Why is this query slow?
-
#pastetheplan https://www.brentozar.com/pastetheplan/?id=SJF21m0lU
I'm trying to figure out what's causing this query (part of a stored procedure) to be so slow. The NOLOCK hints were an earlier attempt to stop deadlocks, I'm guessing they are likely no longer necessary.
I did add an index that helped a ton, but this is still pretty slow and I'm not sure what direction to go in next.
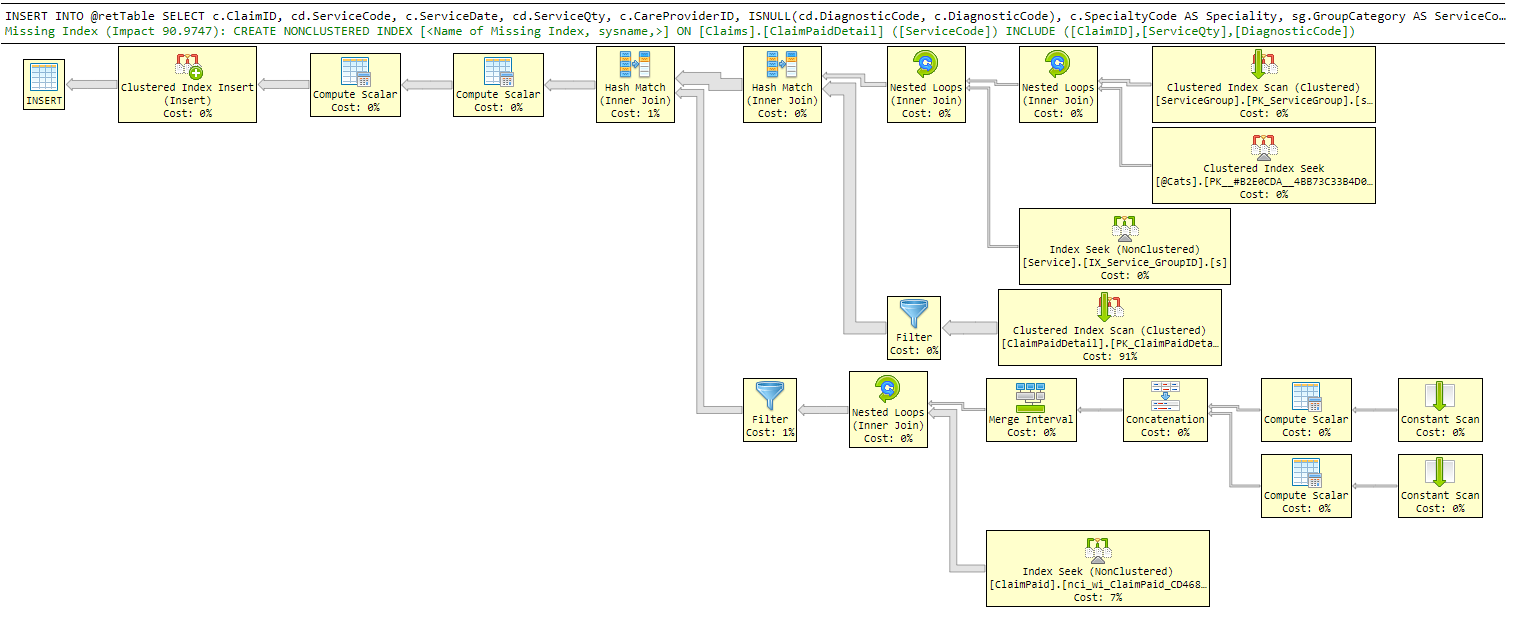
This was the old plan before I added the index it craved:

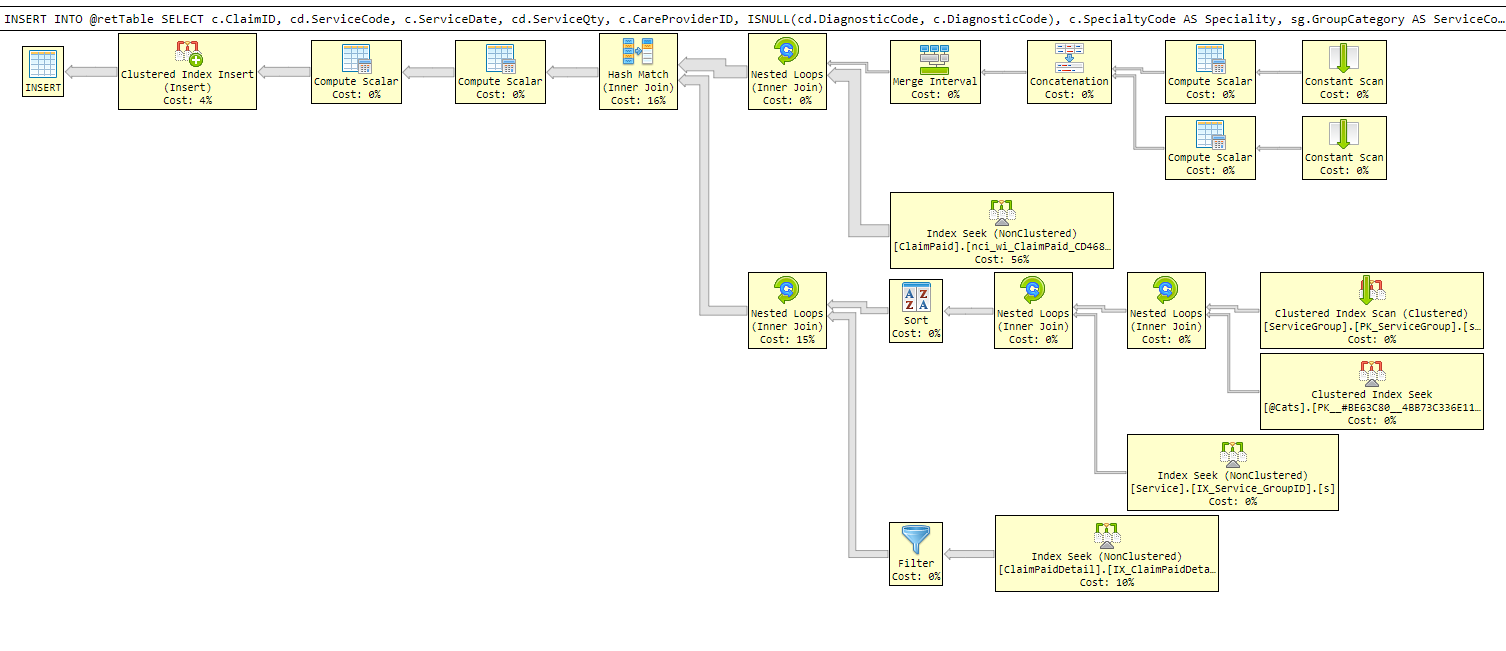
And this is the new/current plan:
-
Would help if you posted the actual execution plan, not a picture of the graphic. There isn't a lot of information available from the picture. Also seeing the code would be helpful as well.
-
It's all in that link: https://www.brentozar.com/pastetheplan/?id=SJF21m0lU
INSERT INTO @retTable
SELECT c.ClaimID, cd.ServiceCode, c.ServiceDate, cd.ServiceQty, c.CareProviderID, ISNULL(cd.DiagnosticCode, c.DiagnosticCode), c.SpecialtyCode AS Speciality,
sg.GroupCategory AS ServiceCodeGroupCategory, 0, NULL
FROM Claims.ClaimPaid c WITH(NOLOCK)
INNER JOIN Claims.ClaimPaidDetail cd WITH(NOLOCK) ON c.ClaimID = cd.ClaimID AND c.PatientID = ISNULL(@PatientID, c.PatientID) AND
c.CareProviderID = ISNULL(@CareProviderID, c.CareProviderID) AND
c.ServiceDate > @MinDate AND c.ServiceDate < @MaxDate --AND -- NOTE: want claim date to be GREATER @MinDate, not >=, want claim date to be LESS than @MaxDate not <=
--c.SpecialtyCode = @SpecialtyCode -- this line is to limit the specialty
INNER JOIN Services.[Service] s WITH(NOLOCK) ON cd.ServiceCode = s.Code
INNER JOIN Services.ServiceGroup sg WITH(NOLOCK) ON s.GroupID = sg.GroupID
INNER JOIN @Cats ct ON sg.GroupCategory = ct.Category -
Can you give us the ACTUAL explain plan, not the estimated one.
INSERT INTO @retTable
SELECT c.ClaimID, cd.ServiceCode, c.ServiceDate, cd.ServiceQty, c.CareProviderID, ISNULL(cd.DiagnosticCode, c.DiagnosticCode), c.SpecialtyCode AS Speciality,
sg.GroupCategory AS ServiceCodeGroupCategory, 0, NULL
FROM Claims.ClaimPaid c WITH(NOLOCK)
INNER JOIN Claims.ClaimPaidDetail cd WITH(NOLOCK) ON c.ClaimID = cd.ClaimID AND
c.PatientID = ISNULL(@PatientID, c.PatientID) AND
c.CareProviderID = ISNULL(@CareProviderID, c.CareProviderID) AND
c.ServiceDate > @MinDate AND c.ServiceDate < @MaxDate --AND -- NOTE: want claim date to be GREATER @MinDate, not >=, want claim date to be LESS than @MaxDate not <=
--c.SpecialtyCode = @SpecialtyCode -- this line is to limit the specialty
INNER JOIN Services.[Service] s WITH(NOLOCK) ON cd.ServiceCode = s.Code
INNER JOIN Services.ServiceGroup sg WITH(NOLOCK) ON s.GroupID = sg.GroupID
INNER JOIN @Cats ct ON sg.GroupCategory = ct.CategoryI would change
c.PatientID = ISNULL(@PatientID, c.PatientID) AND
c.CareProviderID = ISNULL(@CareProviderID, c.CareProviderID) AND
to
(c.PatientID = @PatientID or @PatientID is null) AND
(c.CareProviderID = @CareProviderID or @CareProviderID is null) AND
to see if it improves.
-
You could try one of the following hints at the end of the SQL:
OPTION (OPTIMIZE FOR UNKNOWN)
OPTION (RECOMPILE) -
If you are looking to filter this based on whether or not the parameter @PatientID and/or @CareProviderID is passed in - then include that in the WHERE clause instead of the join.
By putting it in the join - SQL Server is performing an index seek but estimating 226,448 rows and an extremely large number of reads to get that data (1.84844e+06 estimated reads).
Move the date checks to the where clause also...
Insert Into @retTable
Select c.ClaimID
, cd.ServiceCode
, c.ServiceDate
, cd.ServiceQty
, c.CareProviderID
, isnull(cd.DiagnosticCode, c.DiagnosticCode)
, c.SpecialtyCode As Speciality
, sg.GroupCategory As ServiceCodeGroupCategory
, 0
, Null
From Claims.ClaimPaid c With(nolock)
Inner Join Claims.ClaimPaidDetail cd With(nolock) On c.ClaimID = cd.ClaimID
Inner Join Services.[Service] s With(nolock) On cd.ServiceCode = s.Code
Inner Join Services.ServiceGroup sg With(nolock) On s.GroupID = sg.GroupID
Inner Join @Cats ct On sg.GroupCategory = ct.Category
Where c.ServiceDate > @MinDate
And c.ServiceDate < @MaxDate
And (c.PatientID = @PatientID Or @PatientID Is Null)
And (c.CareProviderID = @CareProviderID Or @CareProviderID Is Null)Verify the relationship between Claims.ClaimPaid and Claims.ClaimPaidDetail - make sure you include all columns from Claims.ClaimPaid that are related (for example - does Claims.ClaimPaidDetail contain the PatientID column and is that column part of the primary key in Claims.ClaimPaid?).
Jeffrey Williams
“We are all faced with a series of great opportunities brilliantly disguised as impossible situations.”― Charles R. Swindoll
How to post questions to get better answers faster
Managing Transaction Logs -
First, this is a catch all query. If either of the variables @PatientID or @CareProviderID are null you want to return all rows of data for PatientID and/or CareProviderID.
There is also residule IO involved that could be causing some of the slowness.
One suggestion since this is in a stored procedure would be to select the data from Claims.ClaimsPaid into a temporary table (perhaps #ClaimPaid) indexed on ClaimID and use that table in your query.
-
Another option is to use dynamic SQL. For any input parameters that are null the AND clause could be removed.
For example, if @PatientID were null you could remove this line from the SQL:
And (c.PatientID = @PatientID Or @PatientID Is Null)
If @PatientID were not null then you could change it to this:
And c.PatientID = @PatientID
Are you really using SQL Server 7, 2000?
- Jonathan AC Roberts wrote:
Another option is to use dynamic SQL. For any input parameters that are null the AND clause could be removed. For example, if @PatientID were null you could remove this line from the SQL:
And (c.PatientID = @PatientID Or @PatientID Is Null)
Having written quite a bit of dynamic SQL myself that is the direction I would go. If you aren't comfortable writing dynamic SQL it can be intimidating as it can be harder to debug depending on the complexity of the code. For this, it shouldn't be too hard.
-
Sorry, I had missed there was a second thread on this item. I agree with Jeffery Williams comment about determining why it won't use your ServiceDate index. Looking at the indexes you show in the other post, it looks like there may be some duplicate indexes that could be removed, could be worth investigating. Could we see what the actual definition of these indexes are, with their included columns? It seems to be picking poor index choices for ClaimPaid and ClaimPaidDetail.
- kfrancis25 wrote:
It's all in that link: https://www.brentozar.com/pastetheplan/?id=SJF21m0lU
INSERT INTO @retTable
SELECT c.ClaimID, cd.ServiceCode, c.ServiceDate, cd.ServiceQty, c.CareProviderID, ISNULL(cd.DiagnosticCode, c.DiagnosticCode), c.SpecialtyCode AS Speciality,
sg.GroupCategory AS ServiceCodeGroupCategory, 0, NULL
FROM Claims.ClaimPaid c WITH(NOLOCK)
INNER JOIN Claims.ClaimPaidDetail cd WITH(NOLOCK) ON c.ClaimID = cd.ClaimID AND c.PatientID = ISNULL(@PatientID, c.PatientID) AND
c.CareProviderID = ISNULL(@CareProviderID, c.CareProviderID) AND
c.ServiceDate > @MinDate AND c.ServiceDate < @MaxDate --AND -- NOTE: want claim date to be GREATER @MinDate, not >=, want claim date to be LESS than @MaxDate not <=
--c.SpecialtyCode = @SpecialtyCode -- this line is to limit the specialty
INNER JOIN Services.[Service] s WITH(NOLOCK) ON cd.ServiceCode = s.Code
INNER JOIN Services.ServiceGroup sg WITH(NOLOCK) ON s.GroupID = sg.GroupID
INNER JOIN @Cats ct ON sg.GroupCategory = ct.CategoryA lot of people will typically avoid links even to well known sites. Also, even well known sites can drop like a hat in the future and then you post is no longer useful to others. It's always best to post actual execution plans as a direct attachment on this site.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
NOLOCK everywhere <sigh>
This stuff is going to prevent good index & statistics use:
AND c.PatientID = ISNULL(@PatientID, c.PatientID)
AND c.CareProviderID = ISNULL(@CareProviderID, c.CareProviderID)So, remove them. How though is the fun part. The OR proposal above will work, but might not perform better. The ad hoc approach can get you the customized plans for each value, but can be a little sloppy to maintain. I like the idea of wrapper procedures. Instead of trying to write one, perfect, big query, write three or four small ones and have a procedure that determines which of the three or four it runs. That way, everything can be more focused. It can be almost as much work to maintain as the ad hoc aproach, but it'll be much more clear.
Also, I think there's a view or function that we can't see. Where the heck is that Sort operator coming from? Same thing goes for that bit with the Constant Scan's that's leading to the initial join. That's all code that we can't see in your query. So, there's more here to tune that immediately meets the eye.
"The credit belongs to the man who is actually in the arena, whose face is marred by dust and sweat and blood"
- Theodore RooseveltAuthor of:
SQL Server Execution Plans
SQL Server Query Performance Tuning -
The Sort operation is coming into play because it has chosen poorly for which index on ClaimPaidDetail to use. The way the query is written, it looks like ClaimPaid.ServiceDate looks like the only definite parameter used here, so I would think it should be using the index on ClaimPaid that starts with ServiceDate to limit the reads on that table, and then joining to ClaimPaidDetail on ClaimID but it's using neither of those indexes.
I'm also thinking that if we saw the actual index definitions with their include columns it might be easier to understand, along with the actual values of the 3 variables here used to generate this plan.
-
But why a sort. There's no ORDER BY and the join is a Nested Loops, so order is not required. That's an odd choice in the plan.
"The credit belongs to the man who is actually in the arena, whose face is marred by dust and sweat and blood"
- Theodore RooseveltAuthor of:
SQL Server Execution Plans
SQL Server Query Performance Tuning -
I love all the input everyone, really - lots of information to digest here. I'll try and get that information (and the actual execution plan) asap.
My god, why didn't I find this place sooner. I might have more hair on my head.
Viewing 15 posts - 1 through 15 (of 20 total)
You must be logged in to reply to this topic. Login to reply