

For a long time, I avoided using surrogate keys in some of my tables. I always understood they were great to generate numeric codes, as product IDs and so on, but I was quite skeptical on how they could be helpful on any table with a multi-column identifier. For instance, were they useful on dimensional models? When considering a well-designed database model, I couldn't see any strong reason to consider a generated column as the most important one in a table. After all, by definition, surrogate keys are meaningless from a business point of view.
By default, SQL Server uses the table's primary key as the basis for all indexes. So my question is: from the performance standpoint, will there be any benefit on using surrogate keys? After years working with databases, I believe there are no simple truths in this realm. So I put my question to a test. This is the first of a series of articles to take a closer look on surrogate keys. In all studies to be conducted in this series, I pick a particular table design and then compare the use of a surrogate key against another candidate key. The idea is to evaluate which option works better as the table's primary key.
In this first article, I show some common definitions and explain the approach that is used to evaluate results. To illustrate it, I show the results on a table of products. So let's get started with important concepts.
What is a Primary Key
The primary key (or PK for short) is a unique identifier for each row in a table. I guess we can say the PKs are the basis of relational database design. As PKs identify each row, the PK is the main column or columns to use when defining the relationship between two tables.
Besides being a unique identifier, we also expect the primary key not to be updatable.
Candidate Keys
A candidate key is an attribute or a combination of attributes that uniquely identifies each row in the table. Each table may have one or more candidate keys, but only one of them will be chosen to be the table's primary key.
Surrogate Keys
A surrogate key is an artificially generated unique identifier, which has no relation to the table data. Since the surrogate key is independent of all other columns on the table, we are assured its values will never need to be updated.
A simple way to implement a surrogate key is using an identity column to be the table's PK. Listing 1 shows an example.
CREATE TABLE myTable( pkSurrogate int IDENTITY(1,1) NOT NULL, Colunmn1 smallint, ... ColumnN varchar(5), CONSTRAINT PK_myTable PRIMARY KEY CLUSTERED ( pkSurrogate ASC ) );
Listing 1: Creating a table with a surrogate key.
Indexes
SQL Server works with several different types of indexes. In this article, we are concerned about clustered and non-clustered indexes only.
The clustered index is the main index a table might have. If a table has it, then its data will be sorted by the clustered index key before it is stored in data pages.
On most RDBMSs (SQL Server included), the default is to create a clustered index when creating a PK. The only exception I can remember is DB2 running on z/OS, simply because DB2 on z/OS assumes no default on this matter.
So, if we accept the default, primary key columns will also be the basis for the table's clustered index. Therefore, in this situation, data pages are sorted by the PK values. This is illustrated in Figure 1.
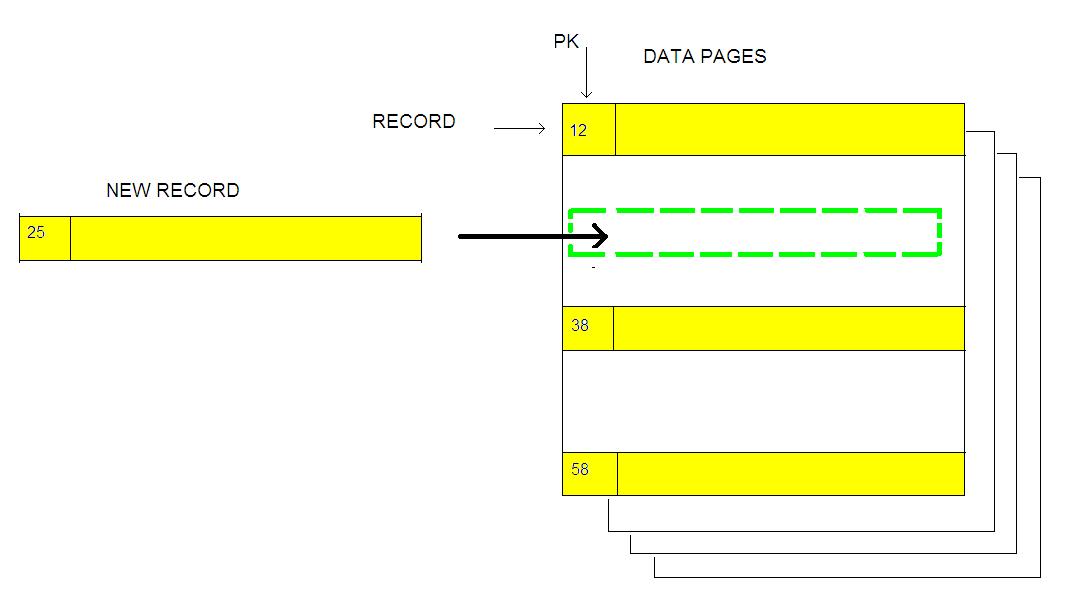
Figure 1: Data Pages and the Primary Key.
Non-clustered indexes are simpler. They also create a "catalog" of key values of particular column or columns, but they don't affect data pages order. In fact, if a table has a clustered index, all non-clustered indexes will be associated to it, as the non-clustered indexes will take advantage of the sorted data pages.
B-Tree Structure
In SQL SERVER, indexes are organized in decision trees known as B-trees (for balanced trees). A B-tree is a storage structure of locating files that "minimizes the number of times a medium must be accessed to locate a desired row, thereby speeding up the process" (SearchSQLServer.com).
The structure of the B-tree includes the root page, intermediate pages and finally the leaf level. This is illustrated in Figure 2, which also shows the path to locate a desired row in a simple 3-level B-tree.
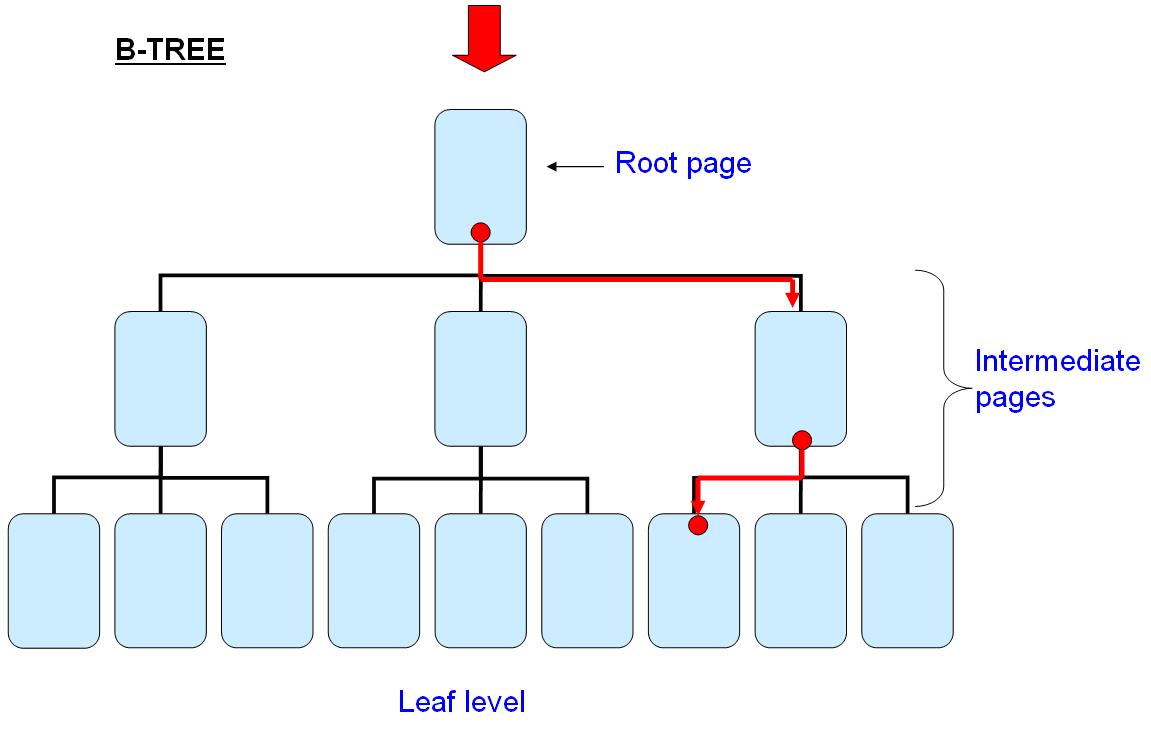
Figure 2: B-tree levels
The clustered index is the main index in the table because its leaf level contains the data pages themselves. The other levels (root page and intermediate levels) contain the actual index pages.
Non-clustered indexes are also organized as B-trees. But in case a clustered index exists, the leaf level of all non-clustered indexes will not point to the data pages, but to the clustered index pages.
PKs Can Help Performance
Putting it all together, we can say that creating a PK can help performance, particularly when we use the default option and let a clustered index be created over the same column(s). Why?
First of all, a good PK definition will create a faster clustered index. This affects data manipulation performance, as the clustered index will help retrieve data faster (SELECT statements), and also help to change data faster (insert, update, delete), by helping SQL Server to locate the desired data pages.
Second, a good PK might create "smaller" indexes, demanding less space for each row in index pages. As we have fewer index pages, the faster it will be to locate the desired information.
Third, if we have an efficient clustered index, non-clustered index will also perform better, as their structures are associated.
What to Compare
I want to check index properties and index performance on very specific test environments. To do so, I use the SQL Server features to show clustered index statistics and also query performance for a couple of DML statements.
In this first article, I choose a simple case to illustrate the methodology I am using: the case of replacing an alphanumeric natural key with a surrogate key. I pick a table design like the one used in the table Production.Product, which is part of SQL Server's sample database, AdventureWorks. This design is adapted to create two similar tables: the first one, dbo.tblProductCK, uses an alphanumeric attribute as the PK (column ProductNumber). The second table is dbo.tblProductSK and it uses a surrogate key as PK (column Productid). Figures 3 and 4 show the detailed design of each table.
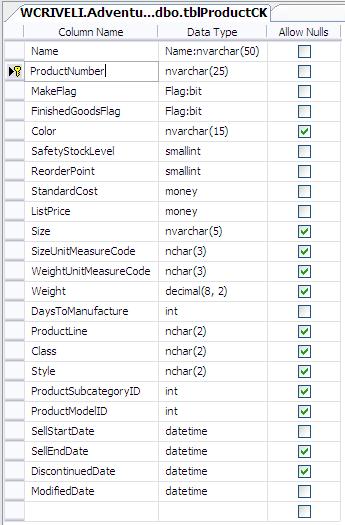
Figure 3: table dbo.tblProductCK
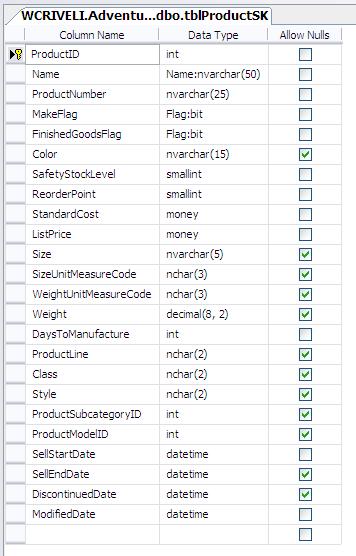
Figure 4: table dbo.tblProductSK
The tests are conducted using two different workloads: the first one (workload1) using the original 504 rows stored on database AdventureWorks. The second one(workload2) has 129,024 rows.
Now let's talk about getting the information I need. To calculate the indexes statistics, I use the Dynamic Management View (DMV) named sys.dm_db_index_physical_stats. I show on Listing 2 the script to use on these tests.
SELECT DB_NAME() AS DB, OBJECT_NAME(I.ID) AS 'TABLE', I.NAME AS 'INDEX', V.index_type_desc, V.avg_page_space_used_in_percent, V.avg_fragmentation_in_percent, V.index_level, V.record_count, V.page_count, V.fragment_count, V.avg_record_size_in_bytes FROM sys.dm_db_index_physical_stats(DB_ID(DB_NAME()), NULL , NULL, NULL , 'detailed') V INNER JOIN sysindexes I ON V.object_id = I.id AND V.index_id = I.indid WHERE OBJECT_NAME(I.ID) LIKE 'tblProduct%' ORDER BY V.object_id, V.index_id, V.index_level DESC
Listing 2: Using DMV to check index statistics.
For checking query performance, I use the Statistics Profile feature. This feature shows information about the execution plan for the query, and the "cost" to run it. As might be implied by its name, costs should be kept as low as possible.
Performance will vary considerably depending on the queries we choose. To keep this study as simple as possible, I choose to run only one SELECT and one UPDATE statement, as shown in Listing 3 and 4.
SET STATISTICS PROFILE ON; -- SELECT * FROM productCK T WHERE COALESCE( DiscontinuedDate,'1/1/1900') = '1/1/1900' AND SellStartDate between '2001-01-01' and '2008-12-31' ORDER BY Name;
Listing 3: SELECT statement considered on performance evaluation.
SET STATISTICS PROFILE ON; -- UPDATE dbo.tblProduct* SET Color = 'Black' WHERE Name = 'ML Mountain Frame-W - Silver, 42';
Listing 4: UPDATE statement considered on performance evaluation.
I pick the UPDATE statement because it basically works as a DELETE followed by an INSERT. So UPDATE statements are supposed to be the DML statement with the highest costs.
Results
Let's start showing the results for the indexes properties, which are generated after running the DMV in Listing 2. To make it easier to compare the different table designs and workloads, I put them all together in Table 1.
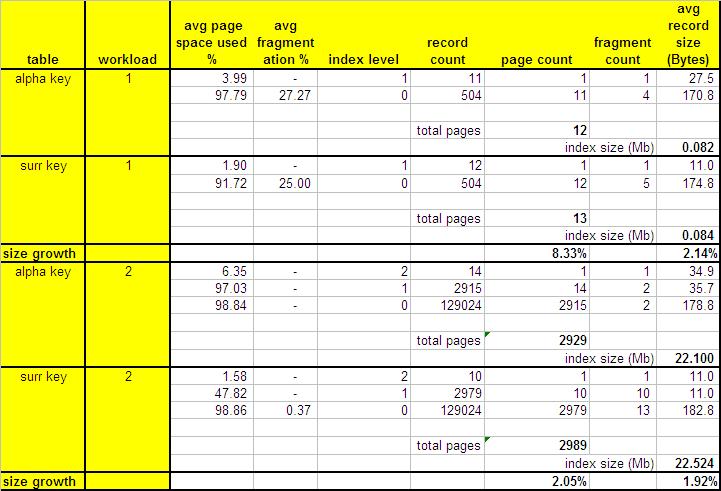
Table 1: Indexes properties for both tables with different workloads
As shown above, the table with the surrogate key demands a bit more index pages (8.33% for the first workload and 2.05% more on the second one). As Workload 1 deals with a much smaller table, the overall number of pages is too small and adding one extra page for the table with a surrogate key represents a significant impact (8.33%). But this is a mathematical "distortion", as we add only 1 extra page.
We can see an interesting thing on the scenario dealing with larger tables. The table with surrogate key has more data pages (2979 against 2915), but the number of index pages (levels 1 and 2 on Table 1) is smaller: 11 for the table with surrogate key and 15 for the table with alphanumeric key.
When it comes to total disk space used by the clustered index in each table, again the numbers are higher for the table with surrogate key (2.14% more on workload 1 and 1.92% on workload 2).
The main index statistics we check show a slight advantage to the table with the alphanumeric key. This advantage is not due the nature of the primary key, but to the fact that we are including an extra column to the second table: the surrogate key, an artificial column explicitly created to work as unique identifier. As we can see on Table 1, the difference comes from the fact that the size and the number of data pages (the index level 0 of the clustered index) are higher for the table with surrogate key. Although this table shows smaller index pages size and also smaller number of index pages (i.e. index level 1 and higher), the numbers have very little impact on the total results, since we have a lot more data pages than index pages.
Now let's check performance when we run the SELECT statement presented on Listing 3. I show on Table 2 the results for all scenarios.
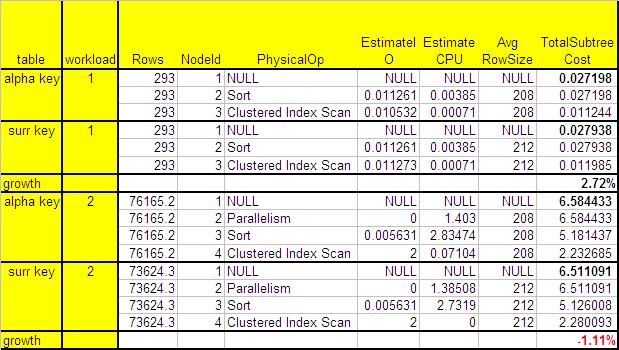
Table 2: Performance when running SELECT statement
Again we have very interesting numbers. See that when comparing performance on the small tables (504 rows), the alphanumeric key has better performance: the subtree cost for the surrogate key is 2.72% higher. But when we go to the larger tables (129024 rows), the surrogate key turns out to be the best option. The cost is 1.11% less than the cost of the alphanumeric key.
Finally, we check performance when running the UPDATE statement (Listing 4). The results are presented on Table 3.
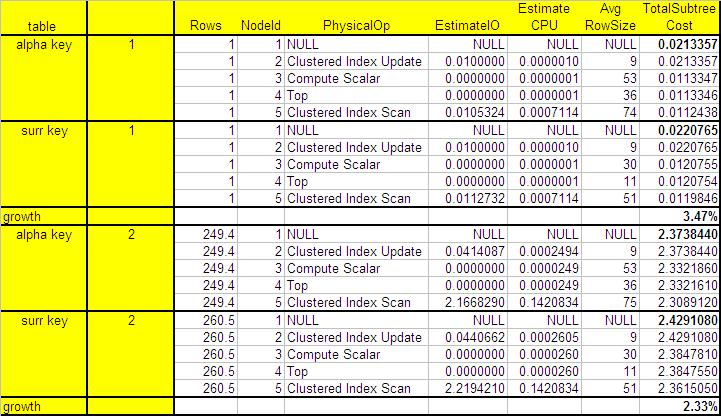
Table 3: Performance when running UPDATE statement
We see in Table 3 the performance for the UPDATE statement for both scenarios (small tables and large tables) is better when using the alphanumeric key. The subtree cost for the table with surrogate key is 3.47% higher for the smaller table and 2.33% higher for the larger one.
Again we notice the difference between the performance for the surrogate and alphanumeric keys seems to get smaller as the tables get larger. But even for the larger table, with more than 1 hundred thousand rows, the UPDATE cost is lower for the table with alphanumeric key.
Conclusion
This article intends to illustrate the concepts and show a simple study comparing the use of a surrogate key to that of an alphanumeric candidate key. The index statistics show that the use of a surrogate key always implies in an overhead: the cost of adding a column to the table and so, increasing the number of data pages to use. This impact is slightly reduced as the table grows bigger.
But when it comes to performance, results are kind of disturbing. For the smaller tables (with 504 rows), performance was better for the alphanumeric candidate key in both tests. When looking at the bigger tables (129,024 rows), it seems the surrogate key perform relatively better. In the SELECT test, for instance, the surrogate key really performs better than the alpha key.
I understand the numbers here suggest that there will be no performance benefit when using a surrogate key in small tables; let's say with less than 10,000 records. But they might be a good choice in larger tables and also in cases where the alphanumeric candidate key might be updated for any reason.
It is important to remember the performance results severely depend on the query you are running. So, in the future, it would be a good idea to do a new study testing performance over a larger set of queries, let's say 10 or even 50 different statements.
In the next article, I will show the study of the use of a surrogate key instead of a 4-column composite key.
References
- WIKIPEDIA. Unique Key. http://en.wikipedia.org/wiki/Primary_key
- WIKIPEDIA. Surrogate key. http://en.wikipedia.org/wiki/Surrogate_key
- MICROSOFT. Types of Indexes - SQL Server 2008 R2. MSDN. http://msdn.microsoft.com/en-us/library/ms175049.aspx
- MICROSOFT. Clustered Index Structures. MSDN. http://msdn.microsoft.com/en-us/library/ms177443.aspx
- SHAW, Gail. Introduction to Indexes (the series). SQLServerCentral. Oct 26th, 2009. http://www.sqlservercentral.com/articles/Indexing/68439/
- SEARCHSQLSERVER.com. B-tree. SearchSQLServer http://searchsqlserver.techtarget.com/definition/B-tree
- DAVE, Pinal. SQL Server - Index Levels, Page Count, Record Count and DMV - sys.dm_db_index_physical_stats. SQLAuthority.com. July 4th, 2010. http://blog.sqlauthority.com/2010/07/04/sql-server-%E2%80%93-index-levels-page-count-record-count-and-dmv-%E2%80%93%C2%A0sys-dm_db_index_physical_stats/
- CODEPLEX Open Source Community. Microsoft SQL Server Database Product Samples: Download SQL Server 2008 SR4. Microsoft. Feb 15th, 2010.

