

 | Thus always to NULL |  |
In previous articles I've discussed SQL NULLs and practical methods for dealing with them
on SQL Server, in the real world. Although I have mentioned previously that the use of NULL
should be minimized in the database ("minimized" meaning as close to zero as
practical), it has been suggested that I have not placed enough emphasis on NULL-avoidance.
It has even been suggested that NULLs should not be dealt with in the real world at all. I
intend to address some of these arguments in this article, and apply the advice of some of the
more prolific experts to implement a "Zero-NULL" database in SQL.
The Rules
Before we begin eliminating NULLs, we're going to lay down a few ground rules. The intent is to
get rid of all NULLs from the database, period. To that end we will adhere strictly to the
following:
- We will be using SQL as implemented on SQL Server to create our sample database, to
execute all our queries, and to generate our solution. We will not be using any hypothetical
computers, "toy languages", or any other exotic or purely academic tools to
implement the Zero-NULL database.
- By the time we finish we will store no NULLs in the Zero-NULL database.
- Other than to declare our columns NOT NULL (so that we cannot store NULLs in them), we will
not even deal with NULLs in the final Zero-NULL database. This also means no NULL-handling
functions like COALESCE and ISNULL, or NULL comparison operators like IS NULL and IS NOT
NULL.
- We will limit ourselves to joins that cannot generate NULLs in the result set. This means
no full outer joins, left joins, right joins, etc. Only INNER JOINs will be allowed.
Because we'll be discussing the practicality of eliminating all NULLs from a SQL database,
we will consider several aspects, including development complexity, maintenance costs, and
performance.
The Baseline
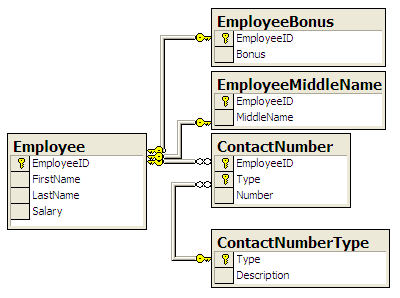
Our starter database is a simple database designed to hold some basic employee information.
This is the database from which we will eliminate all traces of NULL. The tables look like
this:
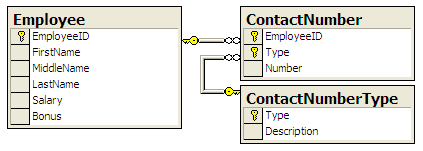
And the script to create and populate these tables is given below:
-- Here we create a table of contact number types |
The following sample query retrieves all employee data:
-- Simple query to retrieve all employee data |
And the result looks like this:

As for performance, SQL Server reports a query execution plan with a total cost of 0.0510,
with an execution plan that looks like this:
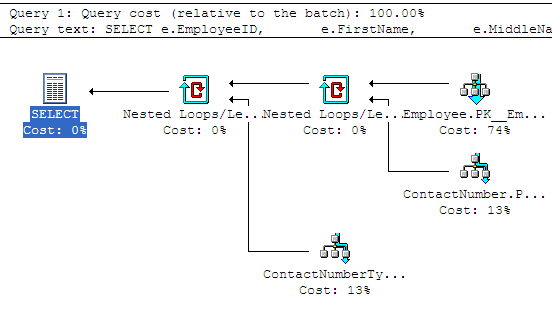
Now that we have a baseline, it's time to start the step-by-step process of eliminating all trace
of NULL from the database.
The First Steps
In Fabian Pascal's "Nulls Nullified" article, he brings up a point about the
confusion between the "absence of data", and "how such absence is
represented and manipulated in databases."
| NOTE: Prior to writing this article, I contacted Pascal with a list of questions concerning his article, "Nulls Nullified" (DBAZine.com). Though he did not answer my questions, he was kind enough to supply a link where his thoughts are available for a fee. |
We can easily address Pascal's issue with using NULL to represent the "absence of
data" by simply not storing NULLs in the database. We will simply make all of the columns
non-nullable and represent the "absence of data" by breaking out nullable columns
into new tables with 1:0..1 relationships, without regard for so-called "attribute
splitting." In our example this means breaking the nullable MiddleName and Bonus
columns out into their own tables with EmployeeID as the Primary Key, in 1:0..1 relationships
with Employee.
-- Changes to initial database to prevent NULLs from being |
Here is the newly created Zero-NULL database:
Step Two: Eliminating NULL From Results
The query to grab all employee information from our revised database now looks like this:
-- Retrieve all employee data from the revised tables |
And this leads us right into the second part of Pascal's complaint concerning "how such
absence is represented and manipulated in databases." This cannot be as easily dismissed
in SQL as one might wish. If we eliminate the LEFT JOINs in the query
above, for instance, the query fails to retrieve a complete list of employees:
--Removing the LEFT JOINs from our query |
The result of this query is one row:

Converting the LEFT JOINs to INNER JOINs results in a simple "all-or-nothing"
proposition when querying the database. Any employees who are missing any "optional"
data are not returned by the query. There are two workarounds to this problem:
- Query the data multiple times and return all data in multiple result sets, each with a different
structure.
- UNION the results of multiple queries together and create arbitrary query-specific
placeholders for missing data.
Implementing the first option for the example database requires eight total queries to ensure that all the
required data is returned in every required format. The possible combinations are represented in the table
below, with "yes" indicating the optional information is available for the employee, and
"no" indicating the optional information is not available for the employee:
| Combination # | Middle Name | Bonus | Contact Number |
|---|---|---|---|
| 1 | yes | yes | yes |
| 2 | yes | yes | no |
| 3 | yes | no | yes |
| 4 | yes | no | no |
| 5 | no | yes | yes |
| 6 | no | yes | no |
| 7 | no | no | yes |
| 8 | no | no | no |
You can easily calculate how many individual queries are needed for any number of optional values.
The total number of individual queries needed is simply 2n where n is the
number of optional values that can be represented. It is up to the client to handle the
2n different result sets returned.
The second option is marginally "better", since it allows you to return a single
result set to the client. Like the first option, you still have to create eight separate
queries, but you get to UNION them all together to create a "single-query" façade.
Additionally, you get to show your creative side by defining several arbitrary query-specific
placeholders. Here is a query based on the second option:
-- First grab the employees with Bonus, Contact Number, and Middle Name |
The results look like this:

Notice the use of the arbitrary placeholders 'NO MIDDLE NAME', 'NO CONTACT NUMBER', and
'NO CONTACT NUMBER TYPE'. You would be forced to cast all bonus amounts to a character data
type (VARCHAR, etc.) if you used a string like 'NO BONUS' as a missing data indicator for
the Bonus column.
Instead the query uses the "magic number" -99999.99 to indicate no bonus. The cost of
performing this query is 0.411, or just over 8 times the cost of our original query. The query execution plan is fairly large for this one, but here's a portion of it:
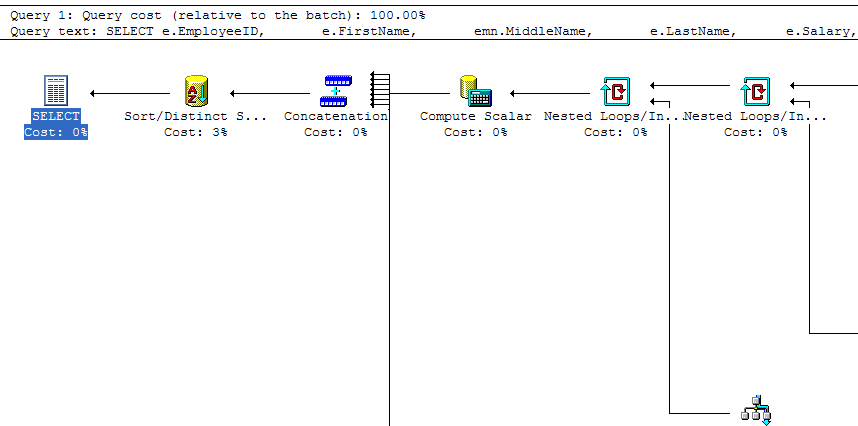
At this point we've effectively eliminated all traces of NULL from the Zero-NULL database. We've also demonstrated several key points:
- The code required to query the Zero-NULL database is significantly more verbose –
if not more complex – than that required to query the original database. It will probably
have a much higher cost to debug and maintain as well.
- You need to define your own special placeholders to indicate missing data. These special
placeholders are query- and/or application-specific. You have the option of either: (a)
casting all columns to a character data type (VARCHAR, NVARCHAR, etc.), or (b) using
query-specific "magic numbers" to indicate numeric and date/time missing data
placeholders. Either way your client-side applications need to be designed to handle your own
special placeholders.
- You can expect a serious performance hit on SQL Server using this method.
We did not consider the implications of adding unique constraints to the tables in this example. I'll
leave it as an exercise to the reader to simulate a simple unique constraint on (FirstName,
MiddleName, LastName) in the Zero-NULL database.
If you're not excited at the prospect of eliminating all NULLs yet, let's see if Sixth
Normal Form provides that extra necessary motivation.
Sixth Normal Form
If you really want to be rigorous in your NULL elimination, decompose your database into
Darwen and Date's Sixth Normal Form (6NF). A table is in 6NF if it satisfies no nontrivial
join dependencies. Darwen summarizes 6NF very succinctly in his paper "How to Handle
Missing Information Without Nulls":
| A 6NF table is a key plus at most one other column. | |
This script creates the Zero-NULL database in 6NF:
CREATE TABLE ContactNumberType (Type CHAR(1) NOT NULL PRIMARY KEY, |
Queries, foreign key constraints, and unique constraints for the 6NF version of the Zero-NULL database are
left as an exercise for the reader.
NULL Misuse
Getting back to Pascal's "Nulls Nullified" article, the author continues his
example of storing "inapplicable data" in a SQL database by suggesting that NULLs
are commonly stored in an employee database for those employees that do not earn a commission;
that is, those employees for which commission is "inapplicable".
| On the one hand, in the real world those employees do not earn a commission, period. Yet, on the other hand, the place for COMMISSION values is present for the rows representing those employees, as if they did earn a commission. |
In his example Pascal is using NULL to represent a known amount of commission.
Specifically, the amount is exactly 0.00. Using NULL
to represent zero is misuse use of NULL that I covered in previous articles, and
I won't re-hash it here. Pascal goes on to state:
| If both inapplicable and unknown values are represented by NULLs, the DBMS won't be able to distinguish them and will produce incorrect results. |
He is correct to use the word if in this sentence. If, on the other hand, you use
NULLs only to represent unknown values you won't ever encounter this
particular issue. Just as you would not use the number "1" to represent both
"1" and "2", NULL should not be used to represent both "inapplicable"
and "unknown".
Dr. Codd himself recognized the inadequacy of using a single NULL mark to represent two
different concepts. He later recommended the introduction of two types of NULL mark (and an
accompanying 4-valued logic) to represent both "Missing but Applicable" and
"Missing but Inapplicable" (Codd, The Relational Model for Database Management:
Version 2).
| NOTE: I am a firm believer that Dr. Codds Relational Model already provides us with the tools to properly store the fact that a value is missing as well as the reason without additional NULL marks or 4-valued logic. The fact of the matter is that you would not (hopefully) store two separate attributes in the same column, like "Short but skinny" or "Silver but dirty". The conjunction "but" provides a strong indicator that you need multiple columns to store these two distinct pieces of data. The same holds true for unknown/missing data. NULL should be used to indicate a value is unknown, and the reason it is unknown should be stored in a separate column. |
Pascal goes on to address "defenders of NULLs":
| What defenders of NULLs fail to appreciate is that the existence of NULLs forces the same kind of complexity in SQL queries that special values produced in application code prior to databases |
I've seen no evidence that a single "special value" with a well-defined behavior
(system-wide) incurs the "same kind of complexity in SQL" that
potentially hundreds of arbitrary application-specific (or even query-specific) user-defined
"special values" produces. In fact, the exact opposite appears to be true in the
real world. Pascal further asserts:
| Either the NULL is unnecessary, in which case it should not be in the language; or it is necessary, in which case not using it is not an option. SQL seems to want to have it both ways... |
As we've seen, it is not "necessary" to store NULLs in a SQL database or to even
retrieve them in result sets, so long as you avoid outer joins like the plague. By the
same logic, looping constructs (e.g., For...Next, While, Do...Repeat and equivalents) are
"unnecessary" in procedural languages that have the equivalent of If...Then and
Goto statements; therefore they should not be in their respective languages. Unless you
"want to have it both ways", that is.
ANSI Flaws = NULLs Bad?
NULL critics are quick to point to flaws in the definitions of ANSI SQL
convenience functions (like the aggregate functions) as proof that the entire concept of
NULL itself is flawed. Hugh Darwen, in his presentation "The Askew Wall",
takes on NULL with selected examples where SQL 3-valued logic (3VL)
and NULL can cause "unexpected" results:
| 1. SELECT * FROM T WHERE X = Y OR NOT ( X = Y ) |
As SQL developers, we are already aware of these issues, and none of the results they
produce are actually "unexpected". Darwen's examples #1 and #3 produce the result we
expect if we know the following simple rule:
- By definition, trying to compare NULL to anything (even another NULL) does not result in
True or False, but rather Unknown; and NOT(Unknown) is also Unknown.
It's a trivial matter to modify Darwen's examples to properly use SQL's 3-valued logic, and I'll
leave that as an exercise for the reader.
SQL developers should not be surprised by Darwen's example #2 either. We already know that
X + Y results in NULL if X or Y is NULL, and SUM (per the ANSI SQL definition) discards NULLs. The simple
solution here (this assumes you're actually looking for solutions) is to use the aggregate
function in accordance with its documented behaviors to obtain the results you seek. A couple
of other options, if you feel that SUM(column) doesn't behave the way you feel it should,
are:
- Use the COALESCE function or a CASE expression in your SELECT to override SUM's
NULL-handling,
- Write a simple SQL Server user-defined function to produce the results you want, or
- Write a SQLCLR user-defined aggregate that treats NULL however you desire.
Pascal may have said it best when he wrote:
| How the function calculation should treat missing values is not governed by the relational model. The DBMS should offer user-options to that effect e.g. ignore missing values, use default values, etc. |
You can easily do as Pascal suggests using standard SQL functionality. As an example here's
SUM(X + Y) using COALESCE to produce the same results
as SUM(X) + SUM(Y):
SELECT SUM(COALESCE(X, 0) + COALESCE(Y, 0)) |
Another common example cited by NULL critics is that the SUM of the empty set should
be zero. ANSI defines the result of SUM(column) on a table with no rows as NULL. The easy
answer, if you want the SUM of a table with no rows to return zero instead of NULL, is to use
SQL's COALESCE function, as in the following example:
SELECT COALESCE(SUM(X), 0) |
Additionally, if you think SUM should return NULL if the column contains a NULL, you can use CASE to
achieve that in a query as well:
SELECT CASE WHEN COUNT(*) = 0 THEN 0 |
On SQL Server you can encapsulate such logic in a user-defined function that performs these
aggregations and handles NULL in any manner you see fit.
As Pascal pointed out, aggregate function treatment of missing values is irrelevant to the discussion.
Even if aggregate function NULL-handling in SQL raises your eyebrows, SQL Server provides
sufficient means for creating your own user-defined functions and user-defined aggregates.
With these tools you can implement your own "user-options" that treat missing
values in any manner you choose.
Conclusions
In this article I've addressed some of the arguments made by critics of SQL NULLs,
and used a short example to demonstrate what life without NULL in SQL really entails.
On the other hand, there are those who would recommend a less dramatic method of dealing
with NULL, namely: "learn how to use them properly, and minimize their use where practical."
©2007 by Michael Coles, regular contributor to SQLServerCentral and author of the upcoming Apress book Pro T-SQL 2005 Programmer's Guide (April 2007). |

