

There are lots of accidental DBAs out there that might not know how tables are distributed across files in a filegroup. It seems often that more inexperienced people get confused with files and filegroups and how SQL Server works to spread data across files. Recently someone was confused about why data hadn't moved when files were added.
This article will look at how data is handled in SQL Server when new files are added to a filegroup. We will also show how to distribute the data more evenly to ensure that the read/write load is balanced.
The Scenario
Let's show a small example that illustrates the purpose. If you have larger data sizes, the problem is larger, but the effect is the same. We'll assume we have a database with some data in it. As you can see here, I have a few tables with a small number of rows.
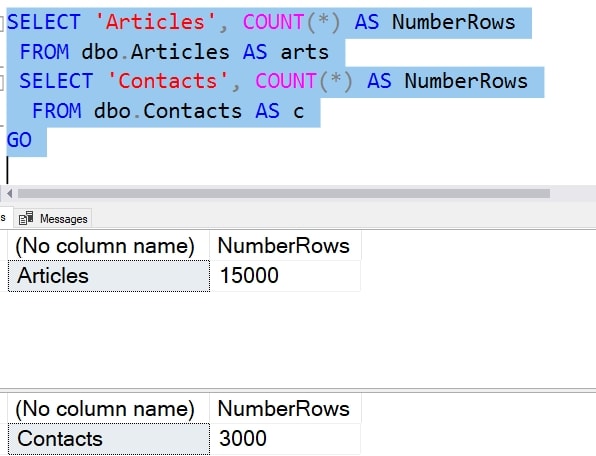
However, my database is running out of space. I estimate that I'm adding a few MB/day, so I'll be out of space soon.

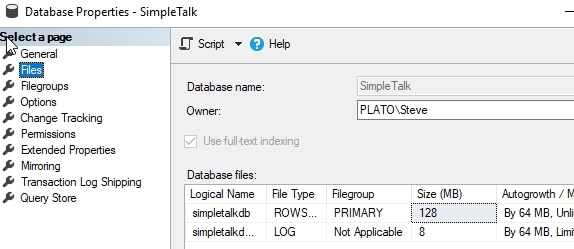
My filegroup is the default one, with a single file. We can see here I have a 128MB file and an 8MB log:
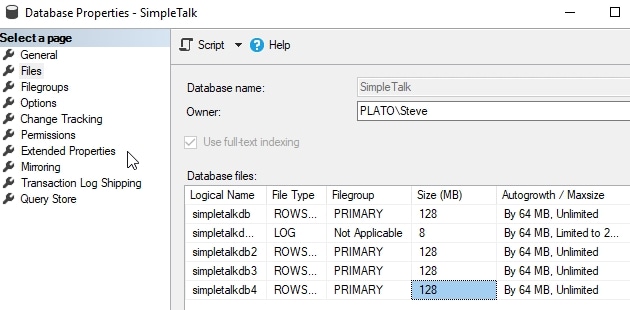
The common action here is to be proactive and add some data files to spread the load. In this case, you can see that we've added 3 additional data files to our database. When I do this, I'm adding the files at the same size as my original file. This is a best practice to ensure that the filegroup remains balanced.
Note: I'm showing this in the GUI, but you should be scripting this and running the ALTER DATABASE command instead of clicking around in Management Studio.
I can now query my files. To do this, I'll run this code:
SELECT
FILE_Name = A.name,
FILEGROUP_NAME = fg.name,
FILESIZE_MB = CONVERT(DECIMAL(10, 2), A.size / 128.0),
USEDSPACE_MB = CONVERT(
DECIMAL(10, 2),
A.size / 128.0
- ((size / 128.0)
- CAST(FILEPROPERTY(A.name, 'SPACEUSED') AS INT) / 128.0
)
),
FREESPACE_MB = CONVERT(
DECIMAL(10, 2),
A.size / 128.0
- CAST(FILEPROPERTY(A.name, 'SPACEUSED') AS INT) / 128.0
),
[FREESPACE_%] = CONVERT(
DECIMAL(10, 2),
((A.size / 128.0
- CAST(FILEPROPERTY(A.name, 'SPACEUSED') AS INT) / 128.0
)
/ (A.size / 128.0)
) * 100
)
FROM
sys.database_files AS A
LEFT JOIN sys.filegroups AS fg
ON A.data_space_id = fg.data_space_id
WHERE A.type_desc <> 'LOG'
ORDER BY
A.type DESC,
A.name;Here are the results I get back. My first file (simpletalkdb) is mostly full. It has 15MB used, and the other files still have just a little overhead (0.06MB) used. The far right column is the percent of free space, 13% for the first file and 99 for the others.

This is where users often get confused. Why hasn't my data moved to balance out the files? If I add new data, here's what I see. I'll add about 30 or megabytes of data and re-query the files. I now see this:

Each file has had some data added, but the distribution isn't even. I will have almost 12% free in one file with 90% free in the others. Why?
Proportional Fill
SQL Server uses a proportional fill algorithm that essentially writes more data to empty files than full ones. This tries to (eventually) balance out the data across all files. You can read about this more at SQLServerCentral and SQLskills. There is a round robin writing algorithm that decides which file to write to, and the more that each file has free space, the more writes it gets.
The best practice is that we keep our file sizes the same and that amount of data roughly the same in each. This balances out writes and should help with performance.
Balancing the Data
If this is our goal, how can we get all the data to be even in the files? If we continue to add data, it will eventually get there, but we will have more and more writes occurring in the empty files until that's the case.
If you have a clustered index, the easy way to try and do this is with an index rebuild. I can use this code on the biggest tables:
ALTER INDEX PK_Article ON dbo.Articles REBUILD ALTER INDEX PK_Contacts ON dbo.Contacts REBUILD
Once this completes, I can re-query the files for data distribution. I now see this:

There has been a little movement, as my new files are 90% full (roughly) and the old one is 12% full. However, that's not great. If I check the size of these tables, however, they are about 13MB in total. This means I'd only expect about 2MB in each file. With proportional fill, this is about as good as things get.
If you have a heap, this doesn't work without you rebuilding all the indexes. Once that is done, you can use the ALTER TABLE...REBUILD command to rebuild the distribution of data.
Unfortunately, the best option to clean this up is more disruptive. It is recommended that you allow the data to balance over these files across time, with regular reindexing on your normal schedule.
If you want to clean this up more quickly, you can to the following. First, add a new filegroup and file. I'll do this in the database, ensuring my file has enough space to hold the data from my large tables.
USE [master] GO ALTER DATABASE [SimpleTalk] ADD FILEGROUP [Temp] GO ALTER DATABASE [SimpleTalk] ADD FILE ( NAME = N'simpletalktemp', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL14.SQL2017\MSSQL\DATA\simpletalktemp.ndf' , SIZE = 20480KB , FILEGROWTH = 65536KB ) TO FILEGROUP [Temp] GO
Next, I want to rebuild the clustered index, but by moving the index to the new filegroup. I'll use this code to move both PKs to the new filegroup:
CREATE UNIQUE CLUSTERED INDEX PK_Article
ON dbo.Articles(ArticlesID)
WITH (DROP_EXISTING = ON )
ON Temp
GO
CREATE UNIQUE CLUSTERED INDEX PK_Contacts
ON dbo.Contacts(ContactsID)
WITH (DROP_EXISTING = ON )
ON Temp
Once the data is moved, we need to move it back. We'll repeat the same action above, but with a different filegroup target.
CREATE UNIQUE CLUSTERED INDEX PK_Article
ON dbo.Articles(ArticlesID)
WITH (DROP_EXISTING = ON )
ON [PRIMARY]
GO
CREATE UNIQUE CLUSTERED INDEX PK_Contacts
ON dbo.Contacts(ContactsID)
WITH (DROP_EXISTING = ON )
ON [PRIMARY]
When we check the files, we now see this:

We can now see that our first file is 62% free, and the other 3 files are 75% free. Fairly balanced. The Temp file has usage that hasn't been cleaned up, but we can remove that file and filegroup like this:
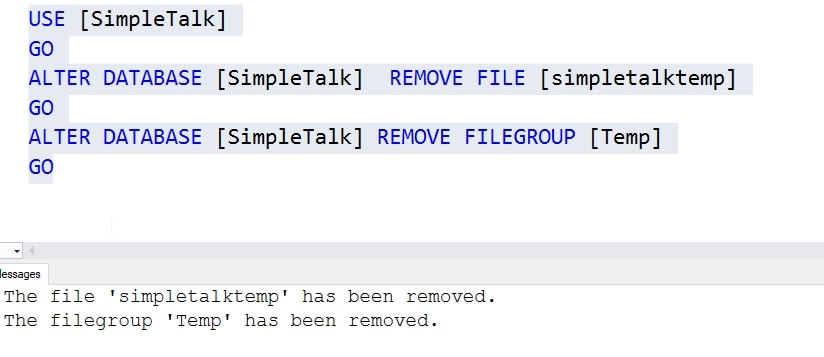
Don't forget to clean up if you do this. If you have space in an existing filegroup, you can do the same thing, specifying that filegroup instead of Temp when you rebuild the clustered index.
Conclusion
This article demonstrates that SQL Server doesn't automatically rebalance data across files if you add them to a filegroup. You will manually need to do this, or just allow it to naturally occur across time. Either will work, though beware of heavy activity in the more empty file until this happens.
Also be sure that you size your files, both in initial size and autogrowth, to match to ensure efficient operation of your instance.

