Much as we would like to avoid it, some discussion of the internal structure of the transaction log, and the internal processes that work on it, is very helpful in understanding the appropriate log maintenance techniques. This topic is well-covered in the literature, the article Understanding Logging and Recovery in SQL Server by Paul Randal, and the book SQL Server 2008 Internals by Kalen Delaney, being two very good examples, so we will keep things brief here.
Virtual Log Files
Transaction log files are sequential files; in other words SQL Server writes to the transaction log sequentially (unlike data files, which tend to be written in a random fashion, as data is modified in random data pages).
Storage Considerations
The different manner in which data and log files are written means that they also have different storage considerations, for example in regard to the appropriate RAID configuration for the disk drives that store each type of file. This is discussed in Level 11.
Each log record inserted into the log file is stamped with a Logical Sequence Number (LSN). When a database and its associated log file are first created, the first log record marks the start of the logical file, which at this stage will coincide with the start of the physical file. The LSNs are then ever-increasing; the most recently-added log record will always have the highest LSN, and marks the end of the logical file (discussed in more detail shortly). All log records associated with a given transaction are linked in an LSN chain with forward and backward pointers to the operation in the transaction that succeeded and preceded the current operation.
Internally, SQL Server divides a transaction log file into a number of sections called virtual log files (VLFs). Figure 1 depicts a transaction log composed of eight VLFs, and marks the active portion of the log.
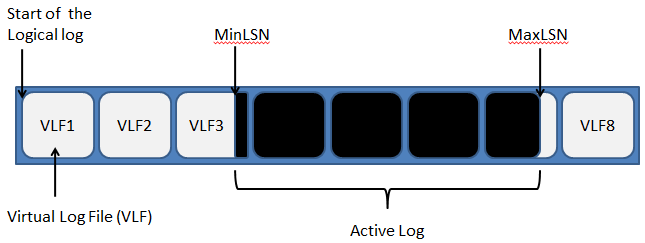
Figure 2.1: A transaction log with 8 VLFs
As discussed in Level 1, any log record relating to an open transaction is required for possible rollback. In addition, there are various other activities in the database (including replication, mirroring and Change Data Capture) that use the transaction log and need transaction log records to remain around until they have been processed. The log record with the MinLSN, shown in Figure 2.1, is defined as the "oldest log record that is required for a successful database-wide rollback or by another activity or operation in the database". This is sometimes referred to as the 'head' of the log.
Reasons for a log record to be active
There are a number of reasons in addition to being part of an active transaction that can keep a log record active. These will be discussed in more detail in a future stairway level. For now it is sufficient to say that if a log record is needed for any operation or activity, that log record is active and as such the VLF it is part of is active.
The most-recent log record will always have the highest LSN, denoted in Figure 2.1 by MaxLSN, and this marks the logical end of the log. All subsequent records are written to the logical end of the log. The portion of the file between the MinLSN record and the logical end of the log is called the active log.
It's important to note that the active log does not contain just details of 'active' (i.e. open) transactions. For example, consider a case where the MinLSN is defined by a log record for an open transaction (T1) that started at 9.00 AM and takes 30 minutes to run. If a subsequent transaction (T2) starts at 9.10 AM and finishes at 9.11 AM, it will still be part of the active log, since the LSN of the related log records will be greater than MinLSN. At 9.30 AM, when T1 commits, the new MinLSN may be defined by a log record for an open transaction (T3) that started at 9.25 AM. At this point the log records for T2 will no longer be part of the active log.
Any VLF that contains any part of the active log is considered an active VLF. For example, VLF3, in Figure 2.1, is an active VLF, even though most of the log records it contains are not part of the active log. As transactions start and are committed, we can imagine (somewhat simplistically) the head of the log moving left to right across Figure 2.1, so that VLFs that previously contained part of the active log now become inactive (VLFs 1 and 2), and VLFs that were previously untouched (VLF8) will become part of the active log.
What happens to mark a VLF "inactive" depends on the recovery model being used for the database, as we'll discuss next.
Log Truncation and Space Reuse
A very important point to note here is that the smallest unit of truncation in the log file is not the individual log record or log block, but the VLF. If there is just one log record in a VLF that is still part of the active log, then the whole VLF is considered active and cannot be truncated.
Broadly speaking, a VLF can be in one of two physical states: active or inactive. However, based on the possible different 'behaviors' of a VLF we can identify four logical states:
- Active – a VLF is this state is active as it contains at least one log record that is part of the active log, and so is required for rollback, or other purposes
- Recoverable – a VLF is this state is inactive but not truncated or backed up. Space cannot be reused
- Reusable – a VLF is this state is inactive. It has been truncated or backed up and space can be reused
- Unused – a VLF is this state is inactive; no log records have ever been recorded in it
The act of marking a VLF as inactive – in terms of our logical states, this means switching from state 2 to state 3 – is known as log truncation.
When this truncation occurs depends on the recovery model in use. When a database is in the SIMPLE recovery model, an active VLF can be made inactive by the occurrence of the checkpoint process. When the checkpoint occurs, any dirty pages in cache are flushed to disk and then the space in the log is made available for reuse.
However, in the FULL or BULK LOGGED models, only a log backup can change an active VLF to inactive.In this case, once the log backup has backed up the log it marks any VLFs that are no longer necessary as inactive and hence reusable.
In Figure 2.2, we can see that as a result of a checkpoint (or log backup), VLF1 and VLF2 have been truncated and are inactive. The start of the logical log is now the start of VLF3. VLF8 has still never been used and hence is still inactive (state 4).
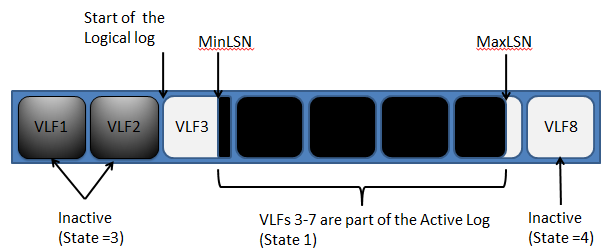
Figure 2.2: A transaction log with 8 VLFs, after truncation.
The next question to consider is what happens when the active log reaches the end of VLF7. It's easiest to think of space in the log file as being reused in a circular fashion, though there are complicating factors that can sometimes make space reuse patterns seems rather arbitrary, and which we're not going to delve deeper into in this Stairway.
Nevertheless, in the simplest case, once the logical end of the log reaches the end of a VLF, SQL Server will start to reuse the next sequential VLF that is inactive. In Figure 1, this would be VLF8. With VLF8 full, it will wrap around and reuse VLFs 1 and 2. If no further VLFs were available at all, the log would need to auto-grow and add more VLFs. If this is not possible, due to auto-growth being disabled or the disk housing the log file being full, then the logical end of the active log will meet the physical end of the log file, the transaction log is full, and the 9002 error will be issued.
This architecture explains the reason why, for example, a very long-running transaction, or a replicated transaction that for some reason has not been dispatched to the distribution database, or a disconnected mirror, among others, can cause the log to grow very large. For example, consider that in Figure 2.2, the transaction associated with the MinLSN is very long running. The log has wrapped around, filled up VLFs 1, 2 and 8, and there are no more inactive VLFs. Even if every transaction that started after the MinLSN one has committed, none of the space in these VLFs can be reused, as all the VLFs are still part of the active log.
We can see this in action quite easily. First, rerun Listing 1.1 to drop and recreate the TestDB database. Then create a small sample table, update one of the rows in the table within an explicit transaction, and leave the transaction open (do not COMMIT it). In a second tab within SSMS, run the scripts in Listings 1.2 to 1.4. This time you should see that space is not made available for reuse after the log backup. However, if you then commit the transaction and rerun the log backup, it will be.
For convenience, the relevant code files from Level 1 are incuded in the code for this Stairway - see the links at the end of the article.
In such cases, where the "area" occupied by the active log is very large, with a lot of space that is not reusable, at some point, the log file will have to grow in size (and grow, and grow…). Other factors that can delay the truncation of the log file will be discussed in Level 8 – Help, my log is full.
Too many VLFs?
In general, SQL Server decides the optimum size and number of VLFs to allocate. However, a transaction log that auto-grows frequently, in small increments will have a very large number of small VLFs. This phenomenon is known as log fragmentation and we can see it in action, to some extent, by repeating the simple example from Level 1, while interrogating the VLF architecture using a command called DBCC LogInfo. For convenience the scripts required for this example are included as downloadable files (see the end of this Level).
Interrogating VLFs using DBCC LogInfo
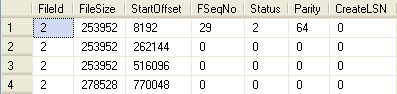
DBCC LogInfo is an undocumented and unsupported command – at least there is very little written about it by Microsoft. However, it can be used to interrogate VLFs. It returns one row per VLF and, among other things, indicates the Status of that VLF. A Status value of 0 indicates that the VLF is usable (in state 3 or 4), as described above, and a Status value of 2, indicates that it is not usable (in state 1 or 2). We will cover this utility in more detail in Level 13.
Simply rerun Listing 1.1 to drop and recreate the TestDB database. Then, run the basic DBCC LogInfo command, as shown in Listing 2.1.
-- how many VLFs? DBCC Loginfo GO
Listing 2.1: How many VLFs in the newly-created TestDB database?
We are not concerned right now with the meaning of any of the columns returned; just note that four rows are returned meaning that we have four VLFs. Now, run Listing 1.3 to insert a million rows into a LogTest table, in the TestDB database, and then rerun the DBCC LogInfo command, as shown in Listing 2.2.
-- now how many VLFs? DBCC Loginfo GO
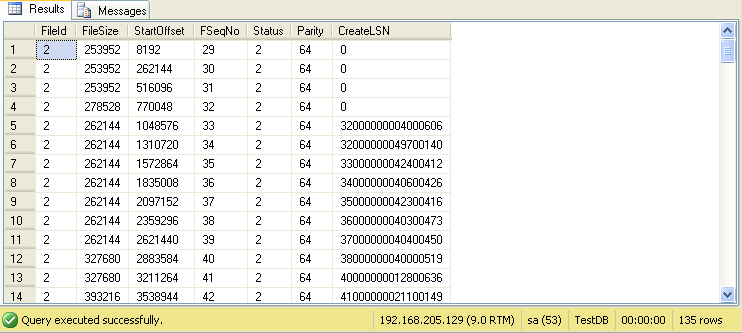
Listing 2.2: How many VLFs in the TestDB database after inserting a million rows?
Notice that we now have 135 rows returned, meaning that we have 135 VLFs! The growth properties inherited from the model database dictate a small initial size for the log files, then growth in relatively small increments. These properties are inappropriate for a database subject to this sort of activity and lead to the creation of a large number of VLFs.
Log file fragmentation can have a considerable impact on performance, especially crash recovery, restores, log backup; in other words, operations that read the log file. We will discuss this in more detail in Level 7 – Sizing and Growing the Transaction Log, and show how to avoid fragmentation by correctly sizing the log file. However, to give you an idea of the impact it can have, Linchi Shea has demonstrated a huge effect on the performance of data modifications when comparing a database with 20,000 VLFs to one with 16 VLFs.
Ultimately, the question of a "reasonable" number of VLFs in a log file will depend on the size of the log. In general, Microsoft regards more than about 200 VLFs as a possible cause for concern, but in a very big log file (say 500 GB) having only 200 VLFs could also be a problem, with the VLFs being too large and limiting space reuse. Kimberly Tripp's article "Transaction Log VLFs - too many or too few?" discusses this issue in more detail.
Summary
In this Level, we've covered the minimal background information regarding the architecture of the transaction log that is required to understand the basic issues, and potential problems, relating to truncation, space reuse and fragmentation, in the log file.
In the next Level, we move onto a detailed discussion of how the transaction log is used in database restore and recovery.