
This is the nineteenth article in a series entitled Stairway to Integration Services. Previous articles in the series include:
- What is SSIS? Level 1 of the Stairway to Integration Services
- The SSIS Data Pump - Level 2 of the Stairway to Integration Services
- Adding Rows in Incremental Loads – Level 3 of the Stairway to Integration Services
- Updating Rows in Incremental Loads – Level 4 of the Stairway to Integration Services
- Deleting Rows in Incremental Loads – Level 5 of the Stairway to Integration Services
- Basic SSIS Workflow Management – Level 6 of the Stairway to Integration Services
- Intermediate SSIS Workflow Management – Level 7 of the Stairway to Integration Services
- Advanced SSIS Workflow Management – Level 8 of the Stairway to Integration Services
- Control Flow Task Errors – Level 9 of the Stairway to Integration Services
- Advanced Event Behavior – Level 10 of the Stairway to Integration Services
- Logging – Level 11 of the Stairway to Integration Services
- Advanced Logging – Level 12 of the Stairway to Integration Services
- An Overview of SSIS Variables - Level 13 of the Stairway to Integration Services
- An Overview of Project Conversion - Level 14 of the Stairway to Integration Services
- An Overview of SSIS Parameters - Level 15 of the Stairway to Integration Services
- Flexible Source Locations - Level 16 of the Stairway to Integration Services
- Multiple Flexible Source Locations – Level 17 of the Stairway to Integration Services
- Deployment and Execution – Level 18 of the Stairway to Integration Services
Introduction
In the previous installment we loaded data from multiple files of different formats into different subject areas. In this article we will extend the SSIS Catalog database, SSISDB, and examine alternate methods for executing SSIS packages.
The SSIS Catalog: An Application and a Database
When you strip away the mystique, the SSIS Catalog is an application and a database. The application was developed by Microsoft and is integrated into SQL Server Management Studio (SSMS), but it’s still really just an application and a database – just like the applications and databases you support and develop every day. I briefly described the SSISDB database in Deployment and Execution – Step 18 of the Stairway to Integration Services. I repeat some screenshots below.
Open Object Explorer in SSMS 2012 (or SSMS 2014) and have a look at the tables shown in Figure 1:
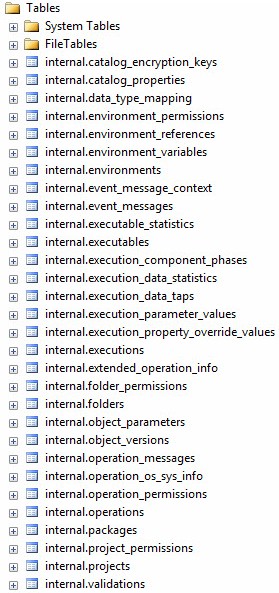
Figure 1
Figure 2 displays a screenshot of the views contained in the SSIS 2012 Catalog:
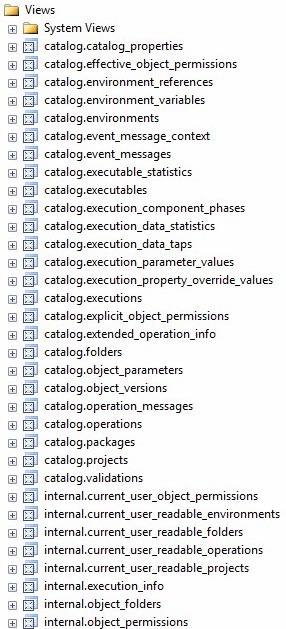
Figure 2
Figure 3 displays a list of Stored Procedures:
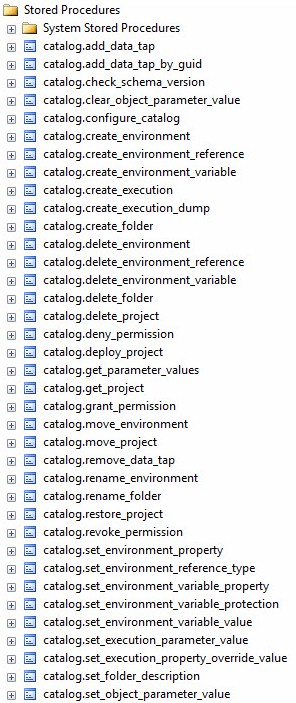
Figure 3
Where Are the Packages in the Catalog?
When you deploy an SSIS project, the project data and metadata are stored in these tables. People often ask me, “Andy, where are the SSIS packages stored in the SSISDB Catalog?” They are stored in the internal.object_versions table. The project, project metadata, and packages are compressed and the compressed data is stored in the object_data field – a varbinary(max) data type column – of the internal.object_versions table.
The packages in a project are coupled; individual package updates cannot be deployed to the SSIS Catalog without deploying all the packages in the project. This design has implications, especially if you wish to deploy changes to only a single package in a project. For that reason, this architecture is a powerful argument for less packages per project; as less packages per project mitigates the impact of package/project coupling. I promise I’m not complaining about this design (not yet, anyway); I am simply pointing out some implications of the design of the SSIS 2012 and 2014 Catalog.
Implications for Execution
As discussed in Deployment and Execution – Step 18 of the Stairway to Integration Services, You can execute an SSIS package in the Catalog by drilling into the SSIS Catalog hierarchy to the Package level, right-clicking the SSIS package you wish to execute, and clicking “Execute…”, as shown in Figure 4:
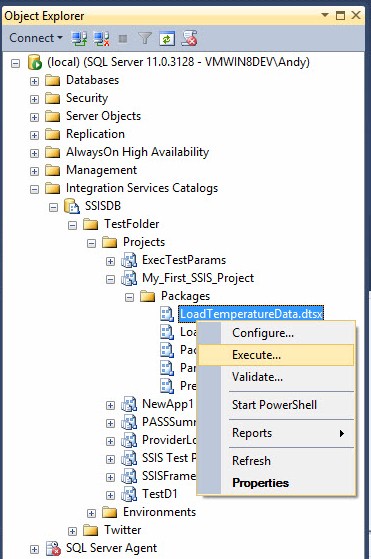
Figure 4
What you cannot do, however, is right-click a Project in the SSIS Catalog and click “Execute.” The option simply doesn’t exist, as shown in Figure 5:
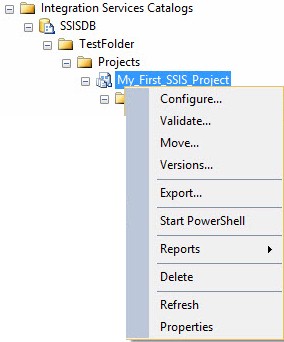
Figure 5
This is not a bad design. But there’s one issue: the packages are coupled at deployment and decoupled at execution time; and this is inconsistent. I can hear some of you thinking, “Is this a big deal, Andy?” The answer is: sometimes, yes it is a big deal.
As someone who has been developing data integration frameworks for a decade (at the time of this writing), I can – and will eventually, I promise – tell you what it takes to support executing all the packages in a project. The first hurdle is execution order. Which package – or packages – execute first? The next hurdle is workflow-related. Do the packages execute serially? In parallel? Or some combination of serial and parallel? Things start to get tricky, rapidly. The amount of metadata required to support such operations increases right along with the complexity of the solution. The SSIS Catalog doesn’t support project execution and, for many users, that’s ok. But for some users this is not ok. For users who need project execution functionality, the SSIS Catalog is incomplete.
I have another issue with project coupling in the SSIS Catalog and Project Deployment Model. If I want to create an SSIS package that executes other SSIS packages, I can either select packages from the File System or from the current SSIS project, but not from another SSIS project. Is this a big deal?
My favorite use case for package reusability is archiving flat files. Years ago, I developed an SSIS package named ArchiveFile.dtsx. I’ve been dragging it around for a long time, modifying it here and there as needed to meet some new requirement. But always, always, maintaining a single copy of this package in each enterprise tier (for example: Development, Test, QA, and Production). ArchiveFile.dtsx is called as part of multiple SSIS applications.
Why is a single copy of this package important in the enterprise? Well, what happens when I discover a bug? If I have one copy of ArchiveFile.dtsx coupled to a dozen projects and deployed to the Catalog, I have to fix the bug in ArchiveFile.dtsx and then replace the package 12 times, or replicate the bug fix 12 times, and then redeploy 12 projects – including every other SSIS package in each project. This is a recipe for producing more bugs. And don’t get me started on the required testing… (Now I’m complaining about the Catalog).
When you right-click a Package and click Execute, the “Execute Package” window displays as shown in Figure 6:
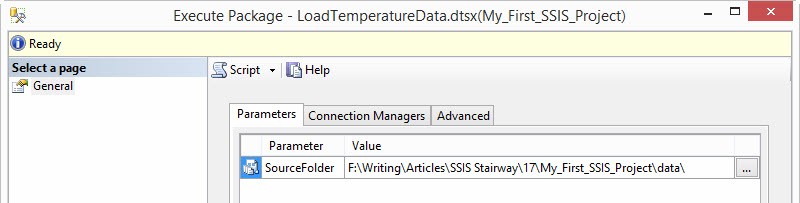
Figure 6
The Execute Package window supports execution configuration. More accurately, the Execute Package window supports configuration of the intent to execute an SSIS package in the Catalog. The Package doesn’t execute until the user starts the execution. I realize this sounds picky of me, but the distinction between an execution and an intent to execution is both subtle and important. Here’s why:
If you have been following along at home, click the “Script” button on the Execute Package window and notice what happens in SSMS, as shown in Figure 7:
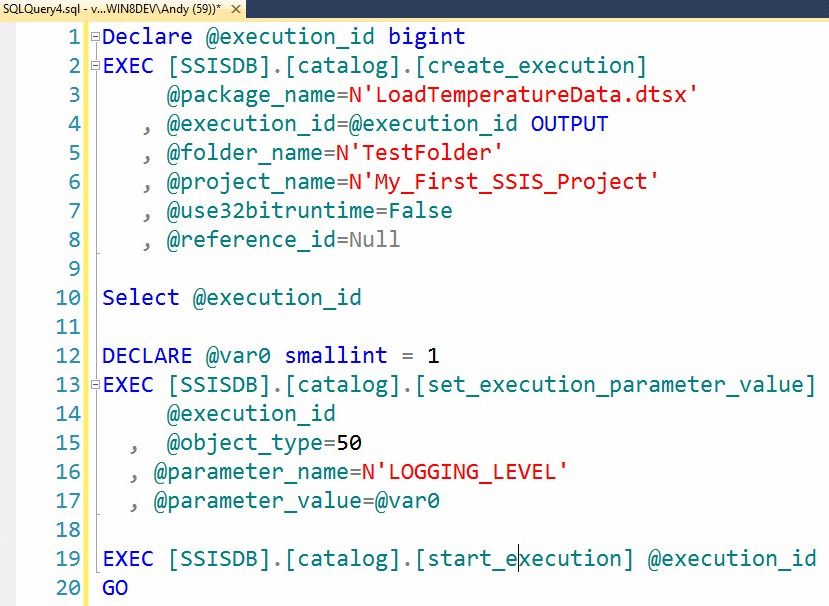
Figure 7
I’ve reformatted the output some. If you execute this T-SQL, the LoadTemperatureData.dtsx package in the My_First_SSIS_Project Catalog project and TestFolder Catalog folder will execute. When I look at this T-SQL script I think, “Hmmm…”.
Considerations for Extending the SSIS Catalog
I write this with the goal of dispelling some of your trepidation. The SSISDB Catalog is just a database and an application. Before we proceed, though, I also want to instill some healthy intimidation related to altering third-party databases. When it comes to integrating with a database over which one has little or no control, there are a couple things you should consider.
The first consideration is whether your extension efforts will reside inside the third-party database or in a separate, companion database. This decision does not exist in a vacuum and one of the most serious implications is referential integrity. If you choose a companion database you are choosing to ignore referential integrity enforcement between your extensions and the third-party database because it is not possible to enforce referential integrity between objects in different databases.
Extending the third-party database by adding objects to the database will support referential integrity, but it poses different challenges. For instance, what happens when the third-party vendor releases a service pack or software patch? Do they drop and rebuild database objects? Do they check for the existence of objects not included in their original or supported design? Some vendors do this, trust me. But even if the vendors don’t perform these checks, how will you maintain your extensions when the inevitable service pack or patch is applied?
If you add your extensions inside the third-party database, how will you maintain separation of concerns – a best practice for software (and database) development – between your functionality and the functionality supplied by the vendor?
Before I share my answers, I want to point out that the best answers to these questions differ from database to database and application to application. There is no right answer; there is only an answer that is right for this database and/or application.
Before I make a decision, I back up the SSISDB database. I highly recommend that you also back up your development version of the database, as shown in Figure 8:
Figure 8
When the Back Up Database window displays, configure the backup appropriately and then click the OK button, as shown in Figure 9:
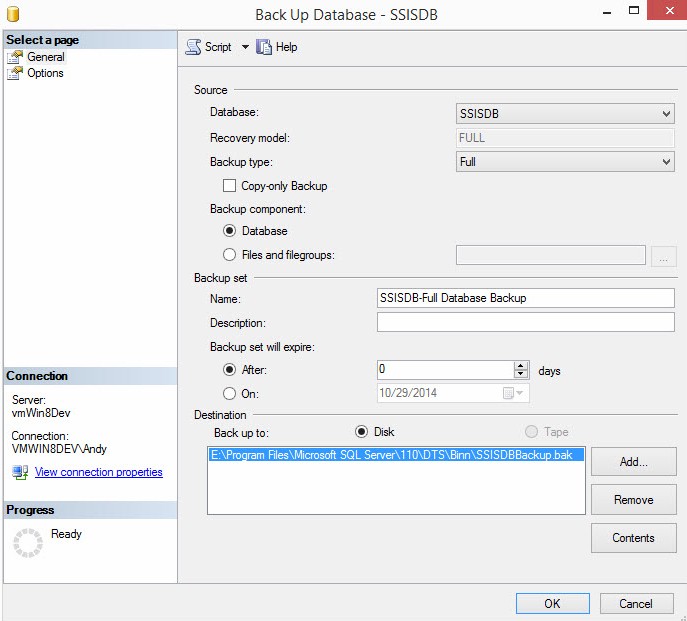
Figure 9
Consider learning more about SQL Server database backup and restore functions from one of the many SQL Server database experts who write for SQL Server Central. There are several books available on the topic as well, including SQL Server 2014 Backup and Recovery by Tim Radney and John Sterrett, SQL Server Backup and Restore by Shawn McGehee, Brad's Sure Guide to SQL Server Maintenance Plans by Brad McGehee, and several others.
Extending the SSIS Catalog
In my example, I choose to create a schema named custom in the SSISDB database. I choose this option because I want to use referential integrity while separating the concerns of my extensions and the Catalog’s off-the-shelf functionality.
I use the T-SQL shown in Listing 1 to create the custom schema. The script is re-executable and satisfies the requirement that the CREATE SCHEMA statement be the only statement in the T-SQL batch in which it executes:
Use SSISDB
Go
print 'Custom Schema'
If Not Exists(Select s.name
From sys.schemas s
Where s.name = 'custom')
begin
print ' - Creating custom schema'
declare @sql varchar(50) = 'Create Schema custom'
exec(@sql)
print ' - Custom schema created'
end
Else
print ' - Custom schema already exists.'
print ''Listing 1
When executed for the first time the script produces the output shown in Figure 10:

Figure 10
The second and subsequent executions of this script produce the output shown in Figure 11:
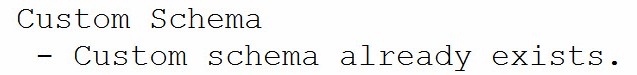
Figure 11
Composing Transact-SQL statements using the If Not Exists syntax makes the code idempotent, which means the T-SQL can be executed repeatedly without ill effect. Adding the print statements provides feedback about which path was taken in the If Not Exists conditional statement. It’s more typing. It’s also better code.
I next create a script to build a stored procedure to encapsulate the three SSIS Catalog stored procedures generated when I clicked the Script button on the Execute Package window (see Figure 6 and Figure 7). Again, I employ idempotent syntax and print-statement feedback. With stored procedures (and functions, views, and many other object types), though, I first drop the stored procedure if it exists – and then re-create it. Why? Because of the way SQL Server keeps track of the metadata associated with custom objects. A short version is: SQL Server captures Data Definition Language (DDL) statements for stored procedures in the sys.sql_modules table. The capture of the DDL takes place when the stored procedure is created, but the captured DDL is not updated when the stored procedure is renamed. One workaround is to always drop and re-create the stored procedure, and this is what I choose to do.
My initial version of a stored procedure named custom.execute_catalog_package is shown in Listing 2:
Use SSISDB
go
print 'Custom.execute_catalog_package stored procedure'
If Exists(Select s.name + '.' + p.name
From sys.procedures p
Join sys.schemas s
On s.schema_id = p.schema_id
Where s.name = 'custom'
And p.name = 'execute_catalog_package')
begin
print ' - Dropping custom.execute_catalog_package'
Drop Procedure custom.execute_catalog_package
print ' - Custom.execute_catalog_package dropped'
end
print ' - Creating custom.execute_catalog_package'
go
Create Procedure custom.execute_catalog_package
@package_name nvarchar(260)
, @folder_name nvarchar(128)
, @project_name nvarchar(128)
, @use32bitruntime bit = False
, @reference_id bigint = NULL
, @logging_level varchar(11) = 'Basic'
As
begin
-- create an Intent-to-Execute
declare @execution_id bigint
exec [SSISDB].[catalog].[create_execution]
@package_name=@package_name
, @execution_id=@execution_id OUTPUT
, @folder_name=@folder_name
, @project_name=@project_name
, @use32bitruntime=@use32bitruntime
, @reference_id=@reference_id
-- Decode and configure the Logging Level
declare @var0 smallint =
Case
When Upper(@logging_level) = 'NONE'
Then 0
When Upper(@logging_level) = 'PERFORMANCE'
Then 2
When Upper(@logging_level) = 'VERBOSE'
Then 3
Else 1 -- Basic
End
exec [SSISDB].[catalog].[set_execution_parameter_value]
@execution_id
, @object_type=50
, @parameter_name=N'LOGGING_LEVEL'
, @parameter_value=@var0
-- Start the execution
exec [SSISDB].[catalog].[start_execution] @execution_id
-- Return the execution_id
Select @execution_id As execution_id
end
go
print ' - Custom.execute_catalog_package created.'
go
Listing 2
Let’s examine the components of this stored procedure, starting with the DROP logic:
If Exists(Select s.name + '.' + p.name
From sys.procedures p
Join sys.schemas s
On s.schema_id = p.schema_id
Where s.name = 'custom'
And p.name = 'execute_catalog_package')
begin
print ' - Dropping custom.execute_catalog_package'
Drop Procedure custom.execute_catalog_package
print ' - Custom.execute_catalog_package dropped'
endThe If conditional uses Transact-SQL to test for the existence of the stored procedure named “execute_catalog_package” in the “custom” schema. If the custom.execute_catalog_package stored procedure exists, the block of statements between the begin and end commands execute. The block starts with a print statement that informs the observer of the intent of the Transact-SQL developer: Dropping custom.execute_catalog_package. The next statement in the block performs the procedure drop: Drop Procedure custom.execute_catalog_package. The final statement in the block informs the observer that the drop occurred without error: Custom.execute_catalog_package dropped.
Had there been an error, the first print statement would have executed. The second print statement may or may not have executed (depending on the severity of the error), but the error would have been noted in red font in the Messages window of SQL Server Management Studio (SSMS).
The next chunk of Transact-SQL informs the observer of the intent to create the custom.execute_catalog_package stored procedure:
print ' - Creating custom.execute_catalog_package' go
The print statement is followed by the “go” batch separator because the Create Procedure statement that follows must be the first statement in a query batch. If you don’t believe me, comment out the go batch separator and observe the results:
Msg 111, Level 15, State 1, Procedure execute_catalog_package, Line 27
'CREATE/ALTER PROCEDURE' must be the first statement in a query batch.
The next chuck of code begins creating the custom.execute_catalog_package stored procedure:
Create Procedure custom.execute_catalog_package @package_name nvarchar(260) , @folder_name nvarchar(128) , @project_name nvarchar(128) , @use32bitruntime bit = False , @reference_id bigint = NULL , @logging_level varchar(11) = 'Basic' As
The stored procedure contains parameters so I can use it to start any SSIS package stored in the SSIS Catalog. Earlier, I stated I did not like the fact the SSIS Catalog doesn’t allow me to execute SSIS packages that reside in other projects or folders. Note that this stored procedure overcomes that limitation by requiring me to pass the name of the folder (@folder_name) and project (@project_name) right alongside the SSIS package name (@package_name).
Where did I get the data type and character-string length of the @package_name, @Folder_name, and @project_name parameters? I looked at the catalog.create_execution stored procedure shown in Figure 12:

Figure 12
I defaulted the remaining three parameters - @use32bitruntime, @reference_id, and @logging_level to values that will be used most often; False, NULL, and 'Basic' respectively.
The next chunk of Transact-SQL in the catalog.create_execution stored procedure calls the Catalog stored procedure catalog.create_execution:
declare @execution_id bigint
exec [SSISDB].[catalog].[create_execution]
@package_name=@package_name
, @execution_id=@execution_id OUTPUT
, @folder_name=@folder_name
, @project_name=@project_name
, @use32bitruntime=@use32bitruntime
, @reference_id=@reference_idI pass every parameter except @logging_level to this stored procedure.
Please note: I am not dissecting what the SSIS Catalog does with these parameters or their values. I maintain I don’t need to know the internals of the SSIS Catalog to create a “wrapper stored procedure,” I merely need to know which stored procedures are called and the order in which they are called.
The next set of Transact-SQL statements decode the Logging Level sent to the @logging_level parameter, then use the decoded value to inform the SSIS Catalog execution of the desired setting:
declare @var0 smallint =
Case
When Upper(@logging_level) = 'NONE'
Then 0
When Upper(@logging_level) = 'PERFORMANCE'
Then 2
When Upper(@logging_level) = 'VERBOSE'
Then 3
Else 1 -- Basic
End
exec [SSISDB].[catalog].[set_execution_parameter_value]
@execution_id
, @object_type=50
, @parameter_name=N'LOGGING_LEVEL'
, @parameter_value=@var0Logging Level is an enumeration:
- 0. None
- 1. Basic
- 2. Performance
- 3. Verbose
In my implementation I default to Basic which is the same default chosen by the SSIS Catalog.
Finally, I call the SSIS Catalog catalog.start_execution stored procedure which executes the package and then return the value of the execution_id:
exec [SSISDB].[catalog].[start_execution] @execution_id -- Return the execution_id Select @execution_id As execution_id
Once deployed, I can test the custom.execute_catalog_package stored procedure by executing the following Transact-SQL statement in SSMS:
Use SSISDB
go
exec custom.execute_catalog_package
@package_name = N'LoadTemperatureData.dtsx'
, @project_name = N'My_First_SSIS_Project'
, @folder_name = N'TestFolder'
The results of the execution will appear as shown in Figure 13:
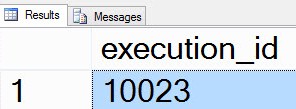
Figure 13
I can view the SSIS Catalog’s built-in Integration Services Dashboard report by right-clicking the SSISDB Catalog, hovering over Reports, then hovering over Standard Reports, and then clicking Integration Services Dashboard as shown in Figure 14:
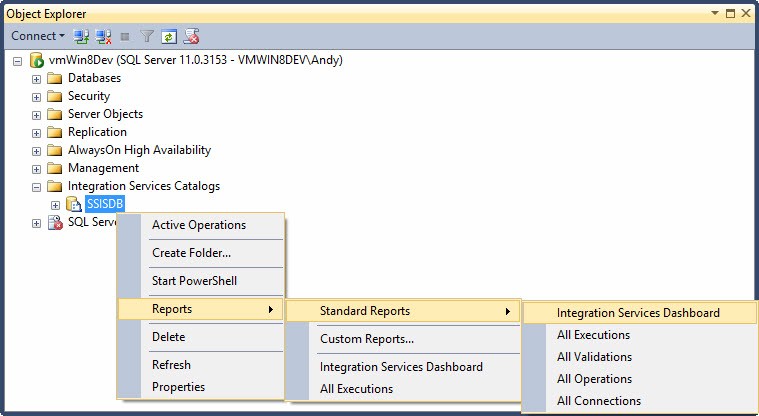
Figure 14
The report displays a really nice summary of the SSIS packages executed in the past 24 hours and appears similar to that shown in Figure 15:
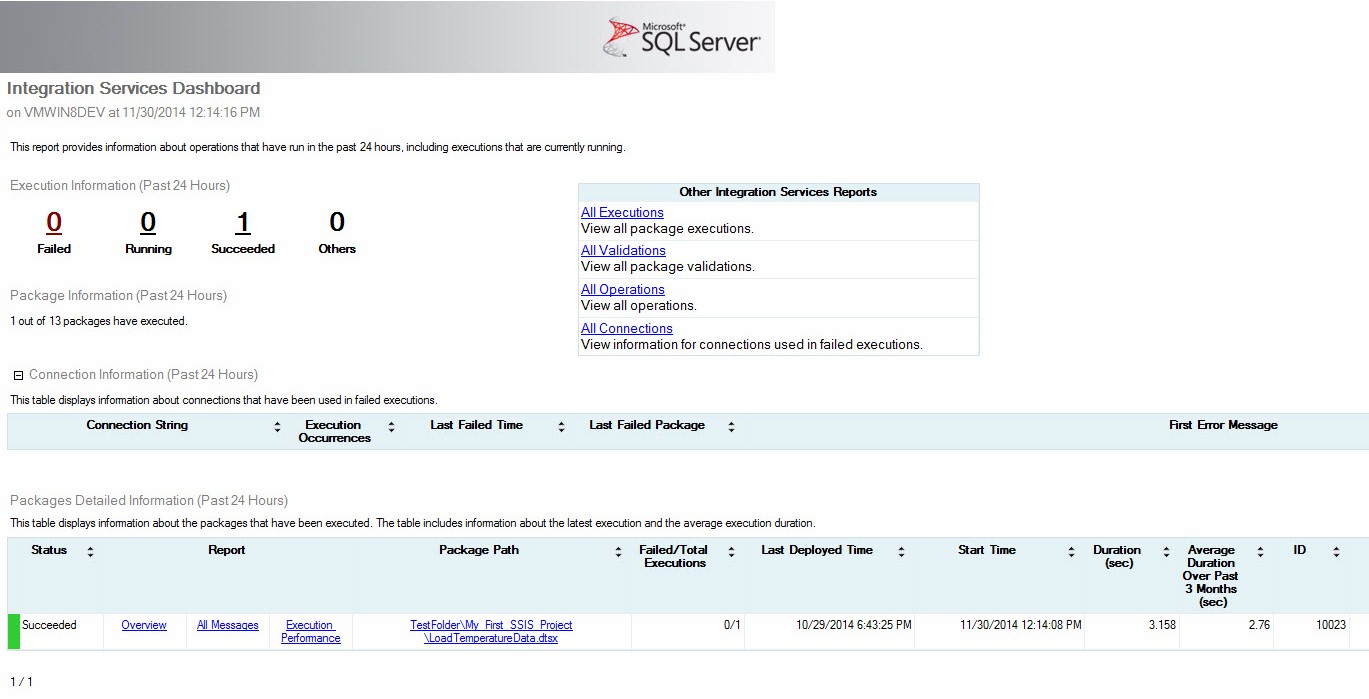
Figure 15
My chief complaint about this report is that, although it is written in SQL Server Reporting Services (SSRS), it is hard-coded into SQL Server Management Studio (SSMS). I would really like to allow more people access to this report, but I don’t necessarily want those people to have access to SSMS’s functionality. This is another complaint I have about the current implementation of the SSIS Catalog.
Conclusion
In this article, we discussed the current design of the SQL Server Integration Services Catalog and some implications for the enterprise posed by this design. We extended SSISDB, the SSIS Catalog database, and examined an alternate method for executing SSIS packages in the SSIS Catalog.
