

Denormalization is not a design strategy. It is a design work-around. Well normalized databases represent a good design strategy, but can often lead to a great deal of complexity when it comes to support, maintenance, and new development. A well designed database can mean that, in order to get specific data you need, you need to go through 5, 10, or even more tables which represent the data you're looking for. Though there are many solutions to this dilemma, such as virtual tables (views), programmatic solutions, temporary tables, and more, I think it's important to not discount the value of well-placed denormalization in the database. The intent of this article is to consider some use cases for denormalization, and from those use cases, assert some generalizations about when and why to use denormalization.
There are often 2 points in the development life cycle where denormalization makes sense:
- During initial design
- Post-Implementation
During initial design, it is very easy to violate simplicity principals of a company or organization. In other words, sometimes during the design phase, system becomes too darn complicated. As with defects, the design phase represents the cheapest point at which to rethink and refactor. As time goes on in the development process, it becomes more and more expensive to make changes to systems.
During post-implementation, once the system has demonstrated its bottlenecks and given insight into opportunities for performance tuning, this phase represents a good opportunity to refactor, and find opportunities for denormalization. One insight in particular which is useful is knowing which queries or stored procedures are most frequently accessed. If your system falls into the 80/20 rule, where 20% of the stored procedures are used 80% of the time, this gives you your entry point by which to consider denormalization.
What I'd like to do is to build a scenario, and generate a few use cases and suggest how denormalization can be a solution to the problem.
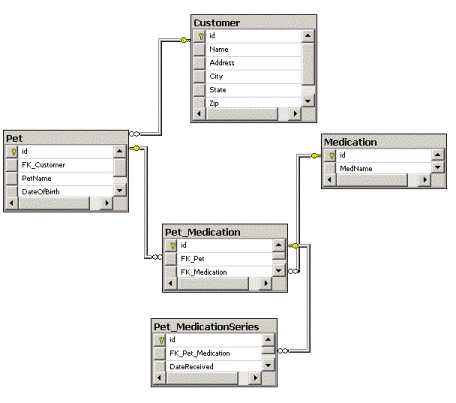
Consider a scenario where I have a Veterinary Practice Management System. In this system, consider I have the following tables:
| Table | Description |
| Customer | Represents a customer who has a pet that he/she brought in at some point |
| Pet | Represents a pet that a customer owns; has a many-to-one relationship with Customer |
| Medication | Represents all the medications available to the veterinary clinic to give to an animal |
| Pet_Medication | Represents all the medications a Pet has been given, either by injection, or by tablet. Has a many-to-one relationship with Medication; also has a many-to-one relationship with Pet |
| Pet_MedicationSeries | In the event where a medication must be given in a series, represents each instance in the series; for instance, if a pet receives rabies boosters each year, or if a pet receives heartworm pills every 6 months, each instance of receiving this booster or new set of pills would be represented as a record in this table. Has a many-to-one relationship with the Pet_Medication table. |
The columns in the above tables should be fairly intuitive, so I will abstain from creating textual tables to representt the layout; rather, I'll show a diagram, to give a clearer picture:
Denormalization makes sense depending on how end-users will use the system. Consider the following features:
Feature #1:
If the most valuable feature in your database application, for most of your customers, is the ability to find which customers purchased the most Heartworm pills in the last year, then the query that would need to be built in the database's current state would be something like:
SELECT C.Name, M.MedName, COUNT(P_MS.*) FROM Customer C JOIN Pet P ON C.ID=P.FK_Customer JOIN Pet_Medication P_M ON P.ID=P_M.FK_Pet JOIN Medication M ON P_M.FK_Medication=M.ID JOIN Pet_MedicationSeries P_MS ON P_M.ID=P_MS.FK_Pet_Medication WHERE P_MS.DateReceived > getdate() - 365 AND M.MedName='HeartWorm' GROUP BY C.Name, M.MedName
Based on the relationships between these tables, and the way we expect this database to get used, one could guess that the largest (in terms of number of records) tables in the above list would probably be Pet_Medication and Pet_MedicationSeries. Any opportunity to bypass large tables represents a potentially large performance gain, because going through large tables to get at particular data can be costly if indexes are fragmented or out of date, because the query optimizer is apt to get a bad performance plan.
Given that the most valuable feature in the database is to query which Customers purchase the most Heartworm pills, it stands to reason that the above query is probably one of the most used queries in the database. To verify which queries or stored procedures are the most frequently accessed, you can run a simple SQL Profiler analysis, or use the below query (>=SQL 2005):
SELECT text, total_worker_time/execution_count AS [Avg CPU Time], execution_count
FROM sys.dm_exec_query_stats AS qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) AS st
ORDER BY execution_count DESC
Based on my this new understanding of how the database gets used most, my assertion would be that the best opportunity for denormalization would occur in the Pet_MedicationSeries table. In particular, I would add a foreign key relationship to the Customer table, and to the Medication table (columns would be called FK_Customer and FK_Medication, respectively). With this denormalization, I could rewrite the above query as follows:
SELECT C.Name, M.MedName, COUNT(P_MS.*) FROM Customer C JOIN Pet_MedicationSeries P_MS ON C.ID=P_MS.FK_Customer JOIN Medication M ON P_MS.FK_Medication=M.ID WHERE P_MS.DateReceived > getdate() - 365 AND M.MedName='HeartWorm' GROUP BY C.Name, M.MedName
With the above denormalization, I was able to cut the number of tables I traveled through from 5 to 3. In the process, I also decreased the number of tables I would have to include in analysis if there were a performance problem.
Feature #2
Consider another important feature that end-users would find particularly valuable: finding which medicines have the most administrations. To build a query to find this data (without the above denormalizations), the query would look something like this:
SELECT M.MedName, COUNT(P_MS.*) FROM Medication M JOIN Pet_Medication P_M ON M.ID=P_M.FK_Medication JOIN Pet_MedicationSeries P_MS ON P_M.ID=P_MS.FK_Pet_Medication GROUP BY M.MedName
In the above example, given that the Pet_Medication table is quite large, it would be better if we could bypass it; therefore a denormalization in the Pet_MedicationSeries table is in order (once again). If we take into account that Feature #1 already had us adding a foreign key relationship between the Pet_MedicationSeries table and the Medication table, it stands to reason that we could leverage that relationship again, to create the below simpler query:
SELECT M.MedName, COUNT(P_MS.*) FROM Medication M JOIN Pet_MedicationSeries P_MS ON M.ID=P_MS.FK_Medication GROUP BY M.MedName
So, if we were to take into account that Feature #1 and Feature #2 were the most popular features in our database application, the above 2 use cases definitely suggest that it is probably worthwhile to add a foreign key relationship to the Pet_MedicationSeries table that references the Medication table; it may also be worthwhile to add a foreign key relationship from the Pet_MedicationSeries table to the Customer table, as well.
With the above assertions in mind, it's also to important to remember that denormalization is not always the appropriate thing to do. Just because there is an opportunity to denormalize in a database does not mean you should. Take the following considerations into account before denormalizing:
- Does denormalization buy you anything? If it doesn't save you development time, execution time, or design simplification, avoid it
- Is denormalization worth the tradeoff? Adding columns, indexes, and modifying the schema all have costs associated with them. Some of those costs are related to disk space, and some of those costs are related to business logic refactoring to deal with schema changes. Even if there is value in denormalizing, is the return on investment large enough to justify the costs.
- What denormalization buys you in query simplification, it may cost you in future maintenance. The new relationships that get introduced into your data model when denormalizing may not be particularly intuitive to those working with and developing on the database. A whole new layer of maintenance gets added with denormalization.
As I mentioned at the beginning of the article, denormalization is not a design strategy; it is a workaround. Therefore, denormalization should be used in an as-needed fashion, as to avoid some of the maintenance issues that arise with it. If you're finding that, even with the maintenance issues that denormalization brings, it is still appealing, then it probably makes sense to incorporate it.
If one chooses to denormalize, here are some rules to live by:
- Denormalize Deliberately: Don't do it on a whim, and don't do it without a fair amount of cost/benefit analysis
- Document: Ongoing maintenance of a denormalized system requires a great deal of documentation, because denormalizations are often not intuitive
- Wrap denormalization modifications into transactions: Put required denormalization modifications in the same place in the business logic as where existing business logic changes are made, and wrap the modifications into the same transaction. Then if a failure occurs, you don't have to worry about losing confidence in the viability of your denormalization.
There are a number of solutions to deal with complex design issues, and denormalization represents one of them. The modern database administrator should be aware of as many solutions as possible to know which one is right for their given situation. I hope that these words have helped to either solidify your existing knowledge, or add to your toolbox of possible performance optimizations.
