

A few years ago I wrote some TSQL code for selecting all Employees who report to a selected Supervisor. The code wasn't fast. It handled records one at a time. It had cursors. It had procedures calling other procedures. It did not take advantage of SQL Server's ability to insert sets of data.
I've been reading SQLServerCentral for some time now. I wondered how different that kind of code would be if I were to write it from scratch today with what I've learned.
The code would not be specific to hierarchies of Employee and Supervisor records. It could be used for other structures too. When going downstream one Employee can be the Supervisor for several other Employees, and so on down the line. Not so when going upstream. For this example an Employee can have only one Supervisor.
That weekend I wrote some new code. On similar databases the new code runs in about one-eighth the clock time and about one-tenth the CPU time of the old kind of code. It uses set operations but it is not purely set oriented code.
If pure set operations is a requirement in your environment please do not use this code.
I started by creating a table of Employee records. The key of the table is the EmpID. The SupID in each Employee record contains the EmpID of the Supervisor of the Employee.
[EmpID] [int] NOT NULL, [EmpName] [varchar](50), [SupID] [int] NULL
If an Employee has no Supervisor, as is the case with the CEO, the SupID will be NULL or zero.
The SupID only points from an Employee to the Supervisor immediately above him or her. There are no pointers from a Supervisor to Employee(s) below.
Sample Table and Logical Hierarchy
We will look at some TSQL that will create and load the sample table for this example. The code will set up the following logical hierarchy of records.
The Employee IDs are in brackets.
[3] Baker
[1] Chandler
[5] Franklin
[6] Allen
[2] Enos
[4] Davis
[7] Gray
The table will have this content.
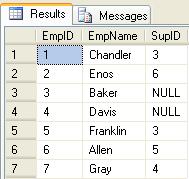
Create and load the table with this TSQL.
CREATE TABLE [Employee](
[EmpID] [int] NOT NULL,
[EmpName] [varchar](50)
COLLATE SQL_Latin1_General_CP1_CI_AS
NOT NULL,
[SupID] [int] NULL,
CONSTRAINT [PK_Employee]
PRIMARY KEY CLUSTERED
(
[EmpID] ASC
) ON [PRIMARY]
) ON [PRIMARY]
GO
INSERT INTO Employee (EmpID, EmpName, SupID)
VALUES (1, 'Chandler', 3)
INSERT INTO Employee (EmpID, EmpName, SupID)
VALUES (2, 'Enos', 6)
INSERT INTO Employee (EmpID, EmpName, SupID)
VALUES (3, 'Baker', NULL)
INSERT INTO Employee (EmpID, EmpName, SupID)
VALUES (4, 'Davis', NULL)
INSERT INTO Employee (EmpID, EmpName, SupID)
VALUES (5, 'Franklin', 3)
INSERT INTO Employee (EmpID, EmpName, SupID)
VALUES (6, 'Allen', 5)
INSERT INTO Employee (EmpID, EmpName, SupID)
VALUES (7, 'Gray', 4)Selecting Downstream
The Downstream select procedure is at the end of this article. We will look at snippets here.
The general approach of the Downstream stored procedure is:
- The ID of a starting point Employee record is in the @selectedEmpID parameter.
- Create a TABLE variable named @workTbl to contain the results.
- "Prime the pump". Insert data from the @selectedEmpID Employee record into @workTbl. If @selectedEmpID is NULL or zero, insert data from all Employee records whose SupID value is NULL or zero.
WHERE ((IsNull(@selectEmpID, 0) = 0) AND (IsNull(Employee.SupID, 0) = 0) ) OR (Employee.EmpID = @selectEmpID)
- Then create a loop for inserting sets of records into @workTbl. We will loop over sets of records, not individual records.
- On each iteration of the loop look at the set of SupID values that are already in the @workTbl. If the corresponding EmpID is not already in @workTbl insert the value from the Employee table. Do this as an insert operation for a set, not as an individual insert. This piece of code is where we gain so much in performance over the old type of code.
INSERT INTO @workTbl SELECT Employee.EmpID, Employee.EmpName, Employee.SupID, @supLevel FROM Employee WHERE NOT EXISTS (SELECT EmpID FROM @workTbl WHERE EmpID = Employee.EmpID) AND EXISTS (SELECT EmpID FROM @workTbl WHERE EmpID = Employee.SupID)
Refer to the logical hierarchy mentioned earlier. Here are some examples of running the Downstream select procedure that is attached to this article.
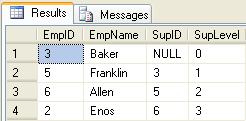
exec usp_Employee_Select_Down_Param_EmpID 5
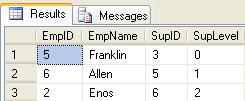
exec usp_Employee_Select_Down_Param_EmpID NULL
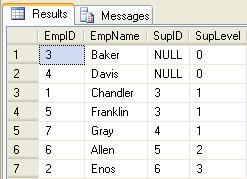
Selecting Upstream
Selecting upstream is much simpler than selecting downstream.
As before, the procedure is at the end of this article. We will just look at a snippet here.
- The ID of a starting point Employee record is in the @selectEmpID parameter. Insert the data for that Employee record into the @workTbl.
- Each iteration represents one level in the structure. The number of interations will be small because organizations rarely have more than 10-15 levels.
- In each iteration of the loop, insert data from the Employee record whose EmpID is the same as the SupID of the most recently inserted record.
SET @nextEmpID = (SELECT SupID FROM @workTbl WHERE ID = (SELECT MAX(ID) FROM @workTbl) ) INSERT INTO @workTbl SELECT Employee.EmpID, Employee.EmpName, Employee.SupID, @supLevel FROM Employee WHERE Employee.EmpID = @nextEmpID
Again, refer to the logical hierarchy mentioned earlier. Here are some examples of running the Upstream select procedure.
exec usp_Employee_Select_Up_Param_EmpID 5
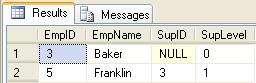
exec usp_Employee_Select_Up_Param_EmpID 2
The @maxSupLevel parameter
The second parameter in each procedure limits the number of levels that you want to search while selecting records. I created this parameter as a protection against runaway looping in case the data were bad. But this parameter can be used for other purposes, too.
In a downstream select, if we only wanted to know the direct reports of a Supervisor we would set @maxSupLevel = 1.
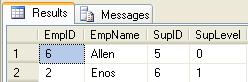
In an upstream select, if we only wanted to know the immediate Supervisor of an Employee we would set @maxSupLevel = 1. The preceding example would show only the selected Employee Enos, and the immediate Supervisor Allen:
exec usp_Employee_Select_Up_Param_EmpID 2, 1
Stored procedures
The stored procedures are in the resources attached to this article.
Conclusion
By switching from old style code to code that takes advantage of set operations you can select from hierarchies in a fraction of the time used by old style code.