

Creating a stored procedure is easy. Writing a well performing stored procedure can be a challenge. Application developers are taught specific patterns for writing efficient, easily maintainable code. Patterns like: an overarching routine should perform a series of steps and compartmentalizing code will allow for reusability. These patterns create a top-down approach to writing code, but it may not be the best pattern for writing T-SQL. Let’s take a look at how each of these patterns can affect a stored procedure in this series.
An overarching routine should perform a series of steps
I’ve seen many stored procedures in the wild that have many separate SQL statements that walk through a logical set of steps. They are gathering data from many tables, massaging the data, and finally outputting a result set. Great! That is what stored procedures are supposed to be used for, but what about the methodology used to create the stored procedure?
Creating a series of SQL statements within the stored procedure that finally creates a result set to be returned can lead to performance problems that can be hard to uncover. Why? The optimizer doesn’t optimize the stored procedure as a whole unit, but at the individual SQL statement level. If there are four discrete SQL statements in a stored procedure, then there are four execution plans created and used every time the stored procedure is used.
Here are some examples.
- Running small queries and inserting the results in temp tables to be used later in the stored procedure. One execution plan will be created and executed for each of these.
- Running small queries and inserting a single value in a variable to be used later in the stored procedure. One execution plan will be created and executed for each of these.
- Using a cursor to perform one or N actions on each row in the cursor. One execution plan for the cursor will be created, plus N execution plans are created for each of the actions. The N execution plans will be executed for each row that is cycled through in the cursor, plus the execution plan for the cursor itself will also be executed.
These types of patterns are not bad, they just shouldn’t be used right out of the gate. They are useful in the correct situation. There are however, some other solutions that can be used with or in lieu of these patterns.
- Instead of using a temp table, use a sub query, in-line table function, or common table expression. These solutions will reduce the number of execution plans and allow the query optimizer to determine the best way to obtain the data from the tables used through set based logic.
- Instead of using a single SQL statement to generate a single value for a variable, use a sub query with cross apply.
- Instead of using a traditional cursor, consider windows functions, joining to a tally table, in-line table functions, or a recursive common table expression.
- Use a single query and allow the optimizer to pick the best plan.
Let’s take a look at a stored procedure written four different ways. These stored procedures return the customer count for each employee in a particular territory group. The first stored procedure is using a temporary table to count all the customers per employee. Then the temporary table is joined to the other tables and filtered on the territory group.
ALTER PROCEDURE [dbo].[SalesTeamAssignment_rpt1] (@Group AS NVARCHAR(50))
AS
SELECT
COUNT(c.StoreID) AS CustomerCount
,c.StoreID
INTO
#TempCustCount
FROM
Sales.Customer AS c
GROUP BY
c.StoreID;
SELECT
p.BusinessEntityID
,p.FirstName
,p.LastName
,s.Name AS Store
,st.[Group] AS TerritoryGroup
,cr.Name AS CountryRegion
,st.Name AS Territory
,tcc.CustomerCount
FROM
sales.salesperson AS sp
JOIN Person.Person AS p ON sp.BusinessEntityID = p.BusinessEntityID
JOIN sales.SalesTerritory AS st ON sp.TerritoryID = st.TerritoryID
JOIN Person.CountryRegion AS cr ON st.CountryRegionCode = cr.CountryRegionCode
JOIN Sales.Store AS s ON s.SalesPersonID = sp.BusinessEntityID
LEFT JOIN #TempCustCount AS tcc ON tcc.StoreID = s.BusinessEntityID
WHERE
st.[Group] = @Group;
DROP TABLE #TempCustCount;
GO
The second stored procedure uses an OUTER APPLY with a subquery to join the customer counts to the other tables.
ALTER PROCEDURE [dbo].[SalesTeamAssignment_rpt2] (@Group AS NVARCHAR(50))
AS
SELECT
p.BusinessEntityID
,p.FirstName
,p.LastName
,s.Name AS Store
,st.[Group] AS TerritoryGroup
,cr.Name AS CountryRegion
,st.Name AS Territory
,c.CustomerCount
FROM
sales.salesperson AS sp
JOIN Person.Person AS p ON sp.BusinessEntityID = p.BusinessEntityID
JOIN sales.SalesTerritory AS st ON sp.TerritoryID = st.TerritoryID
JOIN Person.CountryRegion AS cr ON st.CountryRegionCode = cr.CountryRegionCode
JOIN Sales.Store AS s ON s.SalesPersonID = sp.BusinessEntityID
OUTER APPLY
( SELECT
COUNT(c.StoreID) AS CustomerCount
FROM
Sales.Customer AS c
WHERE
c.StoreID = s.BusinessEntityID) AS c
WHERE
st.[Group] = @Group;
GOThe third stored procedure uses a sub query with a LEFT JOIN. The table on the right of the join is a subquery that contains all the counts of the stores.
ALTER PROCEDURE [dbo].[SalesTeamAssignment_rpt3] (@Group AS NVARCHAR(50))
AS
SELECT
p.BusinessEntityID
,p.FirstName
,p.LastName
,s.Name AS Store
,st.[Group] AS TerritoryGroup
,cr.Name AS CountryRegion
,st.Name AS Territory
,c.CustomerCount
FROM
sales.salesperson AS sp
JOIN Person.Person AS p ON sp.BusinessEntityID = p.BusinessEntityID
JOIN sales.SalesTerritory AS st ON sp.TerritoryID = st.TerritoryID
JOIN Person.CountryRegion AS cr ON st.CountryRegionCode = cr.CountryRegionCode
JOIN Sales.Store AS s ON s.SalesPersonID = sp.BusinessEntityID
LEFT JOIN
( SELECT
COUNT(c.StoreID) AS CustomerCount
,c.StoreID
FROM
Sales.Customer AS c
GROUP BY
c.StoreID
) AS c ON c.StoreID = s.BusinessEntityID
WHERE
st.[Group] = @Group;
GOFinally, the fourth query joins all the tables together directly and then uses a GROUP BY to obtain the customer counts.
ALTER PROCEDURE [dbo].[SalesTeamAssignment_rpt4] (@Group AS NVARCHAR(50))
AS
SELECT
p.BusinessEntityID
,p.FirstName
,p.LastName
,s.Name AS Store
,st.[Group] AS TerritoryGroup
,cr.Name AS CountryRegion
,st.Name AS Territory
,COUNT(c.StoreID) AS CustomerCount
FROM
sales.salesperson AS sp
JOIN Person.Person AS p ON sp.BusinessEntityID = p.BusinessEntityID
JOIN sales.SalesTerritory AS st ON sp.TerritoryID = st.TerritoryID
JOIN Person.CountryRegion AS cr ON st.CountryRegionCode = cr.CountryRegionCode
JOIN Sales.Store AS s ON s.SalesPersonID = sp.BusinessEntityID
LEFT JOIN Sales.Customer AS c ON c.StoreID = s.BusinessEntityID
WHERE
st.[Group] = @Group
GROUP BY
p.BusinessEntityID
,p.FirstName
,p.LastName
,s.Name
,st.[Group]
,cr.Name
,st.Name;
GOWhen I ran all four of these stored procedures, I captured the duration, CPU usage, and the number of reads. Here are my findings.
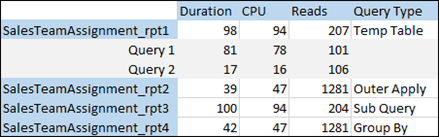
Since the first stored procedure has two separate SQL statements, there are two execution plans. The first is for the temporary table and the second is for the query that returned the results. The other stored procedures only have one query and thus only one execution plan.
The first and third stored procedures performed about the same and the second and fourth stored procedures performed about the same, but let’s dig a little deeper to learn more about what we are seeing here. The first and third stored procedures are off by 3 reads. Why is that? Those three extra reads are from reading the data from the temporary table in the second query. This particular temporary table was small, but a large temporary table could have a serious impact on the number of reads.
The first and the third stored procedure have significantly fewer reads than the second and fourth stored procedures, but the second and fourth stored procedures take half as much CPU and less than half as much time to run. For most environments, having faster stored procedures and reducing any potential CPU pressure is more important than the number of reads.
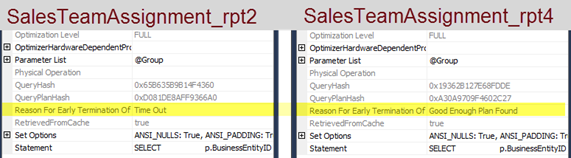
So which stored procedure should I use? There is one last piece of information that will help with that answer. When you look at the execution plan for each query, you can look at additional properties for each operator in the plan. If you look at the properties for the SELECT operator, you can find out if there was enough time to generate a good plan. For the second stored procedure (shown on the left below), the optimizer ran out of time, so it selected the best plan out of the ones it considered. For the fourth stored procedure (shown on the right below), there was enough time to pick a good plan. This is denoted by the phrase “Good Enough Plan Found”.
Conclusion
In this example we were able to show that breaking up a stored procedure into logical steps, was not the best solution. The best solution, was allowing the optimizer to use set theory and its powerful engine to pick the best plan to return the data we need.
