

Good indexes are the key to good performance in SQL Server and the key to creating good indexes is to understand what indexes are and how SQL Server uses them to evaluate queries.
In this first part of a three part series, I’m going to look at the very basics of what indexes are, what types exist in SQL and how they’re used.
What is an index?
An index is a structure within SQL that is used to quickly locate specific rows within a table. It can be useful to imaging an index at the back of a textbook when thinking about SQL indexes. They both serve the same purpose – to find specific information quickly.
General Structure
An index is defined on one or more columns, called key columns. The key columns (also referred to as the index key) can be likened to the terms listed in a book index. They are the values that the index will be used to search for. As with the index found at the back of a text book (see figure 1), the index is sorted by the key columns.

Figure 1: Book index. Image copyright Simple Talk publishing.
If an index is created with more than one key column, it is known as a composite index.
The general structure of an index is that of a balanced tree (b-tree). The index will have a single root page, zero or more intermediate levels and then a leaf level. A page is an 8 kilobyte chunk of the data file, with a header and footer and is identified by a combination of File ID and Page number.
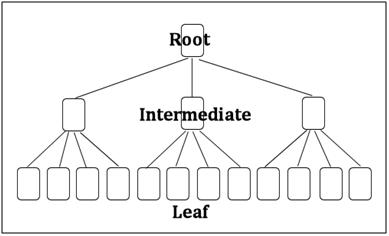
Figure 2: Index Structure |
Note: Commonly the root page is shown at the top of the tree diagram and the leaf pages at the bottom. Think of it as an inverted tree.
In the leaf level, there’s one entry for each row in the index1. The entries in the index are ordered logically2 in the order of the index key.
The non-leaf levels of the index contain one row per page of the level below, referencing the lowest index key value on each page. If all of those rows fit onto a single page, then that page is considered the root and the index is only two levels deep. If all of those rows will not fit on a single page, then one (or more) intermediate levels are added to the index.
The number of levels in an index is referred to as the depth of the index. This is an important consideration for evaluating the efficiency of the index. The index illustrated in figure 2 has a depth of 3.
(1) With the exception of SQL 2008’s filtered indexes, an index will have the same number of rows at the leaf level as the table.
(2) I’m using the phrase ‘logically ordered’ because the index does not necessarily define the physical storage of the rows. The rows are stored in a way that SQL can retrieve them ordered.
Clustered and nonclustered
There are two main types of indexes in SQL Server, the clustered index and the nonclustered index
Clustered indexes define the logical order of the table. The leaf level of the clustered index has the actual data pages of the table. Because of this there can only be one clustered index per table. A table that does not have a clustered index is referred to as a heap.
Nonclustered indexes are separate from the table. The leaf level of a nonclustered index has a pointer as part of each index row. That pointer is either the clustered index key in the cases where the base table has a clustered index or the RID (Row Identifier) in the cases where the table is a heap. The RID is an 8-byte structure comprised of File ID, Page Number and Slot Index and will uniquely identify a row in the underlying heap. Either way, the each row of a nonclustered index has a reference to the complete data row.
Index Limits
There are a number of built-in limitations on indexes
Key size
The size of an index key is limited to a maximum of 900 bytes and a maximum of 16 columns. This is definitely a limit, not a goal, as the larger the index key gets, the more pages in the index and the deeper the index tree. As the number of pages and the depth of the tree increases so the index becomes less efficient to use. Larger indexes also use more storage space and result in less efficient use of SQL’s data cache.
Number of indexes
In SQL 2005 and earlier there was a limitation of 250 indexes per table, one clustered and 249 non-clustered. In SQL 2008, with the addition of filtered indexes, that limitation was increased to 1000, one clustered and 999 non-clustered indexes.
Both of these limits are very high and there are few circumstances where a well-designed system should approach that limit.
The reason for this is twofold.
· As the number of indexes increases so the total size occupied by the table (with all of its indexes) increases. Sure, hard drives are cheap and storage is abundant but increasing the size of a database has other effects, Maintenance operations (backups, restores, consistency checks and index rebuilds) all take longer as the size of a database increases.
· Indexes have to be kept up to date as data changes and the more indexes there are on a table, the more places the data has to be changed. If there are 10 nonclustered indexes on a table, an insert must be done in 11 places (the table and each of those nonclustered indexes). On databases that are mostly read-only (decision support, data warehouses) that may be acceptable. On databases that have frequent inserts, updates and deletes (OLTP systems), the overhead impose by multiple indexes may not be acceptable
How SQL uses indexes
If a table does not have index, the only way to find all occurrences of a value within a table is to read the entire table. If a table has an index, it speeds up the locating of values within that index in two ways.
1. The index is sorted in the order of the key columns. This means that once all the matching values have been found, the remaining portion of the table can be ignored. This is the same as a telephone directory, where once all entries with a particular surname have been found, the rest of the book can be ignored as no further matches are possible
2. The tree structure of the index allows a divide-and-conquer approach to locating rows, where large portions of the table can be quickly excluded from the search. This is illustrated in Figure 3
There are four basic operations that SQL can do on an index. It can scan the index, it can seek on the index, it can do lookups to the index and it can update the index
Scans
An index scan is a complete read of all of the leaf pages in the index. When an index scan is done on the clustered index, it’s a table scan in all but name.
When an index scan is done by the query processor, it is always a full read of all of the leaf pages in the index, regardless of whether all of the rows are returned. It is never a partial scan.
A scan does not only involve reading the leaf levels of the index, the higher level pages are also read as part of the index scan.
Seeks
An index seek is an operation where SQL uses the b-tree structure to locate either a specific value or the beginning of a range of value. For an index seek to be possible, there must be a SARGable3 predicate specified in the query and a matching (or partially matching) index. A matching index is one where the query predicate used a left-based subset of the index columns. This will be examined in much greater detail in a part 3 of this series.
The seek operation is evaluated starting at the root page. Using the rows in the root page, the query processor will locate which page in the next lower level of the index contains the 1st row that is being searched for. It will then read that page. If that is the leaf level of the index, the seek ends there. If it is not the leaf then the query processor again identifies which page in the next lower level contains the specified value. This process continues until the leaf level is reached.
Once the query processor has located the leaf page containing either the specified key value or the beginning of the specified range of key values then it reads along the leaf pages until all rows that match the predicate have been returned. Figure 2 shows how a seek would be done on an index when searching for the value 4.
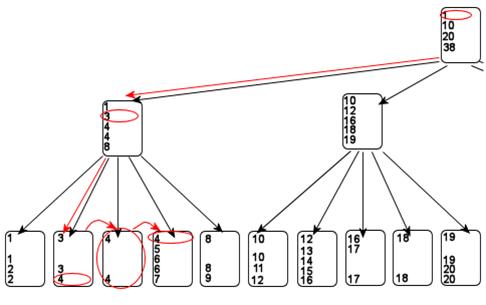
If the index contains all the columns that the query needs, then the index is said to be covering for that query. If the index does not contain all the columns then SQL will do a lookup to the base table to fetch the other columns in order to process the query.
(3) SARGable is a made-up word, constructed from the phrase Search ARGument. It refers to a predicate that is of a form that SQL can use for an index seek. For more details see: http://www.sql-server-performance.com/t-sql-where/2/
Lookups
Lookups occur when SQL uses an index to locate rows affected by a query but that index does not contain all the columns required to satisfy the query, that is the index is not covering for that query. To fetch the remaining columns, SQL does a lookup to either the clustered index or heap.
A lookup to a clustered index is essentially a single row clustered index seek and it is always a single row seek. So if a lookup is needed for 500 rows, that involves 500 individual clustered index seeks.
Updates
Anytime that a row is changed, those changes must be made not only in the base table (clustered index or heap) but also in any index that contains the columns that were affected by the change. This applies to insert, update and delete operations.
Considerations for creating indexes
I’ll be going into more detail on considerations for indexes in the next two parts, but in general:
- Clustered index should be narrow, because the clustering key is part of all nonclustered indexes.
- Composite nonclustered indexes are generally more useful than single column indexes, unless all queries against the table filter on one column at a time.
- Indexes should be no wider than they have to be. Too many columns wastes space and increases the amount of places that data must be changed when an insert/update/delete occurs.
- If an index is unique, specify that it is unique. The optimiser can sometimes use that information to generate more optimal execution plans.
- Be careful of creating lots of indexes on frequently modified tables as it can slow down data modifications.
In part 2 of this series I’ll be looking in more detail into clustered indexes. What they are, how they differ from nonclustered indexes and what the considerations are for creating a clustered index.
The Series
Be sure you read all parts of this series:

