

There are many ways that people design database tables to store data about the entities in their business problem domain. Some of these solutions might suit a problem better than others, but often many of us must work within a design that others have implemented. When that happens, we might not only have to design our queries and reports around the design, but we might have issues with data integrity as well.
In one system, the original designer had decided to use a EAV design to capture various attributes about their clients. Each client was supposed to have a set of core attributes, but over time they found that not all clients had the required items. This caused errors and problems in the application.
In this article, I want to look at this problem and give a couple ways of dealing with the situation.
The Scenario
I've altered the scenario slightly because of security, but the concept remains the same. In this article, we'll look at a much simpler system that gathers various items about football players for the Denver Broncos. For the case of simplicity, I'm only capturing a few elements of data for each player. The idea is our application can store various items about a player in a separate table. Originally the table contained only a few elements.Over time, this changed.
The setup script is shown below, and populates a few tables with information. There is a Player table and an EAV table called PlayerAttribute. I'll populate each with some data.
CREATE TABLE Player
(PlayerKey INT IDENTITY (1,1) NOT NULL CONSTRAINT PLayerPK PRIMARY KEY
, PlayerName VARCHAR(200)
, PlayerStatus TINYINT)
go
CREATE TABLE PlayerAttribute
( PlayerAttributeKey INT IDENTITY (1,1) NOT NULL CONSTRAINT PlayerAttributesPK PRIMARY KEY
, PlayerKey INT NOT NULL CONSTRAINT PlayerAttributesFK_Player_PlayerKey FOREIGN KEY REFERENCES Player
, PlayerAttributeName VARCHAR(100)
, PlayerAttributeValue VARCHAR(500)
)
GO
INSERT Player VALUES ('Shaquil', 1), ('Von', 1), ('Bradley', 1), ('Shane', 2), ('Todd', 2), ('Jerrol', 3), ('Jeff', 3), ('Josey', 3)
INSERT dbo.PlayerAttribute
(
PlayerKey ,
PlayerAttributeName ,
PlayerAttributeValue
)
VALUES
(1, 'Weight', '250')
, (1, 'College', 'CSU')
, (1, 'Height', '74')
, (1, 'Number', '48')
, (1, 'Position', '48')
, (2, 'Weight', '250')
, (2, 'Number', '58')
, (2, 'College', 'Texas A&M')
, (3, 'Height', '76')
, (3, 'Weight', '269')
, (4, 'Position', 'OLB')
, (4, 'College', 'Missouri')
, (4, 'Height', '75')
, (5, 'Weight', '230')
, (5, 'Number', '51')
, (5, 'College', 'Sacramento St')
, (6, 'Weight', '235')
, (6, 'Position', 'LB')
, (7, 'Weight', '249')
, (8, 'Number', '47')
Once this data exists, we can see that there are 8 players in the Player table. Each of these has a PK value in the PlayerKey column. In the PlayerAttribute table, we have this PlayerKey column as a FK. In addition, we have key names for these attributes:
- Number
- Position
- Height
- Weight
- College
Each row has one of these attributes with the appropriate value for the player in the PlayerAttributeValue column. If we check the data for one player, we can see that all attributes are present.
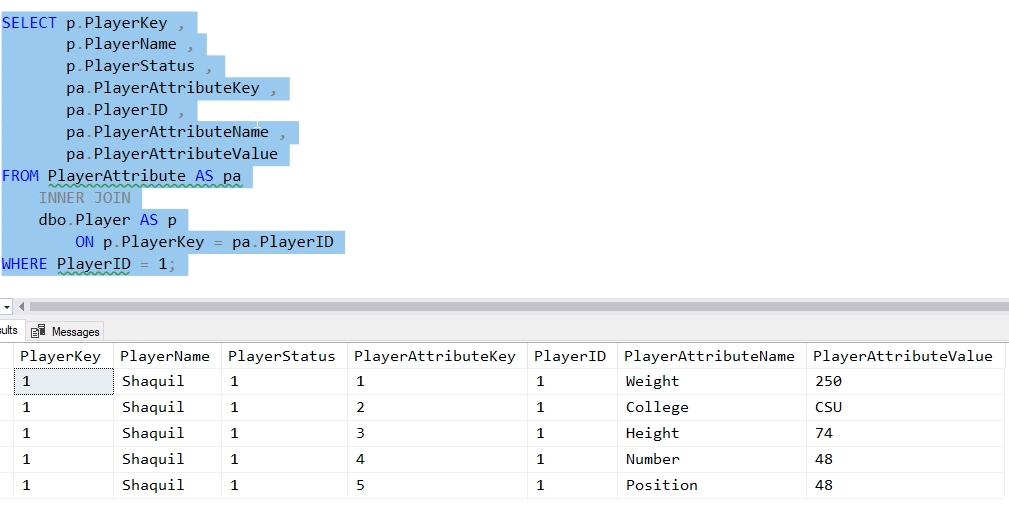
Problems Arise
Over time, the application has evolved. Originally only two elements, number and position, were required. Since these were items every player was assigned, the application didn't enforce an validation. After all, a data entry person would quickly realize a mistake and enter the value. As more data was captured, it was decided that every player needed to have all five elements. This isn't an issue for new players, and data entry employees know to input allt this data, and the appropriate form validation exists in the application.
The problem exists because in our application because older players don't have all the values. In fact, some are even missing our required values. If we look at the data for two players, we can see this.
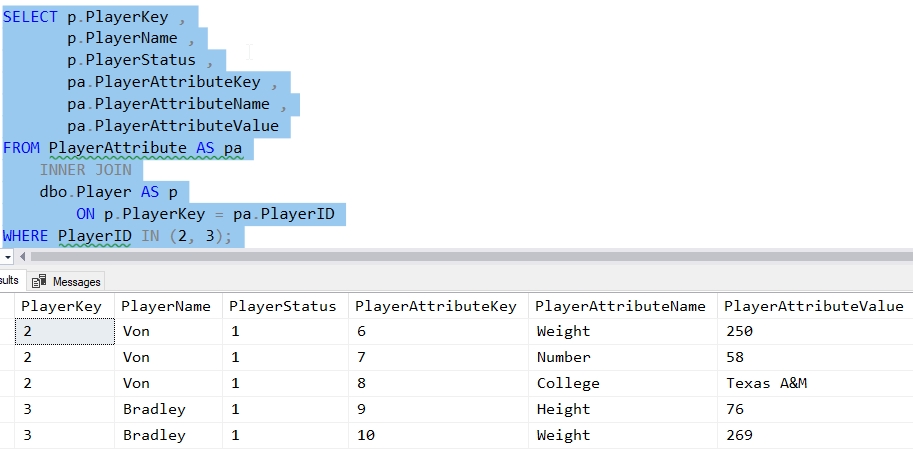
There are really two issues here. One is that we need to find the problem rows and then provide values for the missing attributes. The second is that we don't want this to happen again, so we want ensure we are capturing the required values in the future. Let's deal with each of these.
Finding The Players with Missing Values
The first step in looking at our data is finding the players that are missing data. Since we know there are 5 values required, we can use a simple COUNT(*) aggregate along with a HAVING clause to find out which players are missing data. The query below will give us the results we want.
SELECT p.PlayerName ,
COUNT(*)
FROM dbo.PlayerAttribute AS pa
INNER JOIN
dbo.Player AS p
ON p.PlayerKey = pa.PlayerKey
GROUP BY p.PlayerName
HAVING COUNT(*) < 5;
This gives me the following players. As you can see, all are missing values. There are three players with 3 of the five values, two with 2, and two with 1.
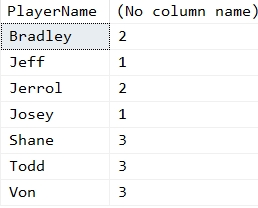
Finding Which Values are Missing
The next step in our process is to determine which values are missing. I know that Shane (Ray) only has 3 values, but which 3? Or more importantly, which 2 are missing? I need a report of some sort that I can give to a user to gather the missing data and fill in the results. If I want to see all the values for each player, I can use an outer join to get the result. However, I need a set of known data that I can use for the outer join.
To start, I need a list of the attributes. I can get this with a simple query, which I'll load into a table variable.
DECLARE @a TABLE
(
AttributeName VARCHAR(100)
);
INSERT @a
SELECT DISTINCT
pa.PlayerAttributeName
FROM dbo.PlayerAttribute AS pa; The next step is to ensure I have a starting point. Every player needs this data, so they need to have 5 full rows. A simple cross join will produce this. I'll use a CTE to make this more readable. This gets the list of players with the full set of attributes.
WITH cteAttribute (PlayerKey, AttributeName) AS ( SELECT playerkey, AttributeName FROM @a CROSS JOIN dbo.Player AS p )
Now that I have the full set of values, I'll use an outer join to find out which values are missing. I could limit this to just the missing values, but what I want to give to someone is a list of the data I have and an easy way to find and fill in the missing values. The can use this to double check the existing data as well as enter new data.
In my query, I'll use COALESCE() to return a string of underscores for missing values. I do this as the values I'm missing will come up as NULLs. One other important point, I need to get the player and the attribute name from my full list (the CTE), as the PlayerAttributeName from the PlayerAttribute table will return as NULL for missing values.
WITH cteAttribute (PlayerKey, AttributeName)
AS
(
SELECT playerkey, AttributeName
FROM @a
CROSS JOIN dbo.Player AS p
)
SELECT
p.PlayerName ,
cteAttribute.AttributeName ,
'AttributeValue' = COALESCE(pa.PlayerAttributeValue, '_________')
FROM cteAttribute
LEFT OUTER JOIN
dbo.PlayerAttribute AS pa
ON pa.PlayerAttributeName = cteAttribute.AttributeName
AND pa.PlayerKey = cteAttribute.PlayerKey
INNER JOIN dbo.Player AS p
ON p.PlayerKey = cteAttribute.PlayerKey
ORDER BY p.PlayerName ,
pa.PlayerAttributeName;
When I run this, with the table variable, I see these results:
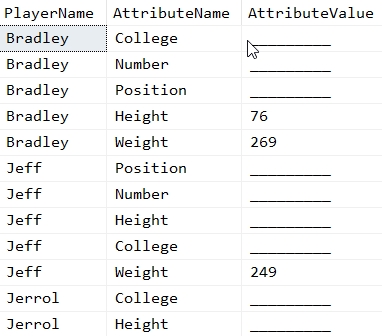
That's a report I can give to a business person to use in their data correction efforts. Note that I've got 2 values for Bradley (PlayerKey = 3) and one value for Jeff (PlayerKey = 7). This matches the report in the previous section.
Handling Future Changes
Ideally in the future we'd redesign this table to ensure that there is a list of required values. We could do this in a few ways. The first is that we don't use the table variable in our query. Instead, we could use a static set of data in a VALUES() clause. That would look like this:
WITH cteAttribute (PlayerKey, AttributeName)
AS
(
SELECT playerkey, AttributeName
FROM (VALUES ('Position'), ('Height'), ('Weight'), ('Number'), ('College')) a(AttributeName)
CROSS JOIN dbo.Player AS p
)
There are problems with this approach. The first is that any change of the required list means that the query must change. My experience has been that data changes are better, and less likely to cause issues, than code changes. Also, we can often undo data changes quickly. With that in mind, I'd suggest a new table be added. Even if the application isn't aware of it, and can't manage it with tooling, adding items to the table could be a periodic DBA task.
The design I'd use would be to create the a table that stores all the attributes. This would allow for marking certain attributes as required as well as allowing validation of the data in the actual table. My design would be:
CREATE TABLE LookupAttribute
( LookupAttributeKey INT IDENTITY(1,1) NOT NULL CONSTRAINT LookupAttributePK PRIMARY KEY,
PlayerAttributeName VARCHAR(100)
, AttributeRequired BIT
)
GO
INSERT dbo.LookupAttribute
(
PlayerAttributeName ,
AttributeRequired
)
VALUES
('Position', 1),
('Height', 1),
('Weight', 1),
('Number', 1),
('College', 1)
GO
This table would then be used in the CTE to replace the table variable or VALUES() clause. This also allows me to add new attributes that aren't required.
One other item is that I can also use a query between this table and PlayerAttribute to show me if the application has entered incorrect data, such as "No." instead of "Number".
Performance Considerations
When using this type of query, one wants to be very careful. The use of a CROSS JOIN is never good for performance as the size of the table grows. If this table is for active players, then it will be around a hundred rows at the most. If it's for the entire history of players, I might ensure that I have some flag in here that can limit the rows sent to the CROSS JOIN.
The OUTER JOIN is also an issue. As the table grows, this can be a source of performance problems. I wouldn't want to use this in a report that is run constantly, such as populating the link to the player roster at the top of the article. Instead, I'd use this technique only for a DBA task that might look for missing values once a week, or be run sparingly. If not, I'd actually look to limit my query to just those players that might be missing values, combing the first report of players without the required number of attributes and the last query that finds those missing values.
It should go without saying, but there need to be the proper indexes on these tables. While there are PKs, I'd ensure that there is an index on the PlayerKey and the PlayerAttributeName that includes the PlayerAttributeValue. Good indexing goes a long way towards improving the performance of many queries.
I'm sure there are other improvements and more creative solutions, and I look forward to reading the discussion for this article. I'm sure someone will optimize what I've done.
Conclusion
This is a trivial example, and one that is fun for me. This situation, however, is one that I've encountered. I've seen this occur in situations where we store some sort of settings or options for users, similar to what Iris Classon wrote about here. I've seen this become a problem over time as rows don't exist for all the entities in your application.
While I've shown this as a data entry item, the first report is the type of item I've written into a daily data integrity check that runs every day. When this returns any rows, a DBA is notified and can go check that there is indeed a data problem. In this way, we can often fix issues quickly before clients notice as well as tracking down potentially problematic application code that isn't enforcing some rule.
I tend to dislike EAV tables, and this article shows one of the problems that can occur. I would prefer that required items actually be added to the Player table, or a vertical partition of this table, to ensure that the design is more straightforward, normalized, and optimized for a relational system.
