

SQL Server 2017 has introduced several changes to the way that query plans work in SQL Server. This article is the first in a series that will cover these changes. The other articles in the series are:
- Automatic Plan Correction (this article)
- Adaptive Query Processing – Batch Mode Memory Grant Feedback
- Adaptive Query Processing – Batch Mode Adaptive Join
- Adaptive Query Processing – Interleaved Execution
Parameter Sniffing Background
Parameter sniffing occurs all the time in SQL Server. When a query is submitted and a plan is being created, SQL will look at the parameters being passed to the query to help determine an optimal execution plan. As long as the various parameters used on subsequent executions would produce the same execution plan, all is well.
Sometimes, different parameters can cause SQL to have different desired execution plans. For instance, one parameter may return just a small handful of rows, and the query plan may use an index seek with a key lookup. A different parameter may returns hundreds (or thousands) of rows, and in such a scenario a key lookup would be a prohibitive operation to perform, so SQL will decide to do a clustered index (or table) scan instead.
The immediate thought to most would be that the scan is bad, and that the seek is good. However, this really depends upon what your typical workload is. If the majority of your workload will require the scan, then this might not be the case – having the plan with the seek make be undesired.
When you start having a parameter sniffing problem, the issue is that the first time the query is run and there isn’t an execution plan in the plan cache, one will be created and stored in the plan cache for subsequent reuse. If the first query is not your typical workload, then you can have the majority of the subsequent queries running a suboptimal query plan. As previously mentioned, parameter sniffing occurs all the time. It's only when you have a parameter sensitive query with an inappropriate cached plan for your typical workload that parameter sniffing becomes "bad".
Prior to SQL Server 2016, the fix for this issue would be to use query hints (truthfully, they are really directives) and various other tricks to get the optimal plan to be created (optimize the plan for specific values, or recompile it with every execution). Plan guides are also a possibility, though most people find these very hard to use. SQL Server 2016 introduced the Query Store, where you could force a selected plan to be used. SQL Server 2017 takes this to the next level, with Automatic Plan Correction.
Automatic Plan Correction
In SQL Server 2017, Automatic Plan Correction has been introduced. SQL Server will monitor the queries being run, and if it detects that the current plan is worse than a previous one (in other words, the plan has regressed), then SQL Server will automatically force the good plan to be used instead of the regressed plan. While there are other things that could cause a plan to regress (out-of-date statistics, change in data distribution), the most likely cause is different parameters for parameter sensitive queries (in other words, queries that are prone to parameter sniffing issues).
In order to know about previous plans, SQL Server utilizes the Query Store to compare queries. After SQL Server 2017 forces a plan using Automatic Plan Correction, it then continues to monitor the performance of that query to ensure that the change is a good change. If it determines that the forced plan wasn’t a good choice, then it will evict the plan from the plan cache, and the next time the query is run a new plan will be created and put into the plan cache. Automatic Plan Correction is one item in the "Automatic Tuning" part of SQL Server, and as of SQL Server 2017, it is the only part of Automatic Tuning. I expect there to be other additions to Automatic Tuning in future versions of SQL Server.
Automatic Plan Correction sounds like a magical solution to parameter sniffing issues. Let’s see it in action! First, create a database, add a table and put some data into this table.
-- Drop / Create database
USE master;
GO
DROP DATABASE IF EXISTS SSC_APC;
GO
CREATE DATABASE SSC_APC;
ALTER DATABASE SSC_APC SET RECOVERY SIMPLE;
GO
USE SSC_APC;
GO
-- Create data. Table drop allows to not recreate the entire database.
SET STATISTICS IO,TIME,XML OFF;
DROP TABLE IF EXISTS dbo.APC_Test;
CREATE TABLE dbo.APC_Test (
type int,
name nvarchar(200),
index ncci nonclustered columnstore (type),
index ix_type(type)
);
INSERT INTO dbo.APC_Test(type, name)
VALUES (1, 'Single');
GO
-- Run this as necessary so that the query plan for type = 2 has a hash aggregate operator.
INSERT INTO dbo.APC_Test(type, name)
SELECT TOP 1000000 2 AS type, o.name
FROM sys.objects, sys.all_columns o;
GO 2 -- for me, it takes two times to get the hash aggregate operator.
-- rebuild indexes after having data
CREATE NONCLUSTERED INDEX [ix_type] ON [dbo].[APC_Test] ([type] ASC) WITH (DROP_EXISTING = ON);
CREATE NONCLUSTERED COLUMNSTORE INDEX [ncci] ON [dbo].[APC_Test] ([type]) WITH (DROP_EXISTING = ON);
GO
-- ensure that everything is flushed to disk in the database.
CHECKPOINT;
GOThe next step is to turn on Automatic Plan correction. As stated, this utilizes the Query Store, so this needs to be turned on first.
-- This feature requires Query Store, so let's turn that on:
ALTER DATABASE current
SET QUERY_STORE = ON
(
OPERATION_MODE = READ_WRITE
, CLEANUP_POLICY = ( STALE_QUERY_THRESHOLD_DAYS = 5 )
, DATA_FLUSH_INTERVAL_SECONDS = 900
, MAX_STORAGE_SIZE_MB = 10
, INTERVAL_LENGTH_MINUTES = 1
);
-- Now turn Automatic Plan Correction on
ALTER DATABASE current
SET AUTOMATIC_TUNING ( FORCE_LAST_GOOD_PLAN = ON );
-- And show that it is turned on
SELECT *
FROM sys.database_automatic_tuning_options;
GONow we will clear the procedure cache and drop the clean buffers (data pages that are unmodified since loaded from disk)
-- Clear the procedure cache ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE; -- Ensure that no data pages are in memory. DBCC DROPCLEANBUFFERS; GO
At this point, turn on the actual execution plans (Query menu | Include Actual Execution Plan, or the Ctrl+M key combination, or click the icon in the SSMS toolbar). Then run this block:
-- Put info about the good query plan in the query store. This query counts lots of rows, and needs to run several times. -- If the query plan has a stream aggregate instead of hash aggregate, run the second insert above until it does the hash aggregate. -- The faster the hardware, the more executions of a good plan may be required (ie. more priming of the good plan). EXECUTE sp_executesql @stmt = N'SELECT COUNT(*) FROM dbo.APC_Test WHERE type = @type', @params = N'@type int', @type = 2; GO 50
This runs a count for type = 2 fifty times, and the following execution plan is generated:
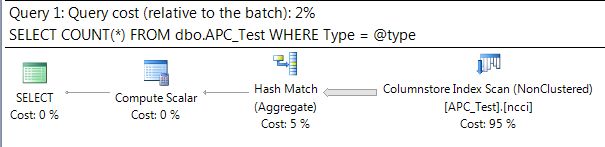
Here we can see that the ideal execution plan for returning a count of all type 2 records utilizes a ColumnStore index scan and a hash match aggregate operator. Since a ColumnStore index has the column compressed, this would be the fastest way to get all of the rows for this column, so this makes sense.
We proceed with clearing the procedure cache, dropping clean buffers, and running this next block which gets the count for type = 1:
-- Clear the procedure cache. This query will then use a stream aggregate / NCI seek to use. ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE; -- Ensure that no data pages are in memory. DBCC DROPCLEANBUFFERS; GO -- Now run query with type=1, where only one row is touched. EXECUTE sp_executesql @stmt = N'SELECT COUNT(*) FROM dbo.APC_Test WHERE type = @type', @params = N'@type int', @type = 1; GO
It's exexution plan is:

As can been seen, the ideal execution plan is to do an index seek and a stream aggregate operator. Since there is only one record for type=1, this makes sense.
In this final step, we will drop the clean buffers. We do not clear the procedure cache – we want to start off with using the execution plan that is in the plan cache. We will then run the count for type=2 again a few times. Remember that it's optimal plan is different from what is currently in the plan cache. If Automatic Plan Correction is working properly, then during its run it will shift from using this cached plan to the preferred plan for that type – the one with the ColumnStore index scan.
-- Ensure that no data pages are in memory. DBCC DROPCLEANBUFFERS; GO -- Execute query again for type=2. Don't clear cache - it will use the stream aggregate that is in the plan cache. -- Sometime during the GO loop, the plan should shift from the stream aggregate to the hash aggregate. EXECUTE sp_executesql @stmt = N'SELECT COUNT(*) FROM dbo.APC_Test WHERE type = @type', @params = N'@type int', @type = 2; GO 15
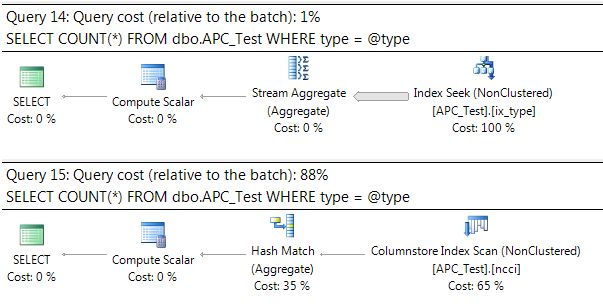
And here we can see that the execution plan that was utilized started off being the one that was last cached, and then it changed to the one in the Query Store between the 14th and 15th execution of the query. That is Automatic Plan Correction in action.
So, what causes a plan to be automatically corrected? Well, there are two conditions. The first is if the plan in the query store has fewer errors in it than the currently executing plan. The second is if the estimated gain (comparison of Execution Counts / Average CPU time for recommended and regressed plans) is greater than 10. Either of these conditions will cause the plan to be corrected.
The tuning recommendations can be seen in a new DMV. The data is stored in JSON, so there are a few new functions to use when querying this DMV. This query also shows the formula used to calculate the estimated gain:
-- See the tuning recommendations
SELECT reason,
score,
script = JSON_VALUE(details, '$.implementationDetails.script'),
planForceDetails.[query_id],
planForceDetails.[new plan_id],
planForceDetails.[recommended plan_id],
estimated_gain = (regressedPlanExecutionCount+recommendedPlanExecutionCount)*(regressedPlanCpuTimeAverage-recommendedPlanCpuTimeAverage)/1000000,
error_prone = IIF(regressedPlanErrorCount>recommendedPlanErrorCount, 'YES','NO')
FROM sys.dm_db_tuning_recommendations
CROSS APPLY OPENJSON (Details, '$.planForceDetails')
WITH ( [query_id] int '$.queryId',
[new plan_id] int '$.regressedPlanId',
[recommended plan_id] int '$.recommendedPlanId',
regressedPlanErrorCount int,
recommendedPlanErrorCount int,
regressedPlanExecutionCount int,
regressedPlanCpuTimeAverage float,
recommendedPlanExecutionCount int,
recommendedPlanCpuTimeAverage float ) as planForceDetails;This query returns the following results:


Extended Events for Automatic Plan Correction
As with all new things being added to SQL Server, Extended Events (XE) are used to monitor the new features. The XE events added for Automatic Plan Correction are qds.automatic_tuning_plan_regression_detection_check_completed (to detect plan regressions) and qds.automatic_tuning_plan_regression_verification_check_completed (to detect when corrections are being verified). The following code shows the creation of two XE sessions to utilize these two new events:
CREATE EVENT SESSION [APC - plans that are not corrected] ON SERVER
ADD EVENT qds.automatic_tuning_plan_regression_detection_check_completed(
WHERE ((([is_regression_detected]=(1))
AND ([is_regression_corrected]=(0))) -- 0: was not corrected; 1: was corrected
AND ([option_id]=(0))
))
ADD TARGET package0.event_file(SET filename=N'plans_that_are_not_corrected')
WITH (STARTUP_STATE=ON);
GO
ALTER EVENT SESSION [APC - plans that are not corrected] ON SERVER STATE = start;
GO
CREATE EVENT SESSION [APC - Reverted plan corrections] ON SERVER
ADD EVENT qds.automatic_tuning_plan_regression_verification_check_completed(
WHERE ((([is_regression_detected]=(1))
AND ([is_regression_corrected]=(1)))
AND ([option_id]=(0))
))
ADD TARGET package0.event_file(SET filename=N'reverted_plan_corrections')
WITH (STARTUP_STATE=ON);
GO
ALTER EVENT SESSION [APC - Reverted plan corrections] ON SERVER STATE = start;
GOSummary
Automatic Plan Correction provides a way for SQL Server to detect query plans that have regressed, and to automatically apply the better plan for you. This will handle the parameter sniffing issue - without you having to investigate and fix it yourself.



