


Credit: Image generated by Google Bard
Generative AI (GenAI) models like GPT, Gemini, PaLM, DALL-E, and others offer businesses powerful text generation, image creation, and language translation capabilities. These models have the potential to automate tasks, generate creative content, and improve customer experiences.
However, businesses face a unique challenge in capitalizing on GenAI's potential. Language Large Models (LLMs) used in GenAI applications can hallucinate, making their outputs unreliable. The democratization of access to foundation models has also reduced the competitive advantage of proprietary models.
The key to creating differentiated GenAI solutions now lies in the data they are augmented with. High-quality and unique data enables businesses to establish trust in LLMs and achieve superior performance. Data management is crucial for building robust GenAI solutions. Organizations that recognize the pivotal role of data can develop customized solutions that meet their unique needs and set them apart from competitors.
This article explores the essential role of data management in scaling GenAI solutions. Specifically, it discusses the importance of data management, governance, and best practices for leveraging these models' transformative power.
Understanding Generative AI and Embeddings
In the realm of Artificial Intelligence (AI), Retrieval Augmented Generation (RAG) has emerged as a transformative paradigm. At its essence, RAG empowers AI systems to go beyond the static knowledge encoded in their model parameters during training. By integrating the ability to dynamically retrieve and incorporate information from external knowledge sources (like databases, document repositories, or real-time data feeds), RAG-enabled models can generate responses that are:
- Contextual and Grounded: Outputs are not mere regurgitations of memorized patterns but demonstrate an understanding of the specific query or prompt in relation to the retrieved knowledge.
- Evidence-Based and Informative: Responses can be supported by citations or references to relevant data, enhancing their credibility and factual basis.
- Adaptive and Up-to-date: The reliance on external knowledge sources allows the model to stay current with new information and trends, avoiding the issue of static and potentially outdated knowledge.
The Concept of Embeddings and Their Role
To bridge the gap between the symbolic world of language (as used by humans and Generative AI models) and the numerical representations required for computations, the concept of "embeddings" plays a pivotal role in RAG. Embeddings are vector representations of words, sentences, or even entire documents. These vectors are created using algorithms that capture patterns and relationships from large corpus of data. In other words, words or concepts that are similar in meaning will have vector representations that are close to each other in the high-dimensional vector space.
Within a RAG pipeline (see the simplified diagram below), embeddings serve two key purposes:
- Indexing and Retrieval: When a “query” is presented to the system, in a natural language, its embedding is generated. This query embedding is then used to search through a vector database, where embeddings of documents, images, text passages, or other relevant data have been pre-computed and stored. The goal is to efficiently retrieve the most relevant pieces of knowledge from the database based on the semantic similarity between the data embeddings and the query embedding.
- Informing the Generative Model: The retrieved knowledge, in the form of text or other data, is then fed to the generative language model. The model is conditioned on this external information to produce a response that is both coherent with the input prompt and informed by the retrieved context.
Key Considerations with Embeddings
When deciding how to generate embedding vectors, a few things have to be considered:
- Embedding Techniques: The choice of embedding technique (e.g., word2vec, GloVe, Transformer-based embeddings) can influence the quality and semantic representation of the vectors. When dealing with multi-modal data (text with image, audio, etc) the embeddings have to be selected accordingly.
- Dimensionality of Embeddings: Higher-dimensional embeddings can capture more nuance but come with higher computational cost, storage costs and latency.
- Vector Databases: Vector databases are designed to store and efficiently search through large collections of embeddings, supporting the retrieval aspect of RAG.
- Dynamic Embedding Generation: In some cases, it may be advantageous to generate embeddings on the fly, especially when dealing with rapidly changing data or specialized domains. Not all vector databases support real-time updates.
- Search Algorithms: Efficiently finding the most similar vectors within a vast embedding database is essential for RAG systems. There are a wide range of search algorithms available for various vector databases. The choice of algorithm depends on the use case and the data.
Data Pipelines and Governance for Generative AI
Data pipelines are the lifeblood of RAG workflows. They orchestrate the complex processes of data collection, transformation, embedding generation, storage, and retrieval – ultimately fueling the ability of AI models to respond from an organization's unique knowledge base and produce tailored, high-quality outputs. Below is the simplified version of a RAG pipeline. The pipelines entail components that increase in complexity as the system scales. This necessitates specialized expertise across various domains to address the evolving technical demands over the period of time.
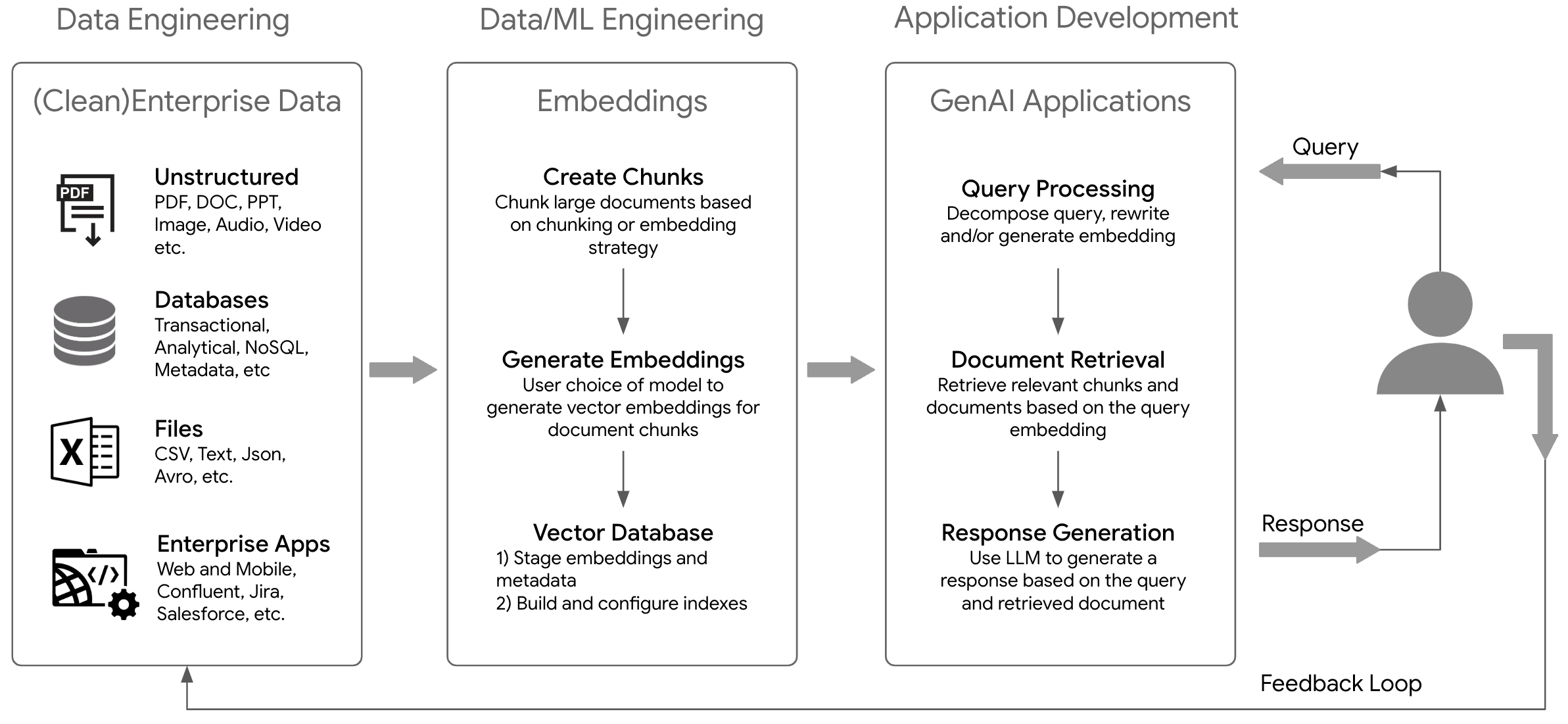
Fig 1. A simplified RAG Architecture
Let's examine the key building blocks of these specialized pipelines:
- Data Ingestion and Transformation: Generative AI pipelines must seamlessly integrate with diverse data sources, including structured databases, unstructured document repositories, real-time data streams, and external APIs. Data cleansing, normalization, and deduplication are essential pre-processing steps to ensure the integrity of the enterprise datasets. The data quality is paramount for models to be able to provide high fidelity results.
- Embedding Generation: The heart of a Generative AI pipeline is the process of transforming raw data into meaningful vector representations (embeddings). This is where domain knowledge and task-specific considerations come into play. Choosing the right embedding techniques is crucial for capturing the semantic nuances of the data. When dealing with large documents, it is a good idea to split it in multiple chunks for better management and retrieval.
- Storage and Retrieval of Embeddings: Vector databases serve as the repositories for embeddings. They can handle vast datasets, support lightning-fast similarity-based searches, and often accommodate frequent updates as data evolves. While a new breed of vector databases are available to support the GenAI solution, the traditional databases such as PostgreSQL, BigQuery, etc. are also extending support for embeddings and searches. The choice of vector database should align with performance, scalability, and integration requirements.
- Data Ownership and Access Control: The traditional data governance best practices continue to apply as GenAI solutions are being developed. Clear ownership and rigorous access control mechanisms are paramount. Especially when handling sensitive data, robust role-based access controls, data lineage tracking, and audit trails are non-negotiable for security and compliance. When exposing GenAI applications to end users, it is critical that they only see generated responses based on that data that they should have access to.
- Data Quality Assurance: The adage "garbage in, garbage out" applies forcefully to Generative AI. Data pipelines must incorporate automated quality checks, anomaly detection, and bias mitigation strategies. Continuous monitoring of data quality metrics helps to maintain the trustworthiness of the AI system.
Governance for Responsible and Sustainable Generative AI
Data governance extends beyond technical implementation. It encompasses establishing clear policies governing data usage, minimizing privacy risks, and ensuring adherence to ethical AI principles. Organizations should proactively address potential biases in their data, prioritize transparency in AI decision-making, and foster collaboration between developers, data teams and AI practitioners.
Best Practices for Data Management
While the technical aspects of data pipelines, embedding generation, and vector databases are essential, the success of Generative AI initiatives hinges on strategic data management practices and adherence to a set of guiding principles. This section outlines key best practices to ensure data serves as a powerful enabler rather than a bottleneck for scaling Generative AI solutions.
Data Architecture Design
A well-designed data architecture lays the foundation for efficient, scalable, and reliable Generative AI systems. Here are some of the consideration
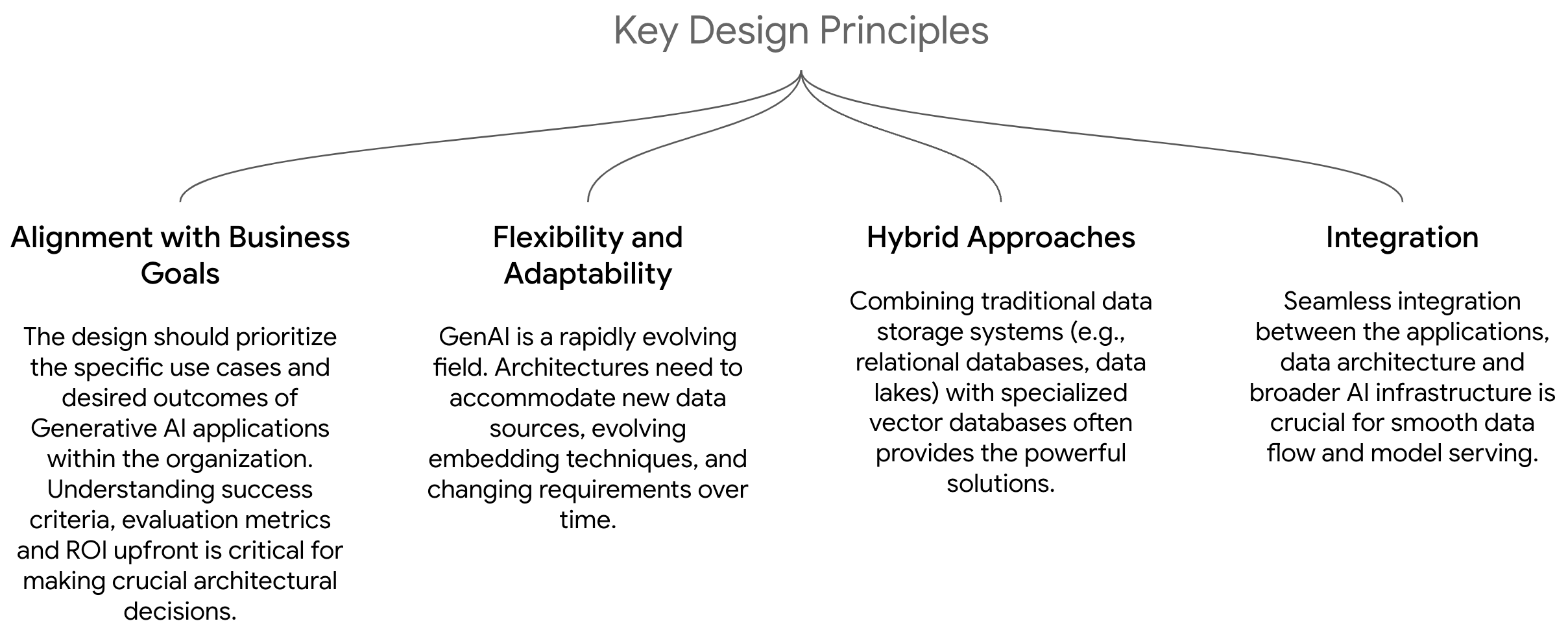
Fig 2. Additional Considerations for GenAI Data architectures
Metadata Management
Metadata, or "data about data," is an invaluable asset for Generative AI. A high quality data catalog can provide a significant boost to the quality of GenAI applications. Robust metadata management practices include:
- Data Provenance: Tracking the origin, transformations, and usage of data throughout its lifecycle enables reproducibility, auditability, and helps maintain data quality.
- Data Versioning: Version control for datasets and embeddings becomes crucial as models evolve and data is updated, allowing for rollbacks and debugging if needed.
- Data Catalogs: Comprehensive data catalogs with detailed descriptions and discoverability mechanisms empower LLMs and users across the organization to find and understand relevant data for Generative AI tasks.
Continuous Monitoring and Improvement
Generative AI data management is not a static endeavor. Best practices dictate a focus on continuous monitoring and iterative improvement:
- Performance Metrics: Track key metrics on data ingestion throughput, retrieval latency, and embedding quality to identify and address bottlenecks.
- Bias Detection: Regularly assess both data and embeddings for potential biases that could lead to discriminatory or unfair AI outputs.
- Data Drift: Monitor changes in the distribution of data over time, as data drift can degrade model performance and necessitates retraining or embedding updates.
- Feedback Loops: Establish mechanisms to collect user feedback on the quality of Generative AI outputs, informing refinements to data pipelines, prompt engineering and model tuning processes.
Future Trends in Data Management for Generative AI
While the foundation is now laid, the field of data management specifically tailored for generative AI remains a burgeoning domain. The future holds exciting advancements that will significantly enhance how we curate, transform, and utilize data to power ever more sophisticated AI models. Here's a look at some of the crucial trends to watch:
- Advanced Embedding Techniques: Currently, vector embeddings serve as the core method of translating raw data into numerical representations that generative AI models can understand. However, research into more advanced embedding techniques is underway. We can expect the emergence of embeddings that capture increasingly nuanced and complex relationships within data. These new techniques might incorporate domain specific semantic understanding, hierarchical structures, and even knowledge graphs. Consequently, generative AI models will be able to reason and create outputs with higher accuracy and relevance to specific domains and tasks.
- Real-Time Embedding Updates: Many vector databases are designed for batch updates. The need for near real-time updates to embeddings (to account for new data and information) will drive the development and adoption of specialized solutions optimized for low-latency embedding updates.
- Data Augmentation and Synthetic Data Generation: The insatiable appetite of generative AI for vast quantities of data poses a challenge, particularly in specialized domains where data may be scarce or sensitive. Data augmentation techniques, where existing data is creatively modified to generate variations, will play an increasing role. Further, the development of sophisticated synthetic data generation methods, trained to produce realistic artificial data, will help mitigate data scarcity. This ensures that AI models have sufficient data to avoid overfitting and deliver robust results even in scenarios where real-world data is limited.
- Data Provenance and Lineage Tracking: As GenAI outputs become business-critical, tracking the origins and transformations of data will be essential for auditing, debugging, and ensuring the reliability of AI decisions. Robust provenance and lineage tools will be a core part of the data stack.
- Ethical Considerations in Data Management for Generative AI: As generative AI becomes increasingly potent, it's crucial to establish proactive ethical guidelines for data management. This includes ensuring the mitigation of biases in datasets, preventing the propagation of harmful stereotypes or misinformation, and addressing issues of data ownership and transparency. Building ethical foundations into the data management infrastructure for generative AI will foster the responsible development and deployment of these powerful technologies, ultimately guiding them toward positive and beneficial use.
Conclusion
The transformative potential of Generative AI is undeniable. However, unleashing this potential rests upon recognizing the paramount role of data management. It's not the readily available language models themselves, but an organization's proprietary data, transformed into insightful embeddings, that forms the true competitive advantage.
Summary of Key Points
- Generative AI, powered by retrieval augmented generation, relies on vast knowledge bases to produce contextually relevant and informative outputs.
- Embeddings are the bridge between raw data and the computational world of AI models. Their strategic generation is fundamental to success.
- Robust data pipelines orchestrate the flow of information, ensuring data quality, and powering efficient embedding creation and retrieval.
- Best practices like thoughtful data architecture, comprehensive metadata management, and continuous improvement are vital for building sustainable Generative AI solutions.
- Future trends like advanced embeddings, data augmentation, real-time vector databases, and ethical considerations will shape the evolution of data management in this domain.
A well-governed data platform acts as a fertile ground for Generative AI to flourish. By meticulously curating data assets, generating high-quality embeddings, and establishing reliable retrieval mechanisms, organizations unlock the following benefits:
- Differentiated Solutions: Tailored data fuels customized Generative AI applications, surpassing the limitations of off-the-shelf models.
- Enhanced Accuracy and Trust: High-fidelity data pipelines and bias mitigation measures promote reliable AI outputs that users can confidently rely on.
- Competitive Advantage: Unique insights extracted from proprietary data become a powerful source of value for businesses in an increasingly competitive landscape.
- Responsible Innovation: Proactive data governance safeguards both the integrity of Generative AI solutions and aligns their development with ethical principles.
Call to Action
The race to leverage Generative AI has commenced. Organizations cannot afford to treat data management as an afterthought. To seize the opportunities and navigate the challenges of this transformative technology, a strategic and proactive approach is imperative:
- Prioritize Data Investment: Recognize the strategic value of data alongside the language models themselves. Invest in building and refining data infrastructure specifically for Generative AI.
- Develop Data Expertise: Cultivate cross-functional data management talent within organizations, fostering a deep understanding of embedding techniques, vector databases, and governance best practices.
- Embrace a Culture of Experimentation: The field of data management for Generative AI is nascent. Encourage a mindset of continuous learning, adaptation, and experimentation with new technologies.
- Champion Ethical Considerations: Embed ethical principles into data collection, curation, and usage from the outset. Proactively address potential biases and advocate for responsible AI practices.
The organizations that embrace these imperatives and successfully unlock the power of their data through robust management strategies will emerge as leaders in the era of Generative AI. The future of innovation and disruption in this space will be written not just in code, but in the very data that fuels these remarkable models.
