

Good indexes are the key to good performance in SQL Server and the key to creating good indexes is to understand what indexes are and how SQL Server uses them to evaluate queries.
In the previous article I looked at the very basics of what indexes are, what types exist in SQL and how they’re used. In this article I’m going to take a closer look at clustered indexes, what makes them different from nonclustered indexes, how SQL uses clustered indexes and some of the recommendations for selecting the clustered index key.
What is a clustered index?
A clustered index is an index where the leaf level of the index contains the actual data rows of the table. Like any other index, a clustered index is defined on one or more columns – the index key. The key columns for a clustered index are often referred to as the clustering key.
The clustered index can be looked at as a balanced tree (b-tree) structure built on top of a table, with the rows in the table stored logically in the order of the clustering key (see figure 1). The clustered index essentially is the table and hence there cannot be more than one on a table.
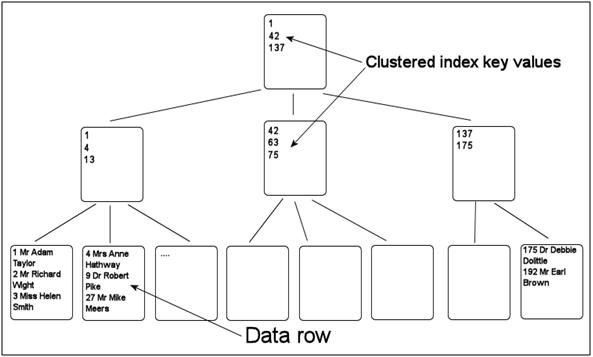
Figure 1: Architecture of a clustered index
The clustering key is, in some ways, the ‘address’ of a data row. It can be used, through the tree structure of the clustered index, to locate a row of data. Because it is used to locate a data row, the clustering key must be unique. If, when the clustered index is created it is defined as unique (either by specifying the UNIQUE keyword as part of the create index statement or by defining the clustered index as part of a primary key or unique constraint), then everything is fine. What if the clustered index is not defined as unique? In that case, SQL automatically adds another column to the index, a 4-byte integer column that’s called the Uniquifier. This column is hidden, it is not displayed in the table design and it cannot be queried directly.
Difference between a clustered index and a heap
A table that has no clustered index is referred to as a heap. Whereas a clustered index has the data stored logically in the order of the index key, a heap has no ordering of rows or pages.
When a row is added to a table with a clustered index, that row has a defined page that it must go on to, according to the value of the clustered index key. Using the index depicted in Figure 1 as an example, if a new row is added with a value of 4 for the clustered index key, that row must go onto the second leaf page. If that page is full, a new page gets allocated, joined into the index and some of the rows from the full page are moved to the new one. This is called a page split, it can be an expensive operation and it leads to fragmentation.
When a row is added to a table without a clustered index (a heap) there’s no specific place that the row has to go. A heap has no defined order. The row will be added wherever there’s a space large enough to put the row.
How a clustered index is used
There are three ways that a clustered index can be used by a query to locate – seek, scan and lookup.
Seek
For the clustered index to be used in a seek operation, the query must contain a SARGable1 predicate based on the clustering key or part of the clustering key.
A simple example of a clustered index seek is as follows (based on the AdventureWorks database)
SELECT ProductID, ProductNumber, Name FROM Production.Product WHERE ProductID = 380
ProductID is the clustering key for the table Production.Product and the filter on ProductID is SARGable.

(1) SARGable is a made-up word, constructed from the phrase Search ARGument. It refers to a predicate that is of a form that SQL can use for an index seek. For more details see: http://www.sql-server-performance.com/tips/t_sql_where_p2.aspx
Scan
A scan of the clustered index is equivalent to a table scan. It’s a read of all of the data pages in the table
Because the clustered index is the table it can be seen as the default access path for queries to get data to retrieve rows. If a query does not have a SARGable predicate1 based on the clustering key and there are no non-clustered indexes which are appropriate for a query (and what makes a non-clustered index appropriate will be discussed in detail in part 3), then a scan of the clustered index will be done to retrieve the data for the query. This is a full scan of all the data pages, i.e. a table scan.
In this example a clustered index scan is done because there are no indexes on either of the columns in the where clause.
SELECT ProductID, ProductNumber, Name FROM Production.Product WHEREColor = 'Blue' AND DaysToManufacture BETWEEN 2 AND 4

SARGable is a made-up word, constructed from the phrase Search ARGument. It refers to a predicate that is of a form that SQL can use for an index seek. For more details see: http://www.sql-server-performance.com/tips/t_sql_where_p2.aspx
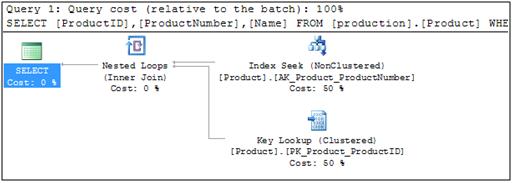
Lookups
A lookup occurs when a nonclustered index was used to locate rows for a query, but the nonclustered index did not contain all of the columns required for the query. To fetch the remaining columns, a lookup is done to the clustered index.
A lookup is equivalent to a single row clustered index seek. Lookups are always done one row at a time. For this reason, they are very expensive operations, especially when lots of rows are involved.
SELECT ProductID, ProductNumber, Name
FROM production.Product
WHERE ProductNumber = 'HN-1224'
Considerations for selecting the clustering key
There are two main schools of thought in what makes a good clustering. One school says to put the clustered index on the column or set of columns that would be most useful for queries, either frequently run queries or ones doing queries of large ranges of data. The other school says to use the clustered index primarily to organise the table and leave data access to the nonclustered indexes.
I hold to the second school, so the rest of this article will be written from that perspective.
There are four main attributes that are desirable for a clustering key. The clustering key should be:
- Narrow
- Unique
- Unchanging
- Ever increasing
Narrow
The width of the clustering key affects the depth of the clustered index and hence it’s efficiency. A clustered index with a very deep b-tree requires queries to read more intermediate pages to locate rows. This increased page reads makes deeper clustered indexes less efficient for data access, especially for lookups. Additionally, more pages means more space used on disk and more space used in memory when the index is in the data cache
The width of the clustering key does not, however, only affect the clustered index. The clustering key, being the rows’ address, is located in every single nonclustered index. Hence a wide clustering key increases the size of all nonclustered indexes, reducing their efficiency as well.
Unique
The clustered index has to be unique. It’s used as the address for a row. If the clustered index is not defined as unique, SQL makes it unique by adding a hidden 4 byte integer column. This makes the index wider than it needs to be and makes the nonclustered indexes wider than they should be.
This attribute needs to be considered in relation to the others. If making the cluster unique requires adding several wide columns then it may be better to keep the index narrower and leave it as not unique.
Unchanging
The clustering key defines where a row is found, which page it is in. If the value of the clustering key is changed, the row must be moved from the page where it currently is to a new location. This means that the update is essentially a delete-insert combination.
Ever-increasing
An ever-increasing column is one where every value inserted is higher than all values currently in the table. This is important for a clustered index as, if inserts occurred all over the table, there would be a high number of page splits and the index would become rapidly fragmented.
Since the clustered index is the largest index on a table (as it contains the entire data row) and because it tends to be used for scans more than other indexes, the clustered index is the one that is affected the most when fragmented and the one that, generally, is the most expensive to rebuild.
For this reason, an ever-increasing clustering key is usually a good choice, especially for tables that are subject to frequent inserts.
In the third and final part of this series I’ll be looking into nonclustered indexes including how SQL uses then and how to select the index columns for various forms of queries.
The Series
Be sure you read all parts of this series:


