

Problem
While working with one of my Risk Advisory clients, I came upon an issue of duplicate records reported from an application user. This user noticed the problem on one of the critical reports that is sent out to the higher management group on weekly basis. Finding a duplicity of data questions the whole application and its data accuracy. As it is a risk advisory client, this can have a huge impact on compliance. The client brand value may also be at stake.
Duplicates means that the same record is seen multiple times in a SQL Server database table. I am sure each developer would have faced such an issue in their work experience. Why do such cases occur? I believe, there are the two major reasons for the duplicity of data. These are as follows:
- Validation missing in an application : There are two common scenarios where the duplicate record is created. First and foremost, while submitting a web form, a user may accidently press the submission/send button multiple times. Another reason, is the user opens up multiple instances, as in a web page open in multiple windows. In this case, the same data is submitted via multiple opened windows.
- Poor Database Design: Yes, it can also be possible because of poor database design as the database may not have proper constraints.
Overview
Here I would like to share a detailed analysis of the problem, along with ways to handle and remove row level duplicates. Firstly, I would like to highlight duplicate records with the help of dummy records. Handling duplicate records is always a time-consuming task and can be a bit tricky. It requires proper analysis to understand the data and in writing queries for the deletion of the duplicate records.
Note: I am taking a scenario of a table where the database table has no primary or unique key constraint.
For an example, execute the below set of queries to create a dummy database, create a table, and insert some values in the table. The Insert statements will add dummy data into the table, and the duplicate, Compliance_ID, values are submitted multiple times by the same user for the same Business Unit with the same status.
Create Database Compliance
Go;
create table BusinessUnit_specific_Compliance
(
Compliance_ID varchar(50),
Business_Unit_Name varchar(50),
Submitted_By varchar(50),
Compliance_Status varchar(50),
Time_Stamp DateTime
)
Insert into BusinessUnit_specific_Compliance values ('1001','Malden', 'sp\Luke', 'Completed',getdate())
Insert into BusinessUnit_specific_Compliance values ('1001','Malden', 'sp\Luke', 'Completed',getdate())
Insert into BusinessUnit_specific_Compliance values ('1002','Cambridge', 'sp\Jane', 'Completed',getdate())
Insert into BusinessUnit_specific_Compliance values ('1003','Everet', 'sp\Liam', 'Pending',getdate())
Insert into BusinessUnit_specific_Compliance values ('1002','Cambridge', 'sp\Jane', 'Completed',getdate())
Insert into BusinessUnit_specific_Compliance values ('1002','Cambridge', 'sp\Jane', 'Completed',getdate())If we check the table, the output will look like as follows:
Select * from BusinessUnit_specific_Compliance

Notice that the same compliance records have been submitted by the same user with same status. As explained earlier, this case could occur if 'Submit' button on a web page has been hit multiple times. Now, we can find the duplicates and deal with them.
Using Grouping to Find the IDs
This type of issue needs some SQL queries to fetch the duplicate records for a better analysis of the problem. Using the HAVING and GROUP BY clauses, we will be able to find the duplicate records count. The below SELECT statement works in the following way:
- The GROUP BY clause will group the rows into groups by values in the columns
- The COUNT() function will return the number of occurrences of each group (of all three columns used in the Group By clause)
- The HAVING clause keeps only duplicate groups that occur more than once
SELECT
A.compliance_id
, Business_Unit_Name
, Submitted_By
, COUNT(*) AS Duplicate_Occurence
FROM BusinessUnit_specific_Compliance A
WHERE
compliance_id = compliance_id
AND Business_Unit_Name = Business_Unit_Name
AND Submitted_By = Submitted_By
GROUP BY
compliance_id, Business_Unit_Name, Submitted_By
HAVING COUNT(compliance_id) > 1;The results of this query show two groups of duplicates. Here, Compliance_ID '1001' has 2 duplicate records and Compliance_ID '1002' has 3 duplicate occurrences.

Using Row_Number() function to find duplicate row
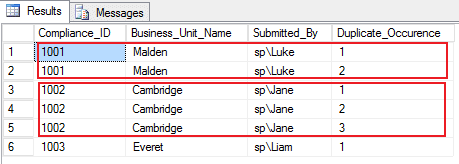
The Row_Number() function will distribute rows of the table BusinessUnit_specific_Compliance into an order inside the values in the columns when we include them in the PARTITION BY phrase. Executing below query will return the duplicate rows with repeated values, but with a different row number for each row in the column, 'Duplicate_Occurence'.
SELECT [Compliance_ID],
[Business_Unit_Name],
[Submitted_By],
ROW_NUMBER() OVER(PARTITION BY [Compliance_ID],
[Business_Unit_Name],
[Submitted_By]
ORDER BY [Compliance_ID]) AS Duplicate_Occurence
FROM [dbo].[BusinessUnit_specific_Compliance]Duplicate rows with unique row numbers for each row as shown below:
Writing a DELETE Query
We can use a CTE (Common Table Expressions) to remove the duplicate rows from a SQL Server table. We can use the query above and Row_Number() inside a CTE and combine this with a delete statement for deleting records where the Duplicate_Occurence is greater than 1. Now, only one record from each group will remain in the table and duplicate rows will be cleaned.
CTE and Row_Number here will be used to handle where there are 2 or more duplicate records in a row.
WITH CTE([Compliance_ID],
[Business_Unit_Name],
[Submitted_By],
Duplicate_Occurence)
AS (SELECT [Compliance_ID],
[Business_Unit_Name],
[Submitted_By],
ROW_NUMBER() OVER(PARTITION BY [Compliance_ID],
[Business_Unit_Name],
[Submitted_By]
ORDER BY [Compliance_ID]) AS Duplicate_Occurence
FROM [dbo].[BusinessUnit_specific_Compliance])
DELETE FROM CTE
WHERE Duplicate_Occurence > 1;
After running this query, a SELECT statement will reflect only unique rows:
Select * from [dbo].[BusinessUnit_specific_Compliance])

Conclusion
Cleaning duplicate records from SQL Server can be a bit tricky and tedious, but it can be easily done with the help of ROW_NUMBER & with CTE.
Note: Do not to implement this directly in a production environment. All code should be tested and verified in another environment.