

Introduction
A transaction is a single logical unit of work. All relational database management systems are expected to follow the four properties of transactions: Atomicity, Consistency, Isolation and Durability. Isolation is necessary in order to make sure multiple transactions are not able to cause changes to data in manner that leaves the eventual results inconsistent. SQL Server guarantees transaction isolation using locking mechanisms. In this article, we shall experiment with a few locking scenarios and see how we can use the sys.dm_tran_locks dynamic management view to observe how SQL Server invoke different kinds of locks depending on the operations desired by the sessions involved.
SQL Server’s mechanism for concurrency control is certainly quite complex. To optimize performance in terms of lock waits, deadlocks, and the like, several decisions have to be made based on the exact scenarios in question. It is worth mentioning that while locks are ALWAYS occurring in the database, the goal of the developer and DBA is to reduce their occurrence by understanding and leveraging the way SQL Server manages concurrency.
Preparing Our Environment
We are going to explore the dynamic management view sys.dm_tran_locks while executing a few SQL Statements in sequence that will cause locks. To prepare our environment we create a single table called Employee (Listing 1). At this stage, it is a HEAP with no indexes whatsoever.
Listing 1: Create and Populate Employee Table
CREATE DATABASE DMV
GO
USE DMV
GO
CREATE TABLE Employee (
EmployeeID INT IDENTITY (1,1)
, FName VARCHAR (50)
, LName VARCHAR (50)
, HireDate DATETIME
, CountryCode CHAR(2)
, DeptID INT
, AvgPerfScore FLOAT
)
-- Populate the Table
insert into Employee
VALUES ('Kenneth','Igiri','20120102','NG',1,96.2);
insert into Employee
VALUES ('Eben','Owusu','20100102','GH',1,97.2);
insert into Employee
VALUES ('Prince','Frimpong','20170102','GH',3,98.2);
GO
insert into Employee
VALUES ('Kokou','Messie','20170102','GH',3,98.2);
GO 20000
Three Statements in Three Sessions
In our experiment, we are going to use three sessions where we execute SQL statements on the Employee table. The first session executes a set of delete statements each within a transaction. We shall call this Kokou's Session. For each Delete Transaction in Kokou's Session, we run SELECT and INSERT statements in other sessions to simulate contention. We achieve this by ensuring that we leave each transaction open while invoking transactions in other sessions.
In all cases of the tests we shall do, we shall use the code in Listing 2 to examine the way SQL Server serializes session 1 (Kokou's Session), session 2 (Eben's Session) and session 3 (Prince's Session) in our experiment. The code projects a few columns from the sys.dm_tran_locks DMV and does a CROSS APPLY to a user defined function, getuser, which is used to associate each session requesting a lock with the connected principal. The DDL for this function is shown in Listing 3.
Listing 2: Querying sys.dm_tran_locks to View Active Lock Requests
USE DMV GO SELECT resource_type , DB_NAME (resource_database_id) database_name --, OBJECT_NAME(resource_associated_entity_id) resource_name , request_mode , request_type , request_status , request_reference_count , request_session_id , resource_associated_entity_id , getuser.login_name FROM sys.dm_tran_locks CROSS APPLY dbo.getuser(request_session_id) as getuser;
This code requires a function, which is created by the code in Listing 3.
Listing 3: SQL Code Used to Create the getuser UDF
USE DMV GO SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO -- DROP FUNCTION [dbo].[getuser] CREATE FUNCTION dbo.getuser ( @sessionid AS INT ) RETURNS TABLE AS RETURN SELECT login_name FROM sys.dm_exec_sessions WHERE session_id=@sessionid; GO
In the following sections, we shall describe the three experiments we perform across all three sessions one after the other.
CASE I: Delete All Rows in Employee
The first experiment we shall conduct is to invoke a delete operation on all rows in the Employee. We want to see what kind of lock requests are registered when we invoke a delete all operation followed by attempts to select rows from the same table. Take note that the table Employee is still a heap (no clustered index). We open a transaction explicitly in this session but we neither COMMIT nor ROLLBACK (see Listing 4). Run this code in a query window.
Listing 4: Kokou's Session - Delete All Rows from Employee
BEGIN TRAN USE DMV GO DELETE FROM EMPLOYEE; -- ROLLBACK
While the delete transaction is still open in Kokou's Session, we invoke a SELECT statement in Eben's Session (Listing 5) and then and INSERT in Prince's Session (Listing 6). Notice that in all cases, all transactions are open so we can see clearly the effects in terms of locking.
Run the code in Listing 5 in a new query window.
Listing 5: Eben's Session - Select All Rows from Employee
BEGIN TRAN USE DMV GO SELECT * FROM Employee; -- ROLLBACK
Run the code in Listing 5 in a new, third, query window.
Listing 6: Prince's Session - Insert a New Row in Employee
USE DMV
GO
INSERT INTO Employee
VALUES ('Janet','Afari','20170102','GH',3,98.2);
GO
-- ROLLBACKIn a fourth query window, run the code in Listing 2.
Analysis
We see from the request_status column in Figure 2 that Kokou's Session (session ID 60 as shown in the request_session_id column) acquires EXCLUSIVE locks on the page where the Employee table sits in order to execute a delete of all rows. The other two sessions Eben's Session (session ID 62) and Prince's Session (session ID 59) need to WAIT for this transaction to be committed or rolled back. Notice that Eben's Session is asking for an INTENT SHARED lock (IS) in order to execute a SELECT statement. On the other hand, Prince's Session is asking for an INTENT EXCLUSIVE lock (IX). BOTH sessions must WAIT.
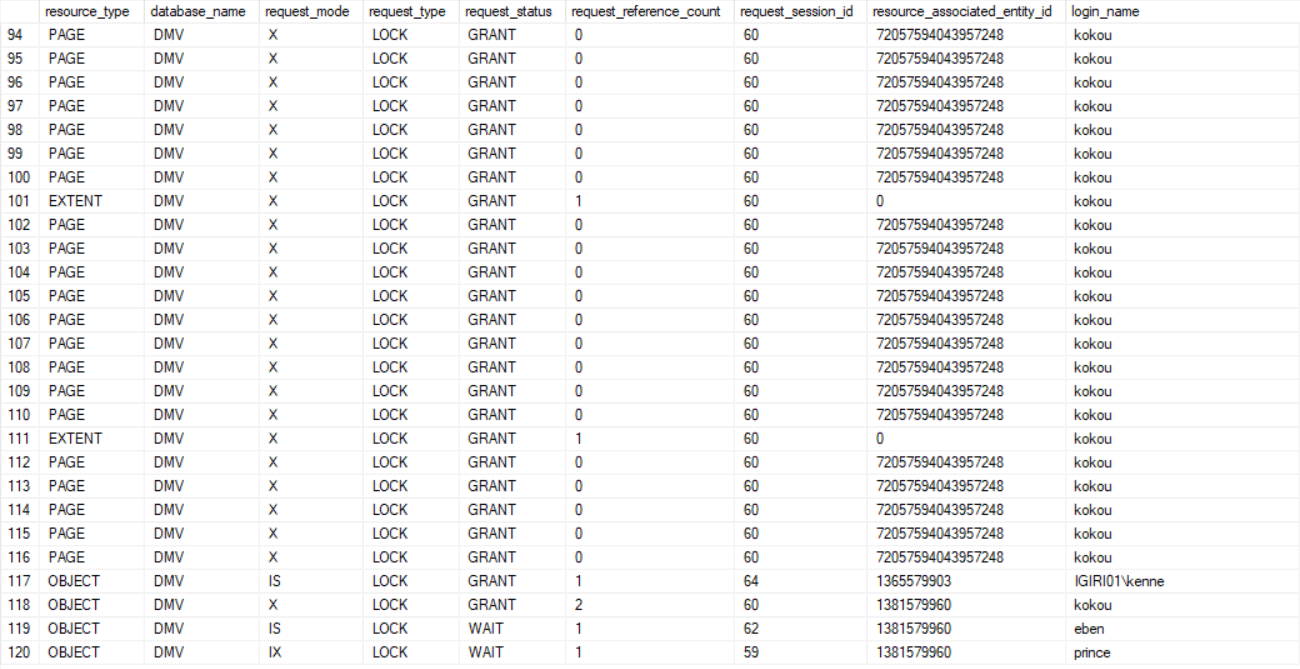
Figure 2: Locks Associated with Delete All Rows
Intent locks are acquired on a higher-level resource (such as at the table level) before attempting to acquire the actual desired lower level lock (e.g. at page or row level) so that no other session acquires a conflicting lock at that higher level. SQL Server would typically check for these intent locks at the higher level before checking for any lower level locks since this approach is more efficient. For example, a check is done for any Intent Exclusive locks on the Employee table before trying to acquire an Exclusive lock on a page or row in that same table.
At the end of each Case, we perform a ROLLBACK and then start over. You will need to run this rollback in each of the three query windows.
CASE II: Delete One Row in Employee
In Case II, we start the experiment by invoking a delete on one one row (see Listing ) in Kokou's Session. We then follow this with the same SELECT and INSERT operations used earlier in Eben's Session and Prince's session respectively (Review Case I, see Listings 8 and 9). We want to see whether the type of locks invoked in the case of a single row delete differ from Case I where we execute a delete on all rows in Employee.
Run each of these code samples in a separate query window.
Listing 7: Kokou's Session - Delete One Row from Employee
BEGIN TRAN USE DMV GO DELETE FROM EMPLOYEE WHERE FName='Kenneth'; -- ROLLBACK
Listing 8: Eben's Session - Select All Rows from Employee
BEGIN TRAN USE DMV GO SELECT * FROM Employee; -- ROLLBACK
Listing 9: Prince's Session - Insert a New Row in Employee
USE DMV
GO
INSERT INTO Employee
VALUES ('Janet','Afari','20170102','GH',3,98.2);
GO
-- ROLLBACKNow run the code in Listing 2 again in a fourth query window. You should get results similar to those down in Figure 3.
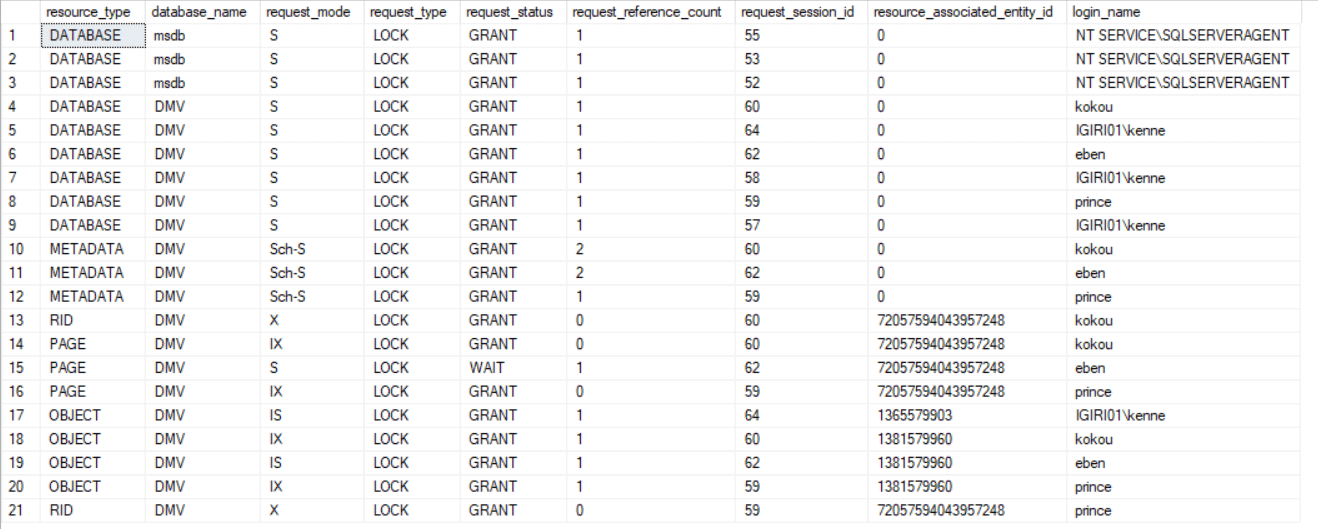
Figure 3: Locks Associated with Delete One Row
Analysis
We see a much shorter result set from sys.dm_tran_locks. Take a look at the request_status, request_session_id and login_name columns in Figure 3. Kokou's Session (session ID 60) acquires an INTENT EXCLUSIVE lock on table Employee and an EXCLUSIVE lock on the Row ID associated with the FName value “Kenneth”. On the other hand, Eben's Session (session ID 62) still needs to wait for a SHARED lock on the page where the Employee table sits to select ALL rows even though he has been granted an INTENT SHARED lock on the table (see rows 15 and 19 on Figure 2).
Thirdly, we see that the Prince's Session (session ID 59) successfully acquires an INTENT EXCLUSIVE lock on the Employee table and an EXCLUSIVE lock on the desired row in the table. Comparing this with the previous case, notice that a “Delete All” transaction will cause more blocking than a delete statement with a filter. This makes a good case for the use of TRUNCATE when Delete All is desired.
Be sure to run the rollback code in each query window now.
CASE III: Delete a Range of Rows in Employee
The third case is the case where we delete a range of rows that meet the criteria in the filter. SQL Server has to decide whether the number of rows that satisfy the filter are enough to escalate from a row level locking to table level locking. We execute the modified delete code shown in Listing 10 followed once again by the same SELECT and INSERT statements in Listing 11 and Listing 12.(executed within transactions).
Be sure each is executed in a separate query window.
Listing 10: Delete a Range of Rows from Employees
BEGIN TRAN USE DMV GO DELETE FROM EMPLOYEE WHERE FName LIKE '%Kokou%'; -- ROLLBACK
Listing 11: Eben's Session - Select All Rows from Employee
BEGIN TRAN USE DMV GO SELECT * FROM Employee; -- ROLLBACK
Listing 12: Prince's Session - Insert a New Row in Employee
USE DMV
GO
INSERT INTO Employee
VALUES ('Janet','Afari','20170102','GH',3,98.2);
GO
-- ROLLBACK
Now again we execute the code in Listing 2 (Querying sys.dm_tran_locks to View Active Lock Requests) in a separate query window. Your results should be similar to the screenshot shown in Figure 4.
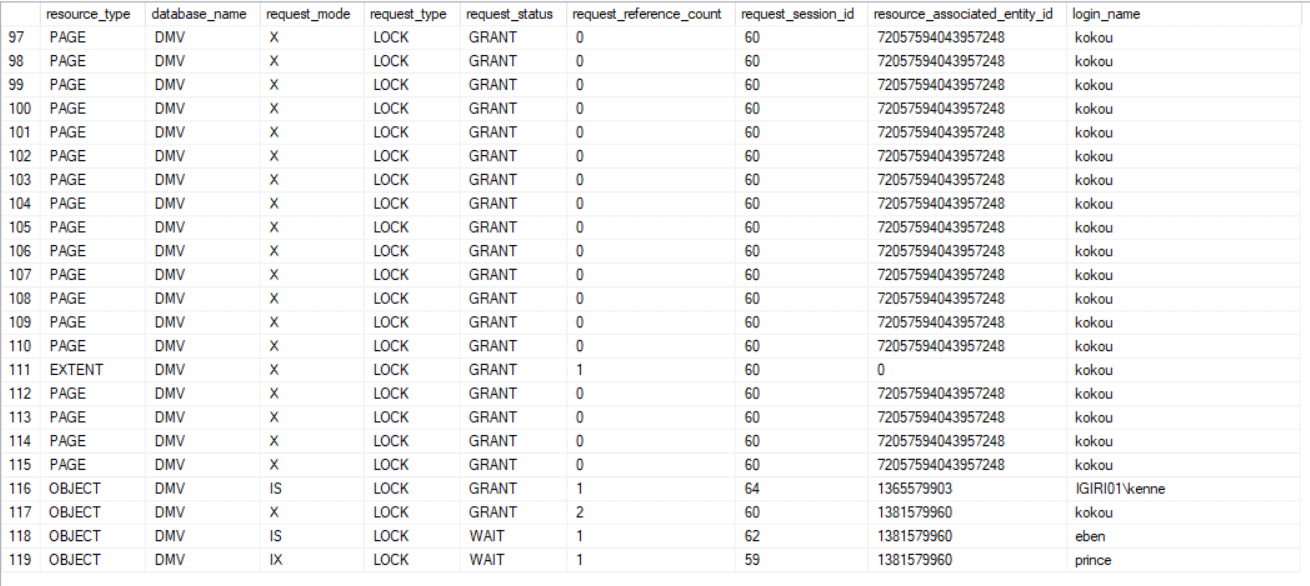
Figure 4: Locking with Delete on a Range of Rows
Analysis
We see a similar outcome as with Case I. SQL Server decided that the number of rows involved in this operation is as good as locking the entire table. A different outcome might be experience if the scenario is different. As an example, using the code in Listing 13 yields the output shown in Figure 5.
Listing 13
BEGIN TRAN USE DMV GO DELETE FROM EMPLOYEE WHERE FName LIKE '%Prince%'; -- ROLLBACK
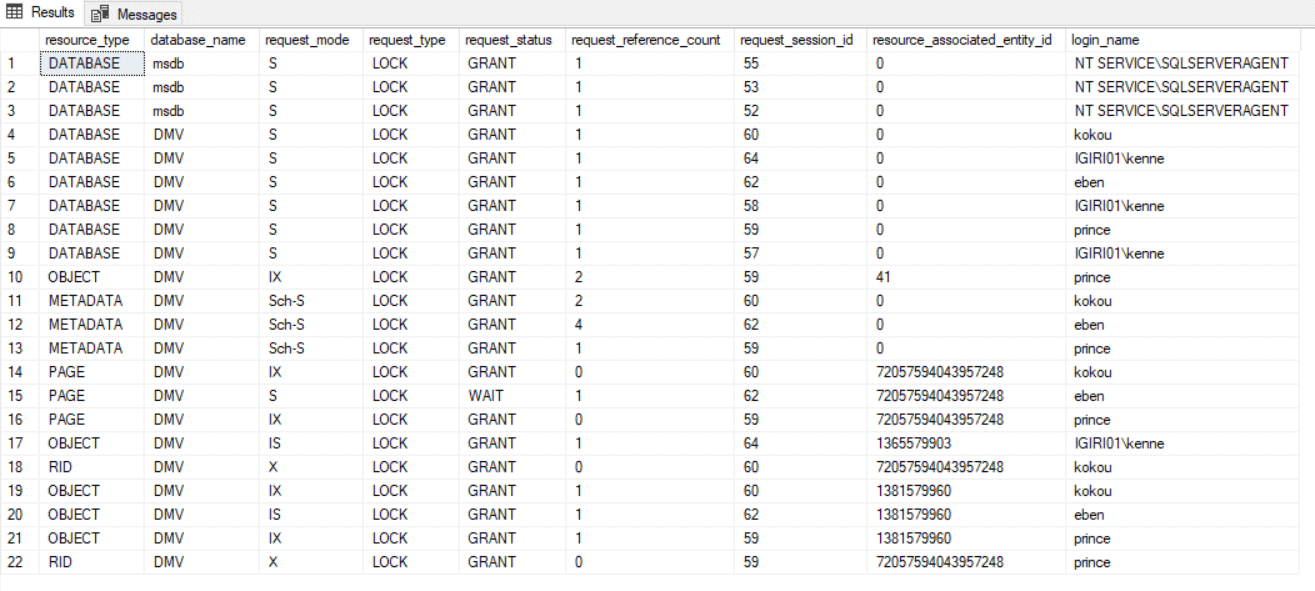
Figure 5: Locking with a Small Range
Introducing a Primary Key
In this section we repeat the steps described in Case I (see Listings 4,5 and 6 earlier in this article) but this time, before we do so, we introduce a Primary Key by executing the code in Listing 14. A primary key introduces an index to the table which changes the way SQL Server executes the statement and improves the performance.
Listing 14: Creating a Primary Key
ALTER TABLE Employee ADD CONSTRAINT PK_EmployeeID PRIMARY KEY (EmployeeID);
Figure 6 shows us that the dynamics change significantly for Case I when we introduce a Primary Key on the Employee table using the code in Listing 14. We still see both sessions 62 and 59 having to wait, but the locking mechanism takes advantage of the clustered index created by the Primary Key and locks the Employee table right away, a less expensive route than having to acquire page level locks.
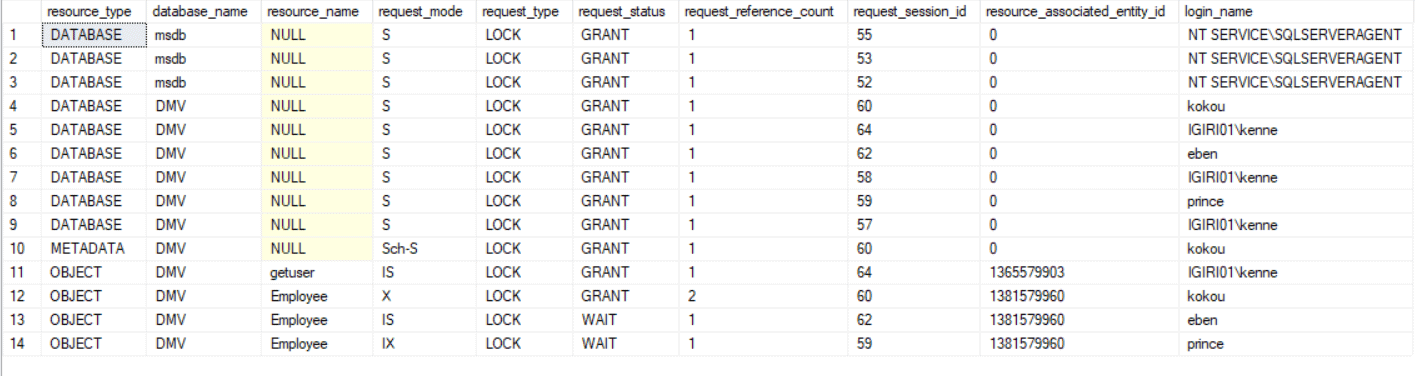
Figure 6: Delete All Rows with Primary Key
Analysis
Listing 15 is the first piece of code from Case I (see Listing 4). We are using it here to compare how SQL Server does not need an exclusive lock on all pages physically holding data for the employee table. Instead, SQL Server chooses to acquire a lock on the Employee table right away (compare Figure 2 with Figure 6). This is possible since Employee is not long o heap. SQL Server takes advantage of the index to approach the code with a more efficient execution plan. (Compare Figure 7 and Figure 8).
Listing 15: Kokou's Session - Delete All Rows from Employee
BEGIN TRAN USE DMV GO DELETE FROM EMPLOYEE; -- ROLLBACK
Figures 7 shows the execution plan for Case I when we run the delete statement shown in Listing 15 WITHOUT an index. Figure 8 shows the execution plans for this same code when we introduce an index by creating a Primary Key. Without the primary key, SQL Server chooses to scan all pages in the table which is a less efficient plan that using the clustered index. This underscores one good reason to implement clustered indexes.
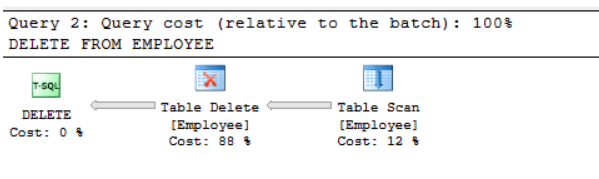
Figure 7: Execution Plan for Heap Delete
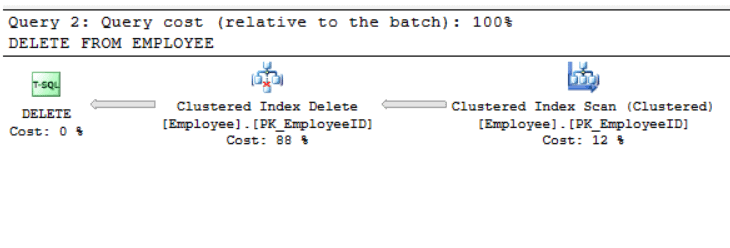
Figure 8: Execution Plan for Clustered Index Delete
Conclusion
Using a set of simple experiments, we have learnt a little more about locking and blocking in SQL Server. We gave reasons for recommendation to use TRUNCATE instead of DELETE (ALL). We also highlighted the need for clustered indexes and how INTENT locks are used in SQL Server. Finally we add a bonus experiment by introducing a clustered index on the Employee table. Feel free to repeat the experiments using tables with a slightly different distribution of data and evaluate the differences in behaviour. In a subsequent article, we shall explore the use of transaction isolation levels in changing these behaviours in SQL Server.
