

This article describes one approach to creating a complex database project in Visual Studio with SQL Server Data Tools (SSDT). This was for a group of databases that had defied more than one previous attempt at being successfully converted into working SSDT database project(s) by senior DBAs and developers proficient in their craft.
Background
We have a web product that is serviced by databases with a layout that looks something like this (databases renamed for illustration/security):
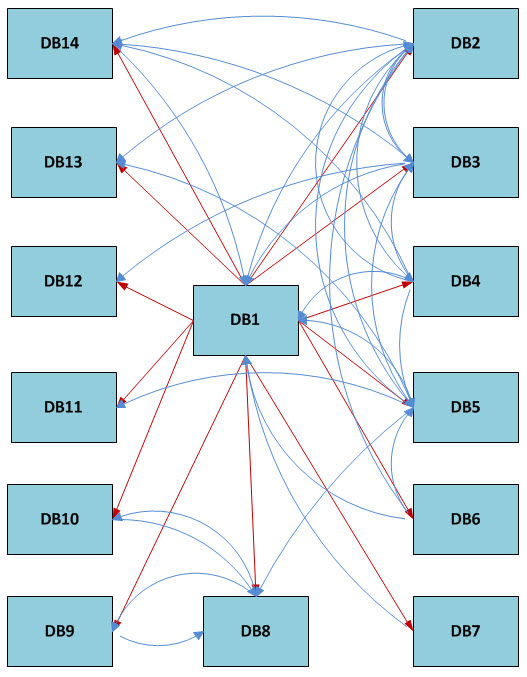
The system was probably not designed this way from the start. It evolved into this complex structure over more than a decade of conversions from one line of business to another and provisioning/appropriating of modules from other products to fulfill a functional need in the current product. Many of these components could probably be defined as legacy. The main database DB1 looks up (red arrows) objects in other databases via stored procedures, functions and views. Most of those databases also have similar references (blue arrows) into other databases, including back into DB1. Thus, there are numerous cross dependencies, ranging from dozens to hundreds of references from any given database into other databases.
Previous Attempts
For any database project to build and compile successfully in SSDT, all its references must exist and must be valid. For instance, if a stored procedure in DB1 is looking up table dbo.TTT in DB2, the SSDT project must be able to resolve the table DB2.dbo.TTT. Without it, the build will fail (with an error on missing objects). You could choose to suppress specific types of errors, but that is bad practice because if a genuine error of that type happens, the project will not alert you to it.
Previous attempts at creating a deployable database project for our product revolved around importing all these databases into SSDT. This never succeeded due to the sheer size and scope of the task. There were too many databases, references and dependencies. Visual Studio could never finish the import, it would keep churning for hours and eventually freeze or crash. I suspect even if it had managed to import all the objects, any development, build, and deployment actions on this project would have been too slow and cumbersome for it to have been of practical use.
Our established company standard for working with database development and deployment is to use SSDT projects. Until this point in time, we had been unable to use SSDT for this product. We had to resort to using a combination of Redgate tools (SQL/Schema Compare, Data Compare, and Source Control) to accomplish this. However, we really wanted to be able to take advantage of SSDT, because among other benefits, Visual Studio is an environment our application developers are more comfortable with than SSMS or Redgate tools. Also, automating product deployment for our teams was far easier with Visual Studio than anything else. So how did we accomplish this?
Solution
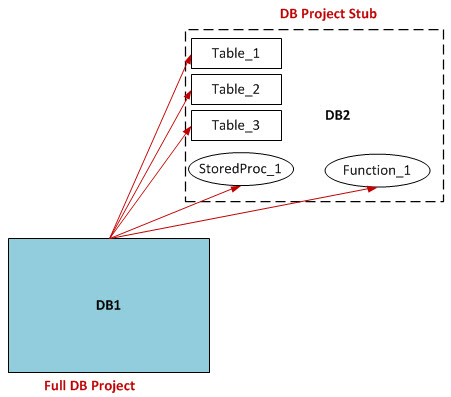
Let's take a closer look at just two databases in our layout: DB1 and DB2. The relationship between them looks like this:
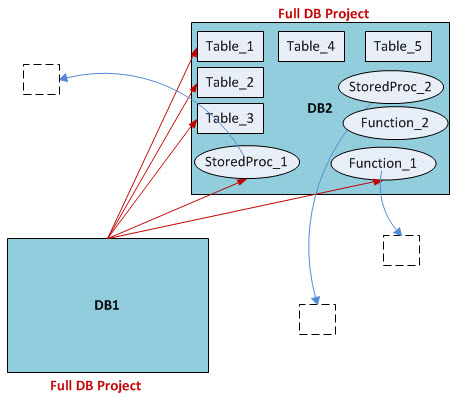
There are references from DB1 to DB2 (red), and references from DB2 to other databases (blue). The condition that all references had to exist had so far pushed a SSDT project out of reach. However, I had an epiphany one day. What if I created a project only to deploy DB1? And what if I gave it only those objects from DB2 that it needed to resolve references, and nothing more? From the above image, DB1 only needs Table1, Table2, Table3, StoredProc1 and Function1 from DB2. It has no need for Table4, Table5, StoredProc2 and Function2. This would greatly reduce the number of objects and references in the project. I reasoned that the number of references would still be large enough to cause performance issues in the DB1 project, so I created a separate solution and project for DB2. This project would only have DB2 objects in it, and only those objects needed by DB1, as follows:
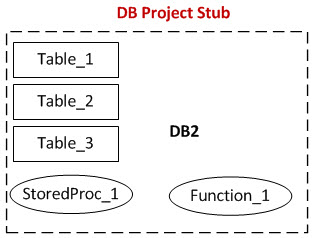
Although the DB2 project was technically sound in that it built and deployed without error, it only had table definitions without any table data. Also, any stored procedures and functions in DB2 were empty shells. There was no need for them to have the real code, just as long as the signature met the requirements that the reference from DB1 was looking for, and it was syntactically valid. So my DB2 objects looked like this:
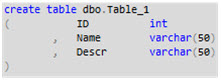
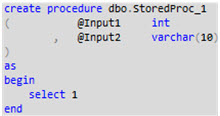
Remember, this project is not intended to deploy DB2 from. It is only meant to be a reference resolution instrument for DB1. I built the DB2 project successfully, thus creating a dacpac file from it. Once I had this dacpac, I copied it at the OS file level into a folder in my main project, DB1. Then, I added a database reference (right-click "References") inside the DB1 project to DB2.dacpac. Alternatively, I could have added a database reference from DB1 directly into the DB2 project location, but I wanted to avoid that dependency. I wanted very loose coupling between DB1 and DB2. At this point, my DB1 project looked conceptually like this:
Next, I repeated my process of building the DB2 dacpac file for each of the other databases, and similarly imported and referenced all those dacpacs from DB1. I ended up with a DB1 project that had the following layout:
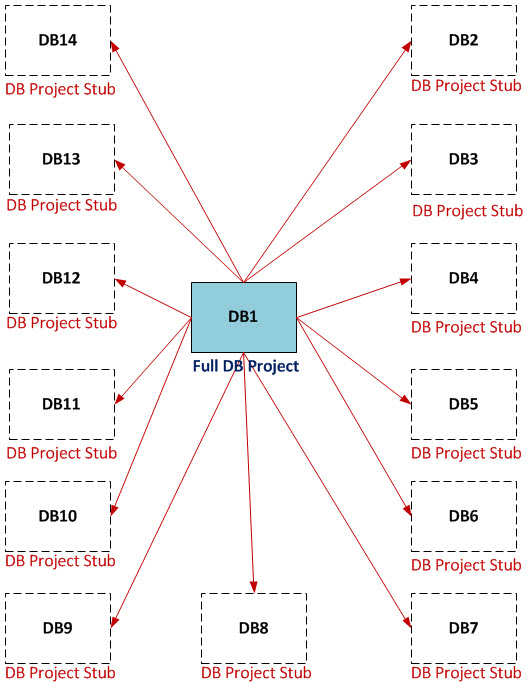
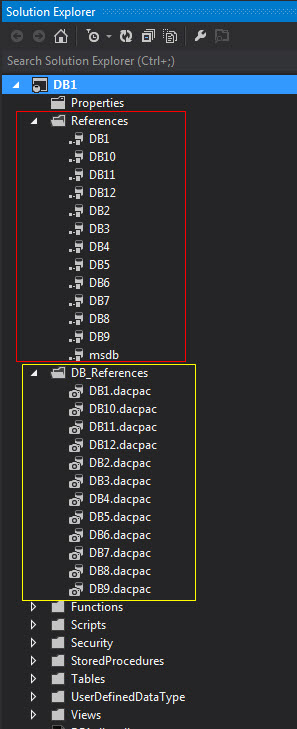
Note that the references are now only one-way, going from DB1 into other databases. There are no references from those other databases going anywhere else. The Solution Explorer looks like this:
And finally, the goal of this exercise, a DB1 project that successfully builds and allows deployment:
The majority of our database development is done on DB1, so this is really the only project we need for the time being. If the developers want to push any changes to any of the other databases, I will just repeat the above process for that database and create a separate deployable project. Granted that this would require several projects instead of one, but it allows us to go back to company standards and use SSDT for this complex database layout.

