

We often talk about the advantage that SharePoint offers organizations: sharing content to help with business intelligence needs. As we all know, disasters can happen in our world. Anyone can lose important data. In SharePoint, how many times have we seen a user mistakenly delete a document, a list, or a whole site collection? Probably many times, and, usually, it’s easy to restore the lost item within minutes. But imagine if a disaster happened and your whole SharePoint farm was lost. What would your options be then? How soon could you bring your SharePoint farm back online—and what would your strategy be? It’s not as easy as restoring a site.
Different organizations have different needs, timelines, and budgets for disaster recovery plans. For example, a small company might want to look for the cheapest option, while a large corporation, like a bank, will look for a quick and efficient option.
Let’s talk about the quickest and most efficient method to bring SharePoint farms back online in the event of disaster. In this article, I will explain a hot standby disaster recovery process where the SharePoint farm will become available within minutes. We will take the scenario of a basic SharePoint farm consisting of two SharePoint servers and a content database server, as shown in this image.
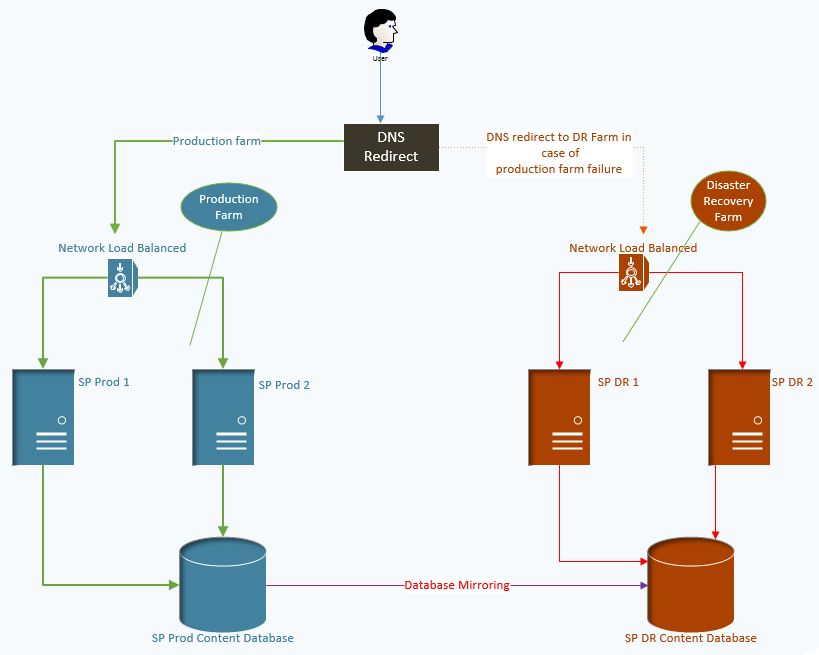
Here I have created two sample SharePoint farms. One is named the Production Farm (left side) and is currently online. One is named the Disaster Recovery Farm (right side) and is currently offline. Traffic is routed to the Production Farm. There is also continuous content database mirroring between the two farms. In the event of failure, we will failover from the Production Farm to the Disaster Recovery Farm. In this article, I will explain how to create a Disaster Recovery Farm, how to failover to the Disaster Recovery Farm, and how to maintain the Disaster Recovery Farm.
Create a Disaster Recovery Farm
For quick, efficient availability, we will be creating a Disaster Recovery Farm which has the same architecture as the Production Farm. Therefore, when switching over to the Disaster Recovery Farm, there will only be a few changes we can make quickly. Below are the steps to create a Disaster Recovery Farm:
- Create a Disaster Recovery SharePoint Farm which will have the same infrastructure as the Production Farm.
- All software versions should be the same as in the Production Farm (SharePoint, SQL server, Window server and third party tools).
- There should be continuous Database Mirroring from Production to the Disaster Recovery content databases.
- Create all service applications exactly the same as in Production.
- Install and deploy all wsp solutions the same as in Production.
- Create all web applications the same as in Production, but these web applications should not have new databases attached to them.
Step by Step Failover to the Disaster Recovery Farm
Now, in the event of a Production Farm failure, how will you failover to the Disaster Recovery Farm? By following the hot standby disaster recovery process, we have made it much easier than other disaster recovery processes. There will only be a few steps:
- Remove database mirroring. By removing database mirroring, the content database will be ready to mount on SharePoint web applications in the Disaster Recovery Farm.
- Mount content databases to all web applications. If you have many content databases, it will be wise to have a PowerShell script ready to mount all the databases at once.
- Perform a DNS redirect to the Disaster Recovery Farm for the farm domain URL.
- Test all the applications.
Those are the basic steps of switching to a Disaster Recovery Farm. Once completed, your farm will be available to users in minutes. Now, each and every SharePoint farm is different, so you may need additional changes. For example, if you have SQL Server Reporting Services integrated into your SharePoint farm, you might need to change the data connections strings at the site collection level. Again, you can create a PowerShell script to do this as there can be many data connections. In the managed metadata service application, managed metadata stores each term as a unique identifier (GUID).You should have a plan in place to move terms and term sets.
Disaster Recovery Farm Maintenance
Once the Disaster Recovery Farm has been created, it’s imperative to do continuous maintenance. Disaster Recovery Farm maintenance should be exactly the same as for the Production Farm. If you are applying SharePoint patches every two months in the Production Farm, then you should follow the same schedule for the Disaster Recovery Farm, for both operating system and SQL Server updates.
All custom solutions (wsp) should be the same as in the Production Farm. Whenever there is a new version of wsp applied in production, you will need to repeat the same steps in the Disaster Recovery (DR) Farm. We all make changes to web config files. You will need to make sure that these changes are copied to the DR Farm. External content types in the Production Farm should be the same in the DR Farm.
If you have Business intelligence capabilities in your SharePoint farm (SQL server reporting services, SQL server analysis service and Performance Point server), then you will need to make sure all pieces of Business intelligence software are installed on the DR Farm. The Site Collection administrator will have a bigger part to play as they want to make sure all data connections and features are working as expected. Site collection administrators will make sure that data is getting populated in their reports and dashboards.
Recommendations
As mentioned earlier, each corporation will have preferences for a disaster recovery plan. There are two other kinds of disaster recovery methods: cold standby and warm standby disaster recovery. These can be used as preferred and can be cost-effective.
It can be challenging to write a disaster recovery plan. I recommend scheduling a few sessions with the required people to discuss the need for disaster recovery and to discuss specific plans. Make sure your disaster recovery plan will work in the case it’s needed. You can do a practice run and involve all the teams related to it. I recommend having a practice run once every six months. That way, your disaster recovery plan will be fool-proof. Have a thorough plan for your service applications, for example, your search service application. Big organizations will have millions of items to crawl, and it can take few days to run search crawl. One common mistake is with server patches. Make sure the Production and Disaster Recovery farms have the same patch level.
