Size of DB Log File
-
hi
I was looking at the size of my db. The log looks really big. It is supposed to be that big?

here is the query i used to get this information:
SELECT
mdf.database_id,
mdf.name,
mdf.physical_name as data_file,
ldf.physical_name as log_file,
db_size_MB = CAST((mdf.size * 8.0)/1024 AS DECIMAL(8,2)),
log_size_MB = CAST((ldf.size * 8.0 / 1024) AS DECIMAL(8,2))
FROM (SELECT * FROM sys.master_files WHERE type_desc = 'ROWS' ) mdf
JOIN (SELECT * FROM sys.master_files WHERE type_desc = 'LOG' ) ldf
ON mdf.database_id = ldf.database_idThank you
-
Seems a little excessive, a 600GB log for a 17.5GB data space.
But without knowing the workload we cannot give you a definitive answer. But something caused the log to grow that much.
What I would look at is,
1. What is the recovery model of that databases FULL/BULK/SIMPLE
2. If FULL/BULK are log backups being taken
3. The "log_wait_reuse_desc" value in sys.databases
If the DB is in FULL/BULK and no log backups are being taken, then that is an immediate red flag.
Time to go ask the business of the RTO and RPO for that DB and if that RPO is less than your full backup schedule, set log backups on a schedule accordingly to match RPO.
If say you backup the DB fully every 24 hours, and the business say well yeah losing 24 hours worth of data isn't critical to operation, then maybe you could look at setting the DB to SIMPLE and shrinking the log.
If the log_wait_reuse_desc is anything other than LOG_BACKUP then you would need to remediate what the cause of that alternative value is.
Once you have determined what action to take, setting up log backups / switching to simple etc and the action has been taken, then you could look at shrinking the log to something more reasonable and monitoring what causes log growth so you know for reference what is causing your log to grow.
- Ant-Green wrote:
Seems a little excessive, a 600GB log for a 17.5GB data space.
But without knowing the workload we cannot give you a definitive answer. But something caused the log to grow that much.
What I would look at is, 1. What is the recovery model of that databases FULL/BULK/SIMPLE 2. If FULL/BULK are log backups being taken 3. The "log_wait_reuse_desc" value in sys.databases
If the DB is in FULL/BULK and no log backups are being taken, then that is an immediate red flag.
Time to go ask the business of the RTO and RPO for that DB and if that RPO is less than your full backup schedule, set log backups on a schedule accordingly to match RPO.
If say you backup the DB fully every 24 hours, and the business say well yeah losing 24 hours worth of data isn't critical to operation, then maybe you could look at setting the DB to SIMPLE and shrinking the log.
If the log_wait_reuse_desc is anything other than LOG_BACKUP then you would need to remediate what the cause of that alternative value is.
Once you have determined what action to take, setting up log backups / switching to simple etc and the action has been taken, then you could look at shrinking the log to something more reasonable and monitoring what causes log growth so you know for reference what is causing your log to grow.
thank you for your reply. my answers to your questions are below:
workload - I study the markets as a hobby. I have an SSIS package that downloads files from the service provider and then import them into SS. I have many SP that are mostly aggregation queries. I run queries against the DB to get market statistics. No real-time DB updates, no real-time running SP etc.
recovery model - I just use the default ones when I select DB -> Tasks -> Back Up. It says FULL.
If FULL/BULK are log backups being taken - I do not know how to check this. How would I check?
log_wait_reuse_desc value - it says "LOG_BACKUP"
RTO and RPO - this is a hobby of mine so there is no dependency on the work I do. That is, no one is impacted but me. So if something fails then I will spend whatever time it takes to fix it. There is no sense of urgency.
Here is the part that continues to confuse me....
600 GB seems way too big. The reason why this is super concerning is that I am only testing my DB project using ONE security. Even the data size 17.5 GB is way too big. The historical CSV files I import into SS are in total (10 plus years of daily data) is only about 1 GB. If the RAW data is 1GB then how does SS get 17.5 GB for the same data?? Doesn't make sense to me. Once my testing is done then I will order the entire stock market data. The uncompressed size of those files is close to 600GB. If a 17.5GB DB produces a 600 GB log file then I am screwed big time when the full history of all stocks is imported into SS. Something isn't right with the test DB. It should not be this big. I just don't know how to fix it. I am a rookie. Any help you can offer to reduce the size to something more reasonable would be much appreciated.
-
OK, so lets tackle the log problem first.
As you say its a hobby and no criticality if something went wrong with the DB, then you could most likely get away with SIMPLE recovery mode, and as it is waiting for a LOG_BACKUP that again notes your in FULL/BULK mode and not doing transaction logs.
Run the following, making sure you substitute <InsertYourDBNameHere> for the name of the database
ALTER DATABASE <InsertYourDBNameHere> SET RECOVERY SIMPLE;
GO
USE [<InsertYourDBNameHere]
GO
CHECKPOINT
GO
DBCC SHRINKFILE (2,1024)
GOThis will set the DB to simple mode so that the transaction log can be truncated and then it will shrink it to 1GB.
Would then recommend getting a copy of the free eBook of log management, so that you can further understand how to better manage transaction logs.
Once this becomes more than a hobby though and you need data being backed up frequently, you will need to change recovery back to full and ensure you are doing backups which meet the acceptable data loss frequency.
Chapter 5 of that book details how to manage the log and perform log backups.
-
For the data, do you do deletes of the data? Are the tables all have a clustered index? Are any of them heaps?
Database design can play a strong factor in storage, especially if the DB isn't normalised well enough and data is duplicated, or if deletes happen on heap tables without specifying tablock as cleanup cannot cleanup those rows, so while they are deleted logically, they are not physically.
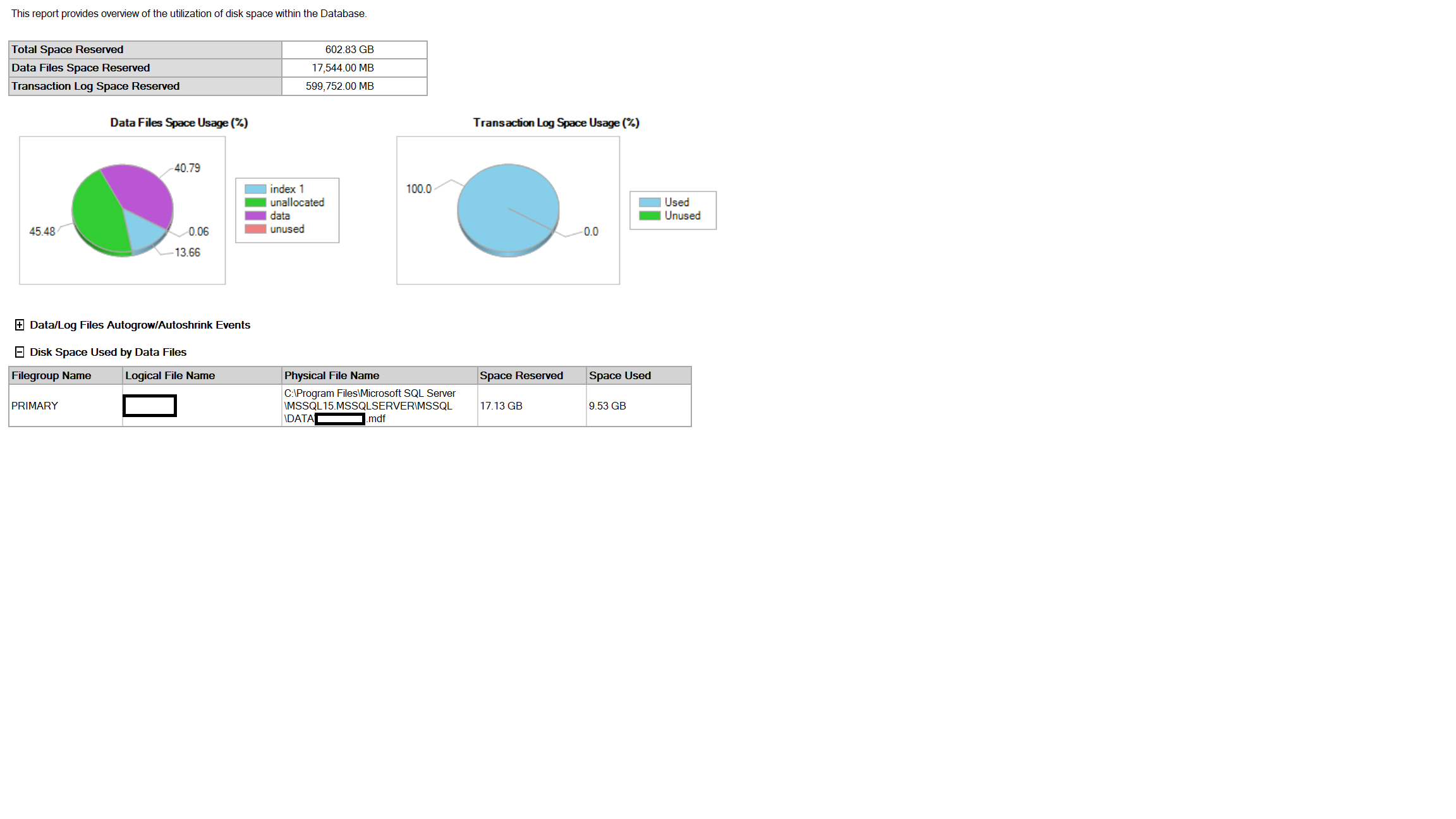
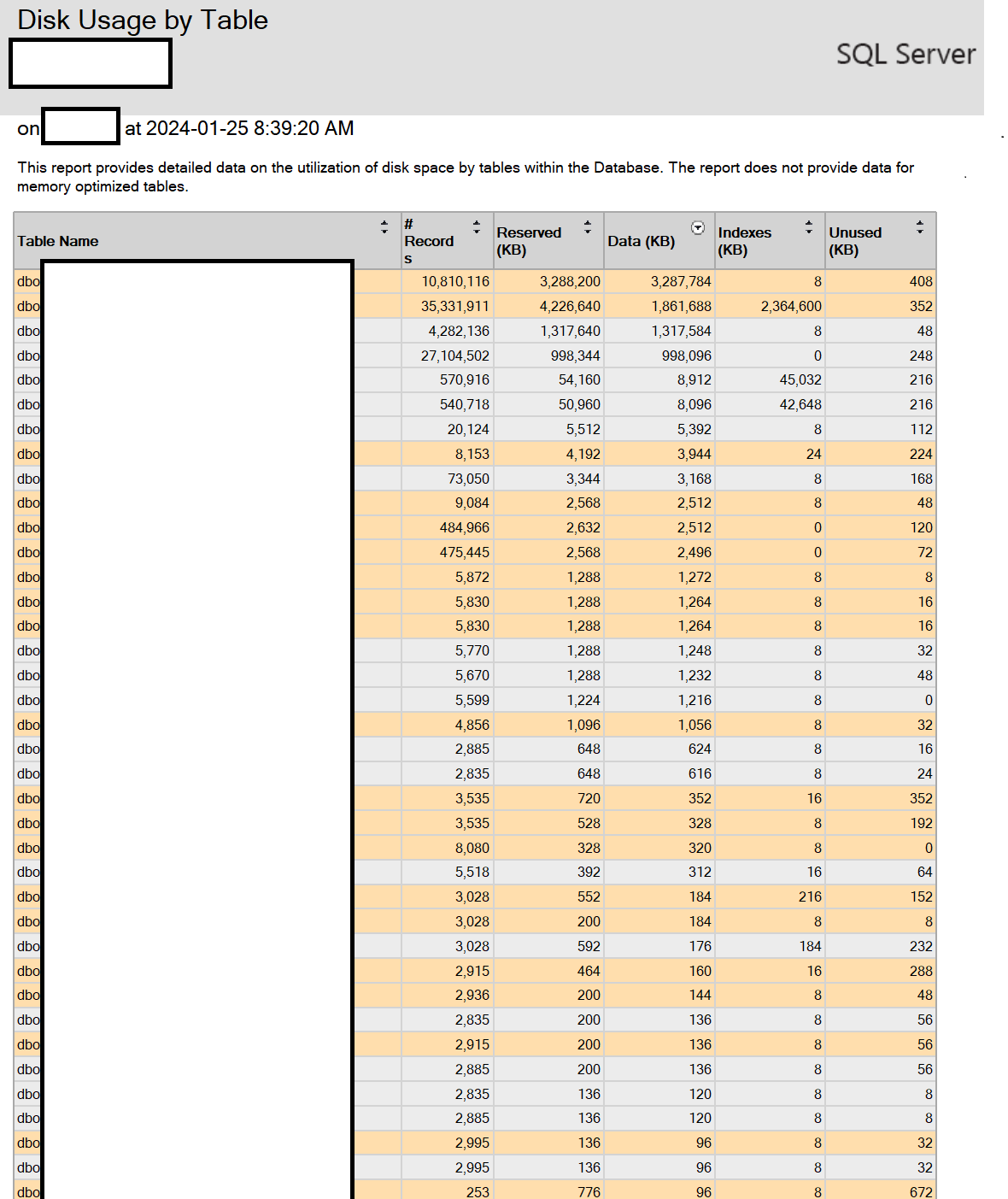
Right click on the database in SSMS, do to reports, then look at disk usage reports and disk usage by top tables.
This will give you a breakdown of allocated/used/unused space along with a list of table holding the most data space.
This will then give you a basis on what to look at, e.g adding clustered indexes to table which don't have one. Maybe you have to many indexes on the tables so you may need to remove some eg where data size is a few MB but index size is many GB, that would say you have to many indexes.
But again it all comes down to design of the DB
- Ant-Green wrote:
OK, so lets tackle the log problem first. As you say its a hobby and no criticality if something went wrong with the DB, then you could most likely get away with SIMPLE recovery mode, and as it is waiting for a LOG_BACKUP that again notes your in FULL/BULK mode and not doing transaction logs.
Run the following, making sure you substitute <InsertYourDBNameHere> for the name of the database
ALTER DATABASE <InsertYourDBNameHere> SET RECOVERY SIMPLE;
GO
USE [<InsertYourDBNameHere]
GO
CHECKPOINT
GO
DBCC SHRINKFILE (2,1024)
GOThis will set the DB to simple mode so that the transaction log can be truncated and then it will shrink it to 1GB.
Would then recommend getting a copy of the free eBook of log management, so that you can further understand how to better manage transaction logs.
Once this becomes more than a hobby though and you need data being backed up frequently, you will need to change recovery back to full and ensure you are doing backups which meet the acceptable data loss frequency.
Chapter 5 of that book details how to manage the log and perform log backups.
I did a bit of research on full vs simple on microsoft website:
Please correct me if my understanding is wrong...full allows for restore to happen at points in time but simple only allows one restore point. plus simple doesn't back up logs.
here is my db layout...
I have two components...one is SP/tables and other is data. The SP/table definitions is most crucial. My hobby fails if I lose them. Losing data is not a big deal. My SSIS package downloads the csv files from SFTP site and saves them to my c-drive after the files are imported into SS. If I lose data then I can re-run SSIS and re-import the data from the c-drive. The SFTP site removes the files after 30 days so I have to download them to save a local copy. Then I have to re-build the indexes. This is time consuming but there is a valid solution to recovering the data.
I will always backup the DB after I make changes to the SP or tables so I have a spare copy of the SP/tables. This is because my hobby fails if I lose the SP/tables.
Given this, I think simple is the best approach for me. I don't really need full. I am not really sure what the logs add to my overall design goals. What are your thoughts?
- Ant-Green wrote:
For the data, do you do deletes of the data? Are the tables all have a clustered index? Are any of them heaps?
Database design can play a strong factor in storage, especially if the DB isn't normalised well enough and data is duplicated, or if deletes happen on heap tables without specifying tablock as cleanup cannot cleanup those rows, so while they are deleted logically, they are not physically.
Right click on the database in SSMS, do to reports, then look at disk usage reports and disk usage by top tables.
This will give you a breakdown of allocated/used/unused space along with a list of table holding the most data space.
This will then give you a basis on what to look at, e.g adding clustered indexes to table which don't have one. Maybe you have to many indexes on the tables so you may need to remove some eg where data size is a few MB but index size is many GB, that would say you have to many indexes.
But again it all comes down to design of the DB
when I first started on my hobby I had no knowledge of SS or DB. I learned as I go along. Hindsight is 20/20 and looking back I should have made better choices. So my design isn't the greatest but to change it is alot of work. I am ok with the re-design if it make sense. I will likely have to do some work when I get the full data.
here is how the SP/DB is laid out... the SSIS package downloads data from SFTP site and imports them into SS. Once this is done then SP are run within the SSIS package. The problem is the following...the SP will truncate tables and re-populate the ENTIRE table again. For example, there is daily data from the service provider so it doesn't make sense to re-calculate previous days data. That data didn't change. The only change is today's data. It makes sense to do the SP on the NEW data not ALL data. This is a serious design flaw. In hindsight, it should be doing appends to existing data not re-calculate old + new data. This design flaw has serious performance issues when my DB gets the full dataset not the one security I currently have. I don't need the SSIS package everyday. Currently, I run it on Fridays after the trading week is done. So I will see how the performance is when I get the full dataset to see if a re-design makes sense or not.
You raise good points when you say "while they are deleted logically, they are not physically". I am constantly deleting so could that be an issue? I had the same problem in MS Access. I delete data but the DB size didn't go down. I had to reshrink the DB manually each time in Access. Does SS work the same way?
here is my disk usage. I have clustered indexes setup. I don't think there are heaps but I will have to double-check. does anything look unusual?
-
I will jump in here - if you are backing up the database after you load new data and you are not modifying that data directly, then simple recovery will allow you to restore to the latest backup. If you are editing the data and need to be able to recover after those edits - then you would probably want full recovery.
It sounds like you don't need that though.
Once a data file grows - it will not automatically shrink, and if it does you want to disable that option. Shrinking a data file will cause logical fragmentation in the database and if you are constantly shrinking/growing the data file it is going to cause file fragmentation. As it looks now - your data file has enough space available for growth and normal operations so no need to shrink or grow.
The biggest issues is your transaction log - once you switch to simple, shrink the log file using DBCC SHRINKFILE as outlined above, except with the following changes:
- Modify the default growth setting for the files. You want those set to a fixed size and not a percentage. I would recommend either 256MB or 512MB for the growth sizes.
- Once you have those set - shrink the log file as much as possible. Once the file is at a size less than your growth - manually grow the file to the fixed size. For example - if you set it to 256MB then manually set the size to 256MB. Any subsequent growths use that size - so once it grows automatically it will be sized at 512MB (increments of 256MB).
As for your process - performing a full refresh of the data in the tables isn't a problem here. You are not really looking at a large enough process to go through the time and effort to build an incremental load process. With that said, it wouldn't hurt to go through that exercise just to learn how to do it.
Jeffrey Williams
“We are all faced with a series of great opportunities brilliantly disguised as impossible situations.”― Charles R. Swindoll
How to post questions to get better answers faster
Managing Transaction Logs -
thank you everyone for your feedback.
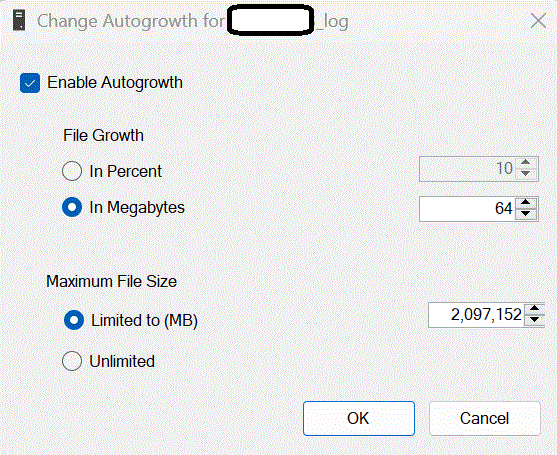
I found this setting for the DB:
Look at that max size! so huge! If I change that to say 1GB max then will that also delete the current 600 GB log? Or do I have to separately reduce the size (after I update above to 1 GB max)?
-
No - you don't need to change the max size as that only limits how large the file can get when it auto grows. The auto growth setting is a fixed size (64MB) - which is okay but probably too small for what you are doing.
The transaction log is make up of virtual log files and are utilized in a circular manner. Logging starts in the first VLF - proceeds to the next VLF - and when it gets to the end of the physical file, loops back to the first open VLF in the file if that VLF has been marked as reusable.
VLF's get marked as reusable once the transaction has been committed and hardened - and if in full/bulk recovery after a transaction log backup is performed. If all VLF's are in-use when it reaches the end of the physical file - the physical file is grown at the defined auto growth setting, creating new VLF's within that new space allocated to the file.
How many VLF's are created depends on the size of the log file and how large the growth setting. This article explains how the transaction log is used - and how VLF's are created:
Jeffrey Williams
“We are all faced with a series of great opportunities brilliantly disguised as impossible situations.”― Charles R. Swindoll
How to post questions to get better answers faster
Managing Transaction Logs -
The problem is very likely that you're simply not doing any log file backups. Full backups do nothing to clear the log file.
If you want to be able to do Point-in-Time recovery, then you need to use the FULL Recovery Model along with FULL Backups AND LOG File backups on a regular basis. Otherwise, the log file will continue to grow forever or until the disk runs out of space.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)

Viewing 11 posts - 1 through 11 (of 11 total)
You must be logged in to reply to this topic. Login to reply