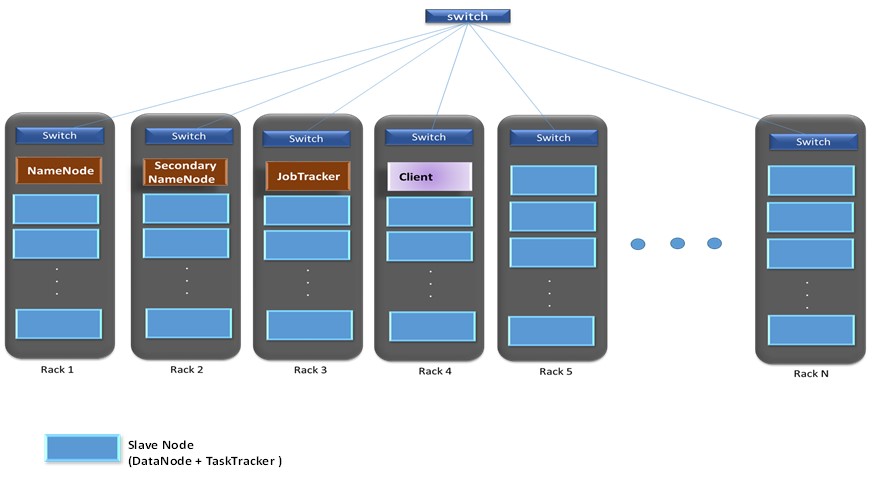
Figure 8: Showing a medium-to-large Hadoop cluster architecture.
In large clusters it is typical to have Client machines with Hadoop installed with all the cluster settings, but acting neither a Master or a Slave. Instead, the role of the Client machine would be to load data into the cluster, submit Map Reduce jobs and then retrieve the results of the job when the job is completed.
As shown on Figure 8, each rack-level switch is connected to a cluster-level switch which may also interconnect with other cluster-level switches. Normally, to maintain the replication factor of three, a minimum of three machines is required per slave node. Hadoop runs best on Linux machines, working directly with the underlying hardware.
The Internet Of things and Hadoop
Let's look at what is fueling Hadoop's adoption into the mainstream and its widespread deployment at organizations in nearly every field. To really appreciate Hadoop's adoption is to understand what is already here and what is in the making. Whether seeking new insight, optimizing operations for efficiency to increase revenue or reduce cost, firms have found out that one way to compete is on analytics, i.e. analyze some of their most valuable assets - data which they are collecting in stock-piles.
Besides being the technology capable of managing some of these large data sets, Hadoop now also appeals to these enterprises because It’s computational platform enables advanced forms of analytics typical in data mining, statistical modeling, text analytics, graph etc. Because of this ecosystem, today they can accomplish tasks like those outlined below and many more:
- Executing marketing campaigns using volumes of information, gathered across multiple communication channels including direct, online and mobile.
- Calculate financial risk through analysis of portfolios with thousands of instruments.
- Building models to detect credit card fraud using thousands of variable and billions of transactions from credit card operation.
- Selectively recommend numerous products to millions of users.
Just a couple of years ago the computing power to accomplished these calculations was not mainstream. Today Hadoop has made such analysis more scalable and affordable.
With all that said, the true importance of Hadoop may be in what is in the making as a result of the convergence of some various technologies like RESTFul APIs, Mobile Apps and the Internet Of Things.
RESTFul APIs
Today the abundance of Representational State Transfer (REST) APIs have revolutionized app development. REST is a software architecture style that defines the best practices for creating scalable web services (Wikipedia). The availability of such specialized web services (like Google Map and Analytics Management , Amazon EC2, Weather Channel etc. ) are allowing businesses and developers to build apps that in some cases refashion their existing businesses, not to mention start-up innovation. Companies and start-ups are effectively able to composed business Apps that uses APIs from several sources including banks, insurance companies, map providers, analytics provider and many others.
Mobile Apps
Mobile app are also leading to a new class of apps that are based on context awareness. These Apps discover and take advantage of contextual information such as user location, time of day, neighboring users and devices, and the activity of the user and many more. The two most differentiating features about mobile apps are the fact that:
- Today's smart phones and other mobile devices like wearables come with GPS, WiFi and all kinds of sensors that enable Apps to understand location, acceleration, direction of movement and many other derived conditions.
- Because people carry their mobile phones with them everywhere.
As a result it is becoming the most important channel businesses are using reach their customers.
Internet Of Things (IoT)
APIs and Apps are changing the game, but the ability to seamlessly integrate technology from embedded systems, wireless, sensors, networks, control systems, building automation and others through the internet is the new frontier. Referred to as Internet Of things (IoT), this system of interconnected "things" is defining some open communications protocols that allow for the integration of devices from all these sources. As noted on wikipedia, the "Things" in the IoT, can refer pretty much to any device that collects useful data with the help of existing technologies and then autonomously flow the data between other devices. This means that:
- IoT will consist of a very large number of devices being connected to the Internet
- IoT finds applications in nearly every field, healthcare, manufacturing, transportation, infrastructure and energy management and marketing to name a few.
- IoT systems generate large amounts of data from diverse locations that needs scalable storage, indexing, and processing.
- IoT systems are expected respond to conditions after sensing things, which means real-time analytic processing.
The Hadoop ecosystem is currently powering data storage and processing of many of such systems, it is especially speeding up this process where cloud Hadoop infrastructure and platforms are being offered as a service (Hadoop IaaS and PaaS). Various companies are positioning themselves for a piece of this action, in many cases forming what they deem are the right alliances to make it happen. Some major players in this field include IBM, AWS, Microsoft, GE, intel, Cisco, AT&T , Oracle and many others as compile by William Toll here: Top 49 Tools For The Internet of Things.
Whiles some companies are capitalizing on their core competence like networking, wireless, embedded system etc., others like IBM, Microsoft and GE have their versions of IoT's, mostly Hadoop powered Cloud based processing service for streaming data and Cloud-based analytics platform. Hadoop is powering many of these major IoT's in the area of storage, data streaming and analytics. Simply put, Hadoop does not seems to be going anywhere anytime soon.
Summary
We learnt that MapReduce is programming paradigm that passes a processed name-value pair from a mapper to a reducer and in Hadoop this types of Jobs are managed by Hadoop MapReduce Framework. We also looked at HDFS, the Hadoop architecture and the range of possible implementation sizes.
The hadoop ecosystem is still gaining grounds offering more richer analytics application options and also leading a new Enterprise data architecture (Data Lake) with mainstream adoption potential. However it is IoT that may be propelling Hadoop to a new status. Like Hadoop some years back, IoT is not a hype anymore. Various organizations currently have versions of their functional IoTs with various "Things" being connected to and through them.
In a subsequent installment of this series we will review some hadoop versions and installation options and also have an in-depth look at how some advanced analytics jobs that could be accomplished using SQL-on-Hadoop and also why some processing alternatives like Spark may me more appealing than MapReduce Java and Streaming Jobs.
