

Introduction
SQL Server 2005 offers an array of ranking
and windowing functions that can be used to evaluate the data and only return
appropriate rows. For instance, a development cycle of a product may
include hundreds of releases, and those releases may have versions associated
with them: a "0" version with its many minor versions, a
"1" version with its minor versions, etc. If the history of a
particular product's releases is kept, then analysis can be done to see how far
a version is developed before it is released. An ORDER BY clause alone cannot fulfill this need
because the query would most likely still return the entire history of the product,
not necessarily the last release of every version. The code is also available
for download. The name of the file is RowCountScenario1-CodeDownload.sql.
Scenario 1 – Versioning
In order to demonstrate the usage
of the ROW_NUMBER() windowing function, I started
with Microsoft's AdventureWorks database. In particular, I used the data
in the Production.ProductCostHistory table. The products in this table
are identified by the ProductID column; this is a foreign key to the
Production.Product table. Using the Production.ProductCostHistory table,
I mocked up some data to create versions for each Product in the table. I
used a random number generation process to create attributes called Version,
MinorVersion and ReleaseVersion for each product. These attributes are meant
to show detailed information about the product. Together 7.0.59 represents
that the 7th version of the product is currently being used, a minor
version represents the iteration of the version, and the release version of
this particular installation is 59. The next iteration of the product's life
cycle could result with 7.2.19. I also used the existing StandardCost to
create different costs for each of the Versions, to create some sense of value
for the particular Version.
I created a table called Production.ProductVersion
with the ProductID, Version, MinorVersion and ReleaseVersion defined as the primary
key and the StandardCost as an attribute. I inserted the mocked up data
generated by the code into this table to model a simple product version/cost history.
CREATE TABLE Production.ProductVersion ( ProductID int NOT NULL, Version int NOT NULL, MinorVersion int NOT NULL, ReleaseVersion int NOT NULL, StandardCost numeric(30, 4) NOT NULL, CONSTRAINT PK_ProductVersion PRIMARY KEY CLUSTERED ( ProductID ASC, Version ASC, MinorVersion ASC, ReleaseVersion ASC ) );
I used the following code to populate the table with randomized data. I created the data using a common
table expression (CTE) and inserted the data into the table after it was generated. The data is based on the Production.ProductCostHistory table.
WITH ProductVersion AS ( SELECT ProductID, 1 AS Version, CAST((ABS(CHECKSUM(NEWID())) % 1001) AS INT) AS MinorVersion, CAST((ABS(CHECKSUM(NEWID())) % 20001) AS INT) AS ReleaseVersion, CAST(StandardCost AS NUMERIC(30,4)) AS StandardCost FROM Production.ProductCostHistory WITH (NOLOCK) UNION ALL SELECT ProductID, ABS(CHECKSUM(NEWID())) % 3 AS Version, CAST((ABS(CHECKSUM(NEWID())) % 1001) AS INT) AS MinorVersion, CAST((ABS(CHECKSUM(NEWID())) % 20001) AS INT) AS ReleaseVersion, CAST((CAST(StandardCost AS NUMERIC(30,4)) * 1.10) AS NUMERIC(30,4)) AS StandardCost FROM Production.ProductCostHistory WITH (NOLOCK) UNION ALL SELECT ProductID, ABS(CHECKSUM(NEWID())) % 5 AS Version, CAST((ABS(CHECKSUM(NEWID())) % 1001) AS INT) AS MinorVersion, CAST((ABS(CHECKSUM(NEWID())) % 20001) AS INT) AS ReleaseVersion, CAST((CAST(StandardCost AS NUMERIC(30,4)) * 2.10) AS NUMERIC(30,4)) AS StandardCost FROM Production.ProductCostHistory WITH (NOLOCK) ) INSERT INTO Production.ProductVersion SELECT ProductID, Version, MinorVersion, ReleaseVersion, MAX(StandardCost) AS StandardCost FROM ProductVersion GROUP BY ProductID, Version, MinorVersion, ReleaseVersion;
The ABS(CHECKSUM(NEWID()))
is utilized as the random number generator; the modulus operator provides the
upper bound for the random number that was generated. The NEWID()
function is guaranteed to generate a globally unique identifier for each row.
The GROUP BY clause is
used to avoid any Primary Key constraint violations that might be encountered.
The purpose of this exercise is to
avoid the complexity of certain code by using the ROW_NUMBER()
windowing function. Suppose you are required to return only the latest version
of a Product with its associated MinorVersion, ReleaseVersion and
StandardCost. The following query will not return the correct result set.
SELECT ProductID, MAX(Version) AS Version, MAX(MinorVersion) AS MinorVersion, MAX(ReleaseVersion) AS ReleaseVersion, MAX(StandardCost) AS StandardCost FROM Production.ProductVersion WITH (NOLOCK) GROUP BY ProductID;
In fact, this query violates
integrity of the rows of data in the table. It simply returns the maximum
Version, the maximum MinorVersion, the maximum ReleaseVersion and the maximum
StandardCost of a particular Product. This is an easy and tempting trap to
fall into. Compare the results displayed in Figure 2 and Figure 3. The actual
data that is in Production.ProductVersion is in Figure 1.
The following sample query captures
the actual requirements, and returns the correct result, but it is long and
convoluted.
SELECT ProductID, ( SELECT MAX(Version) FROM Production.ProductVersion pv2 WITH (NOLOCK) WHERE pv2.ProductID = pv.ProductID ) AS Version, ( SELECT MAX(MinorVersion) FROM Production.ProductVersion pv3 WITH (NOLOCK) WHERE pv3.ProductID = pv.ProductID AND pv3.Version = ( SELECT MAX(Version) FROM Production.ProductVersion pv2 WITH (NOLOCK) WHERE pv2.ProductID = pv.ProductID ) ) AS MinorVersion, ( SELECT MAX(ReleaseVersion) FROM Production.ProductVersion pv4 WITH (NOLOCK) WHERE pv4.ProductID = pv.ProductID AND pv4.Version = ( SELECT MAX(Version) FROM Production.ProductVersion pv2 WITH (NOLOCK) WHERE pv2.ProductID = pv.ProductID ) AND pv4.MinorVersion = ( SELECT MAX(MinorVersion) FROM Production.ProductVersion pv3 WITH (NOLOCK) WHERE pv3.ProductID = pv.ProductID AND pv3.Version = ( SELECT MAX(Version) FROM Production.ProductVersion pv2 WITH (NOLOCK) WHERE pv2.ProductID = pv.ProductID ) ) ) AS ReleaseVersion, ( SELECT StandardCost FROM Production.ProductVersion pv5 WITH (NOLOCK) WHERE pv5.ProductID = pv.ProductID AND pv5.Version = ( SELECT MAX(Version) FROM Production.ProductVersion pv2 WITH (NOLOCK) WHERE pv2.ProductID = pv.ProductID ) AND pv5.MinorVersion = ( SELECT MAX(MinorVersion) FROM Production.ProductVersion pv3 WITH (NOLOCK) WHERE pv3.ProductID = pv.ProductID AND pv3.Version = ( SELECT MAX(Version) FROM Production.ProductVersion pv2 WITH (NOLOCK) WHERE pv2.ProductID = pv.ProductID ) ) AND pv5.ReleaseVersion = ( SELECT MAX(ReleaseVersion) FROM Production.ProductVersion pv4 WITH (NOLOCK) WHERE pv4.ProductID = pv.ProductID AND pv4.Version = ( SELECT MAX(Version) FROM Production.ProductVersion pv2 WITH (NOLOCK) WHERE pv2.ProductID = pv.ProductID ) AND pv4.MinorVersion = ( SELECT MAX(MinorVersion) FROM Production.ProductVersion pv3 WITH (NOLOCK) WHERE pv3.ProductID = pv.ProductID AND pv3.Version = ( SELECT MAX(Version) FROM Production.ProductVersion pv2 WITH (NOLOCK) WHERE pv2.ProductID = pv.ProductID ) ) ) ) AS StandardCost FROM Production.ProductVersion pv WITH (NOLOCK) GROUP BY ProductID;
This query utilizes nested
subqueries in order to ensure the integrity of each row. The first subquery
(lines 117-25 in the code download) provides the maximum Version for each
Product. The second subquery provides the maximum MinorVersion for the maximum
Version of each Product. The subsubquery in the WHERE clause ensures that the
MinorVersions and the Versions match. The third subquery,
SELECT MAX(ReleaseVersion) FROM Production.ProductVersion pv4 WITH (NOLOCK) WHERE pv4.ProductID = pv.ProductID AND pv4.Version = ( SELECT MAX(Version) FROM Production.ProductVersion pv2 WITH (NOLOCK) WHERE pv2.ProductID = pv.ProductID ) AND pv4.MinorVersion = ( SELECT MAX(MinorVersion) FROM Production.ProductVersion pv3 WITH (NOLOCK) WHERE pv3.ProductID = pv.ProductID AND pv3.Version = ( SELECT MAX(Version) FROM Production.ProductVersion pv2 WITH (NOLOCK) WHERE pv2.ProductID = pv.ProductID ) )
(lines 127-46 in the code download) provides the maximum
ReleaseVersion for the maximum MinorVersion of the maximum Version of each
Product. Once again the subqueries ensure that only complete rows of data are retrieved.
If this logic sounds too complicated, that is simply because it is. The
estimated subtree cost for this query turns out to be 0.583005. This includes
several Clustered Index Scan and Seek operations. The query plan is displayed
in Figure 6. The complexity of the subquery approach can increase if the
requirements change.
A simplified approach uses the ROW_NUMBER()
function as shown below.
WITH RowExample1 AS ( SELECT ROW_NUMBER() OVER(PARTITION BY ProductID ORDER BY ProductID, Version DESC, MinorVersion DESC, ReleaseVersion DESC ) AS MaxVersion, ProductID, Version, MinorVersion, ReleaseVersion, StandardCost FROM Production.ProductVersion pv WITH (NOLOCK) ) SELECT ProductID, Version, MinorVersion, ReleaseVersion, StandardCost FROM RowExample1 WHERE MaxVersion = 1 ORDER BY ProductID;
The result set for this query looks like the Figure 3.
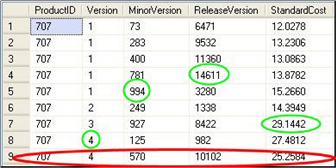
Figure 1: Sample from Production.ProductVersion

Figure 2: Sample from incorrect query

Figure 3: Sample from properly implemented query
The PARTITION BY clause allows a set of row numbers to be
assigned for all distinct Products. When a new ProductID is encountered, the
row numbering will start over at 1 and continue incrementing for each row with
the same ProductID. The row number will be assigned according to the sort
order of the columns that you specify in the OVER clause's ORDER BY clause. The estimated subtree cost for
this improved query is 0.039954. This query has only one Clustered Index Scan
operation. The query plan is displayed in Figure 7.
With the OVER clause, the ROW_NUMBER() function can efficiently assign
a row number to each row in a query. The fact that I've ordered the partitions
by ProductID and then in descending order by Version, MinorVersion, and
ReleaseVersion, guarantees the maximum version will be in the first row of each
ProductID partition. This allows me to use a simple WHERE MaxVersion = 1 predicate in place of the convoluted
sub-query logic in the previous sample query.
To test the effects of indexing on difference between the two methods, I used the following table.
CREATE TABLE Production.ProductVersion2 ( ProductID int NOT NULL, Version int NOT NULL, MinorVersion int NOT NULL, ReleaseVersion int NOT NULL, StandardCost numeric(30, 4) NOT NULL, );
I used the following query to generate a large set of randomized data to compare the estimated query costs for different record size sets.
WITH RCTE AS ( SELECT 0 AS X, ProductID, 1 AS Version, CAST((ABS(CHECKSUM(NEWID())) % 1001) AS INT) AS MinorVersion, CAST((ABS(CHECKSUM(NEWID())) % 20001) AS INT) AS ReleaseVersion, CAST(StandardCost AS NUMERIC(30,4)) AS StandardCost FROM Production.ProductCostHistory WITH (NOLOCK) UNION ALL SELECT X + 1, pv.ProductID, ABS(CHECKSUM(NEWID())) % 3 AS Version, CAST((ABS(CHECKSUM(NEWID())) % 1001) AS INT) AS MinorVersion, CAST((ABS(CHECKSUM(NEWID())) % 20001) AS INT) AS ReleaseVersion, CAST((CAST(pv.StandardCost AS NUMERIC(30,4)) * 1.10) AS NUMERIC(30,4)) AS StandardCost FROM RCTE pv WHERE X < 14 UNION ALL SELECT X + 2, pv.ProductID, ABS(CHECKSUM(NEWID())) % 5 AS Version, CAST((ABS(CHECKSUM(NEWID())) % 1001) AS INT) AS MinorVersion, CAST((ABS(CHECKSUM(NEWID())) % 20001) AS INT) AS ReleaseVersion, CAST((CAST(pv.StandardCost AS NUMERIC(30,4)) * 2.10) AS NUMERIC(30,4)) AS StandardCost FROM RCTE pv WHERE X < 15 ) INSERT INTO Production.ProductVersion2 SELECT TOP (100000) ProductID, Version, MinorVersion, ReleaseVersion, MAX(StandardCost) FROM RCTE GROUP BY ProductID, Version, MinorVersion, ReleaseVersion OPTION (MAXRECURSION 0);
The following charts show the estimated query costs for different row sizes. I chose to start at 1,000
because there are 286 distinct ProductIDs, starting at 100 would have eliminated too many rows.
The following figure shows the estimated query costs for the Production.ProductVersion. The subquery implementation actually took less than 1 second to complete where as the ROW_NUMBER() implementation took about 2 seconds to complete for 1,000,000 rows.
Row Size | Subquery Implementation Cost | ROW_NUMBER() Implementation Cost |
1000 | 0.0652462 | 0.0355736 |
10000 | 0.238573 | 0.673282 |
100000 | 2.2258 | 5.97198 |
1000000 | 14.3881 | 83.7228 |
Figure 4: Indexed estimated query costs
The following figure shows the
estimated query costs for the Production.ProductVersion2. The subquery
implementation took 43 seconds to complete where as the ROW_NUMBER()
implementation took 5 seconds to complete for 1,000,000 rows.
Row Size | Subquery Implementation Cost | ROW_NUMBER() Implementation Cost |
1000 | 0.0355736 | 0.225896 |
10000 | 1.6397 | 0.673282 |
100000 | 44.1332 | 5.97202 |
1000000 | 448.47 | 83.7229 |
Figure 5: Non-indexed estimated query costs
These results may differ according
to the hardware used to run the queries. A quick look at the ROW_NUMBER()
implementation column shows that indexing does not significantly impact this
implementation's query cost where as it is very important to the subquery
implementation's query cost.
Scenario 1 – Change in Requirements
Suppose the requirement changes and
you need to grab the maximum MinorVersions for every (ProductID, Version)
combination. Changing the subquery implementation has a large overhead, namely
breaking down the logic. The subquery approach looks like this with the new
set of requirements:
SELECT ProductID, Version, ( SELECT MAX(MinorVersion) FROM Production.ProductVersion pv3 WITH (NOLOCK) WHERE pv3.ProductID = pv.ProductID AND pv3.Version = pv.Version ) AS MinorVersion, ( SELECT MAX(ReleaseVersion) FROM Production.ProductVersion pv4 WITH (NOLOCK) WHERE pv4.ProductID = pv.ProductID AND pv4.Version = pv.Version AND pv4.MinorVersion = ( SELECT MAX(MinorVersion) FROM Production.ProductVersion pv3 WITH (NOLOCK) WHERE pv3.ProductID = pv.ProductID AND pv3.Version = pv.Version ) ) AS ReleaseVersion, ( SELECT StandardCost FROM Production.ProductVersion pv5 WITH (NOLOCK) WHERE pv5.ProductID = pv.ProductID AND pv5.Version = pv.Version AND pv5.MinorVersion = ( SELECT MAX(MinorVersion) FROM Production.ProductVersion pv3 WITH (NOLOCK) WHERE pv3.ProductID = pv.ProductID AND pv3.Version = pv.Version ) AND pv5.ReleaseVersion = ( SELECT MAX(ReleaseVersion) FROM Production.ProductVersion pv4 WITH (NOLOCK) WHERE pv4.ProductID = pv.ProductID AND pv4.Version = pv.Version AND pv4.MinorVersion = ( SELECT MAX(MinorVersion) FROM Production.ProductVersion pv3 WITH (NOLOCK) WHERE pv3.ProductID = pv.ProductID AND pv3.Version = pv.Version ) ) ) AS StandardCost FROM Production.ProductVersion pv WITH (NOLOCK) GROUP BY ProductID, Version;
The new requirements actually
eliminate some of the nested subqueries. The estimated query cost, however,
does not change significantly for Production.ProductVersion.
This new change requires only a small modification to the ROW_NUMBER() implementation. This is what the ROW_NUMBER()
implementation looks like for the new set of requirements:
WITH RowExample2 AS ( SELECT ROW_NUMBER() OVER(PARTITION BY ProductID, Version ORDER BY ProductID, Version, MinorVersion DESC, ReleaseVersion DESC ) AS MaxVersion, ProductID, Version, MinorVersion, ReleaseVersion, StandardCost FROM Production.ProductVersion pv WITH (NOLOCK) ) SELECT ProductID, Version, MinorVersion, ReleaseVersion, StandardCost FROM RowExample2 WHERE MaxVersion = 1 ORDER BY ProductID;
In this example, the row numbers
are partitioned according to both ProductID and Version. The WHERE
clause is still valid here because the maximum MinorVersion for each
(ProductID, Version) combination is guaranteed to be the first row. The
estimated query cost did not change greatly for the modified code. The
readability, manageability and the efficiency of the function make it a better
choice than the subquery approach.
Estimated Query Plans
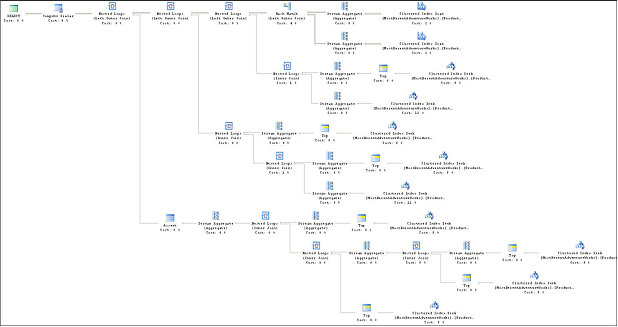
Figure 6: Subquery approach

Figure 7: ROW_NUMBER() approach
Conclusion
These examples show the critical
role of indexing in the subquery approach. The ROW_NUMBER() implementation is
far more readable and therefore easier to maintain. It also remains relatively
independent of indexing even for large amounts of data. Since the function takes
advantage of the SQL Server's ability to sort records, most queries that need
to uphold a level of sequencing should at the very least explore its
implementation. The sorting itself can greatly reduce or replace all together
the extra logic necessary to enforce the integrity of data at the row level.
The readability of the function's implementation also plays a key role in its
manageability. Modifying the code with the ROW_NUMBER()
implementation is easy because the logic is performed in easy to spot areas and
is performed once, whereas in the subquery the logic appears in several places
and could be repeated.
