

A typical day for the DBA usually starts with an overall health check of the database servers in the network. No matter how big or small the environment, the database administrator usually finds himself doing more or less the same type of checks every day.
If the DBA is responsible for ten production SQL Server instances, each hosting three databases on average - it would be thirty production databases to look after. Each morning the DBA would want to know if the instances are all up and running and accepting user connections. Next, he would probably want to see if overnight backups were all successful. When that is ascertained, perhaps the attention would turn to scheduled jobs. There may be regular processes that are critical to the business – like an SSIS package or a reporting job. If nothing has failed in that front, it would be time to check the Windows Event Log and the SQL Error Log for any suspicious looking error messages. Finally, it will be prudent to see if replication has failed or mirroring has frozen or log shipping has broken.
These are only part of the day-to-day health checks and yet when done manually, can take a significant amount of time.
There are a number of tasks that you as the DBA can automate to make life easier and save time. Smart DBAs would always try to proactively check database and server health without waiting for something to happen or someone else reporting about them.
In this article I will try to present some ideas about how some of the daily database health checks can be automated and turned into proactive monitoring. Although database monitoring is not a new idea and there are quite a few third party tools in the market, it may be cost prohibitive for some organisations. The alternative is to build a custom monitoring solution.
System Architecture
The core functionality of a custom-built database monitoring mechanism comes from a number of scheduled processes that automatically looks at your database servers on a regular basis and sends you consolidated reports when any issues are identified. To keep things simple, we will assume that these reports are sent via e-mail.
The scheduled processes or jobs will invariably run one or more SQL scripts that would query the respective server’s system databases and catalogue views.
The best approach for this is to create a series of stored procedures and functions and put them into a central “monitoring database”. Some DBAs tend to put these procedures in the master database. For the sake of discussion, let’s assume we are building a small database called “DB_Monitoring” that will be used for this purpose only.
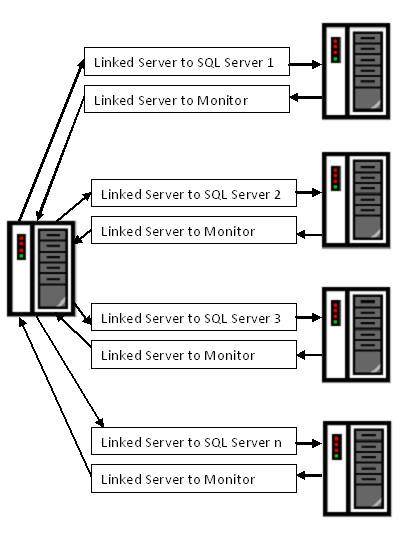
There are two ways the monitoring processes can access the servers. One approach is to keep a central copy of the database and let the procedures execute against the remote servers. Another approach is to put a copy of the DB_Monitoring database in each of the SQL instances being monitored.
If there is a central monitoring database, it will send out periodic e-mails to the DBA about the servers’ and databases’ health status. If each server instance has a copy of the monitoring database, the processes will execute in each local server and each server will send out individual e-mails about its health.
Both these approaches have their own requirements. The central database model requires the monitoring server to be able to “see” all the other SQL servers. In other words, all servers need to be in the same or trusted domains. On the other hand, when a separate copy of the monitoring database is kept in each instance, rolling out a new or updated procedure could be cumbersome. I have used both approaches and find the central database model to be easier to implement when feasible.
The SQL Server instance where the monitoring database will be hosted does not need to be a super-fast machine. It can be a VM (virtual machine) or an old development box, or even the DBA’s workstation if nothing else is available. Whatever the environment, it should always be dedicated for the monitoring purpose and always kept online.
The version of the SQL Server hosting the database will depend on the current environment. In a network with a mixture of SQL 2000 and 2005 instances, the database will need to be developed in SQL 2005. If the network contains only SQL 2000 boxes, SQL 2000 will be the host instance.
Next, the monitoring instance will need to be configured for sending e-mails. Database Mail will need to be configured for SQL 2005 and later versions, while with prior versions of SQL, it would be SQL Mail.
Finally, a set of linked servers will need to be created in the monitoring instance with each linked server pointing to a SQL server in the network. Likewise, a dedicated linked server should be created in each monitored instance pointing back to the central server.
The servers that you will want to monitor will depend on your business needs. In my opinion, if a server is classed as production, it should be monitored.
What to Monitor, How to Monitor, When to Monitor
With the monitoring server in place, you can start developing your DB_Monitoring database. Here are some of the things you can do:
Heartbeat
DBAs would want to be the first to know if a SQL server instance is down. One way to achieve this is to implement a “heartbeat” for the monitored servers where each SQL server instance would send out a small, token message to the monitoring server to inform that it is alive.
With the heartbeat method, the remote server communicates with the central monitoring database and adds a record to a central heartbeat table. The monitoring server periodically checks this table to see the last time a message was received from the remote server. If a record has not been added from a server for a pre-defined period of time, the DBA is sent a warning message.
The remote host should be running a scheduled job for sending the heartbeat data. So if the remote instance’s Agent service down, it won’t be able to send out any message to the monitor even when its SQL service could be up and running. If a heartbeat has not been received within the pre-defined interval, the monitoring database’s code can execute the extended stored procedure xp_servicecontrol to check the status of the remote server’s Agent service.
Although heartbeat jobs should be running as frequently as possible, a good rule of thumb would be to schedule it to run every fifteen or thirty minutes so that the network is not saturated.
Database Status
A Database can get corrupted and turn into an ugly “suspect” status if SQL decides it can’t access it. They can move into simple recovery mode by some installation process, breaking log shipping or mirroring on the way.
You can make use of the DATABASEPROPERTY function to get an update on the status of your databases. A process can check the databases across all the monitored servers to see if any of them are in suspect, read-only, single-user, offline or shut down mode. It can then send a report of its findings.
Database status check can be scheduled to run once every day, particularly just before the normal working hour starts.
Job Monitor
Jobs can be configured to send e-mails to operators if they fail. The problem is, there may be dozens or hundreds of jobs in each of the servers monitored – it can take a while to configure notifications for each of them. Also, when a new job is rolled out in production, the DBA may forget to include its notification properties. Furthermore, if there is a job running every five minutes and failing for some reason, you would not want it to fill up your inbox with the same message. It would be best if the DBA could receive a list of jobs that have failed within a specified time window.
Querying the sysjobs and the sysjobhistory tables of the msdb database in each of your SQL servers can reveal which jobs failed in during a specified time.
How often this job monitor should be run really depends on how often the actual jobs are running in the servers and what jobs are deemed critical. You can schedule this monitor to run once every morning or once every hour. The former can tell you what jobs failed the day before while the latter can warn you about jobs that failed in the past hour.
Backup Status
Most backups are typically performed by scheduled maintenance plans or jobs that execute custom logic. Databases are usually fully backed up every night with log backups happening anywhere between every five minutes to every hour. There can be filegroup and differential backups as well. Whatever the method, the DBA needs to ensure that at least the last full backup was successful. The job monitor report (discussed before) can immediately reveal if a backup job had failed. However, this does not show if a new database has been left out of the backup plan.
The msdb database’s backupset and backupfile tables can be queried to find out the last time a database was fully backed up. Consolidating this information from all the monitored servers will provide a complete backup status report. If a database is not under a backup plan, the report should be able to detect that too.
The database backup status report should be run once every day after the scheduled full backup window. So if the database servers are backed up every day at 2:00 AM, the report should run say, at 4:00 AM that morning.
File and Disk Space Monitor
DBAs also regularly need to check server disk space to ensure databases have enough space to grow.
The extended stored procedure xp_fixeddrives can be used to find the free space available in a server’s local drives. Making use of a little bit of extra coding with it will also show the actual size of the local drives. Combining these two pieces of information with a pre-defined threshold can give a customised report on server disk space usage.
Similarly, querying the output of sp_helpfile system stored procedure against each database can show data files whose sizes are approaching the MAXSIZE property. This can give an idea about how “full” each data file in a server are.
While the file space monitor can be run as infrequently as once every week, the disk space monitor should be run at least once or twice a day.
Conclusion
The monitoring processes discussed above are only the minimum that the DBA should have at his arsenal. You can become as creative as you want with it – for example, a report on index fragmentation could be the one you would find really useful in your current workplace. Whatever the need, when properly implemented, a proactive DBA monitoring can save you time and effort.


