

Good indexes are the key to good performance in SQL Server and the key to creating good indexes is to understand what indexes are and how SQL Server uses them to evaluate queries.
In the previous two articles I looked at the very basics of what indexes are, what types exist in SQL and how they’re used and then took a closer look at the clustered index.
In this article I’m going to take a closer look at nonclustered indexes, how SQL uses nonclustered indexes and some of the recommendations for selecting useful nonclustered indexes.
What is a nonclustered index?
A nonclustered index is the second type of index in SQL Server. They have the same b-tree structure as the clustered index (see previous article). Unlike the clustered index nonclustered indexes does not contain the entire data row at the leaf level. Rather, the nonclustered index contains just the columns defined in the index, and a pointer to the actual data row. See figure 1 for a high-level architecture. Assume that the nonclustered index depicted there is based off the clustered index depicted in the previous part.
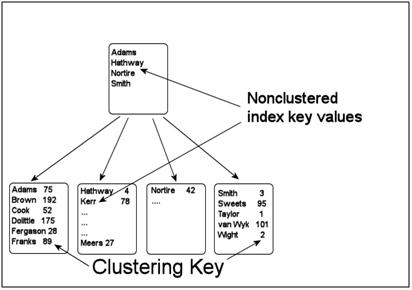
Figure 1: Nonclustered index structure
When the underlying table is a heap (has no clustered index) then the pointer to the data row is the RID, an 8 byte structure comprised of the File ID, Page No and Slot index, i.e. the actual location of the row within the data file.
When the underlying table has a clustered index, the pointer to the actual data row is the clustering key. As mentioned in the previous article, this has important considerations for the selection of a clustering key.
There can be multiple nonclustered indexes on a table. In SQL 2005 and earlier, there was a limit of 249 nonclustered index per table. In SQL 2008, with the introduction of filtered indexes, the limit on indexes has been increased to 999.
Include columns
Columns specified as include columns are stored at the leaf level of the nonclustered index, but not at the intermediate or root levels. They are not part of the index key and do not count towards the 16 column/900 byte limit on indexes. Any data type other than the old LOB types (TEXT, NTEXT, IMAGE) are allowed for include columns, although columns defined as varbinary(MAX) Filestream are not permitted as include columns. The ability to specify include columns was added in SQL 2005.
Include columns are useful in that they are columns available in the index but not contributing to the size of the index key hence they make it easier to create covering indexes (see next section) than could be done without them.
Typically columns that appear only in the select clause of a query and not within the WHERE, FROM or GROUP BY are candidates for INCLUDE columns.
If LOB columns are specified as include columns, the entire contents of the LOB columns are duplicated. It’s not just a pointer to the existing LOB pages added to the nonclustered index.
The ability to specify include columns was added in SQL 2005.
Covering indexes
Covering is not a property of an index, it is not possible to say, without additional information that a query is covering or not covering. Instead, covering deals with an index and a query together.
An index is said to be covering for a specific query if that index contains within it all of the columns necessary for the query. The columns may be part of the key or they may be include columns. This means that a query that has a covering index can be evaluated completely from that index, without needing to go to the base table (heap or cluster) to fetch additional columns.
It has been said before that creating a covering index for a query is just about the best way to speed a query up. This is true. It is not always possible or desirable to cover every query. Covering every query may lead to unacceptably large indexes or unacceptably large numbers of indexes with all the attendant problems (as mentioned in part 1)
It is possible (and often desirable) for an index to be covering for more than one query.
Filtered indexes
Filtered indexes are a new feature in SQL 2008 and they allow for an index to contain only some of the rows in the table. Prior to this, an index would always have, at the leaf level, the same number of rows as the table. With filtered indexes, an index can be based on just a subset of the rows.
When creating a filtered index, a predicate is specified as part of the index creation statement. There are several limitations on this predicate. The comparison cannot reference a computed column, a column that is declared as a user-defined type, a spatial column or a hierarchyid column.
A clustered index cannot be filtered as it is the actual table.
How a nonclustered index is used
Seek
For SQL to do a seek on a nonclustered index, the query must have a SARGable1 predicate referencing the index key or a left-based subset of the index key. In addition to this, the index must be either covering or return sufficiently small number of rows that the required lookups to the clustered index/heap (to retrieve the remainder of the columns) is not considered too expensive by the optimiser. If the required lookups are considered too expensive then the index will not be used.
It usually works out that the number of rows where the optimiser decides that key/RID lookups are too expensive is somewhere around 0.5%-1% of the total rows in the table.
(1) - SARGable is a made-up word, constructed from the phrase Search ARGument. It refers to a predicate that is of a form that SQL can use for an index seek. For more details see: http://www.sql-server-performance.com/tips/t_sql_where_p2.aspx
Scan
An index scan is a read of all of the leaf pages in the nonclustered index. A scan of a nonclustered index is generally more efficient than a scan of the clustered index, because nonclustered indexes are generally smaller.
A nonclustered index scan usually indicates that the index contains all the columns required by the query but they are in the wrong order, the query predicates are not SARGable or there are no query predicates.
Update
When a change is made to a column that is either a key column or an include column of a nonclustered index, that index will be modified as part of the insert statement. Indexes are never left out of sync with the underlying table data.
Inserts and deletes will affect all nonclustered indexes on a table.
Considerations for selecting nonclustered indexes
The decision as to what columns should be indexed should be based on the queries that are run against the table. There’s no point in indexing a column that is never used in a query.
Selectivity
In general, a nonclustered index should be selective. That is, the values in the column should be fairly unique and queries that filter on it should return small portions of the table.
The reason for this is that key/RID lookups are expensive operations and if a nonclustered index is to be used to evaluate a query it needs to be covering or sufficiently selective that the costs of the lookups aren’t deemed to be too high.
If SQL considers the index (or the subset of the index keys that the query would be seeking on) insufficiently selective then it is very likely that the index will be ignored and the query executed as a clustered index (table) scan.
It is important to note that this does not just apply to the leading column. There are scenarios where a very unselective column can be used as the leading column, with the other columns in the index making it selective enough to be used.
Single column vs. Multi-column indexes
In general, wider nonclustered indexes are more useful than single column nonclustered indexes. This is because it is very unusual for SQL to use multiple nonclustered indexes on the same table to evaluate a query. An index defined over more than one column is referred to as a composite index.
Consider a hypothetical table (Table1) that has three indexes on it, one on Col1, one on Col2 and one on Col3. If a query with predicates on all three of those columns is executed against that table, SQL might seek on all three indexes and intersect the results, it might seek on two, intersect the results and do lookups for the column needed for the last filter and apply that filter, it might seek on one, do lookups for the other two columns and then filter them, it might just scan the cluster/heap. All of these ae possible options, but they are not the most optimal option.
If there was a single index defined with all three columns, the matching rows could be located as a single seek operation.
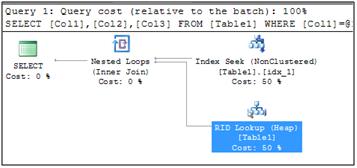
Figure 2: Three separate indexes
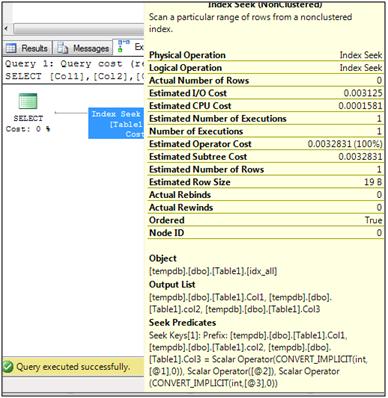
Figure 3: One composite index
For a more details analysis of single vs composite indexes see http://sqlinthewild.co.za/index.php/2010/09/14/one-wide-index-or-multiple-narrow-indexes/
Column order
The order of the columns in an index key should be chosen based on several factors: the selectivity of the columns, what % of queries will filter on that column and whether the queries will filter with equality or inequality matches.
If the query predicate is based on multiple columns and there is an index where the combination of columns forms a left-based subset of the index key, then retrieving the rows is a single seek operation. If the query predicate is based on multiple columns and there is an index that contains those columns as part of the index key, but they do not all form a left-based subset of the index key, then retrieving those rows is a 2-step process; seek on the columns that do form a left-based subset and then filter out rows that don’t match the other conditions.
Let’s look at a quick example.
Imagine we have a hypothetical table named Table1 and that there is an index on that table with the index key consisting of three columns – Col1, Col2 and Col3.
CREATE INDEX idx_Table1_Demo
ON Table1 (Col1, Col2, Col3)
Let’s say further that there are two queries against that table.
SELECT Col1 FROM Table1 WHERE Col1 = @Var1 AND Col2 = @Var2
This query can be evaluated by a single seek operation against the two columns.
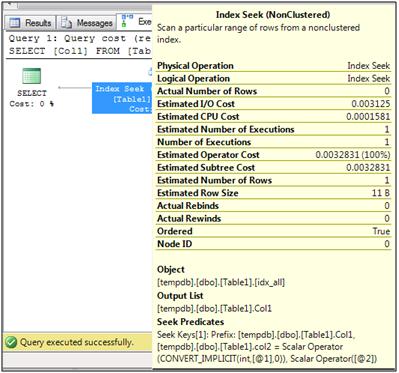
SELECT Col1 FROM Table1 WHERE Col1 = @Var1 AND Col3 = @Var3
This query cannot be evaluated by a single seek operation against the two columns. Rather it has to be done as a seek just on one column, Col1, and the rows that are returned from that seek get checked to see if they match the second predicate or not.
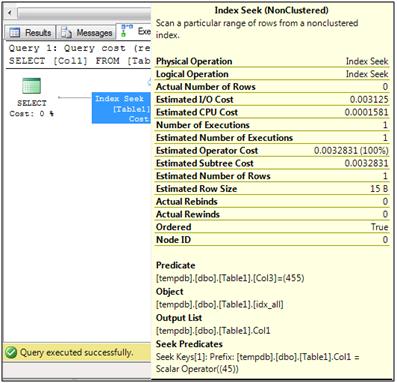
The other thing that has to be considered is the type of predicates that the queries will be using.
It is often said that the most selective column should be made the leading column of an index. This is true, but must be considered in light of the other factors. There is little point in making a column the leading column of an index if only 5% of the queries that use that index filter on that column. It would mean that only those queries could seek on the index and the other 95% would either scan or use a different index (if one existed)
In conclusion
This concludes the introductory coverage of indexes. I hope that this has been of use to people. For further and deeper information there are a few posts on my blog, also see the Inside SQL Server 2005 books, specifically the 1st book (The Storage Engine) and the 4th book (Query tuning and optimisation) and SQL Server 2008 Query Performing Distilled.
The Series
Be sure you read all parts of this series:


