

"SQL Spackle" is a collection of short articles written based on multiple requests for similar code. These short articles are NOT meant to be complete solutions. Rather, they are meant to "fill in the cracks".
--Phil McCracken
You may recall that in an earlier article published by SSC, How to Design, Build and Test a Dynamic Search Stored Procedure, that one of the requirements was to do a LIKE “%string%” search on one of the character string columns of my table. Coincidentally this same requirement came up yet again during some new modifications that we’re making to that application. It got me to thinking about whether the query I was constructing performed the best that it could, given that both of these tables have the potential to become quite large.
Prevailing wisdom suggests that the best you can expect out of a LIKE “%string%” filter such as mine is an INDEX SCAN. And let’s face it; I am a studious follower of best practice, which I believed I was using in my prior article (and mostly I still believe I was). I am also a great believer in “know your data.” Mind you, I’m not just talking about the structure, but also the often intriguing patterns of data that resides in those tables.
So naturally I set about to analyzing the data contained in my column of interest. As it turns out, in my production system’s table, the data is quite sparse consisting of about 20% string values that need to be searched by the filter and 80% NULLs.
This article is about how to add a LIKE “%string%” filter when you have sparse data in the column of interest. The sparseness of my data got me to wondering if I could exclude the 80% NULL values from the rows I was searching.
Test Data
Any good-performing solution requires a bunch of test data, so let’s set up a table and some data that we can work with.
DECLARE @Rows INT = 10000000; -- Ten million rows
CREATE TABLE dbo.StringsTest
(
ID INT IDENTITY PRIMARY KEY
,AString VARCHAR(20) NULL
);
WITH Tally (n) AS
(
SELECT TOP (@Rows) ROW_NUMBER() OVER (ORDER BY (SELECT NULL))
FROM sys.all_columns a CROSS JOIN sys.all_columns b
)
INSERT INTO dbo.StringsTest
SELECT CASE
-- n%10 = 0 = 10% of strings are not NULL
WHEN n%10 = 0
THEN SUBSTRING('ABCDEFGHIJKLMNOPQRSTUVWXYZ', 1+ABS(CHECKSUM(NEWID()))%26, 1) +
SUBSTRING('ABCDEFGHIJKLMNOPQRSTUVWXYZ', 1+ABS(CHECKSUM(NEWID()))%26, 1) +
SUBSTRING('ABCDEFGHIJKLMNOPQRSTUVWXYZ', 1+ABS(CHECKSUM(NEWID()))%26, 1) +
CAST(n%(@Rows/2) AS VARCHAR(10)) +
SUBSTRING('ABCDEFGHIJKLMNOPQRSTUVWXYZ', 1+ABS(CHECKSUM(NEWID()))%26, 1) +
SUBSTRING('ABCDEFGHIJKLMNOPQRSTUVWXYZ', 1+ABS(CHECKSUM(NEWID()))%26, 1) +
SUBSTRING('ABCDEFGHIJKLMNOPQRSTUVWXYZ', 1+ABS(CHECKSUM(NEWID()))%26, 1)
END
FROM Tally;
SELECT [NullCount]=COUNT(CASE WHEN AString IS NULL THEN 1 END)
,[NonNullCount]=COUNT(CASE WHEN AString IS NOT NULL THEN 1 END)
FROM dbo.StringsTest;In this test harness, we’ve created ten million rows with about 10% of those rows (1,000,000) containing about 500,000 unique character strings. Our assumption here is that the column of interest is not a part of the PRIMARY KEY of the table, because in the real world such searches are usually performed on columns of freeform text entry.
The final SELECT confirms our sparseness ratio (NullCount=9,000,000, NonNullCount=1,000,000).
The Benchmark
Our benchmark query (below) is pretty simple and standard. The timing result was obtained from a sister query which is identical except that it shunts the display results to a local variable to eliminate any biasing of the elapsed time caused by rendering the results to the SQL Server Management Studio (SSMS) results pane. In fact, each query was run twice, with results recorded for the second run, so as to give SQL the opportunity to cache an efficient execution plan. This same tactic will be applied to all the timing results we will record as we go along.
SELECT AString FROM dbo.StringsTest WHERE AString LIKE '%221%'; Traditional Solution - no INDEX (4998 row(s) affected) SQL Server Execution Times: CPU time = 1795 ms, elapsed time = 474 ms.
This query has a pretty undistinguished Actual Execution Plan as depicted below. Indeed the expectation that an INDEX SCAN (in this case, of the CLUSTERED INDEX) will be used to deliver the query results is achieved.

Indexing
Because we know that SQL Server ignores NULL values when it constructs an INDEX, our first thought is that perhaps an INDEX on the column of interest might help, so we’ll add one.
CREATE INDEX s_ix1 ON dbo.StringsTest (AString);
The new timing results (remember that our data contains only 10% non-NULL values) now show this:
Traditional Solution - with INDEX (4998 row(s) affected) SQL Server Execution Times: CPU time = 1747 ms, elapsed time = 513 ms.
It is rather disappointing that our attempt at INDEXing has fallen short of improving the query’s elapsed time performance. In fact, it appears to be a little worse, even though CPU is slightly improved.
A Little Trial and Error
Resting not on my laurels nor relying on dogma to guide me, I set about pursuing alternate forms of the query that might somehow, miraculously manage to ignore the large numbers of NULL rows in my column. I came up with about a half a dozen alternative forms, including one that gave me two INDEX SEEKs instead of the INDEX SCAN. Unfortunately, that one proved to be quite worthless because it was significantly slower than my benchmark. What I was really thinking I might find was a case where not all INDEX SCANs are created equal (and that my variant might be a little bit better).
Instead what I stumbled upon was this:
WITH Strings AS
(
SELECT ID, AString
FROM dbo.StringsTest
WHERE AString IS NOT NULL
)
SELECT AString
FROM Strings
WHERE AString LIKE '%221%';This appears to be a rather unremarkable and somewhat absurd refactoring of the original query, but you can see in it the thought path I was taking to eliminate the NULL rows before filtering. All of the queries I tried had that much in common. I sought a way to fool the Optimizer into ignoring those rows with NULLs, and it was surprisingly hard to do so even after multiple attempts.
If I’ve learned anything since I began my study of SQL it is that Common Table Expressions (CTEs) can be expected to neither improve the performance of a query, nor detract from it. It is likely that similar results would be obtained by putting the CTE query into a derived table. Yet, the timings I got from this query were:
Alternate Solution - with INDEX (4998 row(s) affected) SQL Server Execution Times: CPU time = 296 ms, elapsed time = 296 ms.
Holy moldy ravioli! Just look at that CPU time! The elapsed time appears much improved also. Perhaps this is not such an absurd refactoring after all! It seems to work well when there are only 10% non-NULL values, but will it also work well with data that is not quite so sparse?
Let’s take a quick look at the Actual Execution Plans (at 10% non-NULL values) for the traditional and alternate approach.

The first (traditional solution) as expected does a NONCLUSTERED INDEX SCAN, but somehow we’ve managed to force the Optimizer to do an NONCLUSTERED INDEX SEEK for the alternate solution. I don’t really want to think about what the traditional query’s elapsed time would have been if not for that Parallelism operator in the plan.
Since everything I've been led to believe up until now (case in point is this article from Brent Ozar:Sargability: Why %string% Is Slow) is that you can't force a seek on this type of a query, it leads me to believe there's something new here. I'm not sayting the experts are wrong or anything, just that I think I'd be aware of this opportunity had it been heavily written about before. In the worst case, the query must be doing a seek for every non-NULL row.
Running it Through Its Paces
Since my real data consists of 20% non-NULL values, I need to see how well it does with that and while I’m at it I might as well run the gamut all the way up to 100% fully populated (no NULLs) because I’d expect there to be some overhead for the last case.
Let’s construct a query we can apply to our test data that will bump the actual data content (decrease the sparseness) by 10% at a time.
DROP INDEX s_ix1 ON dbo.StringsTest;
DECLARE @Rows INT = 10000000;
-- To add another 10% of the strings
UPDATE dbo.StringsTest
SET AString = SUBSTRING('ABCDEFGHIJKLMNOPQRSTUVWXYZ', 1+ABS(CHECKSUM(NEWID()))%26, 1) +
SUBSTRING('ABCDEFGHIJKLMNOPQRSTUVWXYZ', 1+ABS(CHECKSUM(NEWID()))%26, 1) +
SUBSTRING('ABCDEFGHIJKLMNOPQRSTUVWXYZ', 1+ABS(CHECKSUM(NEWID()))%26, 1) +
CAST(ID%(@Rows/2) AS VARCHAR(10)) +
SUBSTRING('ABCDEFGHIJKLMNOPQRSTUVWXYZ', 1+ABS(CHECKSUM(NEWID()))%26, 1) +
SUBSTRING('ABCDEFGHIJKLMNOPQRSTUVWXYZ', 1+ABS(CHECKSUM(NEWID()))%26, 1) +
SUBSTRING('ABCDEFGHIJKLMNOPQRSTUVWXYZ', 1+ABS(CHECKSUM(NEWID()))%26, 1)
-- Increment 1 by 1 for each additional 10% you want to add
WHERE ID%10 = 1;
CREATE INDEX s_ix1 ON dbo.StringsTest (AString);
SELECT [NullCount]=COUNT(CASE WHEN AString IS NULL THEN 1 END)
,[NonNullCount]=COUNT(CASE WHEN AString IS NOT NULL THEN 1 END)
FROM dbo.StringsTest;Once again, the final SELECT confirms the resulting sparseness ratio (now NullCount=8,000,000 and NonNullCount=2,000,000). We dropped and recreated the INDEX on each run (9 times, incrementing the =1 as commented), to ensure that our UPDATE didn’t cause lots of INDEX fragmentation that might impact our results. The theory being of course, that you’ll rebuild this INDEX periodically to avoid that impact.
Now we can run our query in sparseness increments of 10% and record the timing results for each run. In each case, we also checked to make sure each query returns the same number of matched rows. The raw results are included in the Excel spreadsheet we’ve attached in the resources section of this article, but graphically they look like this.
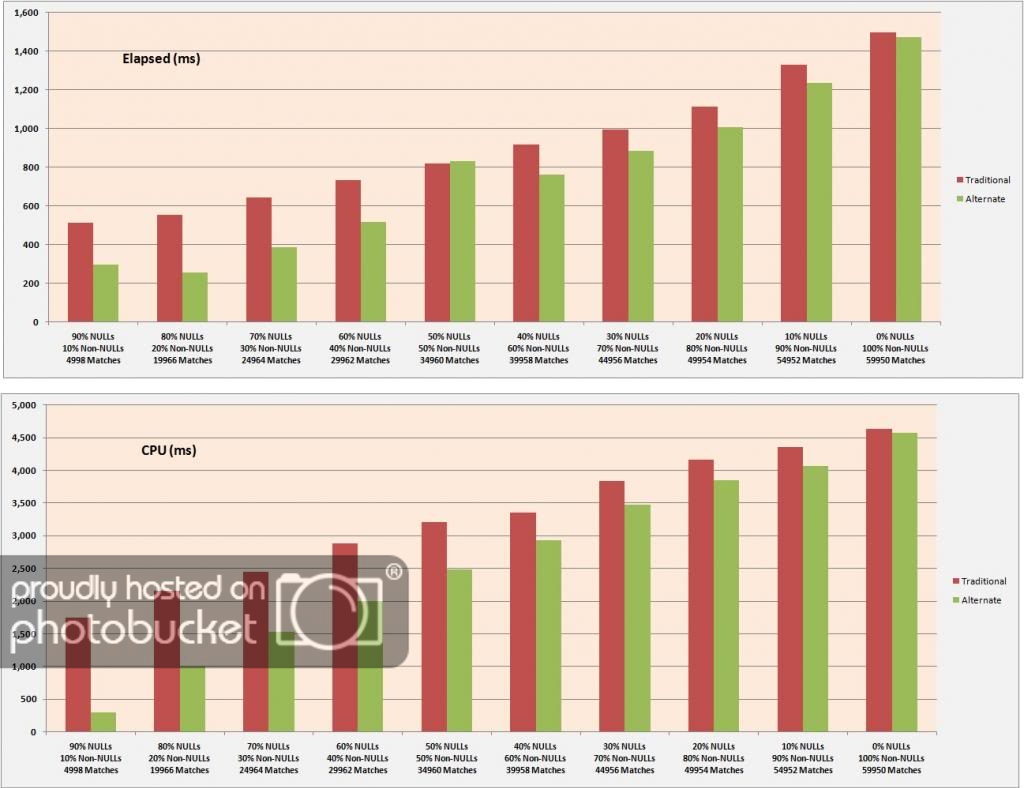
Summary and Conclusions
The results apparently indicate that my alternate solution to the LIKE “%string%” filtering query seems to produce pretty decent results regardless of the sparseness of the data. In fact, I was quite surprised at the results obtained with 0% NULL values in the data, thinking that they might be worse at that point because of the additional overhead of the rows reduction done in the CTE.
Overall, the query cost (either elapsed time or CPU) seems to scale roughly linearly upwards (although there is an anomaly at 50%-50%), depending on either the sparseness decreasing or the number of matching rows returned increasing, or quite possibly both. You’d probably need to consider both if you choose to use this code pattern. While I did not record logical reads during my testing across all NULL ratios, I think you’ll find that they’re also improved (they certainly are for the 90% NULLs case).
Note that without the INDEX, the alternate form doesn’t do diddley for you because it is no better than the traditional one. I suspect without actually having tested it that putting the column of interest into an INCLUDE for the INDEX would not achieve the desired effect either. I also played around with adding a binary collation on the filter (COLLATE Latin1_General_BIN), and while this did seem to improve my query (but not the other) at the 90% NULLs level, I was hesitant to publish the results because the downside is of course that it will no longer preserve case insensitive matching.
*** Disclaimer ***
The results in this article were obtained on MS SQL Server 2008 R2. Timings and execution plans obtained on other versions of SQL Server may differ.
No doubt there will be pundits amongst the SQLverse, so let’s try to anticipate some of their objections and address those now:
"I can’t INDEX every character string column on which I need to do a LIKE “%string%” search because my database will grow too huge, as most of them are VARCHAR(8000)."
Response: Indeed, you’ll be paying a price in storage by having these INDEXes (as you do for any other) and a performance penalty in keeping them maintained during INSERTs, UPDATEs, DELETEs and MERGEs. In my case, the column of interest is a mere NVARCHAR(50), so I can probably live with that amount of storage overhead. Perhaps it would be prudent to review whether VARCHAR(8000) data types are really necessary.
It may also be possible to use a Filtered Index on NOT NULL to reduce storage and/or further improve execution time, but I have not tested that (yet).
All of the tables where I need to do a LIKE “%string%” search contain complex, composite PRIMARY KEYs so getting the alternate query form to work as advertised might be difficult.
Response: Indeed I will face this same challenge in my application, but I’m pretty confident that I can overcome it. You can see some preliminary research I did towards this end in my blog: Getting an INDEX SEEK to Speed up LIKE “%string%” Searches. Note that in this article I added the NOT NULL filter in a CTE to set that code off, but the blog shows a possibly simpler way it can be done.
This all seems pretty complicated for a marginal improvement in query speed. How is someone coming along after me going to know why I did this?
Response: I would say that it isn’t particularly complicated at all, but I guess it depends on your level of expertise with SQL. Developing a test harness similar to your real world case should be relatively easy to do. The improvement in speed is certainly less marginal when your data is increasingly sparse. And as to the second question, the answer is simply: add a comment.
How can I tell if the extra effort I’m going to have to put into this warrants the improvement in performance I can expect to obtain?
Response: This is a difficult one to answer. The effort is going to depend on how quickly you can demonstrate the alternate query form’s performance characteristic. Perhaps the best answer is that you certainly won’t ever really know unless you try.
Ultimately the results I obtained from the alternate LIKE “%string%” search code pattern is a result of one thing I like to tell developers that ask how to improve a query’s performance.
“Your query should only touch the rows it needs to touch and it should try to touch those rows only once. If it can touch only the entry in an index, instead of the row, that is even better.”
-- From my blog: “Make it Work, Make it Fast, Make it Pretty”
Finally, I'd like to thank Chris Morris for helping me do some background research on this after the fact. The links he sent me helped explain things more clearly.
I hope that this bit of SQL Spackle has filled a crack! Until next time folks.
Dwain Camps
SQL Enthusiast and Occasional Slayer of Sacred Cows
Follow me on Twitter: @DwainCSQL
© Copyright Dwain Camps 2014 All Rights Reserved