

Introduction
In this article we highlight the benefits of Database Snapshots and a specific way in which the feature was of use to use in a recent service migration excercise. We shall highlight briefly the concept of Database Snapshots, general use cases and the simple process of creating and dropping a database snapshot.
Concept
A database snapshot is a transactionally consistent, read-only copy of a database sitting on the same instance as the source database. A database snapshot depends on the sources database and cannot be modified. When modifications are made on the source database, the original page is preserved in the snapshot using sparse files. This means that the original data is still available on the snapshot as far as the “reader” is concerned. It also means that the more changes are made to the source database, the larger the sparse files grow. At the point the snapshot is taken, the snapshot is almost empty.

Fig. 1 Database Files and Sparse Files (_snap)
When checking the size of a datafile belonging to a source database and a sparse file belonging to it's corresponding snapshot database, they look the same at face value in Windows Explorer. (see Fig 1 above). On taking a deeper look by examining the properties of each file, we find that the actual space occupied by a sparse file on disk is much less that the datafile size when the snapshot is initialy created. (see Fig. 2 below). In the case of the database file on the left in FIg. 2 (realtime_02), the size and size on disk are the same (6.68 GB) but for the sparse file on the right (realtime_02_snap), the nominal size is 6.68 GB while the size on disk is 64.0 KB.
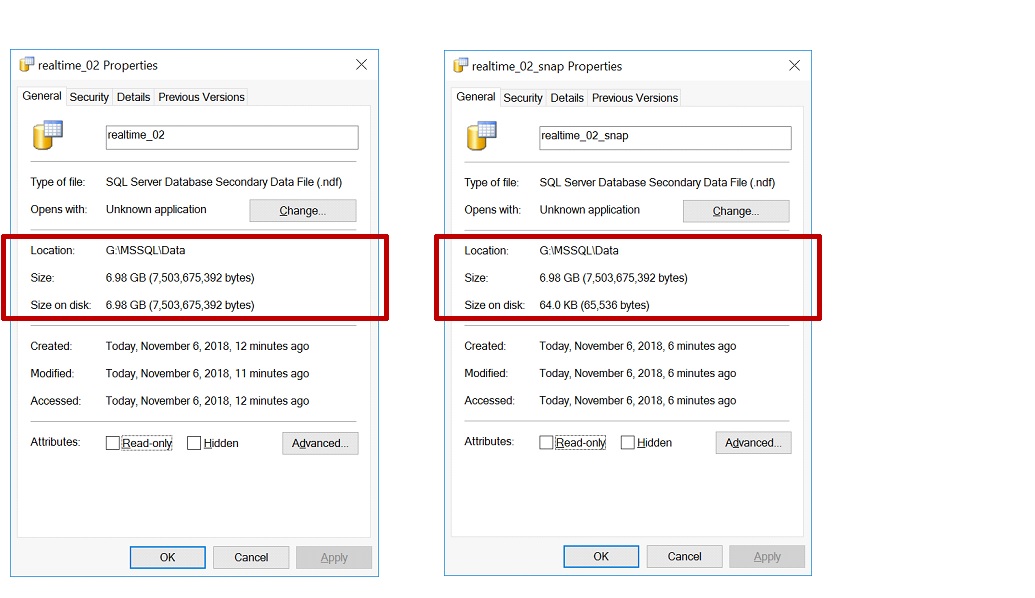
Fig. 2 Actual Data File and Sparse File Sizes
General Use Cases
Microsoft lists a number of possible uses of Database Snapshots in the Benefits of Database Snapshots section of this article. For the purpose of this article we simplify the use cases are follows:
Delayed Reporting
There are cases where it is necessary to preserver the current state of the database for reports at a later time. A good example of this is in banks which perform End of Day/Month Processes. The case in question may look like this:
- The End of Day process consists of, say 10 stages
- Reports are required at stage 5 and automated
- The Core Banking system must be at stage 10 for business to resume the next day
- The Business Reporting Unit is NOT a 24x7 unit
- Thought the reporting can be automated, the Business Reporting unit must review the source of the reports during the next business day
In the scenario described above, a database snapshot can be used to preserve the database at the state required for regulatory reporting (Stage 5). One other way to achieve this would be to take a backup of the database and restore to an instance dedicated to Reporting. This approach, however, would mean taking up the same amount of storage as the source database a situation which a database snapshot circumvents.
Recovery from Human Errors
Database snapshots taken at intervals can serve as a quick way to recover from user error or admin error (as in the case of implementing changes). If an error such as damage to data or damage to database objects occurs, the DBA can quickly revert to the snapshot. However snapshots should not replace a proper Data Protection and Disaster Recovery Strategy.
Change Rollback
In certain situations where it is necessary to make changes to database objects, using a database snapshot can be considered a quick rollback plan. This rollback plan would be valid if the change in question involves only database objects.
Workplace Example
In a recent case where we needed to move a database to a new data centre, the nature of the application made it unreasonable to simply do a backup and restore or depend completely on replication. We had implemented Transaction Log Shipping and were ready to switch but were told by the Application Team that this would simply not work for this particular application. Depending on a backup as a rollback plan was also out of the question because this system supported ATMs and management did not have any appetite for long downtimes. In addition, there was talk of the need to make changes to the database at the destination data centre after migration because configurations like IP Addresses were stored within the database. These IP Addresses would change in the new data centre.
The approach we took was like this:
1. Configured Transaction Log Shipping and ensured data was being replicated to the new Data Centre
2. On the night of the Change we did not do a Role Switch, we simply opened the secondary database. This ensured that the primary and secondary databases were at the same point in time.
-- Opening the Secondary Database RESTORE DATABASE [realtime] WITH RECOVERY;
3. We then took backups and snapshots of the database at both the Old Data Centre and the New Data Centre. After this the application team proceeded with their activities required before final cutover.
-- Creating a Database USE [master] GO CREATE DATABASE [realtime] CONTAINMENT = NONE ON PRIMARY ( NAME = N'realtime_01', FILENAME = N'G:\MSSQL\Data\realtime_01.mdf' , SIZE = 1048576KB , MAXSIZE = UNLIMITED, FILEGROWTH = 65536KB ), FILEGROUP [USERDATA] DEFAULT ( NAME = N'realtime_02', FILENAME = N'G:\MSSQL\Data\realtime_02.ndf' , SIZE = 7327808KB , MAXSIZE = UNLIMITED, FILEGROWTH = 65536KB ), LOG ON ( NAME = N'realtime_log', FILENAME = N'G:\MSSQL\Log\realtime_log.ldf' , SIZE = 5524544KB , MAXSIZE = 2048GB , FILEGROWTH = 65536KB ) WITH CATALOG_COLLATION = DATABASE_DEFAULT GO
This code shows the syntax for creating a Database Snapshot.
-- Creating a Database Snapshot USE [master] GO CREATE DATABASE [realtime_snap] CONTAINMENT = NONE ON PRIMARY ( NAME = N'realtime_01', FILENAME = N'G:\MSSQL\Data\realtime_01_snap.mdf' ), ( NAME = N'realtime_02', FILENAME = N'G:\MSSQL\Data\realtime_02_snap.ndf' ) AS SNAPSHOT OF [realtime] GO
Observe that the syntax is similar to the syntax for creating a database. Thus you can script the source database and then remove the LOG ON and SIZE clauses. This is not the actual database but a copy of the WideWorldImporters database thus in this example I have also excluded the InMemory file since FILESTREAM datafiles are not supported for Database Snapshots.
Rollback Required
It happened that in this case, we needed to rollback change after about three hours. Reverting to the snapshot was very helpful. We did noticed however, that because sessions were active on the Old Data Centre, it too a little longer to revert than it did at the New Data Centre. This is worth remembering if time is a constraint in your case.
Let’s assume the changes made were dropping two tables as shown here.
-- Dropping Tables USE [realtime] GO DROP TABLE [Sales].[CustomerTransactions] DROP TABLE [Sales].[InvoiceLines] GO
Once we do this in this re-enactment, we find that the tables are gone in the source database (shown here)
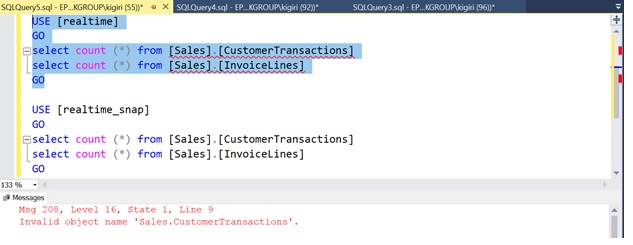
Fig. 4 Tables Dropped in [Realtime]
The tables are still available in the snapshot. (Fig. 5).
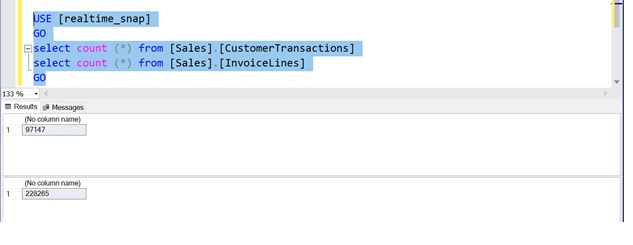
Fig. 5 Tables Still Available in [Realtime_Snap]
We can then revert to the snapshot as a roll back plan as shown here.
-- Dropping Tables USE master; GO RESTORE DATABASE realtime from DATABASE_SNAPSHOT = 'realtime_snap'; GO
Conclusion
Having a Database snapshot helped us in this case when we needed to roll back in the shortest possible time. It became obvious that having a Database Snapshots can be a very effective addition to the Rollback Plan for any database related change. While there are a number of limitation to using snapshots, they come in quite handy in Change scenarios where a quick rollback is required.

