

Introduction
These data types – TEXT, NTEXT, and IMAGE – have been part of SQL Server since its earliest versions, designed to store large objects like documents, HTML, and binary data when there was no better alternative. However, starting from SQL Server 2005, Microsoft officially deprecated them in favour of the more versatile VARCHAR(MAX), NVARCHAR(MAX), and VARBINARY(MAX) types. Despite this clear shift almost two decades ago, I still see these legacy types widely used in production systems today—and even in new developments. Surprisingly, many developers continue to use them, either out of habit, lack of awareness, or simply because they copy existing patterns without questioning their relevance.
In this tutorial, I want to explain why I strongly emphasise upgrading away from these data types. Over time, I have uncovered almost all their weaknesses, quirks, and limitations through extensive practical testing across multiple environments. Some of these behaviours are well‑documented by Microsoft, while others remain hidden and undocumented, surfacing only during real‑world troubleshooting of edge cases. This article is a consolidated one‑place guide where I share these insights, motivate you to plan your migration, and help you understand why these seemingly harmless data types are silent blockers to your performance, maintainability, and future SQL Server upgrades.
The Hidden Limitations: A Practical Walkthrough of TEXT, NTEXT, and IMAGE
Limitation #1 – Deprecated since SQL Server 2005
Microsoft officially deprecated TEXT, NTEXT, and IMAGE data types starting with SQL Server 2005. This means while they continue to work, they are in maintenance mode only, with no further enhancements or compatibility improvements. Their removal in a future version is always a possibility, making them unsuitable for any long-term or strategic database design.
Limitation #2 – Text column cannot be in INCLUDE columns
One critical limitation of these legacy data types is their complete incompatibility with the INCLUDE clause in nonclustered indexes. SQL Server explicitly prohibits using TEXT, NTEXT, or IMAGE types as INCLUDE columns. When you attempt to create an index with these data types in the INCLUDE list, SQL Server immediately throws an error stating that the column is invalid for use as an included column in an index. This restriction removes a powerful optimisation strategy from your toolbox because it prevents queries from becoming fully covered when they reference such columns.
Let’s demonstrate this with a practical example:
DROP TABLE IF EXISTS dbo.Test_Text_Index;
GO
CREATE TABLE dbo.Test_Text_Index (
Id INT IDENTITY PRIMARY KEY,
DataText TEXT
);
GO
Let's try to create a non clustered column by including Datatext by running below command.
CREATE NONCLUSTERED INDEX IX_Test_Text_Include ON dbo.Test_Text_Index (Id) INCLUDE (DataText); GO
Trying to include Datatext column in non-clustered throws below error:
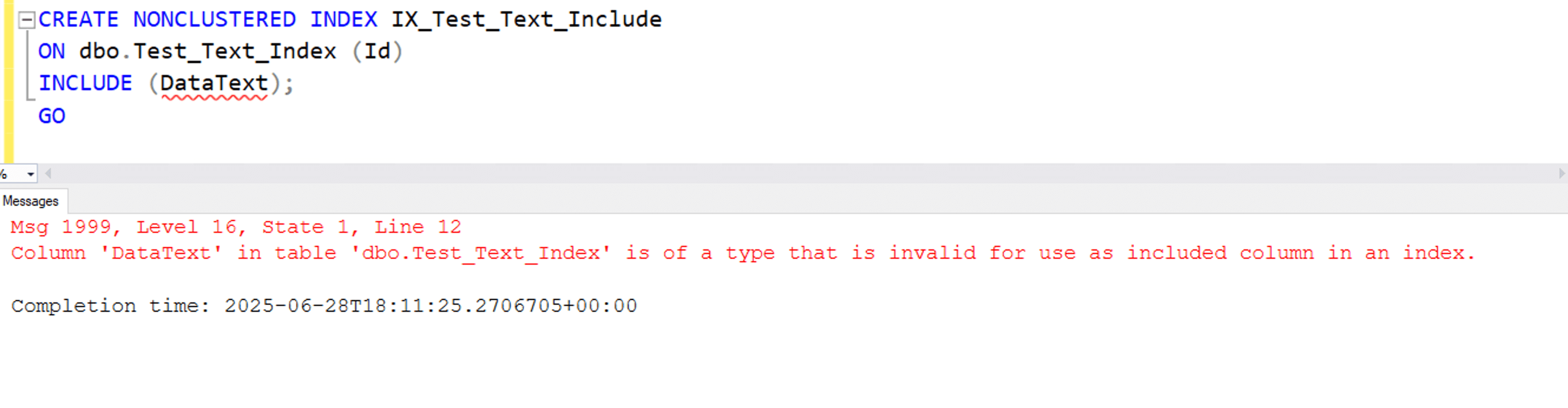
Limitation #3 – Cannot be index key columns
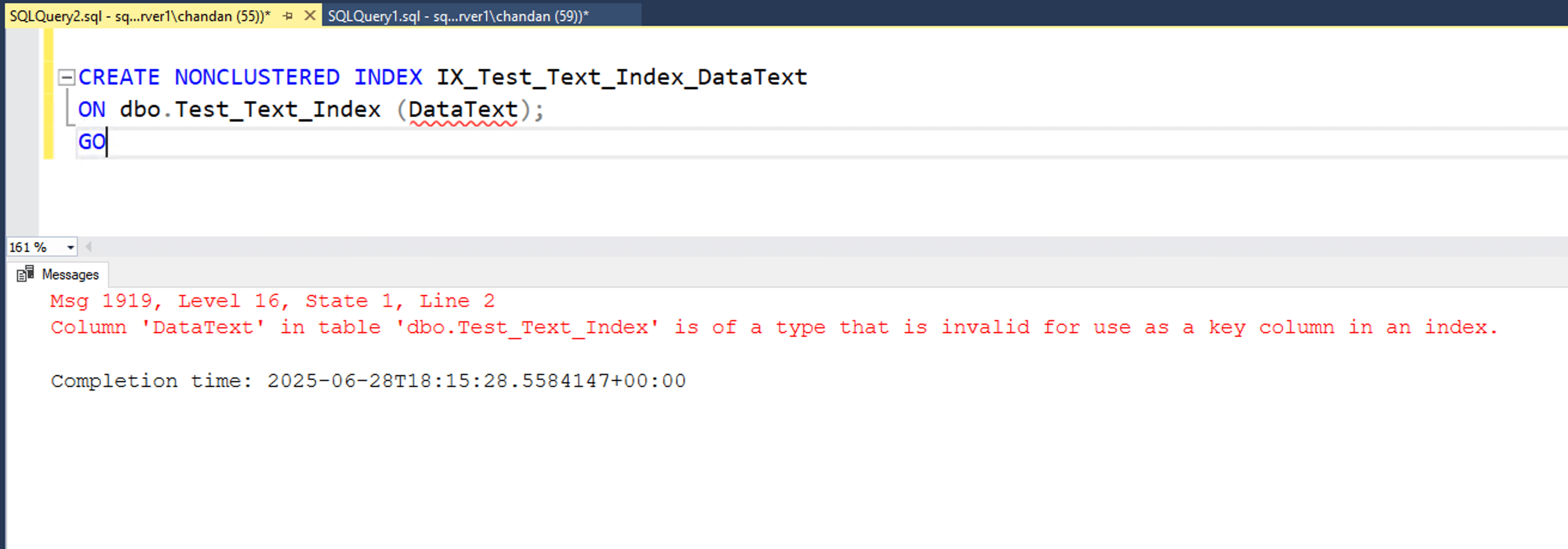
Another blocker: You cannot create an index with these data types as key columns. If you attempt to do so, SQL Server will throw an error stating the data type is invalid for index keys. This limits their use in WHERE clause filtering, seek operations, or query optimisation strategies that depend on indexing.
Let's run the below query to check the same
CREATE NONCLUSTERED INDEX IX_Test_Text_Index_DataText ON dbo.Test_Text_Index (DataText); GO
This throws below error:
Limitation #4 – Blocks online index rebuild
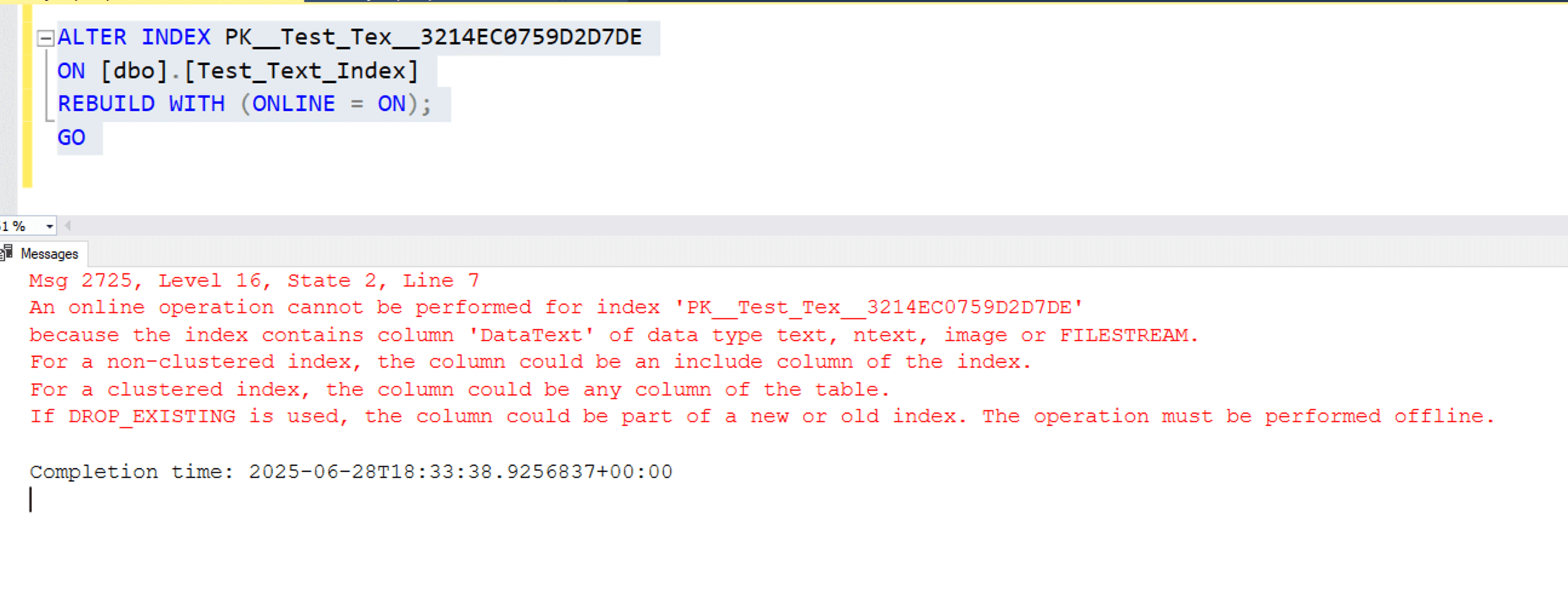
Tables containing text, ntext, or image columns cannot perform online index rebuilds. Even if these columns are not part of the index key, their presence in the table blocks online operations for clustered indexes. As a result, any rebuild must be done offline, which can lock the table and impact availability during maintenance. The screenshot shows an attempt to rebuild an index online on a table with a text column, resulting in error Msg 2725. SQL Server clearly states that online rebuilds are unsupported for indexes containing these legacy data types.
Limitation #5 – Standard string functions unsupported
Standard string functions such as LEN, LEFT, RIGHT, or direct concatenation cannot be used on TEXT, NTEXT, or IMAGE columns. You are forced to use the legacy READTEXT function to read portions of data, which is cumbersome and unfamiliar to most modern developers.
SELECT LEN(DataText) AS TextLength FROM dbo.Test_Text_Index -- Error SELECT LEFT(DataText, 5) AS LeftPart FROM dbo.Test_Text_Index. -- Error SELECT RIGHT(DataText,5) AS TextLength FROM dbo.Test_Text_Index -- Error SELECT DataText + 'Z' AS Concatenated FROM dbo.Test_Text_Index; -- Error
For getting it working we need to cast it to varchar(max) which is a costly operation on large data.
SELECT LEN(CAST(DataText AS VARCHAR(MAX))) AS TextLength FROM dbo.Test_Text_Index; --- Success
SELECT LEFT(CAST(DataText AS VARCHAR(MAX)), 5) AS LeftPart FROM dbo.Test_Text_Index; -- Success
SELECT RIGHT(CAST(DataText AS VARCHAR(MAX)), 5) AS RightPart FROM dbo.Test_Text_Index; -- Success
SELECT CHARINDEX('Chandan', CAST(DataText AS VARCHAR(MAX))) AS Position FROM dbo.Test_Text_Index; -- SuccessLimitation #6 – Requires READTEXT, WRITETEXT, UPDATETEXT
As we understood normal string functions could not be used in text and ntext columns, manipulating these data types requires specialised functions like READTEXT, WRITETEXT, and UPDATETEXT. Unlike simple UPDATE or string manipulation on MAX types, these commands introduce complex syntax and operational risk if not used carefully.
Alternative: Using READTEXT to read part of text column DECLARE @ptrval binary(16); SELECT @ptrval = TEXTPTR(DataText) FROM dbo.Test_Text_Index WHERE Id = 1; -- Read first 20 bytes READTEXT dbo.Test_Text_Index.DataText @ptrval 0 20; -- Result: -- Returns first 20 bytes (for text, bytes = characters) Using UPDATETEXT to insert data DECLARE @ptrval binary(16); SELECT @ptrval = TEXTPTR(DataText) FROM dbo.Test_Text_Index WHERE Id = 1; UPDATETEXT dbo.Test_Text_Index.DataText @ptrval 10 0 'ZZZ'; -- Inserts 'ZZZ' at byte offset 10 -- Using WRITETEXT to overwrite entire value DECLARE @ptrval binary(16); SELECT @ptrval = TEXTPTR(DataText) FROM dbo.Test_Text_Index WHERE Id = 1; WRITETEXT dbo.Test_Text_Index.DataText @ptrval 'Completely new text value.'; -- Replaces entire DataText content
Limitation #7 – Cannot use LIKE directly
While it may appear that LIKE works on text columns, there is a tricky limitation:
If the text value is less than or equal to 8000 characters, LIKE evaluates as expected because SQL Server implicitly converts it to varchar(8000) for comparison.
However, if the text value exceeds 8000 characters, SQL Server only evaluates the first 8000 characters, silently ignoring the remainder. This makes pattern searches unreliable for large data.
SELECT * FROM dbo.Test_Text_Index WHERE DataText LIKE '%Chandan%'; --- Only returns for the rows where length of Datatext value is less than 8000 bytes
You cannot directly use LIKE on these data types. To perform all pattern searches, you first need to CAST them as below to a supported type such as VARCHAR(MAX) within the query, which adds overhead and complexity.
SELECT * FROM dbo.Test_Text_Index WHERE CAST(DataText AS VARCHAR(MAX)) LIKE '%Chandan%'; -- Works irresptive of length with additional cost
Limitation #8 – DATALENGTH has quirks due to off-row storage
While DATALENGTH is often used to check the size of string columns, it behaves very differently for legacy text data types. With varchar(max), DATALENGTH simply returns the number of bytes in the value, executing quickly even for large data because SQL Server can read the value directly. However, for text, ntext, and image types, the situation is trickier. These columns are stored off-row as separate LOB pages linked via pointers. When you run DATALENGTH on a text column, SQL Server must traverse the entire LOB page chain to compute the total byte size. On small tables, this overhead might go unnoticed, but in production systems with millions of rows or large LOB values, it can result in table scans with high IO and CPU costs. I have seen simple DATALENGTH-based filters on text columns bring servers to their knees, especially when used in WHERE clauses without appropriate indexing or row filters. This is yet another reason why migrating to varchar(max) eliminates such hidden performance traps and simplifies query behaviour in modern SQL Server environments.
-- Using DATALENGTH on text SELECT DATALENGTH(DataText) AS TextBytes FROM dbo.Test_Text_Index; -- Forces traversal of entire LOB chain for each row -- Using DATALENGTH on varchar(max) SELECT DATALENGTH(DataText) AS TextBytes FROM dbo.Test_Varchar_Index; -- Direct evaluation; minimal IO even on large values
Limitation #9 – Not allowed as local variables
You cannot declare TEXT, NTEXT, or IMAGE as Local Variables
DECLARE @SampleText TEXT; GO
This throws below error:

Limitation #10 – No computed column support
These data types cannot be used in computed columns. Any attempt to create a computed column referencing them will result in an error, further limiting schema design flexibility.
ALTER TABLE dbo.Test_Text_Computed ADD UpperData AS UPPER(DataText); -- Error GO ALTER TABLE dbo.Test_Text_Computed ADD UpperData AS UPPER(cast(DataText as varchar(MAX))); -- Success with additional cost GO
Limitation #11 – Incompatible with many newer features
text, ntext, and image types are not just deprecated – they actively block modernisation. For example, JSON functions like OPENJSON, JSON_VALUE, and ISJSON do not work directly on these columns, forcing extra CAST operations and complicating queries.
Although OPENJSON may appear to work with TEXT columns in some cases, Microsoft does not guarantee support or consistency across versions. Always CAST to NVARCHAR(MAX) for robust behaviour.
Please find result of testing json functions with text column below.
We created a table with text column and then inserted some data in json format.
-- Create text table
CREATE TABLE dbo.Test_Text_JSON (
Id INT IDENTITY PRIMARY KEY,
DataText TEXT
);
GO
-- Insert JSON into text
INSERT INTO dbo.Test_Text_JSON (DataText)
VALUES ('{"Name":"Chandan","Role":"Data Engineer"}');
GONow we tested all three functions with text and nvarchar(max) coversion and below were the results.
SELECT * FROM OPENJSON((SELECT DataText FROM dbo.Test_Text_JSON WHERE Id = 1)); -- Success, but not recommended by Microsoft use json on text column SELECT ISJSON((SELECT DataText FROM dbo.Test_Text_JSON WHERE Id = 1)) AS IsJsonResult; -- Error SELECT ISJSON((SELECT cast(DataText as nvarchar(max)) FROM dbo.Test_Text_JSON WHERE Id = 1)) AS IsJsonResult; -- Success, but incurs additional cost due to conversion SELECT JSON_VALUE((SELECT DataText FROM dbo.Test_Text_JSON WHERE Id = 1), '$.Name') AS NameValue; -- Error SELECT JSON_VALUE((SELECT cast(DataText as nvarchar(max)) FROM dbo.Test_Text_JSON WHERE Id = 1), '$.Name') AS NameValue; -- Success, but incurs additional cost due to conversion
How to Update or Migrate TEXT, NTEXT, and IMAGE Columns
Upgrading away from TEXT, NTEXT, and IMAGE is not only a recommended best practice – it is often straightforward and brings immediate benefits to your database operations.
For TEXT columns:
Convert them to VARCHAR(MAX).
For NTEXT columns:
Convert them to NVARCHAR(MAX).
For IMAGE columns:
Convert them to VARBINARY(MAX).
Best practices while migrating:
Test conversions in development environments first to ensure your application code, stored procedures, or views referencing these columns continue to work seamlessly.
Update integration pipelines or SSIS packages if they specifically use legacy functions like READTEXT or WRITETEXT.
Refactor code to replace deprecated commands with normal UPDATE, string functions, or modern binary manipulation functions.
Monitor performance post-migration. You will likely see reduced query complexity and improved maintainability.
Summary
In this article, I shared practical demonstrations of why TEXT, NTEXT, and IMAGE data types – despite working for decades – are silent blockers in modern SQL Server environments. From their inability to support standard string functions, indexing limitations, and rebuild restrictions to operational complexities , these legacy types bring hidden risks and unnecessary technical debt.
If you still have these types in your schemas today, this is recommended to plan their migration. Moving to VARCHAR(MAX), NVARCHAR(MAX), or VARBINARY(MAX) will simplify your code, improve compatibility with newer SQL Server features, and make your systems easier to maintain for years to come.
Retaining these types risks future upgrade failures, blocked feature adoption, and hidden performance bottlenecks. Modernising them is not just technical debt cleanup; it is a strategic investment.
Have you encountered performance or upgrade issues due to these data types? Share your experiences in the comments – your lessons can help others plan their migrations effectively.