

Introduction
In a recent SQL-on-Hadoop article on Hive ( SQL-On-Hadoop: Hive-Part I), I was asked the question "Now that Polybase is part of SQL Server, why wouldn't you connect directly to Hadoop from SQL Server? " My simple answer will be "Because of big data storage and computation complexities".
big data engineering, analysis and applications often require careful thought of storage and computation platform selection, not only due to the variety and volume of data, but also because of today's demand for processing speed in order to deliver the innovative data-driven features and functionalities. The various big data tools available today are good at addressing some of these needs, including SQL-On-Hadoop systems like PolyBase, Hive and Spark SQL that enables the utilization of existing SQL skillsets. For instance if you want to combine and analyze unstructured data and your data in a SQL Server Data warehouse then Polybase is certainly your best option, on the other hand for preparation and storage of larger volume of Hadoop data It might be easier to spin-up a Hive cluster in the cloud for that purpose than to scale with Polybase Group on premise. Yet still, for heavier computations and advanced analytics application scenarios, Spark SQL might be a better option. There’s no single tool or platform out there today that is able to address the various big data challenges hence the recent introduction of data-processing architectures like Lambda Architecture that suggests a design approach that uses of a variety of databases and tool to build end-to-end big data system solutions.
One key thing one always has to bear in mind about SQL-On-Hadoop and other big data systems is that, they are tools with distributed computing techniques that eliminates the need for sharding, replication and other techniques that are employed in traditional relational database environments to scale horizontally and to resolve application complexities that resulted from these horizontal data partitioning. In other words, to be able to make the appropriate big data tool selections, it is important to understand the distributed computing challenges that rises from many machines working in parallel to store and process data and how these big data system abstract these challenges.
In this article we will have a high-level look at PolyBase, Hive and Spark SQL and their underlying distributed architectures. We will however try to understand these SQL abstractions in the context of general distributed computing challenges and big data systems developments over time.
Introduction to Distributed Computing
distributed computing encompass diverse application areas including: parallel computing, multi-core systems, the Internet, wireless communication, cloud computing, mobile networks etc. This enormous breadth also mean many hardware and software architectures, but generally, two things underscores these systems;
- On one dimension you have connection of multiple CPUs with some sort of network; whether printed onto a circuit board or consisting of Network hardware and software on loosely coupled devices and cables.
- On another dimension is the ability to interconnect separate processes running on these CPUs with some sort of communication system to enable them achieve some common goal, typically in a master/slave relationship or done without any form of direct inter-process communication, by utilizing a shared database.
Architecturally, distributed computing could be categorize using these basic classes: client–server, three-tier, n-tier, peer-to-peer; [1]
- Client–server: architectures where smart clients contact the server for data then format and display it to the users. Input at the client is committed back to the server when it represents a permanent change.
- Three-tier: architectures that move the client intelligence to a middle tier so that stateless clients can be used. This simplifies application deployment. Most web applications are three-tier.
- n-tier: architectures that refer typically to web applications which further forward their requests to other enterprise services. This type of application is the one most responsible for the success of application servers.
- Peer-to-peer: architectures where there are no special machines that provide a service or manage the network resources. Instead all responsibilities are uniformly divided among all machines, known as peers. Peers can serve both as clients and as servers.
Big Data Systems and Distributed Computing
Going forward big data systems in our discussions will refer to peer-to-peer distributed computing models in which data stored is dispersed onto networked computers such that components located on the various nodes in this clustered environments must communicate, coordinate and interact with each other in order to achieve a common data processing goal. Each nodes in these clusters have certain degrees of freedom, with their own hardware and software however they may share common resources and information for coordinate to solve data processing need.
The Big Data Problem
The exponential growth of data in no news today, the problem is that single CPUs cannot keep up with the rate data is growing because we are reaching the limits to how fast we can make them can go. This posed a limitation to scaling vertically, therefore the only way to scale to store and process more and more of this data today is to:
- Scale horizontally onto large clusters
- And parallelized computations on these clusters
These major distributed computing challenges constitutes the major challenges underlying big data system developments, which we will discuss at length.
Scaling with a Traditional Relational Databases
To understand the challenges big data systems have to overcome, we can look at how traditional database technologies run into problems with both horizontal scalability and computation complexities.
In traditional relational systems, a mix of both reading and writing could lead to locking and blocking. In situations where it is a mix of both, normally the problem can be contained by moving reads to separate servers and enabling quick writes to say, a master server. Although this feature is helpful and built into some RDMBs ( e.g. Always On Availability Groups in SQL Server ), it does have its limitations and requires special skill to setup, deploy and maintained.
In write-heavy applications, restricting writes to a single server may not be able handle write load no matter how much you scale up by adding more hardware. This happens in part because writers issue locks that leads to blocking. The proven technique in these cases is to also spread the write load across multiple machines such that each server will have a subset of the data written into a table, a process known as horizontal partitioning or Sharding. Most RDBMs have their own solutions to setting up Sharding also sometimes referred to as database federation.
A major difficulty with setting up sharding is determining how to proportionately distribute the writes to the shards once you have decided how many of shards are appropriate. There are several approaches to determining where and how to write data into Shards, namely Range partitioning, List partitioning and Hash partitioning. When you have a very heavy write applications often the best option is hash partitioning. Partitioning data using ranges and lists could skew writing to certain servers, but hash partitioning assigns data randomly to the servers ensuring that data is evenly distributed to all Shards.
After setting up sharding, application code dependent on a sharded table needs to know how to find the shard for each key, not only that, if for instance you are doing top-ten counts from this table, you will have to modify your query to get the top 10 from each shard and then merge them together for the global top 10 count. As you get more writes into a table may be as your business grow, you have to scale out to additional servers. The problem is, anytime you do that, you have to re-Shard the table into more Shards, meaning all of the data may need to be re-written to the Shards each time.
You quickly realize you can’t just run one script to do the resharding because it is taking too long to complete. You also have to do all the resharding in parallel and manage many active worker scripts at once. You find the same issue with top 10 queries so decide to run the individual shard queries run in parallel. Now let's say you forget to update the application code handling the database load with the new number of shards, this will cause many calculation/updates to be done in the wrong shards. Under such circumstances you quickly find out that your best option is to probably write a script to manually go through the data to place missing ones.
Eventually managing sharding processes gets more and more complex and painful because there’s so much work to coordinate. Not only that, all dependent downstream applications must be written to be aware of the distributed nature of the data. Now let's Imagine doing this on tens and hundreds of server, because that's the size of clusters some big data applications have to deal with nowadays. The challenges that face big data systems with regards to scalability and complexities could be generalized to include;
- How to continually manage nodes and their consistency
- How to write programs that are aware of each machine
- How to split problem across nodes
- How to deal with failures when it inevitably occur in cluster.
- How to deal with nodes that have not failed, but are very slow.
- Others include Ethernet networking and data locality issues.
Big Data System Developments
The big data systems today addresses these scalability and complexity issues effectively because they are built from the ground up aware of their distributed nature. So, things like sharding and replication are automatically handled. The logic to query datasets distributed over various nodes is implicit, so you’ll never get into a situation where you accidentally query the wrong node. When it comes to the time to scale horizontally, you just add nodes and the systems automatically rebalances your data onto the new nodes. These systems also build a more robust fault-tolerance through replication and making data immutable. Whereas traditional systems mutated data to avoid fast dataset growth, big data systems store raw information that is never modified on cheaper commodity hardware, so that when you mistakenly write bad data you don’t destroy good data.
There are also new programming paradigms that eliminates most of the parallel computation and other job coordination complexities associated with computation on distributed storage. These systems today comes with optimizers that can make cost based decision as to how and even where to parallelize computations in a cluster.
There has been a number of trends in technology that has deeply influence how big data systems are built today. Many were pioneered by the Web 2.0 companies such as Facebook, Google and Amazon.com followed by the open-source communities. The initial systems decouple big data storage from big data Compute. Google revolutionized the industry with;
- Hadoop distributed file systems (HDFS) for storage
- And Hadoop MapReduce framework for computation
Storage
HDFS is a distributed, fault-tolerant storage system that can scale to petabytes of data on commodity hardware. A typical file in HDFS could be gigabytes to terabytes in size and provides high aggregate data bandwidth and can scale to hundreds of nodes in a single cluster. It could support tens of millions of files on a single instance. It became the de-facto big data storage system, however recently there some technologies like MapR File System, Ceph, GPFS, Lustre etc. that claims can be used to replace HDFS in some use cases. HDFS is not without weaknesses but it seems to be the best system available today doing precisely what it was designed to do. It has manage to become the de-facto big data Storage system by being very reliable and delivering very high sequential read/write bandwidth at a very low cost.
Compute
Traditionally, distributed computations employed network programming where some form of message passing between nodes was used e.g. Message Passing Interface (MPI). These programming paradigms did not serve big data systems well, they were very difficult to scale to numerous nodes on commodity hardware. This gave rise to a new programing paradigm called Data Flow with characteristics that included:
- Restricting the programming interface so that the systems can do more automatically.
- Express jobs as graphs of high-level operators instead of message passing, here;
- The system picks how to split each operator into tasks and where to run each task
- Run parts twice for fault recovery
- Ability to scale to the largest clusters
MapReduce
Hadoop MapReduce is a horizontally scalable computation framework that emerged successfully using this new data flow programming technique. MapReduce can parallelize large-scale batch computations on very large amounts of data. MapReduce batch computation systems is a high throughput but high latency systems, they can do nearly arbitrary computations on very large amounts of data, but they may take hours or days to do so. As a result initially you did not use Hadoop for anything where you need low-latency results. Its speed limitation are due to replication and disk storage and that fact that States between steps goes to the distributed file system made it inefficiency for multi-pass algorithms, even though it is great at one-pass computation. These limitations inspired some various other systems available today. Some provided distributed computation abstractions (including SQL) over HDFS whiles others like NoSQL databases are a new breed of systems that provide comprehensive distributed storage and computation.
SQL-On-Hadoop
During the early days, the typical approach was to transfer data from Hadoop to a more traditional database to analyze it with SQL. It could be an MPP system such as PDW, Vertica, Teradata or a relational database such as SQL Server.
To enable their analysts with strong SQL skills but limited or no Java programming skills to analyze data directly in the Hadoop ecosystem, the data team at Facebook built a data warehouse system called Hive directly into the Hadoop ecosystem. Hive/HiveQL began the era of SQL-on-Hadoop. In the beginning Hive was slow mostly because query processes are converted into MapReduce jobs. These weaknesses have been addressed in one of two ways:
- Improvements to the original Hadoop and Hive functionality
- Creation of new external tools that address both the complexity and the speed issues.
Over time, Hive has improved, with the introduction of things like optimized row columnar, which greatly improved performance. At the same time many other external tools are also available on the market today; there are those that followed in the tradition of Hive that work with Hadoop file format eg CitusDB, Cloudera Impala, Apache Drill etc and few SQL database management systems like Microsoft PolyBase which provide SQL access to Hadoop data through polyglot persistence, which means that they are able store data natively in SQL Server or in Hadoop. Others include new programming tools like Spark which provide faster in-memory computations.
NoSQL
A new breed of databases used more and more in big data and real-time web / IoT applications also emerged. Early notable pioneers in the space was Amazon, which created an innovative distributed key/value store called Dynamo. The open source community responded in the years following with Apache HBase, MongoDB, Cassandra, RabbitMQ and many other projects. Many of these new technologies are grouped under the term NoSQL. In some ways, these new technologies are more complex than traditional databases, in that they all have different semantics and are meant to be used for specific purposes not for arbitrary data warehousing. Using these technologies often requires a fundamentally new set of techniques. On the hand they’re simpler than traditional database systems by their ability easily scale to vastly larger sets of data. They are all different in one way or the other, with each specializing in certain kinds of operations. The unique thing them is that even though they borrow heavily from SQL in many cases, they all sacrifice the rich expressive capabilities of SQL for simpler data models for better speeds. I will leave an in-depth NoSQL discussions for another time.
Other Technologies
The open source community has created a plethora other big data systems utilizing existing technologies over the past few years. The notable ones include:
Serialization Frameworks
Serialization frameworks provide tools and libraries for using objects between languages. In the context of big data storage systems, serialization is used to translate data structures or object state into a format that can be stored in a file, memory buffer or transmitted to be reconstruction later in a different environment. They can serialize an object into a byte array from one language and then deserialize that byte array into an object in another language. The serialization frameworks provides the schema definition language for defining objects and their fields and also ensures that objects are safely versioned so that their schema evolves without annulling existing objects. Some of the popular serialization frameworks include Thrift created by Facebook, Protocol Buffers created by Google, Apache Avro, JSON etc.
Messaging/Queuing Systems
A messaging/queuing system provides a way to send and consume messages between processes in a fault-tolerant and asynchronous manner. A message queue is a key component for doing real-time processing. Proprietary options like IBM WebSphere MQ, and those tied to specific operating systems, such as Microsoft Message Queuing have been around for a long time. There are also cloud-based message queuing service options, such as Amazon Simple Queue Service (SQS), StormMQ, and IronMQ offered as SaaS. The more popular ones nowadays are the open source ones, including Apache Kafka, Apache ActiveMQ, Apache Qpid, etc.
Realtime Computation Systems
These are distributed stream/realtime computation frameworks with high throughput and low latency. Whilst they lack the range of computations a batch-processing system can do, they make with the ability process messages extremely fast. The stream processing paradigm simplifies parallel computation that can be performed. Given a sequence of data (a stream), a series of operations (kernel functions) is applied to each element in the stream. Some of the popular ones are in the apache open-source foundation including Storm, Flink, Spark. Apache Spark has become particularly interesting in that it is able ingests data in mini-batches and performs RDD transformations on those mini-batches of data. This design enables the same set of application code written for batch analytics to be used in streaming analytics, this convenience however comes with the penalty of latency equal to the mini-batch duration. Storm and Flink on the other hand process event by event rather than in mini-batches. Also available are some Stream Processing Services: Kinesis (Amazon), Dataflow (Google) and Azure - Stream Analytics (Microsoft)
New Big Data Processing Architecture
Unlike traditional data warehouse / business intelligence (DW/BI) with tried and tested design architecture, end-to-end big data design approach is had been non-existent. This could be attributed to the variety and volume of data and opportunities to design various systems in different ways. But this is changing with the emergence of some new design approaches which has also sparked that discussions.
Lambda Architecture
Available big data system tools today on their own are not able to meet the variety organizational data processing needs which include batch to real-time system and everything in between. But when intelligently used in conjunction with one another, it possible produce scalable systems for arbitrary data problems with human-fault tolerance and minimum complexity. This is what the Lambda architecture proposes with its approach.
The Lambda Architecture suggests a general-purpose approach to implementing an arbitrary function on an arbitrary dataset and having the function return its results with low latency.[2] That doesn’t mean you’ll always use the exact same technologies every time you implement a data system. The specific technologies you use might change depending on your requirements. What the Lambda Architecture does is define a consistent approach to choosing those technologies and to wiring them together to meet your requirements.
The main idea of the Lambda Architecture is to build big data systems as a series of layers which include a Batch Layer (for batch processing), a Speed Layer (for real-time processing) and Serving Layer (responding to queries). Each layer satisfies a subset of the properties and builds upon the functionality provided by the layers beneath it. The architecture employs a systematic design, implementation and deployment of each layer, with ideas of how the whole system fits together.
Figure 1 below is a diagram of the Lambda Architecture showing how queries are resolved by looking at both the batch and real-time views and merging the results together.
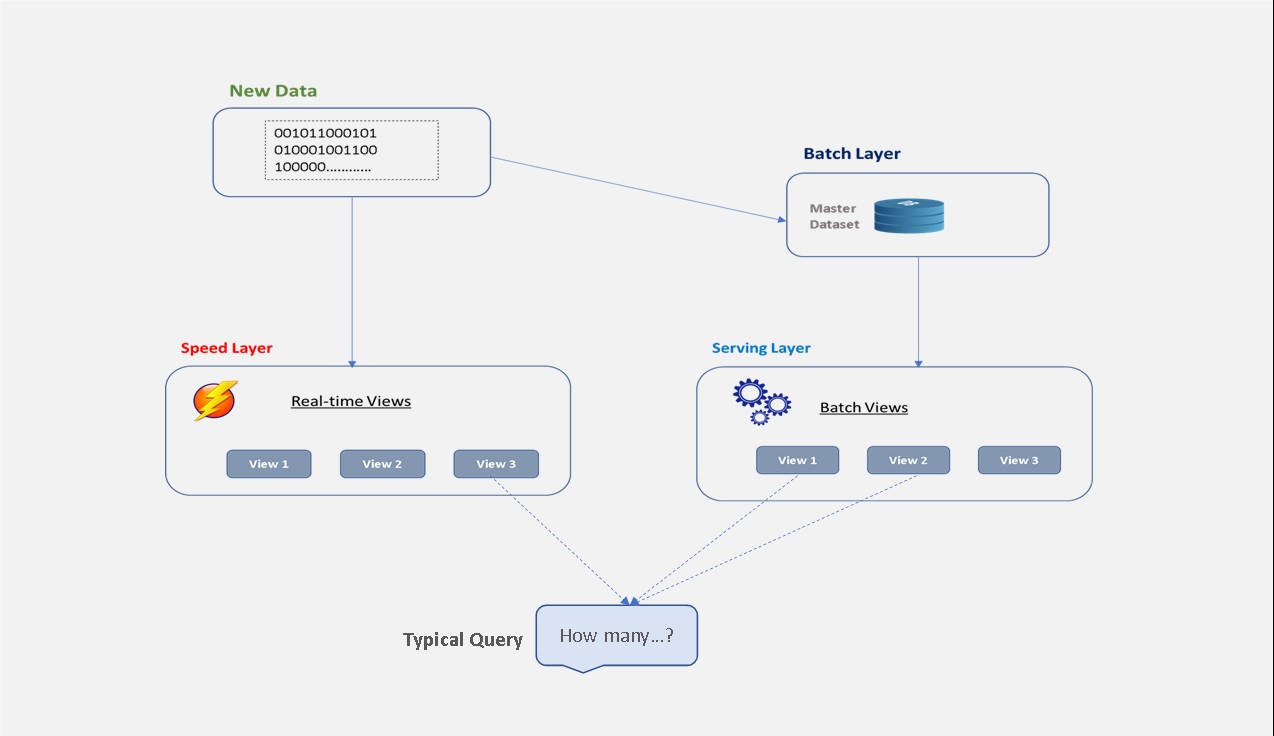
Figure 1 showing the Lambda Architecture diagram
- The batch layer is responsible for two things, first, storing an immutable, constantly growing master dataset and secondly precomputing batch views on the master dataset. Hadoop is a typical batch-processing system ideal for a batch layer.
- The serving layer relegates all random write which causes database problems to the batch layer and focuses on loading batch view from the batch layer into a specialized distributed database design for batch updates and random reads. When new batch views becomes available, the serving layer automatically swaps them for the old ones ensuring availability of more up-to-date results.
- The speed layer uses databases that support both random reads and random writes and thus are more complex those of the batch and serving layers. Its goal is to ensure that query function results on new data is presented as quickly as needed for the application requirements. So unlike the batch layer looks at all the data at once the speed layer only looks at recent data.
SQL-On-Big Hadoop ( Polybase, Hive, Spark )
Ability to run ANSI SQL based queries against distributed data without implementing techniques like Sharding we now know is a blessing. However it is imperative to understand the architecture of these SQL-On-Hadoop abstractions in other to make the right selections to meet the various organizational needs out there. In this section we will have a high-level look of three SQL-On-Hadoop abstractions namely Polybase, Hive and Spark SQL. This will not be an exhaustive discussion on how to choose among them but rather, how the distributed data on Hadoop HDFS cluster affects the architecture and computation by these three systems. We will look at how these system are architected to run adhoc SQL/SQL-like queries against HDFS files as external Data Source, which otherwise would have required Java MapReduce programing. In all our discussion, we will assume a target Hadoop cluster with four nodes and core HDFS component like Yarn/MapReduce with Jobhistory server enabled.
Polybase
Polybase is a technology that makes it easier to access, merge and query both non-relational and relational data all from within SQL Server using the T-SQL command ( Note that Polybase can be used with Azure SQL DW And Analytics Platform System ).
We will be looking at Polybase as used with SQL Server to query external non-relational data on a Hadoop cluster enabling the use of T-SQL as an abstraction to bypass MapReduce coding.
You can configure a single SQL server instance for Polybase and to improve query performance you may enable computations push down to Hadoop which under the hood creates MapReduce jobs and leverages Hadoop’s distributed computational resources. However to process very large data sets and for better query performance the PolyBase Group feature which allows you to create a cluster of SQL Server instances to process external data sources in a scale-out fashion may be the only option. Similar to scaling out Hadoop to multiple compute nodes, this setup enables parallel data transfer between SQL Server instances and Hadoop nodes by adding compute resources for operating on the external data. In this architecture, you install SQL Server with PolyBase on multiple machines as compute nodes and then designate only one as the head node in the cluster. SQL server requires that the machines are in the same domain. Figure 1 below shows a diagram of a three node Polybase Scale-Group architecture on a four node HDFS cluster.
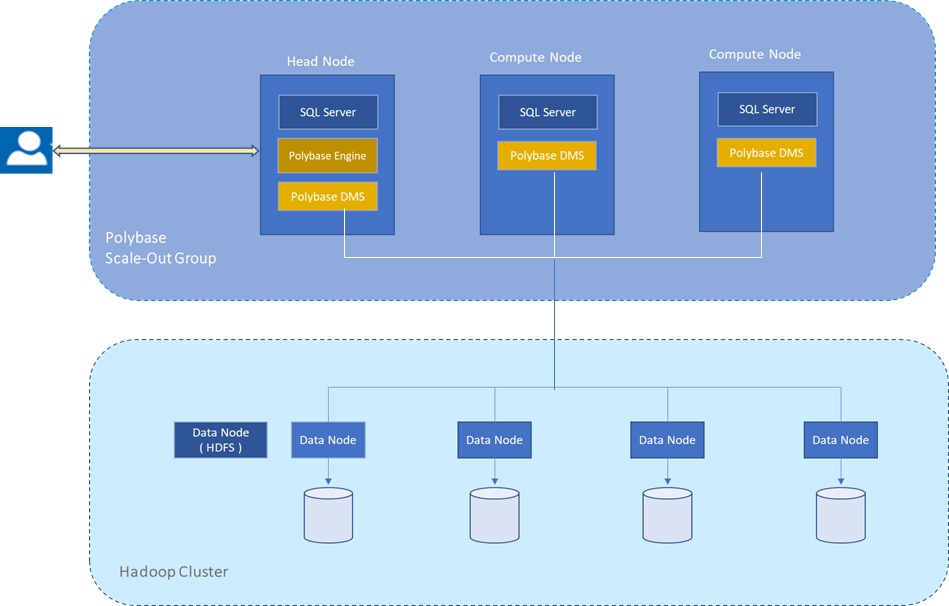
Figure 2: Shows high level view Polybase Scale-Group architecture on a four node HDFS cluster
As shown on figure 2, a head node is a logical group of SQL Database Engine, PolyBase Engine and Polybase Data Movement Service on a SQL Server instance whiles a compute node is a logical group of SQL Server and the Polybase data movement service on a SQL Server instance.
Polybase queries are submitted to the SQL Server on the head node and the part of the query that touches external tables is sent to the Polybase engine. The head node parses the query and generates the query plan and distributes the work to the data movement service(DMS) on the compute nodes for execution. The DMS are also responsible for transferring data between HDFS and SQL Server, and between SQL Server instances on the head and compute nodes. After the work is completed on the compute nodes, they are submitted to SQL Server for final processing and shipment to the client. When Polybase External Pushdown feature is not enabled all of the data is streamed over into SQL Server and stored in multiple temp table (or a temp tables if you have a single instance), after which the Polybase engine coordinates the computations. On the other hand significant performance may achieved by enabling the External Pushdown feature for heavy computations on larger dataset. When enabled the query optimizer makes a cost-based decision to push down some of the computation to Hadoop to improve query performance. It uses statistics on external tables to make the cost-based decision. Note that Pushing down computation leverages Hadoop’s distributed computational resources but this creates MapReduce jobs that can take a few seconds more to start up, therefore scenarios should be tested before using this operation. For instance in a scale-out group mode with enough compute nodes, there may not be any value in pushing work down to your Hadoop cluster to trigger MapReduce Jobs if you observe faster times by pulling the entire data set and performing your filters and other operations in SQL Server.
Hive
Hive was built as a data warehouse-like infrastructure on top of Hadoop and MapReduce framework with a simple SQL-like query language called HiveQL. While HiveQL is SQL, it does not strictly follow the full SQL-92 standard. As you write HiveQL queries, under the hood, the queries are mostly converted to MapReduce jobs and executed on Hadoop. Figure1 below shows a high level view of Hive architecture and how it ships HiveQL queries to be executed as mostly as MapReduce jobs on Hadoop clusters.
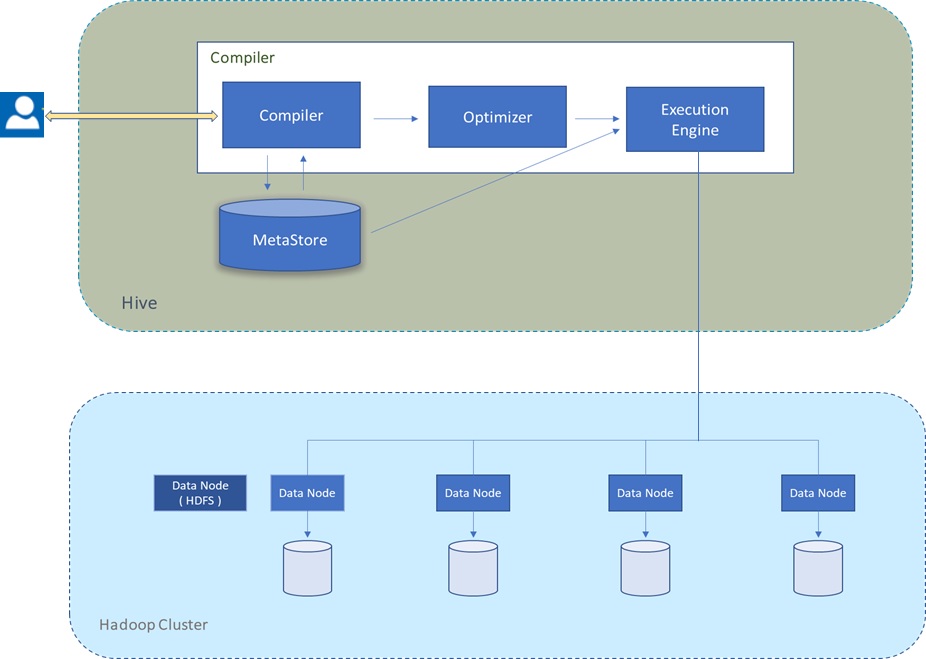
Figure 3: Showing a high level view of Hive architecture on a four node HDFS cluster
Within the driver, the compiler component generates an execution plan by parsing queries using table metadata and necessary read/write information from the Metastore. The plan is optimized and then passed to the engine to execute the initial required steps and then sends MapReduce to Hadoop. The execution engine delivers results ( received from Hadoop and/or prepared locally) to the client. Unlike Polybase Hive relies on the heavily on the Hadoop cluster and automatically pushes MapReduce computations to it. More on Hive can be found here SQL-On-Hadoop : Hive-Part 1.
The Hive Metastore as indicated on Figure 3 is a logical system consisting of a relational database (metastore database) and a Hive service (metastore service) that provides metadata access to Hive and other systems. By default, Hive uses a built-in Derby SQL Server database. This Database is normally sufficient for single process storage, however for clusters, MySQL or a similar relational database is required. You have the option of using SQL Server or other relational database as the metastore database.
Spark and Spark SQL
Spark is a framework for performing general data analytics on distributed computing clusters including Hadoop. Unlike Hive and Polybase It utilizes in-memory computations for increase speed and data processing. Spark achieves this tremendous speed with the help of a data abstraction called Resilient Distributed Dataset (RDD) and an abstraction of RDD objects (RDD lineage) called Directed Acyclic Graph (DAG) resulting in an advanced execution engine that supports acyclic data flow and in-memory computing. This means that, in situations where MapReduce for instance must write out intermediate results to the distributed filesystem, Spark can pass them directly to the next step in the pipeline.
Figure 4 below shows a high level view of spark architecture of how RDDs in spark applications are laid out across the cluster of machines as a collection of partitions which are logical division of data, each including a subset of the data. Partitions do not span multiple machines and are basic units of parallelism in Spark. RDDs are fault tolerant data-structure that knows how to rebuild themselves because Spark stores the sequence of events used to create each RDD.
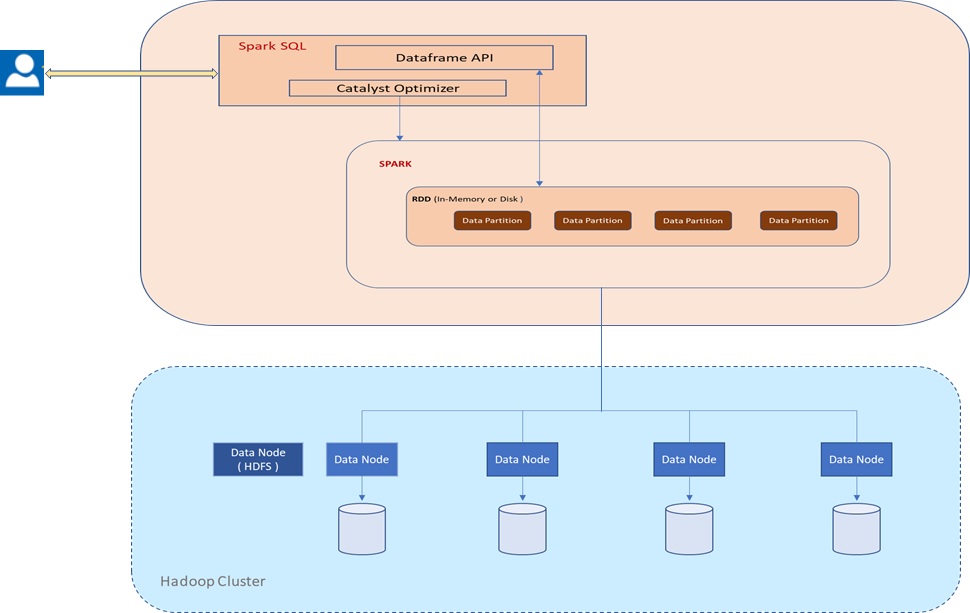
Figure 4: Showing a high level view of Hive architecture on a four node HDFS cluster
Spark SQL is a Spark module for structured data processing. Unlike the basic Spark RDD API mentioned above, the interfaces that comes with Spark SQL provide Spark with more information about the structure of both the data and the computation being performed. Internally, Spark SQL uses this extra information to perform extra optimizations.
The main API in Spark SQL is the DataFrame, a distributed collection of rows with the same schema. Unlike RDDs, DataFrames keep track of their schema and support various relational operations that lead to more optimized execution. They are conceptually equivalent to a table in a relational database or a Dataframe in R/Python, but with richer optimizations under the hood since their operations go through a relational optimizer, Catalyst.
They store data in a more efficiently in columnar format that is significantly more compact than Java/Python objects. DataFrames can be constructed from a wide array of sources such as: structured data files, tables in Hive, external databases, or existing RDDs. They enable easy integration of relational processing with Spark’s functional programming API and the ability to easily perform multiple types of computations on big data that might previously have required different engines. Once constructed, they can be manipulated with various relational operators, such as where and groupBy, which take expressions in a domain-specific language (DSL) similar to Dataframes in R and Python. At a high level DataFrame can be viewed as an RDD of Row objects, allowing users to call procedural Spark APIs such as map.
In distributed mode, Spark uses a master/slave architecture which is independent of the architecture of the underlying HDFS luster it is running on. Spark is agnostic to the underlying cluster manager making it relatively easy to run it on a cluster manager that also supports other applications (e.g. Mesos ).
We will have an in-depth look into Spark SQL later on this forum.
Summary
The different architecture of SQL-on-Hadoop systems and how they compute distributed data makes each one ideal for specific scenarios. For instance PolyBase is ideal for leveraging existing skill sets and BI tools in SQL Server. It presents the opportunity to operate on non-relational data that is external to SQL Server with T-SQL. It enables the ability to join information from a data warehouse in SQL Server and data from Hadoop to creating real-time customer information or new business insights using T-SQL and SQL Server. Polybase can also simplify the ETL process for Data Lakes.
Hive's HiveQL statements are automatically translated into MapReduce jobs so they could be slow for certain types of analytics. It is however ideal for batch data preparation and ETL to schedule processing of ingested Hadoop data into cleaned consumable form for upstream applications and users. It is currently one of the most widely used data preparation tool for Hadoop. It was built directly on top of Hadoop so it does not require additional scale out setups to scale to very large volumes of data.
Unlike MapReduce, the in-memory caching capability of parallelizable distributed dataset in Spark enables more advance and fast forms of Data flow programming paradigms useful for streaming and interactive applications. SQL queries are also fast because they are not converted to MapReduce jobs like Hive and Polybase (in some cases). Spark also makes easy to just bind SQL API with other programing language like Python and R enabling all types computations that might have previously required different engines. Apache Spark and SparkQL directly integrates with Hive.
Conclusion
big data systems have evolve over time but the challenges of architecting end-to-end big data solutions does not seem have abated, not only as a result of more and data but the need for computational speed in the variety of innovative ideas out there. In this article we tried to understand the general distributed data storage and computational challenges big data systems face and how they are resolved by these tools. The high-level understanding of these challenges is crucial because it affects the tool and architectures we choose to address our big data needs. We learned that unlike RDBMs, big data systems including the SQL abstraction computation systems like Polybase, Hive and Spark SQL and the underlying distributed storage systems addresses scalability and complexity issues very effectively but in different ways. We learned how these systems are aware of their distributed nature, such that for instance SQL Server optimizer in a Polysbase system setup makes cost based decisions to push MapReduce computations down to underlying HDFS cluster when necessary.
We also learned that even with the plethora of technologies, no one tool or system has manage to become a panacea for solving all of big data Storage and/or compute challenges, which means that solving end-to-end enterprise level big data solutions require a new thinking. This have ushered in new data storage and processing architecture suggestions and discussions such as the Lambda Architecture, which suggests a comprehensive approach that make tool selection dependent on requirements rather than exact technologies in the implementation of big data system solutions. It defines a consistent approach to choosing these technologies and to wiring them together to meet your requirements, an architecture some prominent firms are known to have adopted. It by no means have it critics, but certainly worth looking at.
References
- Wikipedia, distributed computing, https://en.wikipedia.org/wiki/Distributed_computing, accessed on 09/07/2017.
- Nathan Marz and James Warren, big data; Principles and best practices of scalable realtime data systems
- Sharding Patterns, https://docs.microsoft.com/en-us/azure/architecture/patterns/sharding, Microsoft Azure Docs, accessed on 03/07/201
- Database Sharding, Brent Ozar, https://www.brentozar.com/articles/sharding/
- distributed computing with Spark, Reza Zadeh (Stanford), http://stanford.edu/~rezab/slides/bayacm_spark.pdf
