

Overview
A database clause is a conditional statement used to filter data from the database. There are various database clauses available in PostgreSQL, like Where, Order By, Group By, Having, Distinct, Limit, Fetch. In this first chapter of the tutorial we will cover Where, Order By, Group By clauses with suitable example.
WHERE Clause
The WHERE clause is used to filter the output when used in collaboration with Select, Update or Delete Statement. The basic syntax is:
SELECT col1, col2, ..... colN FROM table_name WHERE [condition] UPDATE table_name SET column1 = value1, column2 = value2,... columnn = valuen WHERE condition; DELETE FROM table_name WHERE condition;
The WHERE clause can be used with logical and comparison operators like AND, OR, =, <, >, <> or !=, >=, <=, IN, LIKE, BETWEEN, NOT, IS NULL. Use any of these to select the appropriate criteria data to work with in your query.
Example 1: Select
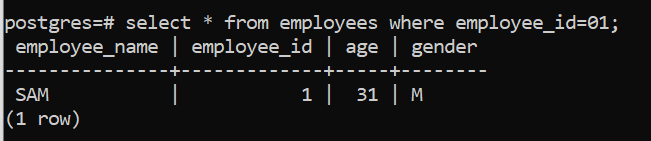
In the Select command the Where condition is used to filter rows returned by the Select statement. In this example we retrieve the details of the employee whose employee id is 1. Similarly other filter criteria can also be used after the Where clause to filter the data.
select * from employees where employee_id=01;
Example 2: Update
In this example we update the age and gender of the employee whose employee id is 3, setting them to 35 and M, respectively.
UPDATE employees SET age=35,gender='M' where employee_id=3;
![]()
Example 2: Delete
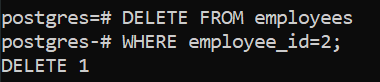
This removes the row(s) where the employee id is 2.
DELETE FROM employees WHERE employee_id=2;
ORDER BY clause
The ORDER BY clause is used for sorting the rows returned by the SELECT statement in either ascending or descending order. By default the select statement fetches the rows in an undetermined order therefore the ORDER BY clause is used for enforce some ordering of the rows in the result set. The ORDER BY clause cannot be directly used in an UPDATE or DELETE statement, however, they can part of the sub-select that are in an UPDATE or DELETE statement.
The ORDER BY clause by default sorts the result set in ascending order, and the ASC keyword need not be explicitly mentioned. To sort the result set in descending order, the keyword, DESC, needs to be explicitly mentioned after the column used in the ORDER BY clause. We shall next see some examples to better understand the functionality.
The basic syntax for the ORDER BY clause is:
SELECT col1,col2,......colN FROM table_name [WHERE condition] [ORDER BY col1, col2, .. colN] [ASC | DESC];
Note, each column listed should have the ASC or DESC keyword after it to explicitly set the ordering.
Example 1: Default single column
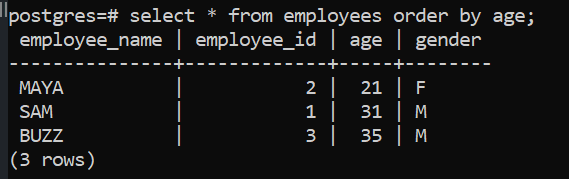
In this query, we see that the results will be sorted on the column age and in ascending order.
select * from employees order by age;
Example 2: Ordering in descending order
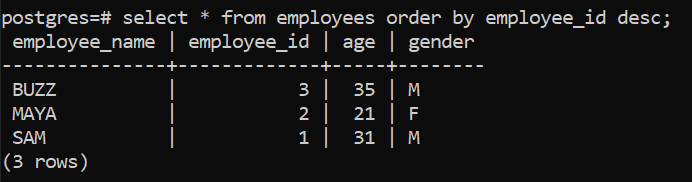
In this example the Order By clause sorts the result set based on the column employee id in descending order because of the explicit mention of the keyword, DESC, after the ORDER BY clause.
select * from employees order by employee_id desc;
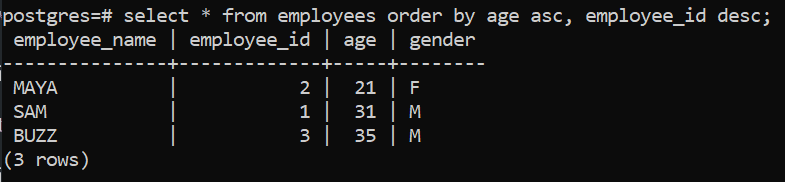
Example 3: Sorting by multiple columns
This example it is possible to sort the result set by multiple columns. The ordering for each column can be set individually by using the ASC or DESC keyword with respect to each column after the ORDER BY statement. The ASC keyword is optional, and is used here to maintain clarity.
select * from employees order by age asc, employee_id desc;
GROUP BY clause
The PostgreSQL GROUP BY clause is used with SELECT statements to accumulate identical data into groups. This is used to reduce the redundancy in the result. The GROUP BY clause works with aggregates functions, like SUM(), COUNT() and also without aggregate functions. The GROUP BY clause comes after the WHERE clause and before the ORDER BY clause.
The basic syntax is as shown here:
SELECT col1,col2,.....colN FROM table_name WHERE [conditions] GROUP BY col1, col2....colN ORDER BY col1, col1....colN
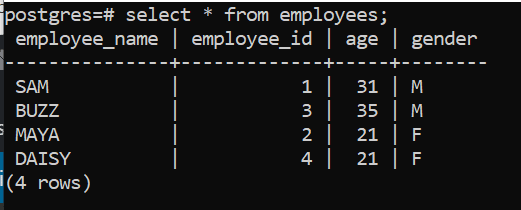
Example 1: GROUP BY clause without aggregate function
This statement basically works as a distinct condition, which removes duplicate date from the result set. We can see all the data here.
If we add the GROUP BY, notice that only two rows are displayed. The remaining rows fall into these two groups.
SELECT gender FROM employees GROUP BY gender;
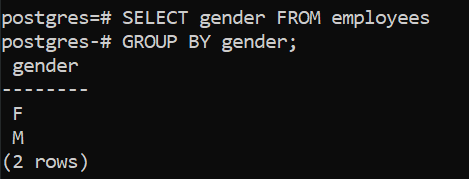
We have removed the other columns, as any column not included in the GROUP BY needs to be included in an aggregate function.
To illustrate the next couple of scenarios, we will use the following table:
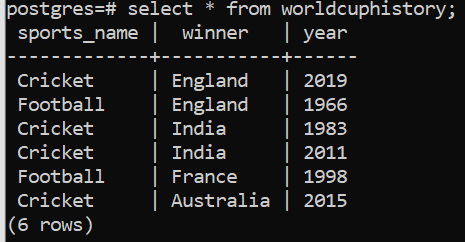
Example 2: GROUP BY clause on multiple columns
When we use GROUP BY Col1, Col2, the query basically puts all those rows with the same values for both Col1 and Col2 in one group. In this example, our idea is to accumulate all the winners of cricket world cup in one group and all the winners of football world cup in another group.
select sports_name,winner from worldcuphistory group by sports_name,winner;

In order to achieve this we add a GROUP BY clause with respect to the column 'sports_name' and winner. Internally, to begin with two groups are created one each for Cricket and Football and then based on these groups the next set of groups with respect to the column 'winner' are created.
The thing to note here there is only a single entry for India though there are two records in the original data set. The reason being as previously mentioned GROUP BY also works as the distinct condition.
Example 3: GROUP BY clause with Count() function
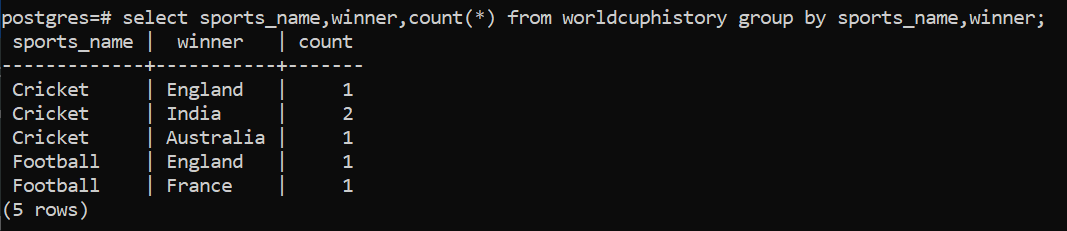
Suppose we want to find the total number of entries for a specific data with respect to the groups formed, we can use the Count() function to do it. Count() is an aggregate function that returns the number of records returned by a select query. As there two entries for India with respect to cricket in the original data set we see count = 2 for India and 1 for everyone else.
select sports_name,winner,count(*) from worldcuphistory group by sports_name,winner;
Example 4: GROUP BY clause with Sum(), Max() function
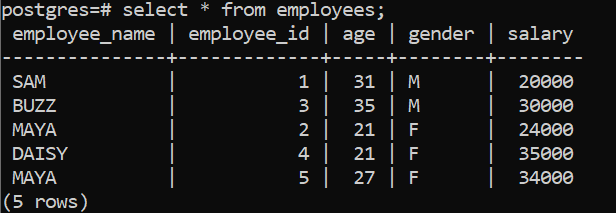
The Sum() is another aggregate function which returns the sum total of rows when divided in groups. For example let us consider the following table data,
From here, if we want to get the sum total of salary for all female employees,
select gender, sum(salary) from employees where gender='F' group by gender;

Similarly if we want to get the maximum salary amongst all male and female employees, we can use the Max() function as shown below:
select gender,max(salary) from employees group by gender;

Conclusion
This article gives an overview on the different aspects of Where, Order By, Group By clauses in PostgreSQL. We show how to use these clauses in practical world with the help different tables. We hope this article will help you get started on your journey.