

One of the features that has been available in SQL Server for many versions it the ability to stripe a backup across multiple files. While some people do this inadvertenly, many choose to do this for a variety of reasons. This short article will show you how to set this up.
What is a Striped Backup?
A striped backup is simple a backup of your database that is spread across multiple files. Just like a database can exist in multiple .mdf and .ndf files, a striped backup places some of your backup data in one file, and some in another.
The distribution of the data is something SQL Server manages, but it tries to evenly balance the data across the files. However, just like in a filegroup that has multiple files, you don't know which data is in which files, and you need all of the files in order to restore the database.
The striped backup works like this. Imagine that I have a database that contains data. I've simplifie the image below to show data as a sentence and 0s as empty space.
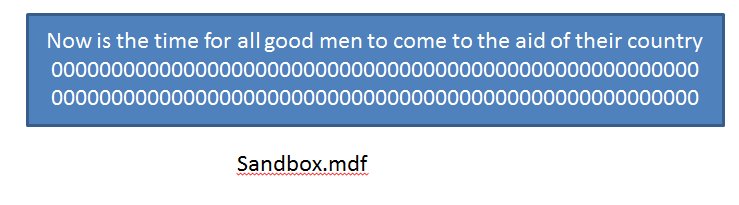
In reality, data is stored as pages, and those pages are what are copied to the backup file. There isn't necessarily an order or rhyme or reason to the order pages go into the backup file as it relates to data, so just understand that all data pages are copied to the backup file, but free space is not. This is shown below as the sentence copied to the backup file.

In a striped backup, we have multiple files for the backup. As shown below, some of our data goes to one file, and some goes to the other. In a SQL Server backup, this means that some pages are copied to one backup file, and some to another. In this image, I've shown every other page copied to each file.
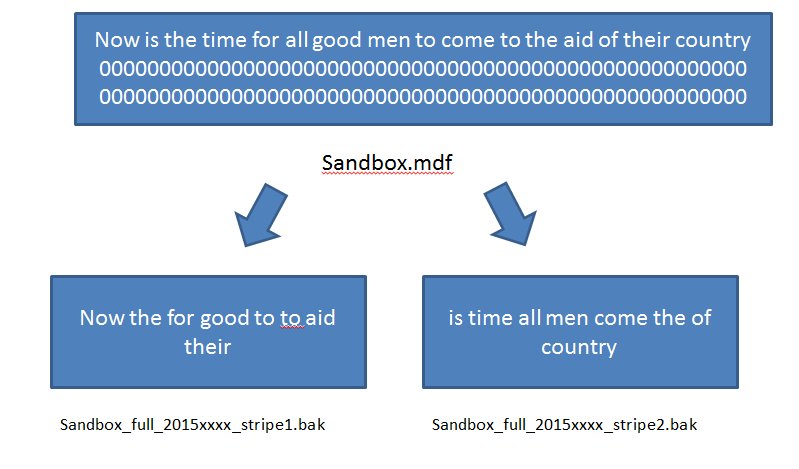
However, since my data might be stored on non contiguous pages, or otherwise separated, I could end up with a backup like this, or in any other format. The important thing to understand is that all my data (and schema and other objects in the database) are copied to the files completely. Nothing is left out, though some log records can be included.

As you can see, some of my data is in one file and some is in the other. The critical understanding that you should take away from this is that to reverse this process with a restore, I need all of the stripes of my backup. There is no RAID here where data is duplicated and we can lose one of our stripes. We need them all to perform a restore.
Note that I've named my files with "Stripex" in each image. I do this so that I am aware that this is a striped backup. You might want to even go so far as to name the files as "Stripe1_of_2" or "Stripe1_of_3", but since DBAs have edited the number of files in the past, I've found it to be a maintenance issue to be sure the file naming is changed as well.
Advantages of Striped Backups
One of the big advantages of striped backup is that the Operating System can use multiple threads to write out the data. If I have put different files on different physical drives, I can dramatically speed up the backup process and reduce the time it takes.
The other advantage is that I can split a large backup across multiple drives if I don't have a single drive large enouge to hold the entire backup.
Note: If you are looking for reasons why people do this, there are a few comments in the discussion for this editorial from your fellow SQL Server DBAs.
Disadvantages of Striped Backups
The main disadvantage of striped backups is that I need all the files to perform a restore. That might not sound like a big deal, but for each additional file I create, I increase the risk that something will happen to a file and I won't be able to restore my system.
If I have one file, then it's unlikely the file will become corrupt, or get lost on a crashed hard drive. If I have 20 files, on 20 drives or tapes, I have more chances that one of those files gets lost or corrupted. I highly recommend that you make multiple copies of each of these files and store them separately if you use striped backups. If I used 4 stripes, I'd make at least 3 copies of all four files, and I'd probably store each set of 4 on separate media.
Note that one of the advantages is fast restores, so I might keep one copy of my four files on separate drives for quick restores, but I'd be sure to move copies elsewhere.
How Do I Create a Striped Backup?
There are a number of ways. You can take the challenge below and try it on your own. If you'd like to see this done in SSMS or T-SQL, click the challenge link and view the text, or watch a video of the process.
The Challenge |
Create a database called "Sandbox" on one of your instances. Set up a striped backup that creates a full backup of "Sandbox" using two files. Name them with the database name, Stripexx where xx is the number of the stripe, and with the date. If you want to check yourself, or just learn how to do this, visit the DBA Skills - Creating a Striped Backup article. Take the Challenge |
Conclusion
Striped backup can provide some great speed benefits. Even on a single drive used for backups, multiple files can complete a backup faster. However if you use mutliple drives, you can dramatically reduce your backup time. A little experimentation will help yuo determine what works best in your environment.
As I showed above, creating a striped backup from SSMS is fairly simple. It's even easier from T-SQL, though you might find that any scripts you use for backups need modifications to account for drive differences on different machines, and possibly different numbers of stripes.
Many of the third party backup products, like SQL Backup Pro, use multiple threads to perform the same process, and then write all the data to a single file. If you extract, or convert, one of these compressed backups to native format, you often end up with a series of files, each one representing a separate process thread that created it. To restore, you'd perform a striped restore.
Hopefully this explains how you can easily build a striped backup in your SQL Server environment.


