

Introduction
In Azure Data Factory, a Data flow is an activity that can be added in a pipeline. The Data flow activity is used to transfer data from a source to destination after making some transformations on the data. Mapping data flows are the visually designed data transformations helping in developing data transformation logic without writing code. The mapping data flow once created and tested, can be added in the Data flow activity of a pipeline. Data Factory handles all the code translation, path optimization and execution of the data flows.
Implementation Details
I will discuss about the step-by-step process for creating and executing a mapping data flow in Azure Data Factory.
Create a Storage account and add a Blob
I create a Storage account first. Then, I add a container and upload a CSV file from my local drive. There is an article, Azure Storage: Blob and Data Lake Storage Gen2 – SQLServerCentral, which may be referred for the detailed discussion on Storage account and Blob. Below you see my file.
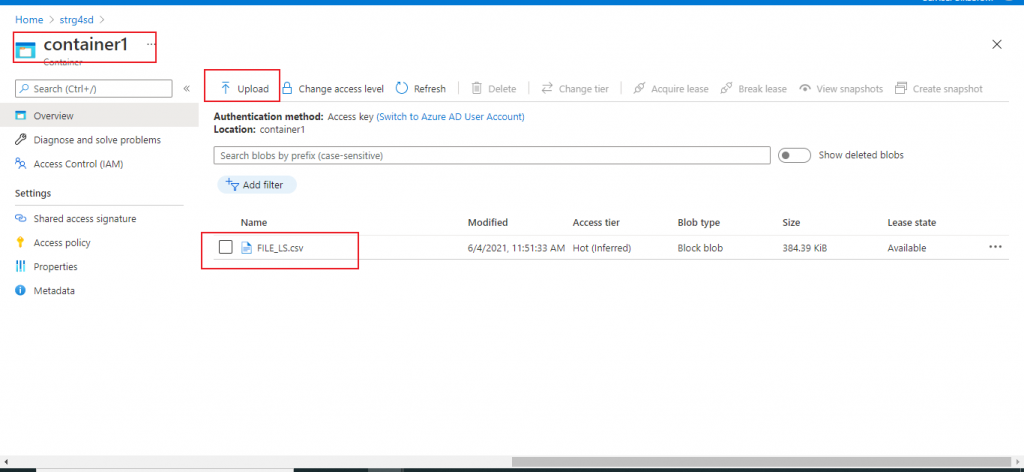
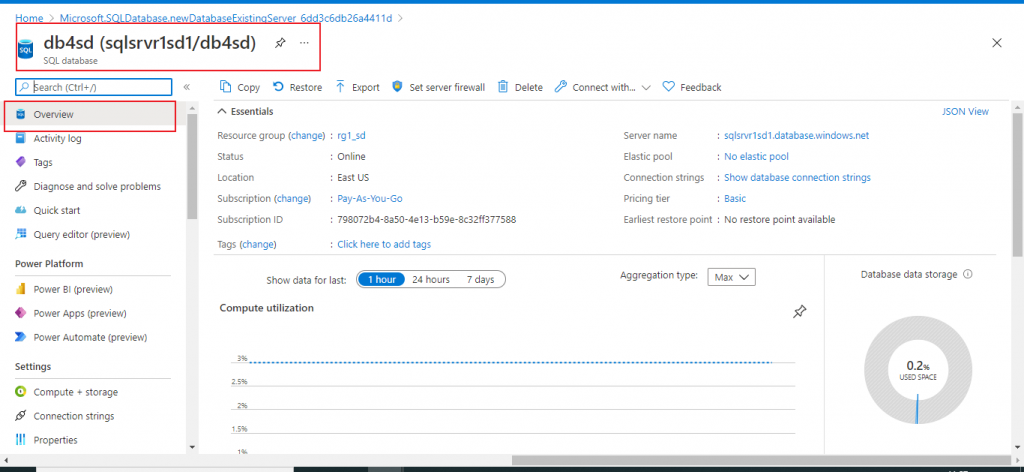
Create an Azure SQL Database
I create an Azure SQL Database from the portal. If you don't know how to do this, there is an article on SQLServerCentral explaining this. Below is the database I created.
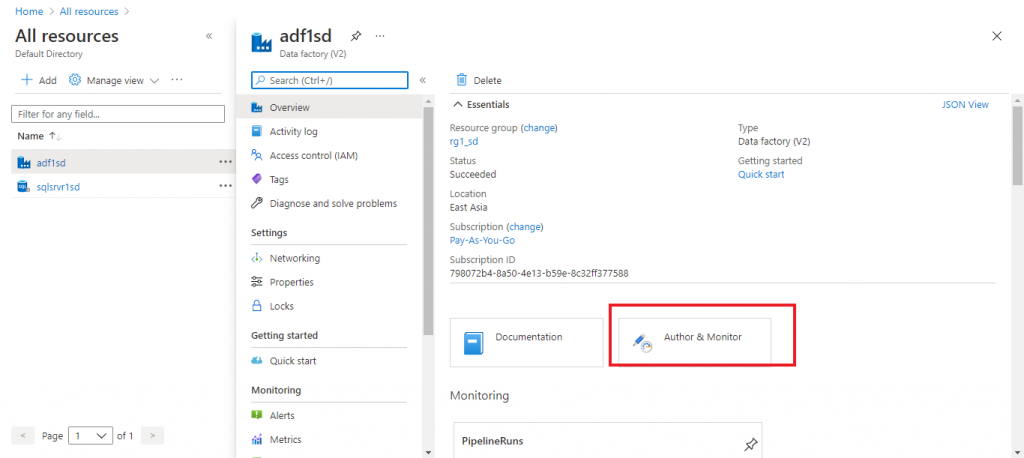
Start development in the Azure Data Factory
I create a Data Factory from the Azure Portal and go to the 'Author & Monitor' tab in the Overview page. You can look at this article for the initial details about creating a data factory: Loading data in Azure Synapse Analytics using Azure Data Factory. Below is my Data factory.
Create a new data flow
I go to the Author tab at the left panel of Data Factory. I click on the '+' sign and select the item Data flow, as shown below.
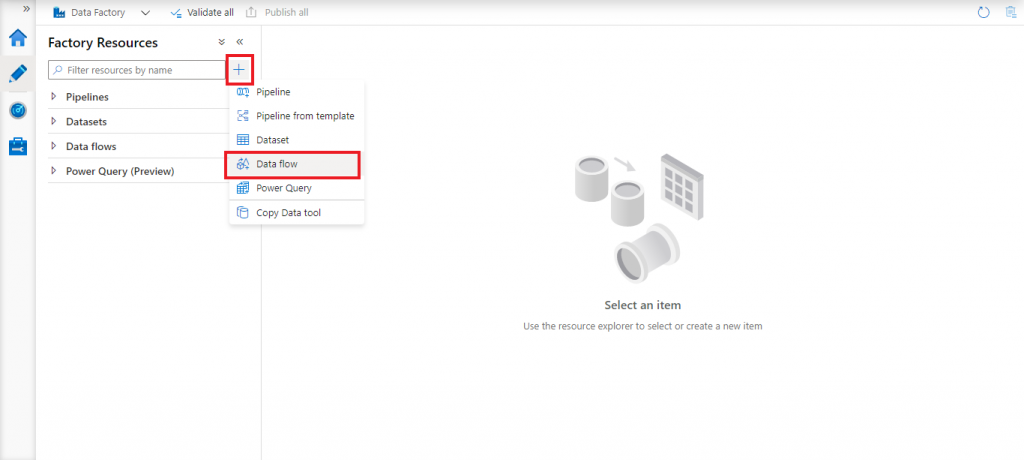
Design canvas
A new design canvas is open where I can design the data flow with an easy visual representation. I first need to add a source, which is the location that will provide the data. The default name for the data flow can also be changed here. I press on the Add Source link and give a name on the right.
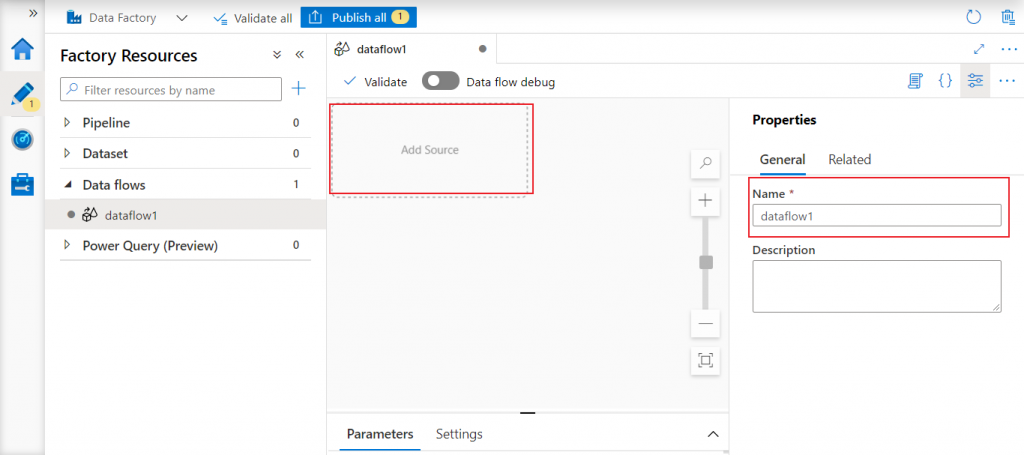
Configure the source
I need to configure the source. I go to the Source Settings tab just below the source component in the Design canvas. Here I may change the default name for the Output stream.
The source type may be Dataset or Inline. If I choose Dataset, I need to configure it. Inline source means that the data may be accessed directly from a source without making any configuration in the data flow. I select the source type as Dataset and press the New button for Dataset.
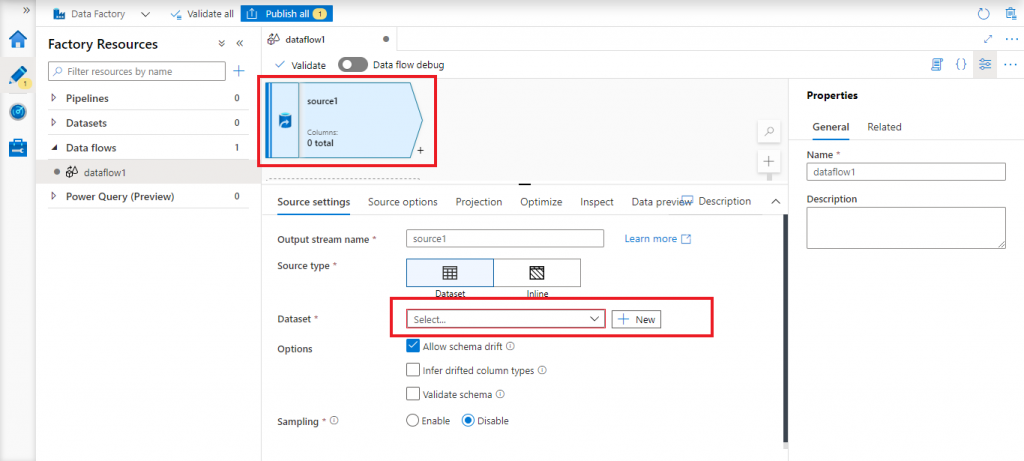
Select the source dataset
A new pop-up window is open. Here, I select the type of input dataset as Azure Blob Storage and press the Continue button.
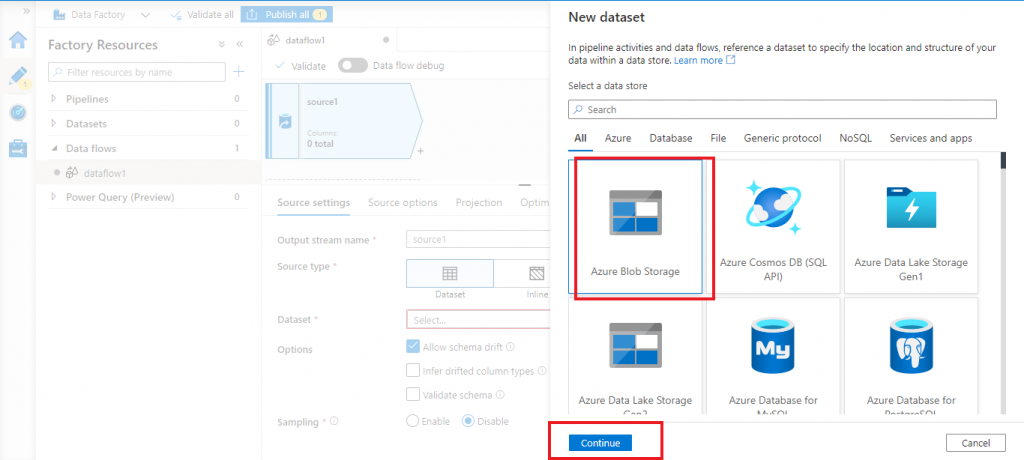
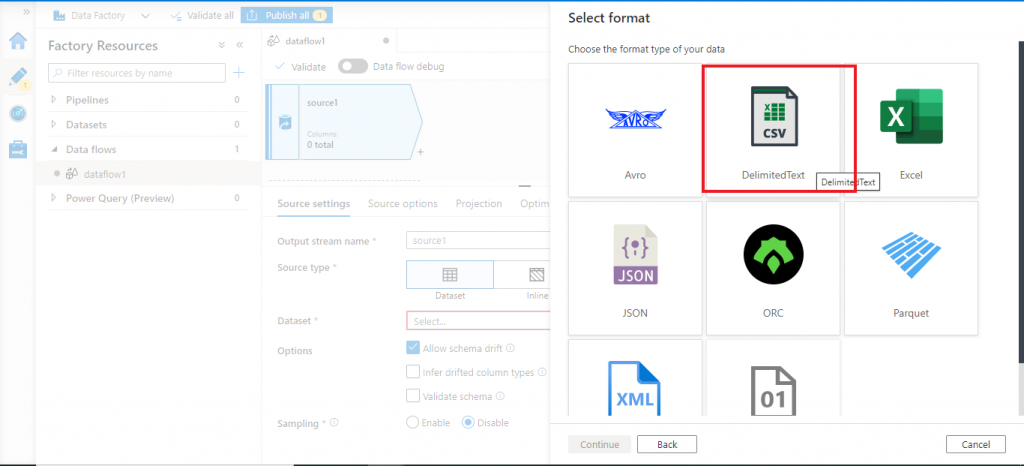
Select the input file format
In the next screen, I need to specify the type of the input file. I select CSV file and press the Continue button.
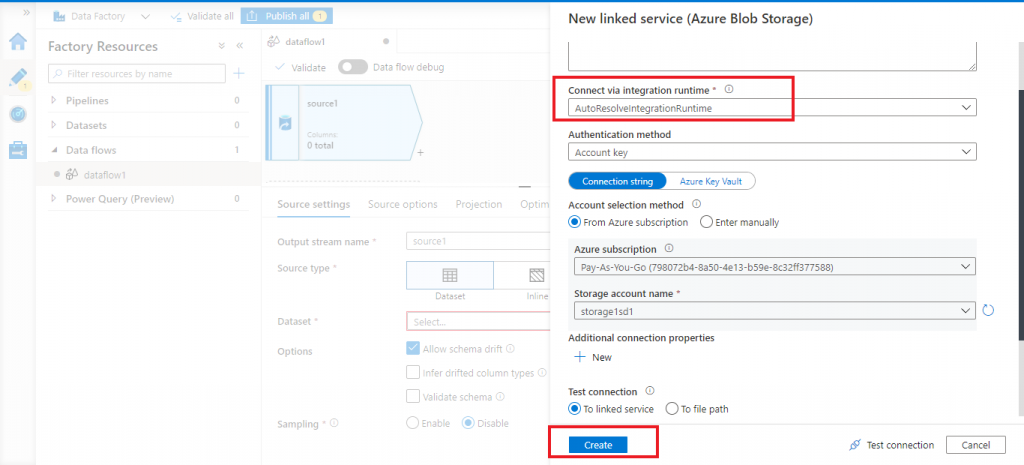
Linked service for Azure Blob storage
In the next screen, I need to provide the details for a new linked service to Azure Blob Storage. I select the default AutoResolveIntegrationRuntime. I provide the Blob Storage account name and press the Create button.
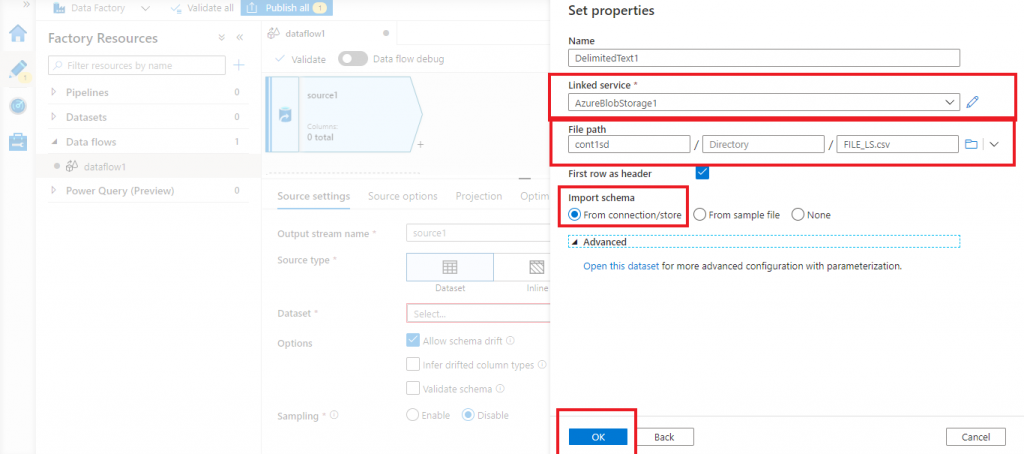
Set properties for the input data set
Once the linked service is created, I provide the details for the input Blob. Here, I need to provide the container name, the folder structure inside the container and the name of the input data file. Then, I press the OK button.
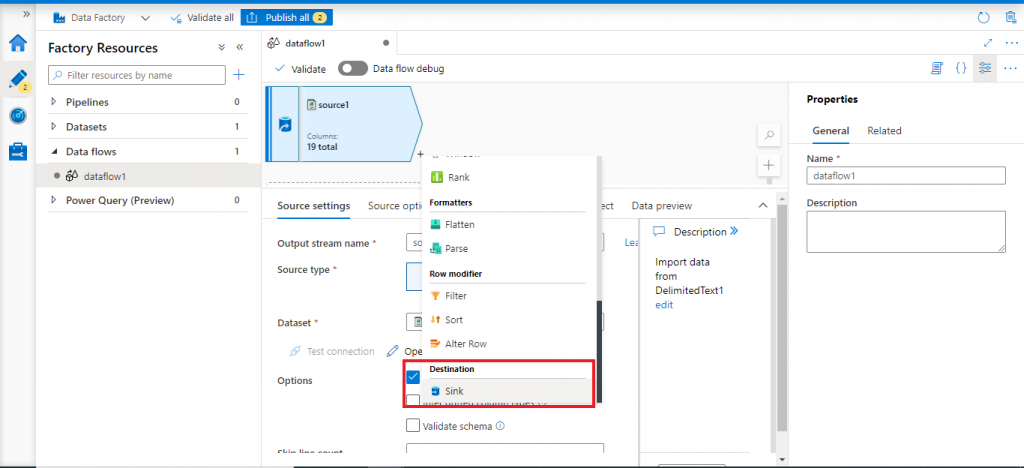
Add a sink after source
Once the source configuration is complete, I press the '+' button in the right bottom of the source component. A drop-down list is open with different types of menu items. I go to Destination and select the item Sink.
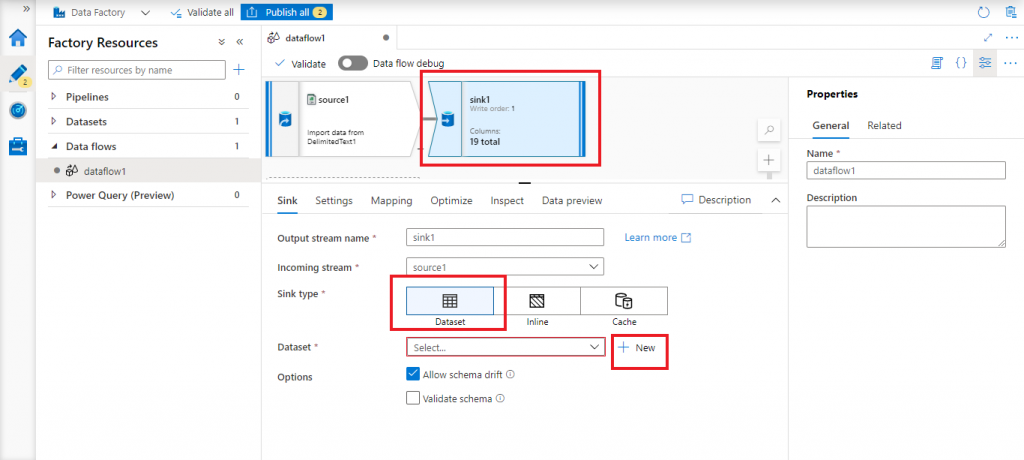
Configure the sink
Now, a sink component is added after the source component in the Design canvas. I need to configure the sink details. I select Sink type as Dataset. Other two options are Inline and Cache. Now, I press the New button next to Dataset.
Dataset for the sink
In the next screen, I select the new dataset type as Azure SQL Database and press the Continue button.
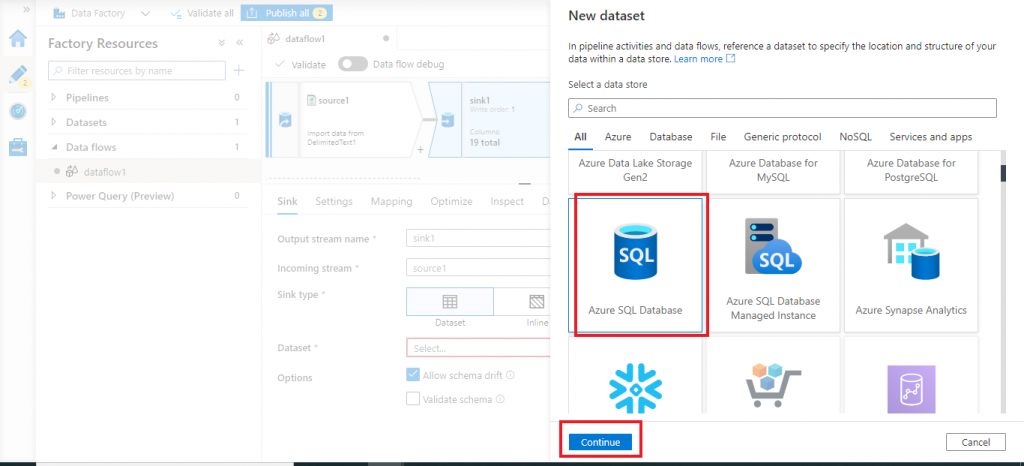
Linked service for Azure SQL Database
In the next screen, I need to configure the new linked service for Azure SQL database. First, I select the default, AutoResolveIntegrationRuntime. Then, I provide the required details related to the Azure SQL Database and press the Create button.
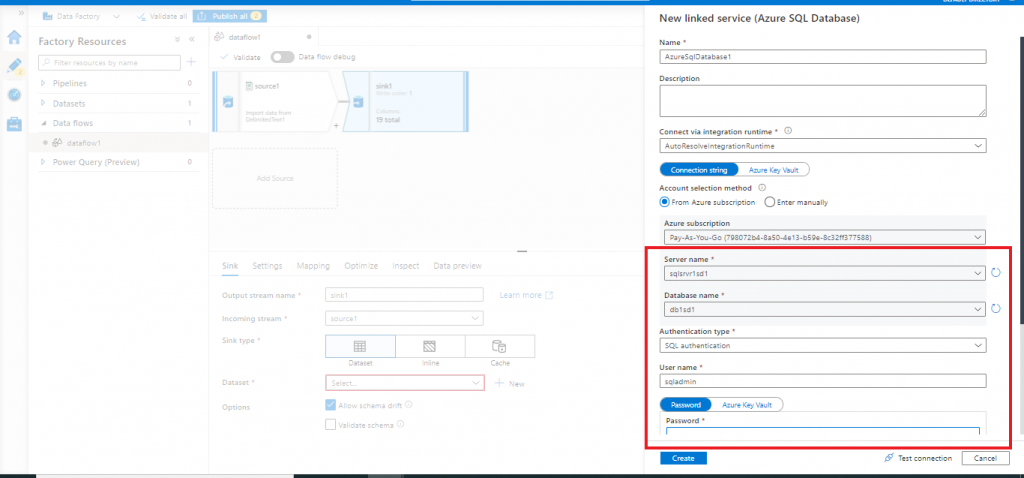
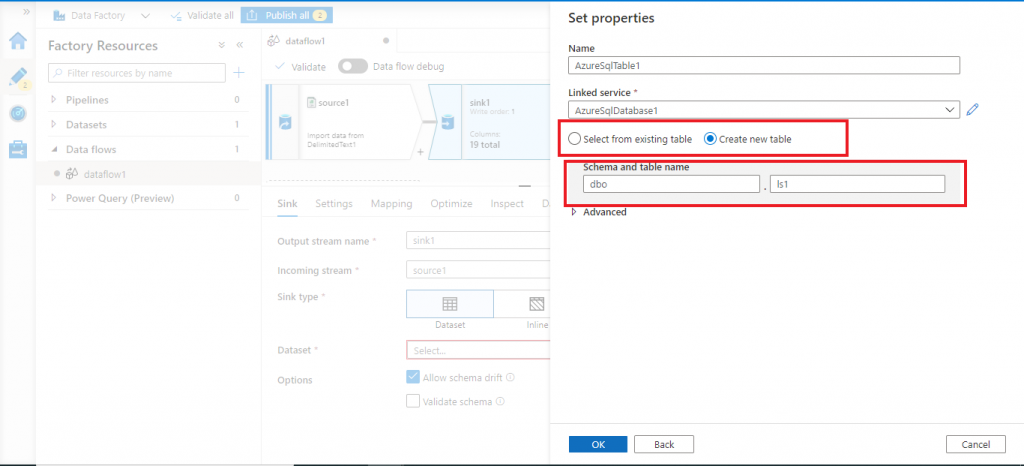
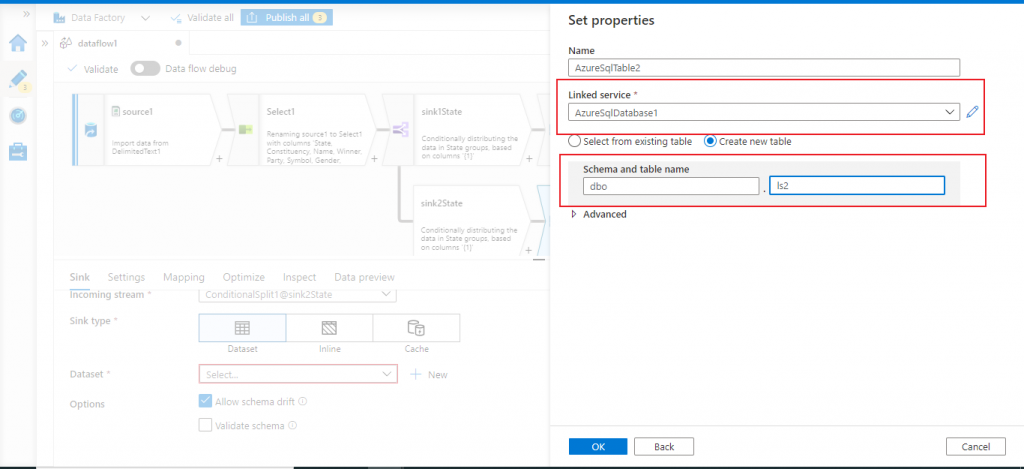
Set properties for the sink
Once the linked service is created, I provide the details for the output table. I may choose an existing table from the database or I may create a new table. I choose the option for creating a new table and provide the details for the schema and table name. Then, I press the OK button.
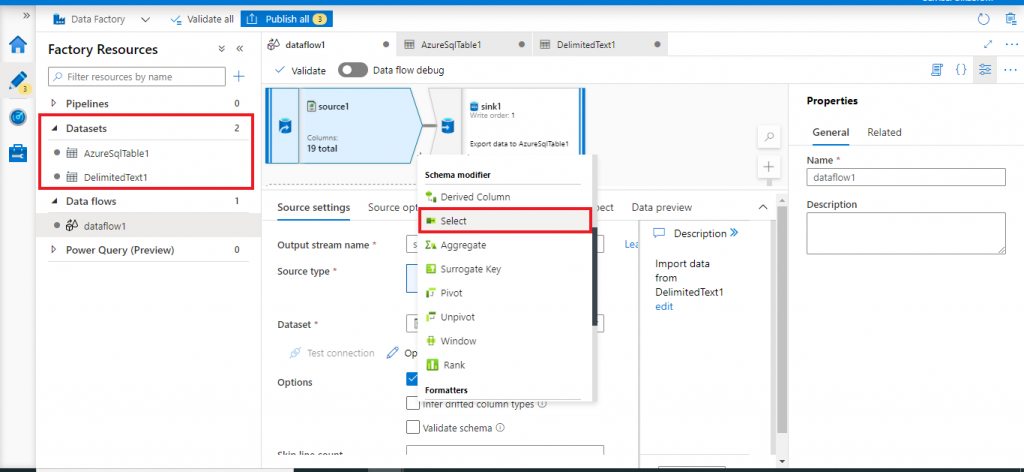
Datasets and Schema modifier
Once the sink configuration is done, I press the '+' button right below the source component in the Design canvas. I click on the Select item under Schema modifier from the drop down list.
There are different categories of items for data transformation in the drop down list.
- Multiple inputs/outputs: used to take data from one input stream and send to multiple output streams or vice versa based on some predefined conditions. The options are New Branch, Join, Conditional Split, Exists, Union, or Lookup.
- Schema modifier: used to make changes in the columns of the input dataset. New columns may be added or existing columns may be removed, renamed, recalculated, restructured. The options are Derived Column, Select, Aggregate, Surrogate Key, Pivot, Unpivot, Window, and Rank.
- Formatters: used to make changes in the dataset structure. The options are Flatten and Parse.
- Row modifier: used to make changes in the rows of the dataset coming from the input stream before sending to the output stream. Filter, Sort, and Alter row are the available options.
In this article, I will use Select and Conditional Split transformations before transferring the data from Azure Blob Storage to Azure SQL Database.
Select Transformation
This Select transformation helps in selecting a subset of columns or source columns with different names and mapping logic to be moved to the sink. I select 10 columns from the total 19 source columns in the settings tab. Now, 10 columns will be copied to the sink once the data flow is executed.
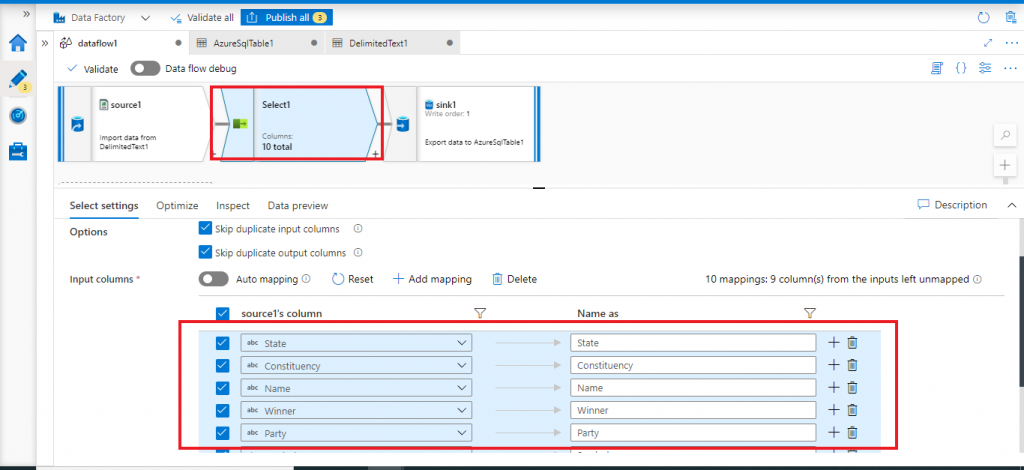
Conditional Split transformation
In between the source and sink components, I may add one or more transformation components. I press the '+' button after the Select transformation and select Conditional Split under Multiple inputs/outputs from the drop-down list.
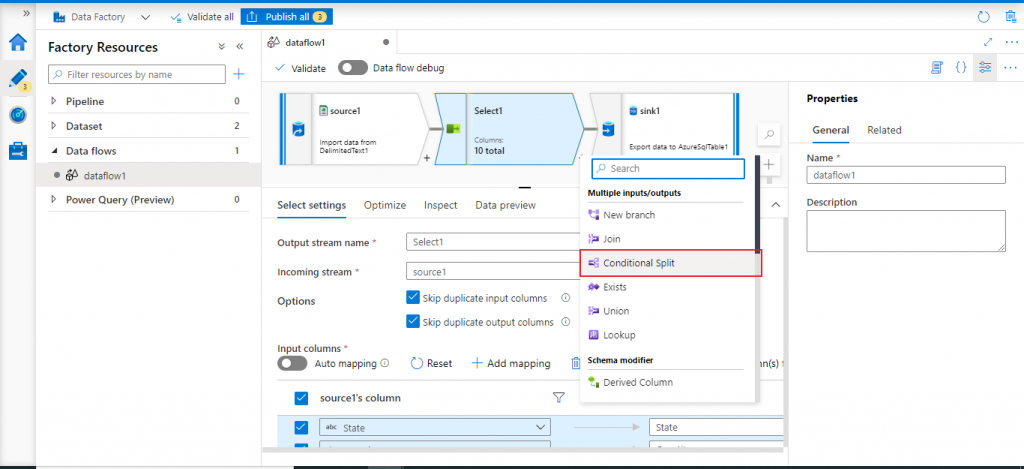
Configure Conditional Split
The Conditional Split helps to split the incoming dataset from the previous component based on some condition. I specify an output stream sink1State, which will contain data for State column only when the value is equal to 'Maharashtra'. This data stream will be copied to sink1, i.e. the new Azure SQL Database table named ls1.
Another output stream named sink2State will have the rest of the records where the State column value is not equal to 'Maharashtra'.
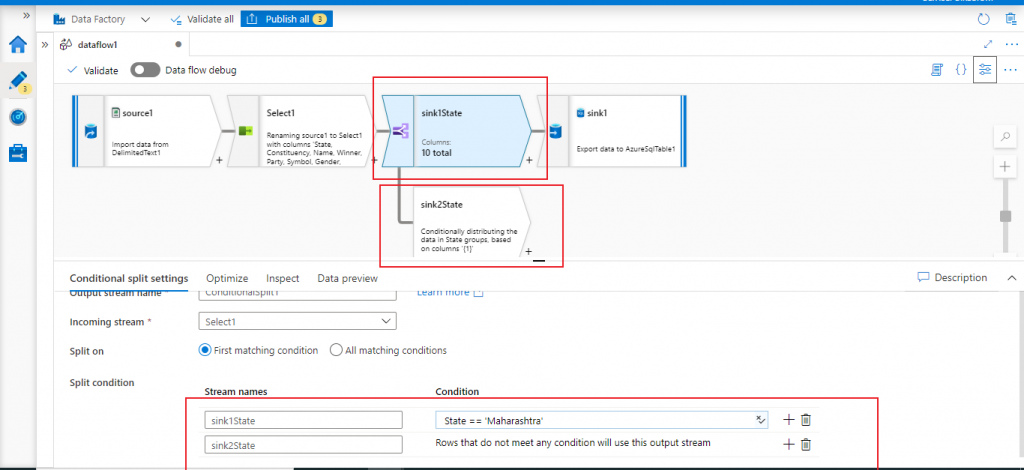
Configure the second output stream
I add another sink component after the output stream named sink2State.
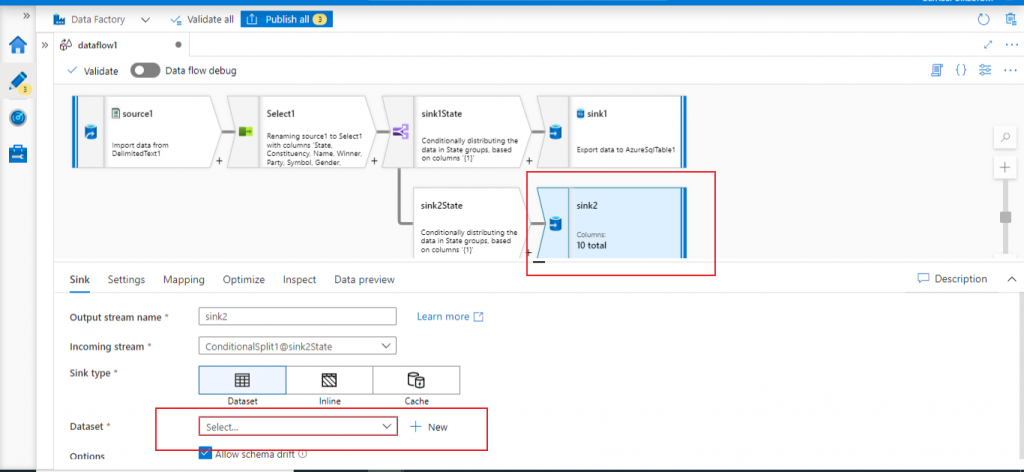
Configure the second sink
I select the same linked service created earlier for Azure SQL Database. I mention a new table named ls2 to populate the data from the second output stream of conditional split.
Activate Data Flow Debug
The debug mode of the mapping data flow allows us to interactively watch the data transformation steps when the build and debug is being executed on the data flow. The debug session can be used to both in the Data flow design session as well as during the pipeline debug execution of data flows. I will explain how to add and execute the data flow from within the pipeline, in the next steps.
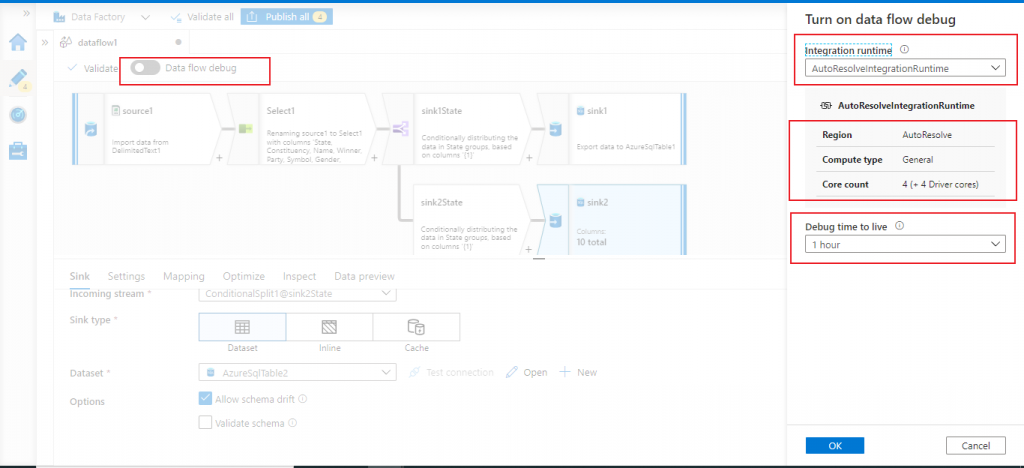
The Data Flow Debug button in the top bar of data flow canvas needs to be turned on to start the debug mode. I move the slider and turn on the debug mode.
As a next step, I need to select the Integration Runtime. I select the AutoResolveIntegrationRuntime. A cluster with eight cores of general compute with a default 60-minute time to live is allotted for the execution of the pipeline. There will be session time-out after 60 minutes of idle time. It is possible to change the time to live (TTL) value. I need to pay hourly charge for the time duration the debug session is turned on.
It is a good practice to build the Data Flows in debug mode. It helps to validate business logic and view the data transformation steps before finally publishing in the Data Factory.
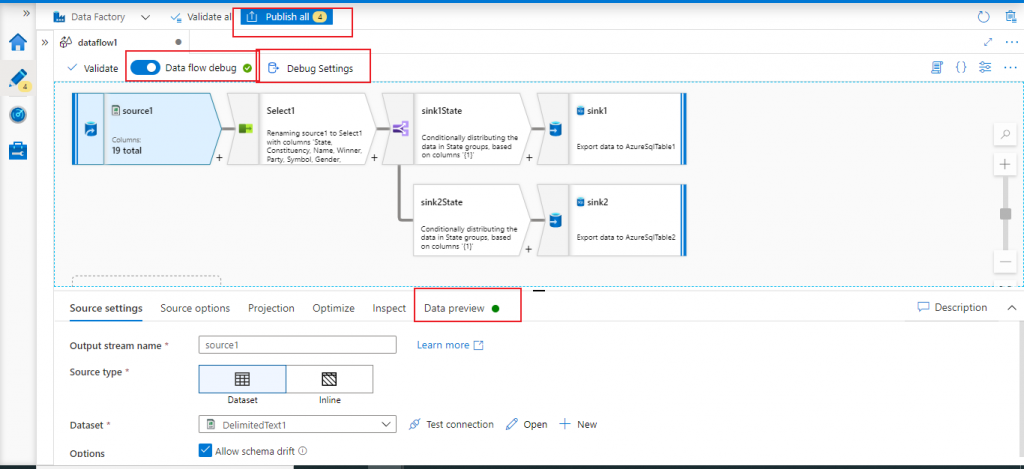
Data flow debug is active now
The green circle beside the Data flow debug indicates that the debug is active now. I may go to Debug settings to modify the existing configuration related to Debug. In the bottom window, a green circle is available beside Data Preview which indicates that the data output for each component may be seen from here now. I press the Publish All button to implement and save all the changes done in the mapping data flow.
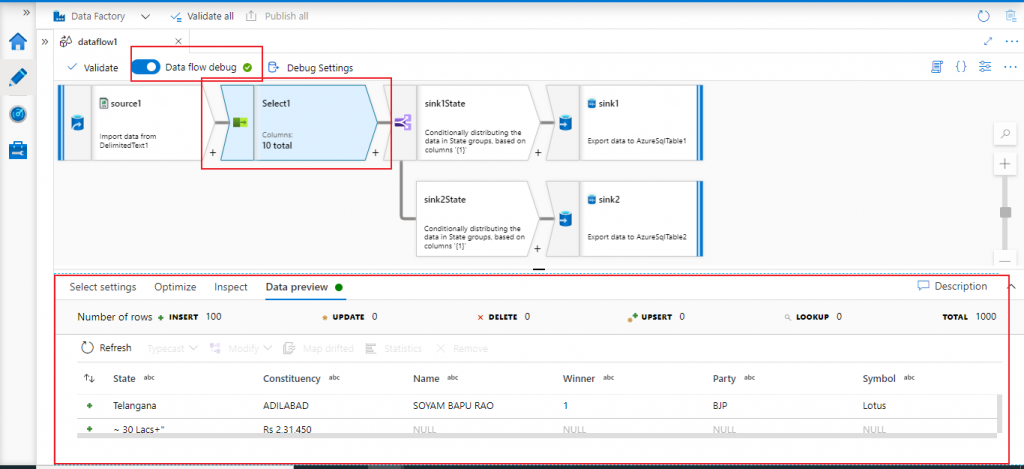
A debug session is started
I can see the Data Preview at each step of the data flow which may help to understand how the data flowing from each input stream to an output stream.
Add data flow in a pipeline
Now, I create a new pipeline from the Author tab and drag a data flow activity. I go to the Settings tab of the Data flow activity and in the Data flow parameter, select the mapping data flow just created, from the drop down list. Next, I press the Publish All button to implement the changes completed in the pipeline.
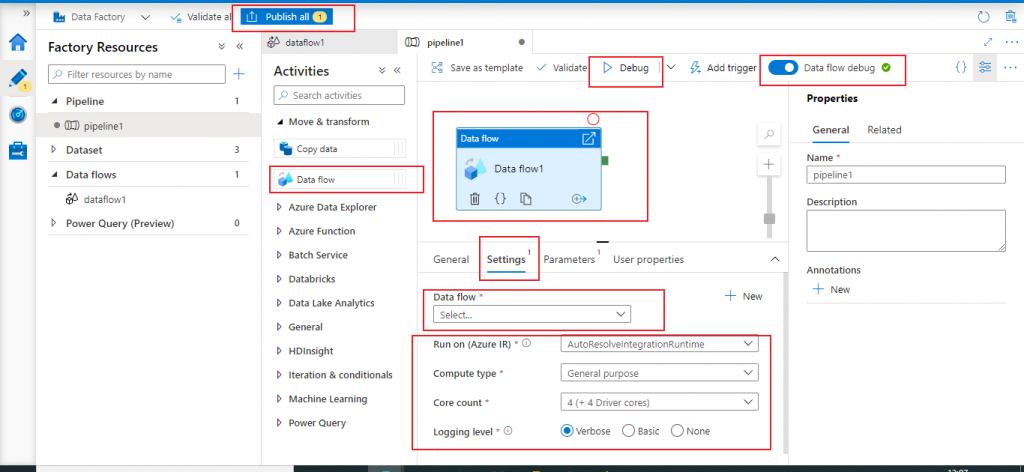
Add Trigger
Now, I go the Add trigger link. Here, I have the choice to execute the pipeline immediately with the Trigger now option. Or, I may create a new trigger to schedule the execution of the pipeline later.
I may press the Debug button as well to start an interactive debug session for the data flow.
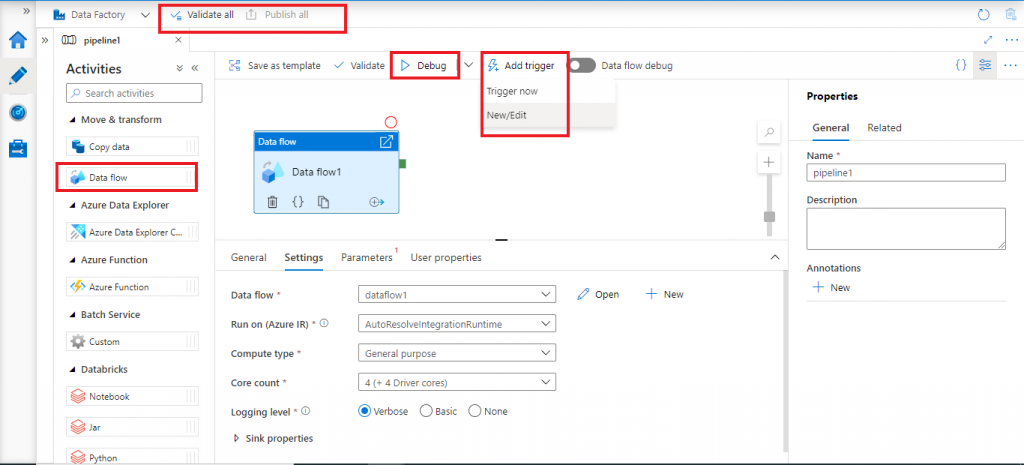
Execute the pipeline
I click on Trigger now option to execute the pipeline immediately.
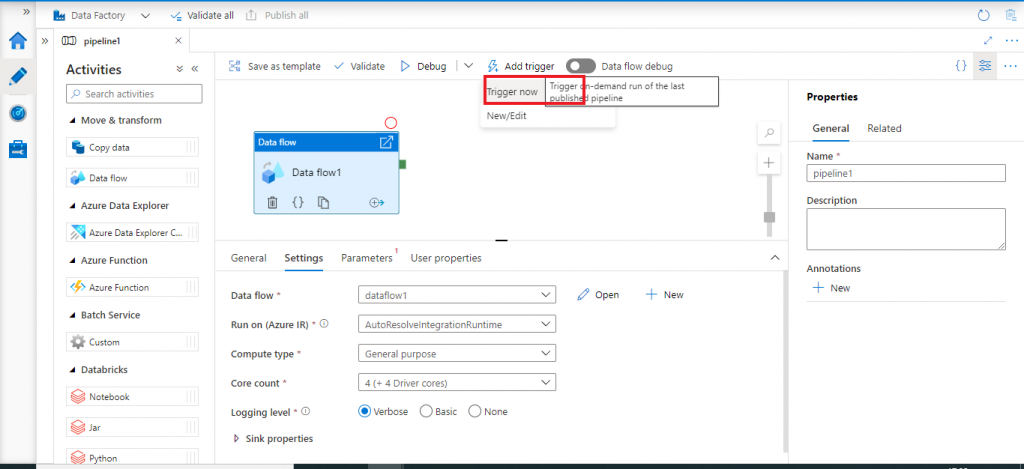
Pipeline run monitoring
The pipeline execution is started. I go to the Monitor tab at the left panel and go to Pipeline runs to check the progress status for the pipeline execution. I click on the Pipeline Name link and I may see the execution status of the different components of the data flow.
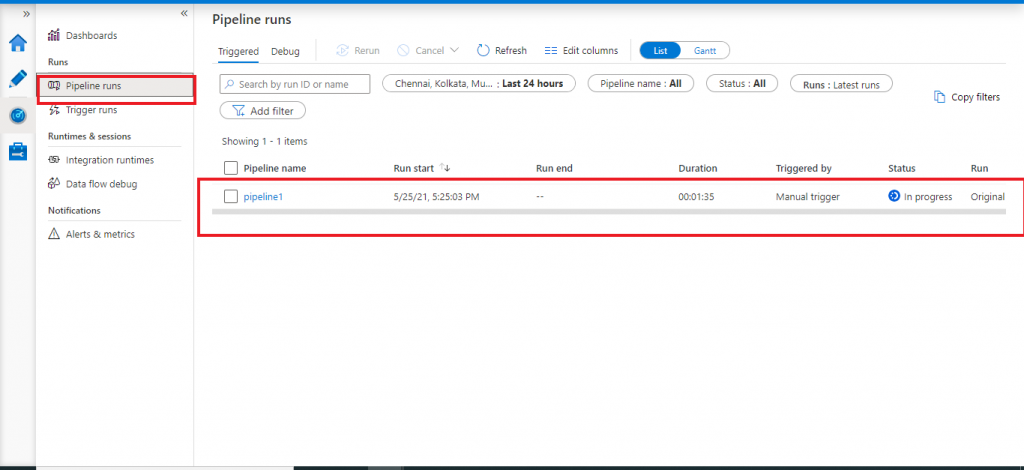
Data flow execution monitoring
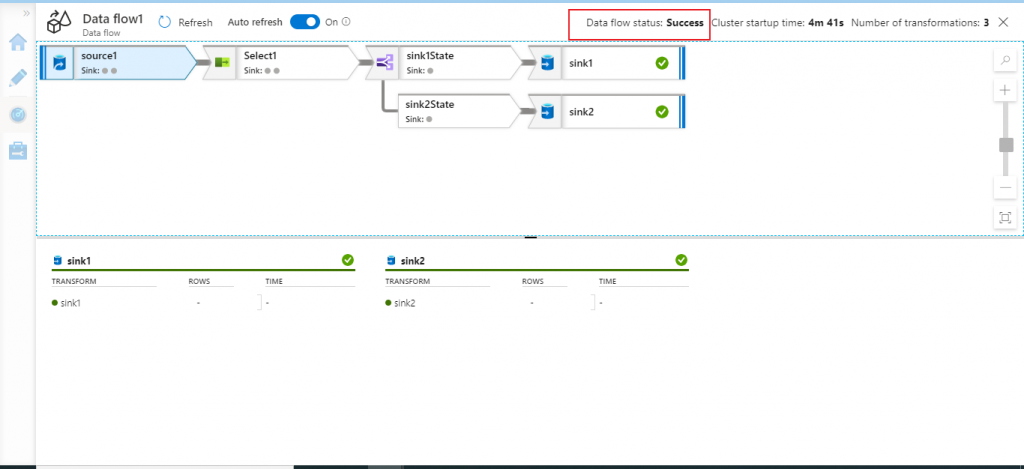
In the next screen, I select the Data flow component and press the data flow details button to see the execution status of each component of the data flow.
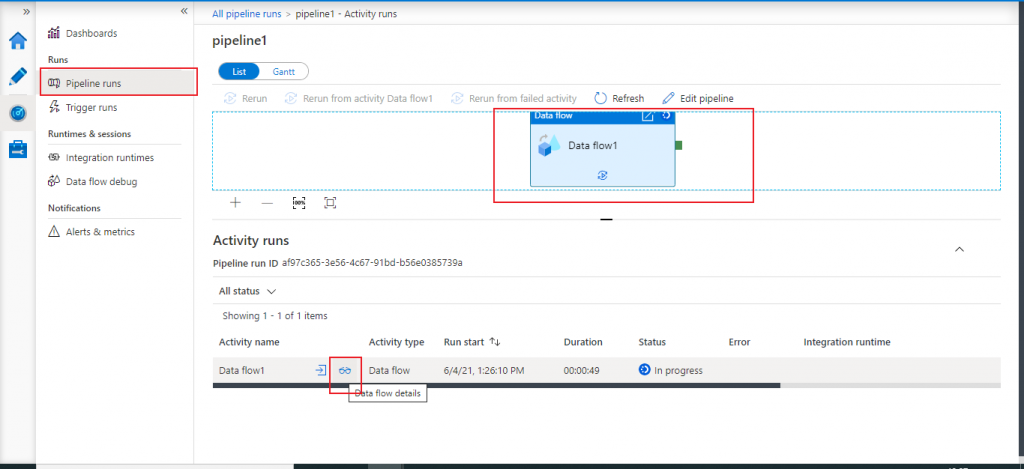
Data flow execution status
Data flow execution is completed successfully. Source data is successfully transferred to the two sinks sink1 (table ls1) and sink2 (table ls2).
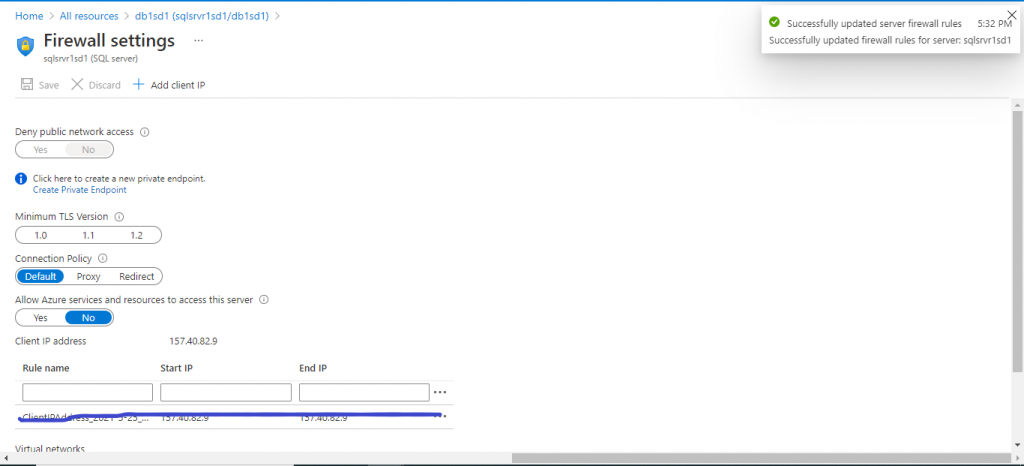
Firewall update in Azure SQL Database
I go to the Firewall settings of Azure SQL Database. I add the client IP address and also check the option for allowing other Azure services and resources to access the SQL Server. I save the changes and go to the Query Editor of the Azure SQL Database.
Query the sink
Two tables ls1 and ls2 are now created with 10 columns each. I write a few queries to check the data in the newly created tables. ls1 table now contains the records with State column value 'Maharashtra'. ls2 table contains the records with State column value other than 'Maharashtra'.
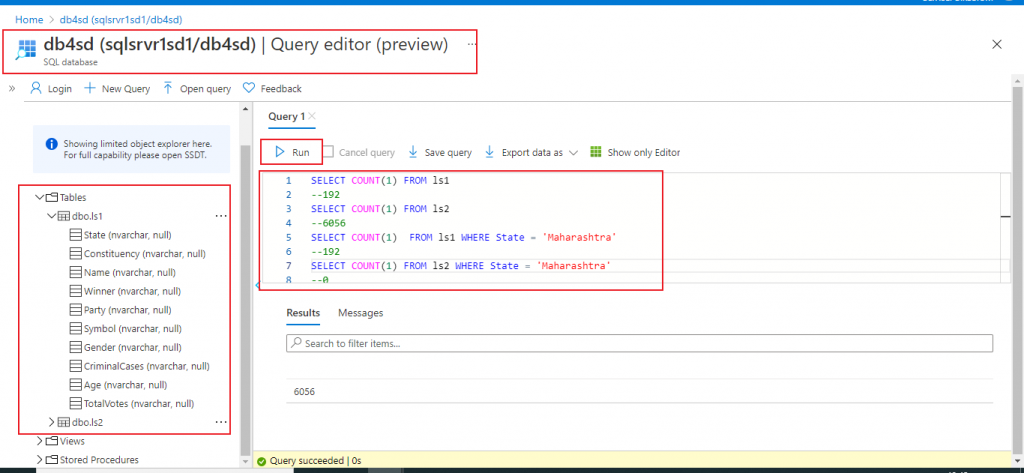
The queries written to check data in the two tables are as below:
SELECT COUNT(1) FROM ls1 --192 SELECT COUNT(1) FROM ls2 --6056 SELECT COUNT(1) FROM ls1 WHERE State = 'Maharashtra' --192 SELECT COUNT(1) FROM ls2 WHERE State = 'Maharashtra' --0 SELECT COUNT(1) FROM ls1 WHERE State != 'Maharashtra' --0 SELECT COUNT(1) FROM ls2 WHERE State != 'Maharashtra' --6056
Conclusion
Mapping data flow helps to design and develop a data transformation logic without writing code. The easy and convenient visual representation helps to implement complex transformation before transferring the data from a source to a destination. The debug mode helps in development and corrections of the data flow as the data preview may be available for the source component and different transformation components. In this article, I could transfer data from Azure Blob Storage to Azure SQL Database after implementing two data transformation steps.
