This title is a bit of a misnomer, as we would not generally manage the log, in any long-term sense, by operating a database in the BULK_LOGGED recovery model. However, a DBA may consider switching a database to the BULK_LOGGED recovery model in the short term during, for example, bulk load operations. When a database is operating in the BULK_LOGGED model these, and a few other operations such as index rebuilds, can be minimally logged and will therefore use much less space in the log. When rebuilding the clustered index for very large tables, or when bulk loading millions of rows of data, the reduction in log space usage when operating in BULK_LOGGED recovery model, compared to FULL recovery model, can be very substantial.
However, we should use BULK_LOGGED recovery only in full knowledge of the implications it has for database restore and recovery. For example, it's not possible to restore to a specific point in time within a log backup that contains log records relating to minimally logged operations. Also, there is a special case where a tail log backup will fail if minimally logged operations, recorded while a database was operating in BULK_LOGGED recovery model, exist in the active portion of the transaction log and a data file becomes unavailable as a result of a disaster (such as disk failure).
If your luck is out in terms of the timing of such a disaster, then either of these limitations could lead to data loss. Check the Service Level Agreement (SLA) for the database in question, for acceptable levels of data loss; if it expresses zero tolerance then it's highly unlikely that use of the BULK_LOGGED model, even for short periods, will be acceptable. Conversely, of course, if such a database is subject to regular index rebuilds or bulk loads, then the database owners must understand the implications for log space allocation for that database, of performing these operations under the FULL recovery model.
Having said all this, for many databases, the ability to switch to BULK_LOGGED recovery so that SQL Server will minimally log certain operations, is a very useful weapon in the fight against excessive log growth. In most cases, the SLA will allow enough leeway to make its use acceptable and, with careful planning and procedures, the risks will be minimal.
This level will cover:
- what we mean by "minimal logging"
- advantages of minimal logging in terms of log space use
- implications of minimal logging for crash recovery, point-in-time restore, and tail log backups
- best practices for use of
BULK_LOGGEDrecovery.
Minimally Logged Operations
When a database is operating in the FULL recovery model, all operations are fully logged. This means that each log record stores enough information to roll back (undo), or roll forward (redo), the operations that it describes. With all log records in a given log file fully logged, we have a complete description of all the changes made to a database, in that timeframe. This means that, during a restore operation, SQL Server can roll forward through each log record, and then recover the database to the exact state in which it existed at any point in time within that log file.
When a database is operating in BULK_LOGGED (or SIMPLE) recovery model, SQL Server can minimally log certain operations. While some minimally logged operations are obvious (BULK INSERT, bcp or index rebuilds), others are not. For example, INSERT…SELECT can be minimally logged under some circumstances in SQL Server 2008 and later versions. (See http://msdn.microsoft.com/en-us/library/ms191244%28v=sql.100%29.aspx for details.)
You can find here a full list of operations that SQL Server can minimally log: http://msdn.microsoft.com/en-us/library/ms191244.aspx. Some of the more common ones are as follows:
- bulk load operations – such as via SSIS, bcp or
BULK INSERT SELECT INTOoperations- creating and rebuilding indexes.
It's worth noting that "can be" minimally logged is not the same as "will be" minimally logged. Depending on the indexes that are in place and the plan chosen by the optimizer, SQL Server might still fully log bulk load operations that, in theory, it can minimally log. Due (mainly) to recoverability requirements, SQL Server only minimally logs a bulk data load that is allocating new extents. For example, if we perform a bulk load into a clustered index that already has some data, the load will consist of a mix of adding to pages, splitting pages, and allocating new pages, and so SQL Server can't minimally log. Similarly, it's possible for SQL Server to log minimally inserts into the table, but fully log inserts into the non-clustered indexes. See the white paper, The Data Loading Performance Guide, (http://msdn.microsoft.com/en-us/library/dd425070.aspx) for a fuller discussion.
Books Online describes minimally logged operations as "logging only the information that is required to recover the transaction without supporting point-in-time recovery." Similarly, Kalen Delaney, in her book, SQL Server 2008 Internals (Chapter 4, page 199), defines minimally logged operations as "ones that log only enough information to roll back the transaction, without supporting point-in-time recovery."
In order to understand the difference between what is logged for a "minimally logged" operation, depending on whether the database uses FULL or BULK_LOGGED recovery, let's try it out and see!
Data and backup file locations
All of the examples in this level assume that data and log files are located in 'D:\SQLData' and all backups in 'D:\SQLBackups', respectively. When running the examples, simply modify these locations as appropriate for your system (and note that in a real system, we wouldn't store everything on the same drive!).
We'll use a SELECT…INTO statement, which can be minimally logged in SQL Server 2008, to insert 200 rows, of 2,000 bytes each, into a table called SomeTable. Since the page size in SQL Server is 8 KB, we should get four rows per page and so 50 data pages in all (plus some allocation pages). Listing 6.1 creates a test database, FullRecoveryFULL recovery model, and then runs the SELECT…INTO statement.
USE master
GO
IF DB_ID('FullRecovery') IS NOT NULL DROP DATABASE FullRecovery; GO -- Clear backup history EXEC msdb.dbo.sp_delete_database_backuphistory @database_name = N'FullRecovery' GO CREATE DATABASE FullRecovery ON (NAME = FullRecovery_dat, FILENAME = 'D:\SQLData\FullRecovery.mdf' ) LOG ON ( NAME = FullRecovery_log, FILENAME = 'D:\SQLData\FullRecovery.ldf' ); ALTER DATABASE FullRecovery SET RECOVERY FULL GO BACKUP DATABASE FullRecovery TO DISK = 'D:\SQLBackups\FullRecovery.bak' WITH INIT GO USE FullRecovery GO IF OBJECT_ID('dbo.SomeTable', 'U') IS NOT NULL DROP TABLE dbo.SomeTable GO SELECT TOP ( 200 ) REPLICATE('a', 2000) AS SomeCol INTO SomeTable FROM sys.columns AS c;Listing 6.1: Running a SELECT…INTO operation on a FULL recovery model database.
Now, at this point, we'd like to peek inside the log, and understand what SQL Server recorded in the log because of our fully logged SELECT…INTO statement. There are some third-party log readers for this purpose, but very few of them offer support beyond SQL Server 2005. However, we can use two undocumented and unsupported functions to interrogate the contents of log files (fn_dblog) and log backups (fn_dump_dblog), as shown in Listing 6.2.
SELECT Operation ,
Context ,
AllocUnitName ,
-- Description ,
[Log Record Length] ,
[Log Record]
FROM fn_dblog(NULL, NULL)Listing 6.2: Investigating log contents using fn_dblog.
Figure 6.1 shows a small portion of the output consisting of a set of eight pages (where the allocation unit is dbo.). Notice that the context in each case is SomeTableLCX_HEAP, so these are the data pages. We also see some allocation pages, in this case a Differential Changed Map, tracking extents that have changes since the last database backup (to facilitate differential backups), and some Page Free Space (PFS) pages, tracking page allocation and available free space on pages.
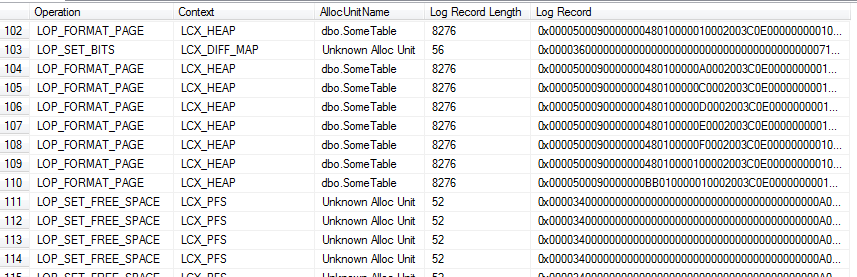
Figure 6.1: fn_dblog output after SELECT…INTO on a FULL recovery model database.
The log records describing the changes made to SomeTable are all of type LOP_FORMAT_PAGE; they always appear in sets of 8, and each one is 8,276 bytes long. The fact that they appear in sets of 8 indicates that SQL Server was processing the insert one extent at a time and writing one log record for each page. The fact that each one is 8,276 bytes shows that each one contains the image of an entire page, plus log headers. In other words, for the INSERT…INTO command, and others that SQL Server will minimally log in BULK_LOGGED recovery, SQL Server does not log every individual row when run in FULL recovery; rather, it just logs each page image, as it is filled.
A closer examination of the Log Record column shows many bytes containing the hex value 0x61, as shown in Figure 6.2. This translates to decimal 97, which is the ASCII value for 'a', so these are the actual data rows in the log file.

Figure 6.2: A closer look at the log records.
So in FULL recovery model, SQL Server knows, just by reading the log file, which extents changed and exactly how this affected the contents of the pages. Let's now compare this to the log records that result from performing the same SELECT…INTO operation on a database operating in BULK_LOGGED recovery.
USE master
GO
IF DB_ID('BulkLoggedRecovery') IS NOT NULL
DROP DATABASE BulkLoggedRecovery;
GO
EXEC msdb.dbo.sp_delete_database_backuphistory @database_name = N'BulkLoggedRecovery'
GO
CREATE DATABASE BulkLoggedRecovery ON
(NAME = BulkLoggedRecovery_dat,
FILENAME = 'D:\SQLData\BulkLoggedRecovery.mdf'
) LOG ON
(
NAME = BulkLoggedRecovery_log,
FILENAME = 'D:\SQLData\BulkLoggedRecovery.ldf'
);
GO
ALTER DATABASE BulkLoggedRecovery SET RECOVERY BULK_LOGGED
GO
BACKUP DATABASE BulkLoggedRecovery TO DISK =
'D:\SQLBackups\BulkLoggedRecovery.bak'
WITH INIT
GO
USE BulkLoggedRecovery
GO
IF OBJECT_ID('dbo.SomeTable', 'U') IS NOT NULL DROP TABLE dbo.SomeTable GO SELECT TOP ( 200 ) REPLICATE('a', 2000) AS SomeCol INTO SomeTable FROM sys.columns AS c;Listing 6.3: Running a SELECT…INTO operation on a BULK_LOGGED recovery model database.
Rerun the fn_dblog function, from Listing 6.2, in the BulkLoggedRecovery database, and what we get this time is a very different set of log records. There are no LOP_FORMAT_PAGE log records at all.
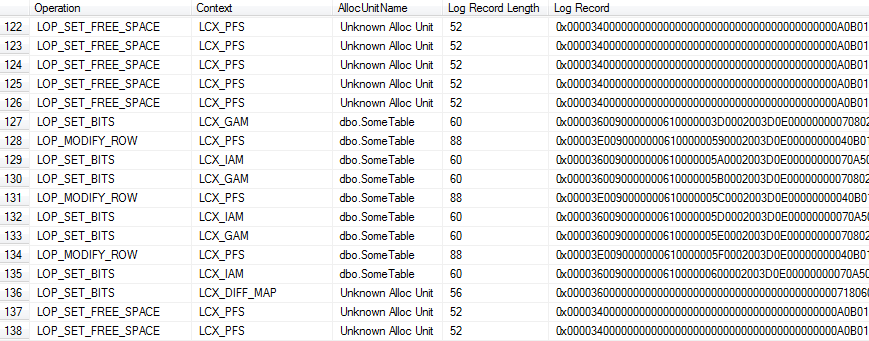
Figure 6.3: fn_dblog output after SELECT…INTO on a BULK_LOGGED database.
This time, the log records for the changes made to SomeTable appear in the context of Global Allocation Maps (GAMs) and Index Allocation Maps (IAMs), tracking extent allocation, plus some PFS pages. In other words, SQL Server is logging the extent allocations (and any changes to the metadata, i.e. system tables, which we don't show in Figure 6.3), but the data pages themselves are not there. There is no reference in the log as to what data is on the allocated pages. We do not see here the 0x61 pattern that appeared in the log records for the FullRecovery database, and most of the log records are around 100 bytes in size.
Therefore, now we have a clearer picture of exactly what it means for SQL Server to minimally log an operation: it is one where SQL Server logs allocations of the relevant extents, but not the actual content of those extents (i.e. data pages).
The effects of this are twofold. Firstly, it means that SQL Server writes much less information to the transaction log, so the log file will grow at a significantly slower rate than for equivalent operations in the FULL recovery model. It also means that the bulk load operations may be faster (but see the later discussion on this topic, in the section on Advantages of Minimal Logging and BULK_LOGGED Recovery).
Secondly, however, it means that SQL Server logs only enough information to undo (roll back) the transaction to which the minimally logged operation belongs, but not to redo it (roll it forward). To roll back the transaction containing the SELECT…INTO operation, all SQL Server needs to do is de-allocate the affected pages. Since page allocations are logged, as shown in Figure 6.3, that's possible. To roll the transaction forward is another matter. The log records can be used to re-allocate the pages, but there is no way, when an operation is minimally logged, for SQL Server to use these log records to recreate the contents of the pages.
Minimally logged versus "extent de-allocation only"
For DROP TABLE and TRUNCATE TABLE operations, as for bulk operations, SQL Server logs only the extent de-allocations. However, the former are not true minimally logged operations because their behavior is the same in all recovery models. The behavior of true minimally logged operations is different in FULL recovery from in BULK_LOGGED (or SIMPLE) recovery, in terms of what SQL Server logs. Also, for true minimally logged operations, when log backups are taken, SQL Server captures into the backup file all the data pages affected by a minimally logged operation (we'll discuss this in more detail a little later), for use in restore operations. This does not happen for the DROP TABLE and TRUNCATE TABLE commands.
Advantages of Minimal Logging and BULK_LOGGED Recovery
Before we discuss potential issues with use of BULK_LOGGED recovery, let's deal with the major advantages for the DBA.
Operations can be minimally logged in either the SIMPLE or BULK_LOGGED recovery model. However, if we switch a database from FULL to SIMPLE recovery model, we trigger a CHECKPOINT, which truncates the log and we immediately break the LSN chain. No further log backups will be possible until the database is switched back to FULL (or BULK_LOGGED) recovery, and the log chain is restarted with a full database backup, or we "bridge the LSN gap" with a differential database backup.
Switching to BULK_LOGGED from FULL recovery, however, does not break the log chain. It is not necessary to take a database backup after switching the database from FULL recovery to BULK_LOGGED recovery; it's effective immediately. Similarly, it is not necessary to take a database backup when switching back to FULL recovery. However, it is a good idea to take a log backup immediately before switching to BULK_LOGGED and immediately after switching back (see the Best Practices for Use of BULK_LOGGED section later, for further discussion).
Although there are still issues to consider when switching to BULK_LOGGED model, which we'll discuss in detail shortly, it is a much safer option in terms of risk of data loss, since the log chain remains intact. Once the database is working in the BULK_LOGGED model, the real advantage is the reduction in the log space used by operations that can be minimally logged, and the potentially improved performance of these operations.
Let's look at an example of an index rebuild, an operation that can be minimally logged. In FULL recovery model, the index rebuild operation requires log space greater than, or equal to, the size of the table. For large tables, that can cause massive log growth, and this is the root cause of many forum entries from distressed users, along the lines of, "I rebuilt my indexes and my log grew huge / we ran out of disk space!"
In BULK_LOGGED recovery, only the page allocations for the new index are logged, so the impact on the transaction log can be substantially less than it would in FULL recovery. A similar argument applies to large data loads via bcp or BULK INSERT, or for copying data into new tables via SELECT…INTO or INSERT INTO…SELECT.
To get an idea just how much difference this makes, let's see an example. First, we'll create a table with a clustered index and load it with data (the Filler column adds 1,500 bytes per row and ensures we get a table with many pages).
USE FullRecovery
GO
IF OBJECT_ID('dbo.PrimaryTable_Large', 'U') IS NOT NULL
DROP TABLE dbo.PrimaryTable_Large
GO
CREATE TABLE PrimaryTable_Large
(
ID INT IDENTITY
PRIMARY KEY ,
SomeColumn CHAR(4) NULL ,
Filler CHAR(1500) DEFAULT ''
);
GO
INSERT INTO PrimaryTable_Large
( SomeColumn
)
SELECT TOP 100000
'abcd '
FROM msdb.sys.columns a
CROSS JOIN msdb.sys.columns b
GO
SELECT *
FROM sys.dm_db_index_physical_stats(DB_ID(N'FullRecovery'),
OBJECT_ID(N'PrimaryTable_Large'),
NULL, NULL, 'DETAILED');Listing 6.4: Creating and loading PrimaryTable_Large.
Let's now rebuild the clustered index (consisting of 20,034 pages, according to sys.dm_db_index_physical_stats) in our FULL recovery model database, and see how much log space the index rebuild needs, using with the sys.dm_tran_database_transactions DMV.
--truncate the log
USE master
GO
BACKUP LOG FullRecovery
TO DISK = 'D:\SQLBackups\FullRecovery_log.trn'
WITH INIT
GO
-- rebuild index and interrogate log space use, within a transaction
USE FullRecovery
GO
BEGIN TRANSACTION
ALTER INDEX ALL ON dbo.PrimaryTable_Large REBUILD
-- there's only the clustered index
SELECT d.name ,
-- session_id ,
d.recovery_model_desc ,
-- database_transaction_begin_time ,
database_transaction_log_record_count ,
database_transaction_log_bytes_used ,
DATEDIFF(ss, database_transaction_begin_time, GETDATE())
AS SecondsToRebuild
FROM sys.dm_tran_database_transactions AS dt
INNER JOIN sys.dm_tran_session_transactions AS st
ON dt.transaction_id = st.transaction_id
INNER JOIN sys.databases AS d ON dt.database_id = d.database_id
WHERE d.name = 'FullRecovery'
COMMIT TRANSACTIONListing 6.5: Log space usage when rebuilding a clustered index.
When I ran this code on a database operating in FULL recovery, the output from the DMV was as shown in Figure 6.4.

Figure 6.4: Index rebuild time and log space use in FULL recovery.
It took approximately 5 seconds to rebuild the index, and the rebuilds required about 166 MB of log space for 20,131 log records; this is ignoring the log reservation in case of rollback, so the total log space required is larger.
If we run the same example in the BulkLoggedRecovery database, the output is as shown in Figure 6.5.

Figure 6.5: Index rebuild time and log space use in BULK_LOGGED recovery.
The rebuild appears to be a bit faster, at 4 seconds; however, because the index in this example is quite small, and because the data and log files are both on a single drive, not much can be concluded from that time difference. The main point here is the difference in the log space used. In BULK_LOGGED recovery, that index rebuild only used about 0.6 MB of log space, compared to the 166 MB of log space in FULL recovery. That's a major saving considering that this was quite a small table, at only 160 MB in size.
In case anyone's wondering whether the behavior will be any different in SIMPLE recovery, look at Figure 6.6 (the code to reproduce the example in a SIMPLE recovery database, as well as BULK_LOGGED, is included in the code download for this level).

Figure 6.6: Index rebuild time and log space use in SIMPLE recovery.
As expected, the behavior is the same as for BULK_LOGGED recovery, since operations that are minimally logged in BULK_LOGGED recovery are also minimally logged in SIMPLE recovery.
This is the major reason for running a database in BULK_LOGGED recovery; it offers both the database recovery options of FULL recovery (mostly, see the coming sections), but it reduces the amount of log space used by certain operations, in the same way as SIMPLE recovery. Note also, that if the database is a log-shipping primary, we cannot switch the database into SIMPLE recovery for index rebuilds without having to redo the log shipping afterwards, but we can switch it to BULK_LOGGED for the index rebuilds.
Finally, note that database mirroring requires FULL recovery only and, as such, a database that is a database mirroring principal cannot use BULK_LOGGED recovery.
Implications of Minimally Logged Operations
Earlier, we discussed how, when a database is operating in BULK_LOGGED recovery, the log contains only the extent allocations (plus metadata), and not the actual results of the minimally logged operation (i.e. not, for example, the actual data that was inserted). This means that the log on its own only holds enough information to roll back a transaction, not to redo it. In order to perform the latter, SQL Server needs to read the log's records describing the operation and the actual data pages affected by the operation.
This has implications whenever SQL Server needs to redo transactions, namely during crash recovery, and during database restore operations. It also has implications for log backup operations, both in terms of what SQL Server must copy into the backup file, and the situations in which this may or may not be possible.
Crash recovery
Crash recovery, also called restart recovery, is a process that SQL Server performs whenever it brings a database online. So for example, if a database does not shut down cleanly, then upon restart SQL Server goes through the database's transaction log. It undoes any transaction that had not committed at the time of the shutdown and redoes any transaction that had committed but whose changes had not been persisted to disk.
This is possible because, as discussed in Level 1, the Write Ahead Logging mechanism ensure that the log records associated with a data modification are written to disk before either the transaction commits or the data modification is written to disk, whichever happens first. SQL Server can write the changes to the data file at any time, before the transaction commits or after, via the checkpoint or Lazy Writer. Hence, for normal operations (i.e. ones that are fully logged), SQL Server has sufficient information in the transaction log to tell whether an operation needs to be undone or redone, and has sufficient information to roll forward or roll back.
For operations that were minimally logged, however, roll forward is not possible as there's not enough information in the log. Therefore, when dealing with minimally logged operations in SIMPLE or BULK_LOGGED recovery model, another process, Eager Write, guarantees that the thread that is executing the bulk operation hardens to disk any extents modified by the minimally logged operation, before the transaction is complete. This is in contrast to normal operations where only the log records have to be hardened before the transaction is complete, and the data pages are written later by a system process (Lazy Writer or checkpoint).
This means that crash recovery will never have to redo a minimally logged operation since SQL Server guarantees that the modified data pages will be on disk at the time the transaction commits, and hence the minimal logging has no effect on the crash recovery process.
One side effect of this requirement that SQL Server writes both log records and modified data pages to disk before the transaction commits, is that it may actually result in the minimally logged operation being slower than a regular transaction, if the data file is not able to handle the large volume of writes. Minimally logged operations are usually faster than normal operations, but there is no guarantee. The only guarantee is that they write less information to the transaction log.
Database restores
SQL Server also needs to perform redo operations when restoring full, differential, or log backups. As we've discussed, for a minimally logged operation the affected pages are on disk at the point the transaction completes and so SQL Server simply copies those pages into any full or differential backup files, and restores from these backups are unaffected.
Restores from log backups, however, are more interesting. If the log backup only contained the log records relating to extent allocation, then on restoring the log backup there would be no way to recreate the contents of the extents that the minimally logged operation affected. This is because, as we saw earlier, the log does not contain the inserted data, just the extent allocations and metadata.
In order to enable log restores when there are minimally logged operations, included in the log backup are not just the log records, but also the images of any extent (set of eight pages) affected by the minimally logged operation. This doesn't mean images of them as they were after the minimally logged operation, but the pages as they are at the time of the log backup. SQL Server maintains a bitmap allocation page, called the ML map or bulk-logged change map, with a bit for every extent. Any extents affected by the minimally logged operation have their bit set to 1. The log backup operation reads this page and so knows exactly what extents to include in the backup. That log backup will then clear the ML map.
So, for example, let's say we have a timeline like that shown in Figure 6.7, where a log backup occurs at 10:00, then at (1) a minimally logged operation (let's say a BULK INSERT) affected pages 1308–1315 among others, at (2) an UPDATE affected pages 1310 and 1311 and at (3) another log backup occurred.

Figure 6.7: Example timeline for database operations and log backups.
The log backup at 10:30 backs up the log records covering the period 10:00–10:30. Since there was a minimally logged operation within that log interval, it copies the extents affected by the minimally logged operations into the log backup. It copies them as they appear at the time of the log backup, so they will reflect the effects of the BULK INSERT and the UPDATE, plus any further modifications that may have taken place between the UPDATE and the log backup.
This affects how we can restore the log. It also affects the size of the log backups and, under certain circumstances, may affect tail log backups, but we'll get to that in more detail in the next section.
Let's take a look an example of how minimally logged operations can affect a point-in-time restore. Figure 6.8 depicts an identical backup timeline for two databases. The green bar represents a full database backup and the yellow bars represent a series of log backups. The only difference between the two databases is that the first is operating in FULL recovery model, and the second in BULK LOGGED.
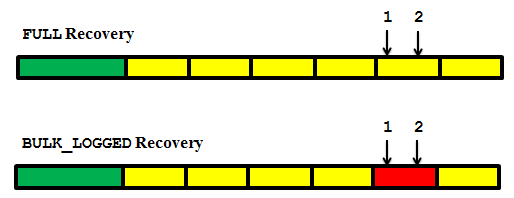
Figure 6.8: Database backup timeline.
The time span of the fifth log backup is 10:00 to 10:30. At 10:10, a BULK INSERT command (1) loaded a set of data. This bulk data load completed without a hitch but, in an unrelated incident at 10:20, a user ran a "rogue" data modification (2) and crucial data was lost. The project manager informs the DBA team and requests that they restore the database to a point in time just before the transaction that resulted in data loss started, at 10:20.
In the FULL recovery model database, this is not an issue. The bulk data load was fully logged and we can restore the database to any point in time within that log file. We simply restore the last full database backup, without recovery, and apply the log files to the point in time right before the unfortunate data loss incident occurred, using the RESTORE LOG command with the STOPAT parameter, to stop the restore operation sometime before 10:20.
In the BULK_LOGGED database, we have a problem. We can restore to any point in time within the first four log backups, but not to any point in time within the fifth log backup, which contains the minimally logged operations. Remember that for this log backup we only have the extents affected by the minimally logged operation, as they existed at the time of the log backup. The restore of the fifth log backup is "all or nothing:" either we apply none of the operations in this log file, stopping the restore at the end of the fourth file, or we apply all of them, restoring to the end of the file, or proceeding to restore to any point in time within the sixth log backup.
If we tried to restore that fifth log backup, with STOPAT 10:15 (a time between the minimally logged operation and the rogue modification), SQL is not going to walk the rest of the log backup figuring out what operations it needs to undo on the pages that were affected by the minimally logged operation. It has a simpler reaction:
Msg 4341, Level 16, State 1, Line 2
This log backup contains bulk-logged changes. It cannot be used to stop at an arbitrary point in time.
Unfortunately, if we apply the whole of the fifth log file backup, this would defeat the purpose of the recovery, since the errant process committed its changes somewhere inside of that log backup file, so we'd simply be removing the data we were trying to get back! We have little choice but to restore up to the end of the fourth log, recover the database, and report the loss of any data changes made after this time.
This inability to restore the database to point-in-time if there are minimally logged operations within the log interval is something that must be considered when choosing to run a database in BULK_LOGGED recovery, either for short or long periods. It is easy to identify whether or not a specific log backup contains any minimally logged operations. A RESTORE HEADERONLY returns a set of details about the backup in question, including a column HasBulkLoggedData. In addition, the msdb backupset table has a column has_BULK_LOGGED_data. If the column value is 1, then the log backup contains minimally logged operations and can only be restored entirely or not at all. That said, finding this out while planning or executing a restore may be an unpleasant surprise.
Log backup size
The need to copy into the log backup the pages affected by a minimally logged operation affects the size of log backups. Essentially, it means that while the actual log will grow less for a bulk operation in a BULK_LOGGED recovery database, compared to a FULL recovery database, the log backup sizes will not be smaller, and may occasionally be bigger than the comparable log backups for FULL recovery databases.
To see the possible impact of minimally logged operations, and BULK_LOGGED recovery model on the size of the log backups, we'll look at a simple example. First, rerun the portion of Listing 6.3 that drops and recreates the BulkLoggedRecovery database, sets the recovery model to BULK_LOGGED and then takes a full database backup. Next, run Listing 6.6 to create 500K rows in SomeTable.
USE BulkLoggedRecovery
GO
IF OBJECT_ID('dbo.SomeTable', 'U') IS NOT NULL
DROP TABLE dbo.SomeTable ;
SELECT TOP 500000
SomeCol = REPLICATE('a', 2000)
INTO dbo.SomeTable
FROM sys.all_columns ac1
CROSS JOIN sys.all_columns ac2 ;
GOListing 6.6: Insert 500K rows into SomeTable in the BulkLoggedRecovery database.
Next, we check current log space usage, and then back up the log.
DBCC SQLPERF(LOGSPACE) ; --24 MB --truncate the log USE master GO BACKUP LOG BulkLoggedRecovery TO DISK = 'D:\SQLBackups\BulkLoggedRecovery_log.trn' WITH INIT GO
Listing 6.7: Backing up the log for BulkLoggedRecovery.
Given that the log size is only about 24 MB, you may be surprised to see the size of the log backup, about 1 GB in my test! For a database in FULL recovery, you'll find that the log size and log backup size are both about 1 GB.
Tail log backups
Let's imagine that a hardware glitch causes some data corruption, but the database is still online, and we wish to restore over that database. Performing a tail log backup, with BACKUP LOG…WITH NORECOVERY, will capture the remaining contents of the log file and put the database into a restoring state, so that no further transactions against that database will succeed, and we can begin the restore operation. This sort of tail log backup, as well as normal log backups, require the database to be online (so that SQL Server can stamp information regarding the log backup into the database header).
However, assume instead that the damage to the data file is severe enough that the database becomes unavailable and an attempt to bring it back online fails. If the database is in FULL recovery model, with regular log backups, then as long as the log file is still available then we can take a tail log backup, but using the NO_TRUNCATE option instead, i.e. BACKUP LOG…WITH NO_TRUNCATE. This operation backs up the log file without truncating it and doesn't require the database to be online.
With the existing backups (full, perhaps differential, and then log) and the tail log backup, we can restore the database up to the exact point that it failed. We can do that because the log contains sufficient information to re-create all of the committed transactions.
However, if the database is in BULK_LOGGED recovery and there are minimally logged operations in the active portion of the transaction log, then the log does not contain sufficient information to recreate all of the committed transactions, and the actual data pages are required to be available when we take the tail log backup. If the data file is not available, then that log backup cannot copy the data pages it needs to restore a consistent database. Let's see this in action, using the BulkLoggedRecovery database.
BACKUP DATABASE BulkLoggedRecovery
TO DISK = 'D:\SQLBackups\BulkLoggedRecovery2.bak'
WITH INIT
GO
USE BulkLoggedRecovery
GO
IF OBJECT_ID('dbo.SomeTable', 'U') IS NOT NULL
DROP TABLE dbo.SomeTable ;
SELECT TOP 200
SomeCol = REPLICATE('a', 2000)
INTO dbo.SomeTable
FROM sys.all_columns ac1
GO
SHUTDOWN WITH NOWAITListing 6.8: Create the BulkLoggedRecovery database, perform a SELECT INTO, and then shut down.
With the SQL Server service shut down, go to the data folder and delete the mdf file for the BulkLoggedRecovery database, and then restart SQL Server. It's not a complete simulation of a drive failure, but it's close enough for the purposes of this demo.
When SQL Server restarts, the database is not available, which is no surprise since its primary data file is missing. The state is Recovery_Pending, meaning that SQL couldn't open the database to run crash recovery on it.
USE master
GO
SELECT name ,
state_desc
FROM sys.databases
WHERE name = 'BulkLoggedRecovery'
name state_desc
---------------------------------------
BulkLoggedRecovery RECOVERY_PENDINGListing 6.9: The BulkLoggedRecovery database is in a Recovery_Pending state.
In Listing 6.10, we attempt to take a tail log backup (note that NO_TRUNCATE implies COPY_ONLY and CONTINUE_AFTER_ERROR):
BACKUP LOG BulkLoggedRecovery TO DISK = 'D:\SQLBackups\BulkLoggedRecovery_tail.trn' WITH NO_TRUNCATE Processed 7 pages for database 'BulkLoggedRecovery', file 'BulkLoggedRecovery_log' on file 1. BACKUP WITH CONTINUE_AFTER_ERROR successfully generated a backup of the damaged database. Refer to the SQL Server error log for information about the errors that were encountered. BACKUP LOG successfully processed 7 pages in 0.007 seconds (7.463 MB/sec).
Listing 6.10: Attempting a tail log backup using BACKUP LOG…WITH NO_TRUNCATE.
Well, it said that it succeeded (and despite the warning, there were no errors in the error log). Now, let's try to restore this database, as shown in Listing 6.11.
RESTORE DATABASE BulkLoggedRecovery FROM DISK = 'D:\SQLBackups\BulkLoggedRecovery2.bak' WITH NORECOVERY RESTORE LOG BulkLoggedRecovery FROM DISK = 'D:\SQLBackups\BulkLoggedRecovery_tail.trn' WITH RECOVERY Processed 184 pages for database 'BulkLoggedRecovery', file 'BulkLoggedRecovery' on file 1. Processed 3 pages for database 'BulkLoggedRecovery', file 'BulkLoggedRecovery_log' on file 1. RESTORE DATABASE successfully processed 187 pages in 0.043 seconds (33.895 MB/sec). Msg 3182, Level 16, State 2, Line 5 The backup set cannot be restored because the database was damaged when the backup occurred. Salvage attempts may exploit WITH CONTINUE_AFTER_ERROR. Msg 3013, Level 16, State 1, Line 5 RESTORE LOG is terminating abnormally.
Listing 6.11: Attempting to restore BulkLoggedRecovery.
RESTORE DATABASE BulkLoggedRecovery FROM DISK = 'D:\SQLBackups\BulkLoggedRecovery2.bak' WITH NORECOVERY RESTORE LOG BulkLoggedRecovery FROM DISK = 'D:\SQLBackups\BulkLoggedRecovery_tail.trn' WITH RECOVERY, CONTINUE_AFTER_ERROR Processed 184 pages for database 'BulkLoggedRecovery', file 'BulkLoggedRecovery' on file 1. Processed 3 pages for database 'BulkLoggedRecovery', file 'BulkLoggedRecovery_log' on file 1. RESTORE DATABASE successfully processed 187 pages in 0.037 seconds (39.392 MB/sec). Processed 0 pages for database 'BulkLoggedRecovery', file 'BulkLoggedRecovery' on file 1. Processed 7 pages for database 'BulkLoggedRecovery', file 'BulkLoggedRecovery_log' on file 1. The backup set was written with damaged data by a BACKUP WITH CONTINUE_AFTER_ERROR. RESTORE WITH CONTINUE_AFTER_ERROR was successful but some damage was encountered. Inconsistencies in the database are possible. RESTORE LOG successfully processed 7 pages in 0.013 seconds (4.018 MB/sec).
Listing 6.12: Restoring the log backup using CONTINUE_AFTER_ERROR.
That worked, so let's investigate the state of the restored database. Rerun Listing 6.9 and you'll see it's reported as ONLINE, and SomeTable, the target of SELECT…INTO exists, so let's see if any of the data made it into the table (remember, the page allocations were logged, the contents of the pages were not).
USE BulkLoggedRecovery
GO
IF OBJECT_ID('dbo.SomeTable', 'U') IS NOT NULL
PRINT 'SomeTable exists'
SELECT *
FROM SomeTable
Msg 824, Level 24, State 2, Line 1
SQL Server detected a logical consistency-based I/O error: incorrect pageid (expected 1:184; actual 0:0). It occurred during a read of page (1:184) in database ID 32 at offset 0x00000000170000 in file 'C:\Program Files\Microsoft SQL Server\MSSQL10.MSSQLSERVER\MSSQL\DATA\BulkLoggedRecovery.mdf'. Additional messages in the SQL Server error log or system event log may provide more detail. This is a severe error condition that threatens database integrity and must be corrected immediately. Complete a full database consistency check (DBCC CHECKDB). This error can be caused by many factors; for more information, see SQL Server Books Online.Listing 6.13: Attempting to read SomeTable.
Note that this was the error message from SQL Server 2008 Enterprise Edition. It's possible you'll see different errors on other versions. In any event, this doesn't look good; let's see what DBCC CHECKDB says about the state of the database.
DBCC CHECKDB ('BulkLoggedRecovery') WITH NO_INFOMSGS, ALL_ERRORMSGS
Msg 8921, Level 16, State 1, Line 1
Check terminated. A failure was detected while collecting facts. Possibly tempdb out of space or a system table is inconsistent. Check previous errors.Listing 6.14: Checking the state of BulkLoggedRecovery with DBCC CHECKDB.
This doesn't look good at all, unfortunately (and TempDB was not out of space). About the only sensible option here is to restore again and leave off the tail log backup. It means that any transactions that committed between the last normal log backup and the point of failure are lost.
This is another important consideration when deciding to run a database in BULK_LOGGED recovery model for long or short periods. In FULL recovery model, a tail log backup requires access only to the transaction log. Therefore, we can still back up the transaction log even if the MDF files are unavailable, due to disk failure, for example. However, in BULK_LOGGED model, if any minimally logged operations have occurred since the last log backup, it will mean that we cannot perform a tail log backup, if the data files containing the data affected by the minimally logged operations become unavailable. The reason for this is that when performing a transaction log backup in BULK_LOGGED model, SQL Server has to back up to the transaction log backup file all the actual extents (i.e. the data) that the bulk operation modified, as well as the transaction log entries. In other words, SQL Server needs access to the data files in order to do the tail log backup.
Best Practices for Use of BULK_LOGGED
Firstly, check the SLA for the database is question for the acceptable risk of data loss. If no data loss is acceptable, then plan to perform all operations in FULL recovery model, with the implications this has for log growth. If you can complete the operations you wish to minimally log within the maximum allowable data loss, as specified in the SLA, then you can consider using BULK_LOGGED recovery.
The golden rule, when using the BULK_LOGGED recovery model is to use it for as short a time as possible and to try, as far as possible, to isolate the minimally logged operations into their own log backup. Therefore, take a transaction log backup immediately prior to switching to BULK_LOGGED recovery and another transaction log backup immediately upon switching back to FULL recovery. This will ensure that the smallest possible of time and smallest number of transactions are within a log interval that contains minimally logged operations.
To illustrate how this reduces risk, consider the following scenario:
- 1:00 a.m. Full backup
- 1:15 a.m. Transaction log backup1
- 2:15 a.m. Transaction log backup2
- 2:40 a.m. Switch to
BULK_LOGGED, Bulk operation begins - 3:05 a.m. Bulk operation ends
- 3:10 a.m. – FAILURE – MDF becomes unavailable
- 3:15 a.m. Transaction log backup3
In this case, the 3.15 a.m. log backup would fail, as would a subsequent attempt to do a tail log backup. All we could do is restore the full backup followed by the first two log backups, so we would lose 55 minutes-worth of data.
If instead, we had adopted the following regime we would have been in a much better situation:
- 1:00 a.m. Full backup
- 1:15 a.m. Transaction log backup1
- 2:15 a.m. Transaction log backup2
- 2:35 a.m. Transaction log backup3
- 2:40 a.m. Switch to
BULK_LOGGED, Bulk operation begins - 3:05 a.m. Bulk operation ends
- 3:05 a.m. Switch back to
FULLand perform transaction log backup4 - 3:10 a.m. – FAILURE – MDF becomes unavailable
- 3:15 a.m. Transaction log backup5
Here, the 3:15 log backup would also fail, but we would subsequently be able to perform a tail log backup, since log backup4 ensures that there are no minimally logged operations in the live log. We could then restore the full backup, the four transaction log backups, and the tail log backup to recover to the point of failure at 3.15 a.m.
Even given these precautionary log backups, it is best to perform any minimally logged operations out of hours, when very few, if any, other transactions are being performed. This way, if anything goes wrong we may simply be able replay the bulk load to restore the data.
Even if you minimize risk by taking extra log backups before and after every bulk operation, it is inadvisable to operate a database continually in BULK_LOGGED model. It can be very hard, depending on your environment, to exert total control over who might perform a minimally logged operation and when. Bear in mind that any table owner can create or rebuild indexes on that table; anyone who can create a table can also run SELECT…INTO statements.
Finally, we recommend reading The Data Loading Performance Guide (http://msdn.microsoft.com/en-us/library/dd425070.aspx), which offers a lot of advice on achieving high-speed bulk data modifications, and discusses how to measure the potential benefit that will arise from minimal logging, using Trace Flag 610.
Summary
The BULK_LOGGED recovery model offers a way to perform data loads and some database maintenance operations such as index rebuilds without the transaction log overhead that they would normally have in FULL recovery model, but while still keeping the log chain intact. The downsides of this include greater potential data loss if a disaster occurs during, or over the same time span as, the bulk operation. In other words, you won't be able to use the STOPAT option when restoring a log file that contains minimally logged operations. It is still possible to restore the entire transaction log backup to roll the database forward, and it is still possible to restore to a point in time in a subsequent log file which doesn't contain any minimally logged operations. However, in the event of an application bug, or a user change that causes data to be deleted, around the same period as the minimally logged operation, it will not be possible to stop at a specific point in time in the log in which these changes are recorded, in order to recover the data that was deleted.
When using BULK_LOGGED recovery, keep in mind the increased risks of data loss, and use the recovery model only for the duration of the maintenance or data load operations and not as a default recovery model.
Even with the increased risks, it is a viable and useful option and is something that DBAs should consider when planning data loads or index maintenance.
Acknowledgements
Many thanks to Shawn McGehee, author of SQL Server Backup and Restore (http://www.simple-talk.com/books/sql-books/sql-backup-and-restore/) for contributing additional material to the Database restores section of this Level.
