Longest Common Substring in an ITVF
-
So as not to hijack an unrelated thread I started a new topic. This is a continuation of a discussion I was having with Eirikur Eiriksson in this thread: http://www.sqlservercentral.com/Forums/Topic1749223-3690-3.aspx
.
PLEASE FORGIVE THE LITTLE MINI ARTICLE... I wanted to be as detailed as possible since Eirikur was nice enough to help with this. Feel free to join in and/or ask for any clarification...
I'm going to keep this as pithy as possible... I am trying to develop an iTVF function to calculate the longest common substring between two strings which performs better that Phil Factor's version when comparing strings longer than ~500 characters.
Here's my Solution:
/****************************************************************************************
(1) My solution uses NGrams (note the 3 Examples)
****************************************************************************************/;
CREATE FUNCTION dbo.NGrams8k
(
@string varchar(8000), -- Input string
@N int -- requested token size
)
/****************************************************************************************
Purpose:
A character-level @N-Grams function that outputs a contiguous stream of @N-sized tokens
based on an input string (@string). Accepts strings up to 8000 varchar characters long.
For more information about N-Grams see: http://en.wikipedia.org/wiki/N-gram.
Compatibility:
SQL Server 2008+ and Azure SQL Database
Syntax:
--===== Autonomous
SELECT position, token FROM dbo.NGrams8k(@string,@N);
--===== Against a table using APPLY
SELECT s.SomeID, ng.position, ng.string
FROM dbo.SomeTable s
CROSS APPLY dbo.NGrams8K(s.SomeValue,@N) ng;
Parameters:
@string = The input string to split into tokens.
@N = The size of each token returned.
Returns:
Position = bigint; the position of the token in the input string
token = varchar(8000); a @N-sized character-level N-Gram token
Examples:
--===== Turn the string, 'abcd' into unigrams, bigrams and trigrams
SELECT position, token FROM dbo.NGrams8k('abcd',1); -- unigrams (@N=1)
SELECT position, token FROM dbo.NGrams8k('abcd',2); -- bigrams (@N=2)
SELECT position, token FROM dbo.NGrams8k('abcd',3); -- trigrams (@N=1)
--===== How many times the substring "AB" appears in each record
DECLARE @table TABLE(stringID int identity primary key, string varchar(100));
INSERT @table(string) VALUES ('AB123AB'),('123ABABAB'),('!AB!AB!'),('AB-AB-AB-AB-AB');
SELECT string, occurances = COUNT(*)
FROM @table t
CROSS APPLY dbo.NGrams8k(t.string,2) ng
WHERE ng.token = 'AB'
GROUP BY string;
Developer Notes:
1. This function is not case sensitive
2. Many functions that use NGrams8k will see a huge performance gain when the optimizer
creates a parallel query plan. One way to get a parallel query plan (if the optimizer
does not chose one) is to use make_parallel by Adam Machanic which can be found here:
sqlblog.com/blogs/adam_machanic/archive/2013/07/11/next-level-parallel-plan-porcing.aspx
3. When @N is less than 1 or greater than the datalength of the input string then no
tokens (rows) are returned.
4. This function can also be used as a tally table with the position column being your
"N" row. To do so use REPLICATE to create an imaginary string, then use NGrams8k to
split it into unigrams then only return the position column. NGrams8k will get you up
to 8000 numbers. There will be no performance penalty for sorting by position in
ascending order but there is for sorting in descending order. To get the numbers in
descending order without forcing a sort in the query plan use the following formula:
N = <highest number>-position+1.
Pseudo Tally Table Examples:
--===== (1) Get the numbers 1 to 100 in ascending order:
SELECT N = position FROM dbo.NGrams8k(REPLICATE(0,100),1);
--===== (2) Get the numbers 1 to 100 in descending order:
DECLARE @maxN int = 100;
SELECT N = @maxN-position+1
FROM dbo.NGrams8k(REPLICATE(0,@maxN),1)
ORDER BY position;
-- note that you don't need a variable, I used one to make this easier to understand.
----------------------------------------------------------------------------------------
Revision History:
Rev 00 - 20140310 - Initial Development - Alan Burstein
Rev 01 - 20150522 - Removed DQS N-Grams functionality, improved iTally logic. Also Added
conversion to bigint in the TOP logic to remove implicit conversion
to bigint - Alan Burstein
Rev 03 - 20150909 - Added logic to only return values if @N is greater than 0 and less
than the length of @string. Updated comment section. - Alan Burstein
Rev 04 - 20151029 - Added ISNULL logic to the TOP clause for the @string and @N
parameters to prevent a NULL string or NULL @N from causing "an
improper value" being passed to the TOP clause. - Alan Burstein
****************************************************************************************/
RETURNS TABLE WITH SCHEMABINDING AS RETURN
WITH
L1(N) AS
(
SELECT 1
FROM (VALUES -- 90 NULL values used to create the CTE Tally table
(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),
(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),
(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),
(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),
(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),
(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),
(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),
(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),
(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL)
) t(N)
),
iTally(N) AS -- my cte Tally table
(
SELECT TOP(ABS(CONVERT(BIGINT,(DATALENGTH(ISNULL(@string,''))-(ISNULL(@N,1)-1)),0)))
ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) -- Order by a constant to avoid a sort
FROM L1 a CROSS JOIN L1 b -- cartesian product for 8100 rows (90^2)
)
SELECT
position = N, -- position of the token in the string(s)
token = SUBSTRING(@string,N,@N) -- the @N-Sized token
FROM iTally
WHERE @N > 0 AND @N <= DATALENGTH(@string); -- force the function to ignore a "bad @N"
GO
/****************************************************************************************
(2) How to get ALL the substrings that exist insided @string (and their length)
****************************************************************************************/;
DECLARE @string varchar(8000) = 'abcdefg';
WITH iTally AS
(
SELECT TOP(LEN(@string)) N=ROW_NUMBER() OVER (ORDER BY (SELECT NULL))
FROM sys.all_columns
)
SELECT StrLen = N, ng.*
FROM iTally i
CROSS APPLY dbo.NGrams8K(@string,N) ng;
/****************************************************************************************
(3) My Solution:
****************************************************************************************/;
IF OBJECT_ID('dbo.LCSS1') IS NOT NULL DROP FUNCTION dbo.LCSS1;
GO
CREATE FUNCTION dbo.LCSS1
(
@string1 varchar(8000),
@string2 varchar(8000)
)
RETURNS TABLE WITH SCHEMABINDING AS RETURN
WITH
Strings AS
(
SELECT
String1 = CASE WHEN LEN(@string1)>LEN(@string2) THEN @string1 ELSE @string2 END,
String2 = CASE WHEN LEN(@string1)>LEN(@string2) THEN @string2 ELSE @string1 END
),
i(N) AS (SELECT position FROM Strings CROSS APPLY dbo.NGrams8K(String2,1))
SELECT TOP (1) WITH TIES
TokenLength = N,
Token
FROM i CROSS APPLY Strings s CROSS APPLY dbo.NGrams8K(String2,N)
WHERE CHARINDEX(token,String1) > 0
ORDER BY N DESC;
GO
Here's Phil's version (which I modified to get a more "apples to apples" comparison. Note that I changed the input string datatype from varchar(max) to varchar(8000) because my
version is varchar(8000). Second I added WITH TIES to his function in case there are ties
(mine handled ties, his did not).
CREATE FUNCTION dbo.LongestCommonSubstring
/**
summary: >
The longest common subSubstring (LCS) tells you the longest common substring between two strings.
If you, for example, were to compare ‘And the Dish ran away with the Spoon’ with ‘away’, you’d
get ‘away’ as being the string in common. Likewise, comparing ‘465932859472109683472’ with
‘697834859472135348’ would give you ‘8594721’. This returns a one-row table that gives you the
length and location of the string as well as the string itself. It can easily be modified to give
you all the substrings (whatever your criteria for the smallest substring. E.g. two characters?
Author: Phil Factor
Revision: 1.0
date: 05 Dec 2014
example:
code: |
Select * from dbo.LongestCommonSubstring ('1234', '1224533324')
Select * from dbo.LongestCommonSubstring ('thisisatest', 'testing123testing')
Select * from dbo.LongestCommonSubstring ( 'findthishere', 'where is this?')
Select * from dbo.LongestCommonSubstring ( null, 'xab')
Select * from dbo.LongestCommonSubstring ( 'not beginning-middle-ending',
'beginning-diddle-dum-ending')
returns: >
the longest common subString as a string
**/
(
@firstString VARCHAR(8000), -- Changed By Alan Burstein (originally varchar(max))
@SecondString VARCHAR(8000) -- Changed By Alan Burstein (originally varchar(max))
)
RETURNS @hit TABLE --returns a single row table
--(it is easy to change to return a string but I wanted the location of the match)
(
MatchLength INT,--the length of the match. Not necessarily the length of input
FirstCharInMatch INT,--first character of match in first string
FirstCharInString INT,--first character of match in second string
CommonString VARCHAR(8000) --the part of the FirstString successfully matched
)
AS BEGIN
DECLARE @Order INT, @TheGroup INT, @Sequential INT
--this table is used to do a quirky update to enable a grouping only on sequential characters
DECLARE @Scratch TABLE (TheRightOrder INT IDENTITY PRIMARY KEY,TheGroup smallint, Sequential INT,
FirstOrder smallint, SecondOrder smallint, ch CHAR(1))
--first we reduce the amount of data to those characters in the first string that have a match
--in the second, and where they were.
INSERT INTO @Scratch ( TheGroup , firstorder, secondorder, ch)
SELECT Thefirst.number-TheSecond.number AS TheGroup,Thefirst.number, TheSecond.number, TheSecond.ch
FROM --divide up the first string into a table of characters/sequence
(SELECT number, SUBSTRING(@FirstString,number,1) AS ch
FROM numbers WHERE number <= LEN(@FirstString)) TheFirst
INNER JOIN --divide up the second string into a table of characters/sequence
(SELECT number, SUBSTRING(@SecondString,number,1) AS ch
FROM numbers WHERE number <= LEN(@SecondString)) TheSecond
ON Thefirst.ch= Thesecond.ch --do all valid matches
ORDER BY Thefirst.number-TheSecond.number, TheSecond.number
--now @scratch has all matches in the correct order for checking unbroken sequence
SELECT @Order=-1, @TheGroup=-1, @Sequential=0 --initialise everything
UPDATE @Scratch --now check by incrementing a value every time a sequence is broken
SET @Sequential=Sequential =
CASE --if it is not a sequence from the one before increment the variable
WHEN secondorder=@order+1 AND TheGroup=@TheGroup
THEN @Sequential ELSE @Sequential+1 END,
@Order=secondorder,
@TheGroup=TheGroup
--now we just aggregate it, and choose the first longest match. Easy
INSERT INTO @hit (MatchLength,FirstCharInMatch, FirstCharInString,CommonString)
SELECT TOP (1) WITH TIES --just the first. You may want more so feel free to change -- ALAN BURSTIEN: Added WITH TIES
COUNT(*) AS MatchLength,
MIN(firstorder) FirstCharInMatch,
MIN(secondorder) AS FirstCharInString,
SUBSTRING(@SecondString,
MIN(secondorder),
COUNT(*)) AS CommonString
FROM @scratch GROUP BY TheGroup,Sequential
ORDER BY COUNT(*) DESC, MIN(firstOrder) ASC, MIN(SecondOrder) ASC
RETURN
END--and we do a test run
GO
One final note before the tests, I use Make_Parallel in my test because it speeds my version up.
Lastly (sorry BTW for the shortness here Eirikur - it's midnight and I've been up since 3:30AM)...
My function is LCSS1, his is called LongestCommonSubstring. I run mine with a serial plan and then with a parallel plan. I run his only with a serial plan (because parallel obviously does not improve perf for his mTVF)....
I did 2 tests tonight: the first with 1000 rows and average string length of 100.
Mine does much better there.... Here's the results:
Starting Test...
rows: 1000; Avg Len: 101
Beginning execution loop
=== LCSS1 serial ===
3123
=== LCSS1 serial ===
3076
=== LCSS1 serial ===
3086
Batch execution completed 3 times.
Beginning execution loop
=== LongestCommonSubstring serial ===
8043
=== LongestCommonSubstring serial ===
7910
=== LongestCommonSubstring serial ===
7886
Batch execution completed 3 times.
Beginning execution loop
=== LCSS1 parallel ===
890
=== LCSS1 parallel ===
783
=== LCSS1 parallel ===
806
Batch execution completed 3 times.
The second test is 10 rows with an average string length of 777 chars... His mTVF does much better:
Starting Test...
rows: 10; Avg Len: 777
Beginning execution loop
=== LCSS1 serial ===
12983
=== LCSS1 serial ===
13003
=== LCSS1 serial ===
13046
Batch execution completed 3 times.
Beginning execution loop
=== LongestCommonSubstring serial ===
5630
=== LongestCommonSubstring serial ===
6193
=== LongestCommonSubstring serial ===
5880
Batch execution completed 3 times.
Beginning execution loop
=== LCSS1 parallel ===
8466
=== LCSS1 parallel ===
8303
=== LCSS1 parallel ===
8443
Batch execution completed 3 times.
Here's the test code, note my comments. (I have other tests that I can't find at the moment but this test works for what I'm trying to show you)....
SET NOCOUNT ON;
IF OBJECT_ID('tempdb..#strings') IS NOT NULL DROP TABLE #strings
GO
DECLARE @string varchar(max) =
'
Aaron Copland Collection
When Aaron Copland boarded a ship for Paris in June 1921, a few months short of his twenty-first birthday, he already had a good musical training thanks to his conservative but thorough American teacher, Rubin Goldmark. He carried in his luggage the manuscript of what was to be his first published piece, the "scherzo humoristique" The Cat and the Mouse, which played with the progressive techniques of whole-tone scale and black-note versus white-note alternation. Nevertheless, it was in France, under the encouragement of his teacher Nadia Boulanger, that Copland produced his first large-scale works: the ballet Grohg (now known principally through the excerpt Dance Symphony, and the Symphony for Organ and Orchestra, with which he introduced himself to American audiences.
Grohg and the Symphony for Organ and Orchestrawere written in a style suggested by European modernism (Copland confessed that Grohg was written under the spell of Florent Schmitt''s La Tragédie de Salomé). In the works that followed Copland sought to discover a particularly American style, an interest that continued for the remainder of his career as a composer. Yet Copland did not seek to establish a single "American" style, nor did he ask that an American work contain particular references to American idioms: it was of Roger Sessions''s 1927-30Sonata for Piano, a very un-Coplandish work with no audible Americanisms, that he said "To know [this] work well is to have the firm conviction that Sessions has presented us with a cornerstone upon which to base an American music."
At first Copland sought for Americanism in the influence of jazz—"jazz" as he had played it (see letter from Copland to Nadia Boulanger, August 1924) as part of a hotel orchestra in the summer of 1924. The Concerto for Piano and Orchestra, the Music for the Theatre, and the Two Pieces for Violin and Piano contrast jazzy portions with slow introspective sections that use bluesy lines over atmospheric ostinati—the latter sometimes suggesting Charles Ives''s song "The Housatonic at Stockbridge," a work Copland could not have known during the 1920s.
No later Copland works rely on jazz textures as these works do, though many are infused with rhythms suggesting jazz. (Copland''s one mature work with a seeming jazz reference in its title, the 1949 Four Piano Blues, uses "blues" to suggest an informal music of American sound, his equivalent of intermezzior impromptus.)
Copland also continued to write works for the concert hall, often using the somewhat simplified musical language he had developed for his ballet and film scores and for a series of works for young performers, including the school opera The Second Hurricane, of 1937 and An Outdoor Overture from 1938, the latter an orchestral piece accessible to very accomplished student players. Among these pieces for the concert hall Fanfare for the Common Man and Lincoln Portrait (both 1942) reflect the patriotic spirit of the World War II era. Others were straight concert music: notably Quiet City (1939), based on incidental music for a play about New York; the landmark Piano Sonata (1941), inspired by the piano playing of the young Leonard Bernstein and written in response to a request by Clifford Odets; and the Sonata for Violin and Piano (1943), which speaks the most radically simplified language of any Copland concert work.
The climactic composition of this period is the Third Symphony (1946). It is Copland''s most extensive symphonic work, drawing on the language ofAppalachian Spring and of the Fanfare for the Common Man (and on the notes of the latter) to celebrate the American spirit at the end of World War II. It is also Copland''s most public utterance, moving in the world of the major Prokofiev, Stravinsky, and Shostakovich symphonies of the 1940s.
In the late 1940s Copland wrote two of his most popular and frequently performed works, the long 1947a cappella chorus In the Beginning (which he wrote sequestered in a Boston hotel room against the deadline of a performance at Harvard''s Symposium on Music Criticism) and the 1948 Concerto for Clarinet and String Orchestra, written for Benny Goodman. At the same time he was also meditating what would be another of his key works.
As a teenager Copland had admired the songs of Hugo Wolf, and his early production had included several individual songs; "Poet''s Song" (1927) was the one completed song of a planned cycle on poems of e.e. cummings. In 1950 Copland completed his only song cycle, the Twelve Poems of Emily Dickinson for voice and piano. Avoiding the most famous of Dickinson''s poems save for the final setting of "The Chariot" ("Because I would not stop for Death"), this cycle "center
around no single theme, but . . . treatof subject matter particularly close to Miss Dickinson—nature, death, life, eternity, " as he explained in the note published at the start of the cycle. One of the century''s great song cycles, it is regarded by some Copland scholars as his finest work.Copland''s music of the late 1920s drives towards two of his key works, both uncompromising in their modernism: the Symphonic Ode of 1929 and the Piano Variations of 1930. The fate of these compositions contrasts sharply. While the Piano Variations is not often performed in concert, it is well known to pianists because although it does contain virtuoso passages, even those of very modest ability can "play at" the work in private. It represents the twentieth-century continuation of the great tradition of keyboard variations—the tradition that produced such works as the Bach Goldberg Variations, the BeethovenDiabelli Variations, and the Brahms Handel Variations. The Symphonic Ode, on the other hand, remains almost unknown: an intense symphonic movement of the length and heft of a Mahler first movement, it was considered unperformable by the conductor Serge Koussevitzky, otherwise the most potent American champion of Copland''s work during the first half of the century. Koussevitzky did perform a revised version in 1932; but even with a second, more extensive revision in 1955, the Ode is seldom played. It is Copland''s single longest orchestral movement.
Perhaps as a reaction to the performance problems of the Symphonic Ode, Copland''s next two orchestral works deal in shorter units of time: the Short Symphony of 1933 requires fifteen minutes for three movements and the six Statements for orchestra of 1935 last only nineteen minutes. Yet in fact these works were somewhat more complex than the Ode; in particular, the wiry, agile rhythms of the opening movement of the Short Symphony proved too much for both the conductors Serge Koussevitzky and Leopold Stokowski. In the end it was Carlos Chávez and the Orquesta Sinfónica de México who gave the Short Symphony its premiere. In 1937 Copland arranged theShort Symphony as the Sextet for piano, clarinet, and string quartet (the ensemble is an homage to Roy Harris''s 1926 Concerto for the same combination of instruments); and it is in its sextet form that the Short Symphony is most often heard.
It may have been partly Copland''s friendship with Carlos Chávez that drew him to Mexico. Copland first visited Mexico in 1932 and returned frequently in later years. His initial delight in the country is related in his letter of January 13, 1933, to Mary Lescaze; photographs of his visits to Mexico may be found in this online collection. His interest in Mexico is also reflected in his music, including El Salón México (1936) and the Three Latin American Sketches (1972).
Mexico was not Copland''s only Latin American interest. A 1941 trip to Havana suggested his Danzón Cubano. By the early 1940s he was friends with South American composers such as Jacobo Ficher, and in 1947 he toured South America for the State Department. (Some of the folk music he heard in Rio de Janeiro on this trip appears in the second movement of hisClarinet Concerto of 1948.) Copland in fact envisioned "American music" as being music of the Americas. His own use of Mexican material in the mid-1930s helped make his style more accessible to listeners not committed to modernism: El Salón Méxicois the earliest of his works to appear regularly in anthologies Copland''s best-known music.
In the mid-1930s Copland began to receive commissions from dance companies. The first, from the Chicago choreographer Ruth Page, resulted in the 1935 score Hear Ye! Hear Ye!, a ballet with a Rashomon-like plot set in a court of law. Hear Ye! Hear Ye! was a local success but did not make the transition to repertory; when asked about it in later years Copland would say "I wrote that piece very fast." His second commission, from Lincoln Kirstein''s Ballet Caravan in New York, resulted in Billy the Kid (1938), one of his best-known works and the work which first definitely identified him with the American West. (Music for Radio, written in 1937, was given the title Saga of the Prairie as the result of a contest, so some people heard the West in Copland''s music even before the first of his works to have a specifically Western subject.) Kirstein wanted the score of Billy the Kid to contain quotations of cowboy songs and sent Copland off to Paris with several cowboy songbooks; thus the score''s heavily folk-music texture is partly a result of the commission.
Copland again made extensive use of folk material in his next ballet score, Rodeo, written in 1942 for the choreographer Agnes DeMille. (In it he included one fiddle tune from a Library of Congress field recording, which he knew through its transcription in John and Alan Lomax''s Our Singing Country.)
Two years later Martha Graham''s introspective scenario about life in Pennsylvania when it was the frontier elicited Copland''s score Appalachian Spring, first performed in the Coolidge Auditorium in the Library of Congress. Appalachian Spring won Copland the Pulitzer Prize for music; it is widely thought of as the quintessential Copland work. After Appalachian Springhe turned away from dance until 1959, when he wrote the abstract dance score Dance Panels.
Copland wrote for film as well as for the stage in the late 1930s and 1940s. His first film score, The City(1939), was for a documentary by Ralph Steiner that was shown at the New York World''s Fair. In 1945 he did another documentary score, The Cummington Story, for the U.S. government. Otherwise his film scores of the period were for Hollywood films: Of Mice and Men (1939), based on John Steinbeck''s novel;Our Town (1940), based on the Thornton Wilder play;The North Star (1943), for a film to a script by Lillian Hellman concerning a Russian town''s resistance to the Nazi invasion (and Copland''s only dramatic score afterGrohg that did not have an American setting); The Red Pony (1948), after John Steinbeck''s story; andThe Heiress (1948), after Henry James''s novelWashington Square. Copland''s score to The Heiresswon an Academy Award for best film score. In 1942 he assembled sections of the scores for The City, Of Mice and Men, and Our Town into a suite entitled Music for the Movies.
After The Heiress Copland wrote only once more for film, for the 1961 independent production Something Wild. In this final film score, as earlier in The City, Copland came to grips with his own city of New York: he considered calling the suite drawn from the film The Poet in Manhattan. Written for the London Symphony Orchestra, the suite was finally titled Music for a Great City, the particular city unspecified.
n 1950 it seemed that another of Copland''s ambitions was about to be fulfilled: Sir Rudolf Bing approached him with the suggestion that he and Thornton Wilder write an operatic version of Our Town for the Metropolitan Opera. But Wilder declined ("I''m convinced that I write a-musical plays . . . that in them even the life of the emotions is expressed contra musicam"). In 1952-54, responding to a commission for an "opera for television," Copland wrote his one full-length opera, The Tender Land. In its final form The Tender Land is an opera for the stage rather than for television, "conceived with an eye to modest production and intimate scale." With its story of growing up in a Midwestern countryside, the opera continues to lead a healthy life in productions in university opera departments and on midsize opera stages; the finale from Act One, "The Promise of Living," is also widely performed as an anthem-like evocation of the American vision.
The 1950s also saw a renewal of Copland''s interest in works more challenging to the listener. Many of these were chamber music: the Quartet for Piano and Strings of 1950, commissioned by the Coolidge Foundation in the Library of Congress; the Piano Fantasy of 1957; and the autumnal Nonet for strings of 1960, perhaps his most personal piece, dedicated "To Nadia Boulanger after forty years of friendship." In the Quartet and the Piano Fantasy (but not in the Nonet) Copland used a modified version of the serial technique then increasingly favored by American composers, and in the 1960s he produced two orchestral works, Connotations (1962) and Inscape(1967), which employed classical serial technique. (The score to the 1961 work Something Wild, which has much of the sizzle of Connotations and Inscape, is resolutely non-serial.) In 1968 Copland made sketches for a String Quartet using serial technique; it remained unfinished. It was his final attempt at adapting serialism to his own music.
In parallel with these challenging works, Copland produced a series of pieces in a style similar to the simplified musical language he had developed in the 1940s, including the Canticle of Freedom (1955) and Emblems (1964) for band. He also produced two sets of song arrangements entitled Old American Songs(1950), (second set) (1952). They explore the varieties of American song in the nineteenth century, including minstrel songs, hymns, and songs for children. One arrangement, of the Shaker song "Simple Gifts" (which Copland had first used in Appalachian Spring), has become an American anthem.
When people talk about the American aspects of Copland''s music, they often emphasize the Western flavor of some of his works. This is perhaps understandable, for the three major ballets (Appalachian Spring, Rodeo, and Billy the Kid), his three most often performed works in the concert hall as well as on stage, all deal with some aspect of the West or of the U.S. frontier: Appalachian Spring with Pennsylvania when it was the frontier, Rodeo with an established Western society, Billy the Kid with the West and frontier as well. And Copland''s "Western" language was appropriated by a generation of film composers such as Elmer Bernstein, whose Copland-derived score for The Magnificent Seven, subsequently used also for a series of Marlboro ads, further cemented the association between the Copland sound and the American West.
Yet Copland''s identification with American subjects goes much further. One of his central works is a setting of twelve Emily Dickinson poems, and he also set texts by Edwin Arlington Robinson, Ezra Pound, and e. e. cummings. He scored films based on Henry James''s late nineteenth century New York and on Thornton Wilder''s New Hampshire town seen against the backdrop of eternity; two of his film scores took on contemporary New York. (The City, despite its title, also invokes rural New England.) Nor was Copland''s "America" limited to the United States: with such works as El Salón México and Danzón Cubano it embraced the northern half of the hemisphere.
In a letter to Serge Koussevitzky in 1931, Copland commented that Leopold Stokowski was not an ideal conductor for Stravinsky''s Oedipus Rex because "there is one quality you must have in order to give a good performance of Oedipus and that is le sens tragique de la vie [the tragic sense of life]. This Stokowski simply has not got—instead he has le sens mystique de la vie[the mystical sense of life] which is something quite different." In his own music—and, one feels in his letters, in his life as well—what Copland had was le sens lyrique de la vie—the lyrical sense of life. Whatever his music may do, it always sings: of his century, of his land, of his life and of ours.
During the 1970s Copland put his musical house in order, producing works based on earlier sketches, of which the most extensive is the Duo for Flute and Piano of 1971. A second career, that of conductor, opened up for him as he conducted not only his own compositions but those of other Americans and works from the standard repertory. He also recorded much of his own music, the orchestral works with the London Symphony orchestra
At the same time, Copland made preparations for writing his autobiography, such as requesting that his friends send him copies of the letters they had received from him. Written with Vivian Perlis and including transcriptions of Perlis''s oral-history interviews with Copland''s friends and associates, the autobiography appeared in two volumes, the first in 1984 and the second in 1989.
Aaron Copland died on December 2, 1990, a few days after his ninetieth birthday.
';
CREATE TABLE #strings
(
strID int primary key,
string1 varchar(8000) NOT NULL,
string2 varchar(8000) NOT NULL
);
-- CHANGE THE TOP VALUE for more rows and the checksum values for longer/shorter avg strings...
INSERT #strings
SELECT TOP (1000) --10
ROW_NUMBER() OVER (ORDER BY (SELECT NULL)),
SUBSTRING
(
@string,
1+ABS(CHECKSUM(newid())%1000), -- 10000
1+ABS(CHECKSUM(newid())%200) -- 2000
),
SUBSTRING
(
@string,
1+ABS(CHECKSUM(newid())%1000), -- 10000
1+ABS(CHECKSUM(newid())%200) -- 2000
)
FROM sys.all_columns
GO
DECLARE @rows varchar(10), @avglen varchar(10);
SELECT
@rows = COUNT(*),
@avglen = AVG(LEN(string1+string2)/2)
FROM #strings;
PRINT 'Starting Test...';
PRINT CONCAT('rows: ',@rows,'; Avg Len: ',@avglen);
GO
DECLARE @st datetime = getdate(), @x varchar(8000);
PRINT '=== LCSS1 serial ===';
SELECT @x = token
FROM #strings
CROSS APPLY dbo.LCSS1(string1, string2)
OPTION (MAXDOP 1);
PRINT DATEDIFF(MS,@st,getdate());
GO 3
PRINT '=== LongestCommonSubstring serial ===';
DECLARE @st datetime = getdate(), @x varchar(8000);
SELECT @x = CommonString
FROM #strings
CROSS APPLY dbo.LongestCommonSubstring(string1,string2)
PRINT DATEDIFF(MS,@st,getdate());
GO 3
DECLARE @st datetime = getdate(), @x varchar(8000);
PRINT '=== LCSS1 parallel ===';
SELECT @x = token
FROM #strings
CROSS APPLY dbo.LCSS1(string1, string2)
CROSS APPLY dbo.make_parallel()
PRINT DATEDIFF(MS,@st,getdate());
GO 3
"I cant stress enough the importance of switching from a sequential files mindset to set-based thinking. After you make the switch, you can spend your time tuning and optimizing your queries instead of maintaining lengthy, poor-performing code."-- Itzik Ben-Gan 2001
-
Hi Alan, nice job 🙂
Here's a completely different take on the problem, loosely based on some fuzzy matching stuff I've worked on over the years. It looks promising and you won't have to do much to tweak it whichever way:
DECLARE @string1 varchar(8000) = LEFT('
Aaron Copland Collection
When Aaron Copland boarded a ship for Paris in June 1921, a few months short of his twenty-first birthday, he already had a good musical training thanks to his conservative but thorough American teacher, Rubin Goldmark. He carried in his luggage the manuscript of what was to be his first published piece, the "scherzo humoristique" The Cat and the Mouse, which played with the progressive techniques of whole-tone scale and black-note versus white-note alternation. Nevertheless, it was in France, under the encouragement of his teacher Nadia Boulanger, that Copland produced his first large-scale works: the ballet Grohg (now known principally through the excerpt Dance Symphony, and the Symphony for Organ and Orchestra, with which he introduced himself to American audiences.
Grohg and the Symphony for Organ and Orchestrawere written in a style suggested by European modernism (Copland confessed that Grohg was written under the spell of Florent Schmitt''s La Tragédie de Salomé). In the works that followed Copland sought to discover a particularly American style, an interest that continued for the remainder of his career as a composer. Yet Copland did not seek to establish a single "American" style, nor did he ask that an American work contain particular references to American idioms: it was of Roger Sessions''s 1927-30Sonata for Piano, a very un-Coplandish work with no audible Americanisms, that he said "To know [this] work well is to have the firm conviction that Sessions has presented us with a cornerstone upon which to base an American music."
At first Copland sought for Americanism in the influence of jazz—"jazz" as he had played it (see letter from Copland to Nadia Boulanger, August 1924) as part of a hotel orchestra in the summer of 1924. The Concerto for Piano and Orchestra, the Music for the Theatre, and the Two Pieces for Violin and Piano contrast jazzy portions with slow introspective sections that use bluesy lines over atmospheric ostinati—the latter sometimes suggesting Charles Ives''s song "The Housatonic at Stockbridge," a work Copland could not have known during the 1920s.
No later Copland works rely on jazz textures as these works do, though many are infused with rhythms suggesting jazz. (Copland''s one mature work with a seeming jazz reference in its title, the 1949 Four Piano Blues, uses "blues" to suggest an informal music of American sound, his equivalent of intermezzior impromptus.)
Copland also continued to write works for the concert hall, often using the somewhat simplified musical language he had developed for his ballet and film scores and for a series of works for young performers, including the school opera The Second Hurricane, of 1937 and An Outdoor Overture from 1938, the latter an orchestral piece accessible to very accomplished student players. Among these pieces for the concert hall Fanfare for the Common Man and Lincoln Portrait (both 1942) reflect the patriotic spirit of the World War II era. Others were straight concert music: notably Quiet City (1939), based on incidental music for a play about New York; the landmark Piano Sonata (1941), inspired by the piano playing of the young Leonard Bernstein and written in response to a request by Clifford Odets; and the Sonata for Violin and Piano (1943), which speaks the most radically simplified language of any Copland concert work.
The climactic composition of this period is the Third Symphony (1946). It is Copland''s most extensive symphonic work, drawing on the language ofAppalachian Spring and of the Fanfare for the Common Man (and on the notes of the latter) to celebrate the American spirit at the end of World War II. It is also Copland''s most public utterance, moving in the world of the major Prokofiev, Stravinsky, and Shostakovich symphonies of the 1940s.
In the late 1940s Copland wrote two of his most popular and frequently performed works, the long 1947a cappella chorus In the Beginning (which he wrote sequestered in a Boston hotel room against the deadline of a performance at Harvard''s Symposium on Music Criticism) and the 1948 Concerto for Clarinet and String Orchestra, written for Benny Goodman. At the same time he was also meditating what would be another of his key works.
As a teenager Copland had admired the songs of Hugo Wolf, and his early production had included several individual songs; "Poet''s Song" (1927) was the one completed song of a planned cycle on poems of e.e. cummings. In 1950 Copland completed his only song cycle, the Twelve Poems of Emily Dickinson for voice and piano. Avoiding the most famous of Dickinson''s poems save for the final setting of "The Chariot" ("Because I would not stop for Death"), this cycle "center
around no single theme, but . . . treatof subject matter particularly close to Miss Dickinson—nature, death, life, eternity, " as he explained in the note published at the start of the cycle. One of the century''s great song cycles, it is regarded by some Copland scholars as his finest work.Copland''s music of the late 1920s drives towards two of his key works, both uncompromising in their modernism: the Symphonic Ode of 1929 and the Piano Variations of 1930. The fate of these compositions contrasts sharply. While the Piano Variations is not often performed in concert, it is well known to pianists because although it does contain virtuoso passages, even those of very modest ability can "play at" the work in private. It represents the twentieth-century continuation of the great tradition of keyboard variations—the tradition that produced such works as the Bach Goldberg Variations, the BeethovenDiabelli Variations, and the Brahms Handel Variations. The Symphonic Ode, on the other hand, remains almost unknown: an intense symphonic movement of the length and heft of a Mahler first movement, it was considered unperformable by the conductor Serge Koussevitzky, otherwise the most potent American champion of Copland''s work during the first half of the century. Koussevitzky did perform a revised version in 1932; but even with a second, more extensive revision in 1955, the Ode is seldom played. It is Copland''s single longest orchestral movement.
Perhaps as a reaction to the performance problems of the Symphonic Ode, Copland''s next two orchestral works deal in shorter units of time: the Short Symphony of 1933 requires fifteen minutes for three movements and the six Statements for orchestra of 1935 last only nineteen minutes. Yet in fact these works were somewhat more complex than the Ode; in particular, the wiry, agile rhythms of the opening movement of the Short Symphony proved too much for both the conductors Serge Koussevitzky and Leopold Stokowski. In the end it was Carlos Chávez and the Orquesta Sinfónica de México who gave the Short Symphony its premiere. In 1937 Copland arranged theShort Symphony as the Sextet for piano, clarinet, and string quartet (the ensemble is an homage to Roy Harris''s 1926 Concerto for the same combination of instruments); and it is in its sextet form that the Short Symphony is most often heard.
It may have been partly Copland''s friendship with Carlos Chávez that drew him to Mexico. Copland first visited Mexico in 1932 and returned frequently in later years. His initial delight in the country is related in his letter of January 13, 1933, to Mary Lescaze; photographs of his visits to Mexico may be found in this online collection. His interest in Mexico is also reflected in his music, including El Salón México (1936) and the Three Latin American Sketches (1972).
Mexico was not Copland''s only Latin American interest. A 1941 trip to Havana suggested his Danzón Cubano. By the early 1940s he was friends with South American composers such as Jacobo Ficher, and in 1947 he toured South America for the State Department. (Some of the folk music he heard in Rio de Janeiro on this trip appears in the second movement of hisClarinet Concerto of 1948.) Copland in fact envisioned "American music" as being music of the Americas. His own use of Mexican material in the mid-1930s helped make his style more accessible to listeners not committed to modernism: El Salón Méxicois the earliest of his works to appear regularly in anthologies Copland''s best-known music.
In the mid-1930s Copland began to receive commissions from dance companies. The first, from the Chicago choreographer Ruth Page, resulted in the 1935 score Hear Ye! Hear Ye!, a ballet with a Rashomon-like plot set in a court of law. Hear Ye! Hear Ye! was a local success but did not make the transition to repertory; when asked about it in later years Copland would say "I wrote that piece very fast." His second commission, from Lincoln Kirstein''s Ballet Caravan in New York, resulted in Billy the Kid (1938), one of his best-known works and the work which first definitely identified him with the American West. (Music for Radio, written in 1937, was given the title Saga of the Prairie as the result of a contest, so some people heard the West in Copland''s music even before the first of his works to have a specifically Western subject.) Kirstein wanted the score of Billy the Kid to contain quotations of cowboy songs and sent Copland off to Paris with several cowboy songbooks; thus the score''s heavily folk-music texture is partly a result of the commission.
Copland again made extensive use of folk material in his next ballet score, Rodeo, written in 1942 for the choreographer Agnes DeMille. (In it he included one fiddle tune from a Library of Congress field recording, which he knew through its transcription in John and Alan Lomax''s Our Singing Country.)
Two years later Martha Graham''s introspective scenario about life in Pennsylvania when it was the frontier elicited Copland''s score Appalachian Spring, first performed in the Coolidge Auditorium in the Library of Congress. Appalachian Spring won Copland the Pulitzer Prize for music; it is widely thought of as the quintessential Copland work. After Appalachian Springhe turned away from dance until 1959, when he wrote the abstract dance score Dance Panels.
Copland wrote for film as well as for the stage in the late 1930s and 1940s. His first film score, The City(1939), was for a documentary by Ralph Steiner that was shown at the New York World''s Fair. In 1945 he did another documentary score, The Cummington Story, for the U.S. government. Otherwise his film scores of the period were for Hollywood films: Of Mice and Men (1939), based on John Steinbeck''s novel;Our Town (1940), based on the Thornton Wilder play;The North Star (1943), for a film to a script by Lillian Hellman concerning a Russian town''s resistance to the Nazi invasion (and Copland''s only dramatic score afterGrohg that did not have an American setting); The Red Pony (1948), after John Steinbeck''s story; andThe Heiress (1948), after Henry James''s novelWashington Square. Copland''s score to The Heiresswon an Academy Award for best film score. In 1942 he assembled sections of the scores for The City, Of Mice and Men, and Our Town into a suite entitled Music for the Movies.
After The Heiress Copland wrote only once more for film, for the 1961 independent production Something Wild. In this final film score, as earlier in The City, Copland came to grips with his own city of New York: he considered calling the suite drawn from the film The Poet in Manhattan. Written for the London Symphony Orchestra, the suite was finally titled Music for a Great City, the particular city unspecified.
n 1950 it seemed that another of Copland''s ambitions was about to be fulfilled: Sir Rudolf Bing approached him with the suggestion that he and Thornton Wilder write an operatic version of Our Town for the Metropolitan Opera. But Wilder declined ("I''m convinced that I write a-musical plays . . . that in them even the life of the emotions is expressed contra musicam"). In 1952-54, responding to a commission for an "opera for television," Copland wrote his one full-length opera, The Tender Land. In its final form The Tender Land is an opera for the stage rather than for television, "conceived with an eye to modest production and intimate scale." With its story of growing up in a Midwestern countryside, the opera continues to lead a healthy life in productions in university opera departments and on midsize opera stages; the finale from Act One, "The Promise of Living," is also widely performed as an anthem-like evocation of the American vision.
The 1950s also saw a renewal of Copland''s interest in works more challenging to the listener. Many of these were chamber music: the Quartet for Piano and Strings of 1950, commissioned by the Coolidge Foundation in the Library of Congress; the Piano Fantasy of 1957; and the autumnal Nonet for strings of 1960, perhaps his most personal piece, dedicated "To Nadia Boulanger after forty years of friendship." In the Quartet and the Piano Fantasy (but not in the Nonet) Copland used a modified version of the serial technique then increasingly favored by American composers, and in the 1960s he produced two orchestral works, Connotations (1962) and Inscape(1967), which employed classical serial technique. (The score to the 1961 work Something Wild, which has much of the sizzle of Connotations and Inscape, is resolutely non-serial.) In 1968 Copland made sketches for a String Quartet using serial technique; it remained unfinished. It was his final attempt at adapting serialism to his own music.
In parallel with these challenging works, Copland produced a series of pieces in a style similar to the simplified musical language he had developed in the 1940s, including the Canticle of Freedom (1955) and Emblems (1964) for band. He also produced two sets of song arrangements entitled Old American Songs(1950), (second set) (1952). They explore the varieties of American song in the nineteenth century, including minstrel songs, hymns, and songs for children. One arrangement, of the Shaker song "Simple Gifts" (which Copland had first used in Appalachian Spring), has become an American anthem.
When people talk about the American aspects of Copland''s music, they often emphasize the Western flavor of some of his works. This is perhaps understandable, for the three major ballets (Appalachian Spring, Rodeo, and Billy the Kid), his three most often performed works in the concert hall as well as on stage, all deal with some aspect of the West or of the U.S. frontier: Appalachian Spring with Pennsylvania when it was the frontier, Rodeo with an established Western society, Billy the Kid with the West and frontier as well. And Copland''s "Western" language was appropriated by a generation of film composers such as Elmer Bernstein, whose Copland-derived score for The Magnificent Seven, subsequently used also for a series of Marlboro ads, further cemented the association between the Copland sound and the American West.
Yet Copland''s identification with American subjects goes much further. One of his central works is a setting of twelve Emily Dickinson poems, and he also set texts by Edwin Arlington Robinson, Ezra Pound, and e. e. cummings. He scored films based on Henry James''s late nineteenth century New York and on Thornton Wilder''s New Hampshire town seen against the backdrop of eternity; two of his film scores took on contemporary New York. (The City, despite its title, also invokes rural New England.) Nor was Copland''s "America" limited to the United States: with such works as El Salón México and Danzón Cubano it embraced the northern half of the hemisphere.
In a letter to Serge Koussevitzky in 1931, Copland commented that Leopold Stokowski was not an ideal conductor for Stravinsky''s Oedipus Rex because "there is one quality you must have in order to give a good performance of Oedipus and that is le sens tragique de la vie [the tragic sense of life]. This Stokowski simply has not got—instead he has le sens mystique de la vie[the mystical sense of life] which is something quite different." In his own music—and, one feels in his letters, in his life as well—what Copland had was le sens lyrique de la vie—the lyrical sense of life. Whatever his music may do, it always sings: of his century, of his land, of his life and of ours.
During the 1970s Copland put his musical house in order, producing works based on earlier sketches, of which the most extensive is the Duo for Flute and Piano of 1971. A second career, that of conductor, opened up for him as he conducted not only his own compositions but those of other Americans and works from the standard repertory. He also recorded much of his own music, the orchestral works with the London Symphony orchestra
At the same time, Copland made preparations for writing his autobiography, such as requesting that his friends send him copies of the letters they had received from him. Written with Vivian Perlis and including transcriptions of Perlis''s oral-history interviews with Copland''s friends and associates, the autobiography appeared in two volumes, the first in 1984 and the second in 1989.
Aaron Copland died on December 2, 1990, a few days after his ninetieth birthday.',8000);
DECLARE @String2 VARCHAR(8000) = 'In the late 1940s Copland wrote two of his most popular and frequently performed works, the long 1947a cappella chorus In the Beginning (which he wrote sequestered in a Boston hotel room against the deadline of a performance at Harvard''s Symposium on Music Criticism) and the 1948 Concerto for Clarinet and String Orchestra, written for Benny Goodman. At the same time he was also meditating what would be another of his key works.
';
SELECT LEN(@String1), LEN(@String2);
DECLARE @Now DATETIME = GETDATE();
WITH E1 AS (SELECT n = 0 FROM (VALUES (0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) d (n)),
E2 AS (SELECT n = 0 FROM E1, E1 b),
E4 AS (SELECT n = 0 FROM E1, E1 b),
iTally AS (SELECT n = ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM E4, E4 b, E4 c),
LongStrings AS (
SELECT n, grp = n-ROW_NUMBER() OVER(ORDER BY n)
FROM iTally
WHERE n <= LEN(@String1)
AND @String2 LIKE '%' + SUBSTRING(@String1,n,2) + '%'),
Processing AS (
SELECT n, grpsize = COUNT(*) OVER(PARTITION BY grp)+1
FROM LongStrings)
SELECT TOP 1
StringMatch = SUBSTRING(@String1,n,grpsize),
StartPoint = n
FROM Processing
ORDER BY grpsize DESC, n;
SELECT DATEDIFF(MILLISECOND,@Now,GETDATE());
“Write the query the simplest way. If through testing it becomes clear that the performance is inadequate, consider alternative query forms.” - Gail ShawFor fast, accurate and documented assistance in answering your questions, please read this article.
Understanding and using APPLY, (I) and (II) Paul White
Hidden RBAR: Triangular Joins / The "Numbers" or "Tally" Table: What it is and how it replaces a loop Jeff Moden -
Very slick Chris.:-)
I'm buried today but will play with this later tonight and report back.
"I cant stress enough the importance of switching from a sequential files mindset to set-based thinking. After you make the switch, you can spend your time tuning and optimizing your queries instead of maintaining lengthy, poor-performing code."-- Itzik Ben-Gan 2001
-
Hi Alan and thank you for sharing this problem and this very fine post, good job indeed. I've been swamped with work but will have a go at it as soon as I can.
😎
-
ChrisM@Work (1/5/2016)
Hi Alan, nice job 🙂Here's a completely different take on the problem, loosely based on some fuzzy matching stuff I've worked on over the years. It looks promising and you won't have to do much to tweak it whichever way:
Very nice indeed Chris!
😎
For a laugh, I'm just going to post a query I wrote yesterday based on some work I did years ago
USE TEEST;GO
SET NOCOUNT ON;
--
-- ------ ------
DECLARE @STR02 VARCHAR(8000) = 'ABCA12345678BCABCABCABCABCABCABCABCABCABC0123456789ABCAB12345678CABCABCABCA12345678BCABCABCABCABCABCABC12345678ABCABCABCABC12345678ABCABC12345678ABCABCA12345678BCABCABCABCABCABCABCABCABCABC0123456789ABCAB12345678CABCABCABCA12345678BCABCABCABCABCABCABC12345678ABCABCABCABC12345678ABCABC12345678ABCABCA12345678BCABCABCABCABCABCABCABCABCABC0123456789ABCAB12345678CABCABCABCA12345678BCABCABCABCABCABCABC12345678ABCABCABCABC12345678ABCABC12345678ABCABCA12345678BCABCABCABCABCABCABCABCABCABC0123456789ABCAB12345678CABCABCABCA12345678BCABCABCABCABCABCABC12345678ABCABCABCABC12345678ABC01234567890ABC12345678ABCABCA12345678BCABCABCABCABCABCABCABCABCABC01234567FINDMEYINHERE89ABCAB12345678CABCABCABCA12345678BCABCABCABCABCABCABC12345678ABCABCABCABC12345678ABCABC12345678ABCABCA12345678BCABCABCABCABCABCABCABCABCABC0123456789ABCAB12345678CABCABCABCA12345678BCABCABCABCABCABCABC12345678ABCABCABCABC12345678ABCABC12345678ABCABCA12345678BCABCABCABCABCABCABCABCABCABC0123456789ABCAB12345678CABCABCABCA12345678BCABCABCABCABCABCABC12345678ABCABCABCABC12345678ABCABC12345678ABCABCA12345678BCABCABCABCABCABCABCABCABCABC0123456789ABCAB12345678CABCABCABCA12345678BCABCABCABCABCABCABC12345678ABCABCABCABC12345678ABCABC12345678ABCABCA12345678BCABCABCABCABCABCABCABCABCABC0123456789ABCAB12345678CABCABCABCA12345678BCABCABCABCABCABCABC12345678ABCABCABCABC12345678ABCABC12345678ABCABCA12345678BCABCABCABCABCABCABCABCABCABC0123456789ABCAB12345678CABCABCABCA12345678BCABCABCABCABCABCABC12345678ABCABCABCABC12345678ABCABC12345678ABCABCA12345678BCABCABCABCABCABCABCABCABCABC0123456789ABCAB12345678CABCABCABCA12345678BCABCABCABCABCABCABC12345678ABCABCABCABC12345678ABCABC12345678ABCABCA12345678BCABCABCABCABCABCABCABCABCABC0123456789ABCAB12345678CABCABCABCA12345678BCABCABCABCABCABCABC12345678ABCABCABCABC12345678ABCABC12345678ABC';
-- 1234567890123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890
-- 0 1 2 3 4 5 6 7 8 9 10
DECLARE @STR01 VARCHAR(8000) = 'FINDMEXINHERE'
-- 12345678901234567890123456789012345678901234567890
-- 0 1 2 3 4 5
--
;WITH SHORTER_LONGER AS
(
SELECT
CASE
WHEN LEN(@STR01) <= LEN(@STR02) THEN @STR01
ELSE @STR02
END AS SHORTER_STR
,CASE
WHEN LEN(@STR01) <= LEN(@STR02) THEN @STR02
ELSE @STR01
END AS LONGER_STR
)
, T(N) AS (SELECT N FROM (VALUES (0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) AS X(N))
,NUM_SHORT(N) AS
(
SELECT
TOP((SELECT LEN(SL.SHORTER_STR) FROM SHORTER_LONGER SL)) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS N
FROM T T1,T T2,T T3,T T4
)
,SHORT_STR_CHARS AS
(
SELECT
NS.N
,ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS RID
,SUBSTRING(SL.SHORTER_STR,NS.N,1) AS SCHR
,(CHARINDEX(SUBSTRING(SL.SHORTER_STR,NS.N,2),SL.LONGER_STR,1)) AS IS_IN_LONG
FROM SHORTER_LONGER SL
CROSS APPLY NUM_SHORT NS
WHERE (CHARINDEX(SUBSTRING(SL.SHORTER_STR,NS.N,2),SL.LONGER_STR,1)) > 0
)
SELECT
SSC.N
,SSC.N - SSC.RID
,SSC.SCHR
,SSC.IS_IN_LONG
FROM SHORT_STR_CHARS SSC;
-
Eirikur Eiriksson (1/5/2016)
For a laugh, I'm just going to post a query I wrote yesterday based on some work I did years agoVery fast code! It wouldn't take much tweaking to make it return the required results either.
Here's another version which is about as fast and does return the required results but could return false positives with large enough strings:
DECLARE @Now DATETIME = GETDATE();WITH E1 AS (SELECT n FROM (VALUES (0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) d (n)),
E2 AS (SELECT a.n FROM E1 a, E1 b),
iTally AS (SELECT n = ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM E2 a, E2 b) -- TOP(8000)
SELECT TOP(1) WITH TIES
Word = SUBSTRING(@String1, MIN(n), 1+COUNT(*)),
Position = MIN(n),
[Length] = 1+COUNT(*)
FROM (
SELECT n, dr = DENSE_RANK() OVER(ORDER BY n)
FROM iTally
WHERE n <= LEN(@String1)
AND @String2 LIKE '%' + SUBSTRING(@String1,n,2) + '%'
) d
GROUP BY n-dr
ORDER BY COUNT(*) DESC;
SELECT [Duration (ms)] = DATEDIFF(MILLISECOND,@Now,GETDATE());
“Write the query the simplest way. If through testing it becomes clear that the performance is inadequate, consider alternative query forms.” - Gail ShawFor fast, accurate and documented assistance in answering your questions, please read this article.
Understanding and using APPLY, (I) and (II) Paul White
Hidden RBAR: Triangular Joins / The "Numbers" or "Tally" Table: What it is and how it replaces a loop Jeff Moden -
ChrisM@Work (1/6/2016)
Eirikur Eiriksson (1/5/2016)
For a laugh, I'm just going to post a query I wrote yesterday based on some work I did years agoVery fast code! It wouldn't take much tweaking to make it return the required results either.
Here's another version which is about as fast and does return the required results but could return false positives with large enough strings:
Slick and nice Chris, didn't expect anything else.
😎
I think the challenge, in order to optimize the performance, is to get rid of the sorting, a blocking sort operator in the execution plan is about half the cost of the query. Thinking that a more relational division type approach might be better.
-
First, sorry for falling off the radar - I personally get annoyed when people post a question then vanish. That said I have been looking at and playing around with the code that you both posted and it's excellent stuff mates. Frankly, I've had to spend some time reverse engineering your work to understand what you're doing because some of what's going on is a little over my head.
What has me completely blown away is Chris' first solution is finding the longest common subsequence. This is a much, much trickier problem than the longest common substring problem I originally posted about. I have spent literally dozens of hours trying to write a query that retrieves the longest common subsequence and failed miserably. Bravo Chris! Extremely impressive stuff!
I'm buried with work and won't be able to play around with this code again until tomorrow but I just wanted to thank you both for your input.
"I cant stress enough the importance of switching from a sequential files mindset to set-based thinking. After you make the switch, you can spend your time tuning and optimizing your queries instead of maintaining lengthy, poor-performing code."-- Itzik Ben-Gan 2001
-
UPDATED 20200803 at 9:30PM
Ok, 4 1/2 years later I have a something really good to show!
This code is from one of many articles in various phases of completion which I'll post ASAP. I think this puts the final nail in the mTVF coffin before kicking it into the ocean (even with 2019 mTVF inlining). That was the original point of this post when I posted it.
- Given the length of the string(L), the number of substrings is calculated as L(L+1)/2. This means that, for two 8K strings you have to compare ~32,000,000 substrings with ~32,000,000 other substrings, a total of ~1,000,000,000,000,000 (a quadtrillion in US english.)
- We also must sort all the matching strings to determine the longest one, up to one-quadrillion rows sorted (N log N complexity)
Using a single CPU (MAXDOP 1) let's do the performance test. Below I'm using a combination of lcssApprox8K cascading to other lcssApprox8K calls to itself or lcssWindowAB to "reduce the search area" while still returning an exact, deterministic result. I am good at figuring this stuff out but terrible at explaining it. See the attached code which you can run in a tempDB to see how these guys work. I haven't turned this logic into iTVFs yet because I have more testing to do. LCSS_GapReduced and LCSS_IslandReduced are the names I give to the inline set-based code used in this test:
THE TEST HARNESS
(note that the string sizes are 7998 and 7999 to show they are not truncated.)
SET NOCOUNT ON;
BEGIN
SET STATISTICS TIME, IO ON;
DECLARE @s1 VARCHAR(8000) = REPLICATE('!',11)+REPLICATE('Blah...',161)+REPLICATE('!',6860),
@s2 VARCHAR(8000) = REPLICATE('?',34)+REPLICATE('Blah...',162)+REPLICATE('?',6831),
@gap1 INT = 800,
@high INT = 1200, -- CHEATER PARAM
@p INT = 1; -- precision
-- Parameters for performance test
DECLARE
@Fn1 VARCHAR(50) = CHAR(10)+'samd.lcssApprox8K, No Ties - ',
@Fn2 VARCHAR(50) = CHAR(10)+'samd.lcssWindow8K, No Ties - ',
@br VARCHAR(95) = CHAR(10)+REPLICATE('-',90),
@br2 VARCHAR(95) = REPLICATE('-',30);
PRINT @Fn1+CONCAT('Serial(g=',@gap1,',h=',@high,')'+@br)
SELECT LCSS_GapReduced.*
FROM
(
SELECT a.L1, a.L2, a.S1Index, a.S2Index, p.ItemLen, p.Item--, a.SimMax
FROM samd.lcssApprox8K(@s1,@s2,@high,@gap1) AS a --Approx #1
CROSS APPLY (VALUES(a.ItemLen,IIF(@gap1<@high,@high,a.ItemLen+@gap1-1))) AS tp(L,H) --Tuning Arg #1
CROSS APPLY (VALUES(ISNULL(NULLIF((tp.H-tp.L)/10,0),1))) AS r(G) -- Gap Reducer
CROSS APPLY samd.lcssApprox8K(SUBSTRING(a.S1,a.S1Index,tp.H),
SUBSTRING(a.S2,a.S2Index,tp.H),tp.H,r.G-1) AS a2
CROSS APPLY (VALUES(a2.itemLen+r.G-1)) AS f2(H)
CROSS APPLY samd.lcssApprox8K(SUBSTRING(a2.S1,a2.S1Index,f2.H),
SUBSTRING(a2.S2,a2.S2Index,f2.H),f2.H,@p) AS p -- Precision (@p=1=Exact)
) AS LCSS_GapReduced
OPTION(MAXDOP 1); --OPTION(QUERYTRACEON 8649); << No benefit
PRINT @Fn2+CONCAT('Serial(g=',@gap1,',h=',@high,')'+@br);
SELECT LCSS_IslandReduced.*
FROM
(
SELECT a.L1, a.L2, a.S1Index, a.S2Index, lcss.ItemLen, lcss.Item--, a.SimMax
FROM samd.lcssApprox8K(@s1,@s2,@high,@gap1) AS a -- Approx #1
CROSS APPLY (VALUES(a.ItemLen,
IIF(@gap1<@high,@high,a.ItemLen+@gap1-1))) AS tp(L,H) -- Tuning Prm #1
CROSS APPLY (VALUES(ISNULL(NULLIF((tp.H-tp.L)/10,0),1))) AS r(G) -- Gap Reducer
CROSS APPLY samd.lcssApprox8K(SUBSTRING(a.S1,a.S1Index,tp.H),
SUBSTRING(a.S2,a.S2Index,tp.H),tp.H,r.G-1) AS a2
CROSS APPLY (VALUES(a2.itemLen+r.G-1)) AS f2(H) -- Approx #
CROSS APPLY samd.lcssWindowAB(a2.S1,a2.S2,@high,1) AS lcss -- Exact Results
) AS LCSS_IslandReduced
OPTION(MAXDOP 1); --OPTION(QUERYTRACEON 8649); << No benefit
SET STATISTICS TIME, IO OFF;
END;FUNCTION RESULT SETS:
samd.lcssApprox8K, No Ties - Serial(g=800,h=1200)
------------------------------------------------------------------------------------------
L1 L2 S1Index S2Index ItemLen Item
------ ------ -------------------- ----------- ----------- -------------------------------
7998 7999 12 35 1127 Blah...Blah...Blah...
samd.lcssWindow8K, No Ties - Serial(g=800,h=1200)
------------------------------------------------------------------------------------------
L1 L2 S1Index S2Index ItemLen Item
------ ------ -------------------- ----------- ----------- -------------------------------
7998 7999 12 35 1127 Blah...Blah...Blah...PERFORMANCE TEST RESULTS:
samd.lcssApprox8K, No Ties - Serial(g=800,h=1200)
------------------------------------------------------------------------------------------
SQL Server Execution Times: CPU time = 0 ms, elapsed time = 6 ms.
samd.lcssWindow8K, No Ties - Serial(g=800,h=1200)
------------------------------------------------------------------------------------------
Table 'Worktable'. Scan count 4, logical reads 2789
Table 'tally'. Scan count 2, logical reads 8...
SQL Server Execution Times: CPU time = 1593 ms, elapsed time = 1587 ms.
Completion time: 2020-07-31T13:32:03.9359718-05:00Note that the function returns the Length of the strings, and the position, length and text of the longest common substring in each of the two strings. Using pure brute for this would be ~1,000,000,000,000,000 logical operations. Here we're using brute force and getting the result back in: 0.0MS CPU time using only one CPU for the first version and 1.5 seconds for the other.
Last - FOR THE ATTACHED CODE: ONCE YOU OPEN IT, GO TO EDIT > OUTLINING > TOGGLE ALL OUTLINING so that it looks like this in SSMS:
 "I cant stress enough the importance of switching from a sequential files mindset to set-based thinking. After you make the switch, you can spend your time tuning and optimizing your queries instead of maintaining lengthy, poor-performing code."
"I cant stress enough the importance of switching from a sequential files mindset to set-based thinking. After you make the switch, you can spend your time tuning and optimizing your queries instead of maintaining lengthy, poor-performing code."-- Itzik Ben-Gan 2001
-
I'm not seeing any code attached to your last post. What code are you talking about being "attached"?
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:
I'm not seeing any code attached to your last post. What code are you talking about being "attached"?
Grrr...
/*********************************** PART #1 - SETUP ***********************************/
SET NOCOUNT ON;
USE tempdb;
GO
CREATE SCHEMA core;
GO
CREATE SCHEMA samd;
GO
CREATE FUNCTION core.rowz()
/*****************************************************************************************
[Purpose]:
Returns 1024 rows. Can be used to build a virtual tally table (AKA virtual auxillary
table of numbers), "dummy rows" for sample data for performance test and much more.
[Author]:
Alan Burstein
[Compatibility]:
SQL Server 2008+
[Syntax]:
--===== Basic Syntax Example
SELECT f.x
FROM core.rowz() AS f;
[Parameters]: N/A
[Returns]:
Inline Table Valued Function returns:
x = INT; A dummy row
[Dependencies]: N/A
[Developer Notes]:
1. core.rowz can be self-cross joined once for up to 1,048,576 rows; with a second cross
join, you have up to 1,073,741,824 rows.
2. The return type is INT. My testing did not show any performance improvement when
changing the return type.
3. core.rowz is deterministic. For more about deterministic functions see:
https://msdn.microsoft.com/en-us/library/ms178091.aspx
[Examples]:
--===== 1. Return 1000 rows
SELECT TOP (1000) 1
FROM core.rowz() AS f;
--===== 2. Return 50000 rows
SELECT TOP (50000) 1
FROM core.rowz() AS a
CROSS JOIN core.rowz() AS b;
--==== 3. Return 50000 random strings
SELECT TOP (50000) SomeString = NEWID()
FROM core.rowz() AS a
CROSS JOIN core.rowz() AS b;
[Revision History]:
-----------------------------------------------------------------------------------------
Rev 00 - 20200417 - Initial Development - Alan Burstein
*****************************************************************************************/
RETURNS TABLE WITH SCHEMABINDING AS RETURN
SELECT a0.x
FROM
(
VALUES(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)
) AS a0(x);
GO
CREATE FUNCTION core.rangeAB
(
@Low BIGINT, -- (start) Lowest number in the set
@High BIGINT, -- (stop) Highest number in the set
@Gap BIGINT, -- (step) Difference between each number in the set
@Row1 BIT -- Base: 0 or 1; should RN begin with 0 or 1?
)
/****************************************************************************************
[Purpose]:
Creates a lazy, in-memory, forward-ordered sequence of up to 1,073,741,824 integers
beginning with @Low and ending with @High (inclusive). RangeAB is a pure, 100% set-based
alternative to solving SQL problems using iterative methods such as loops, cursors and
recursive CTEs. RangeAB is based on Itzik Ben-Gan's getnums function for producing a
sequence of integers and uses logic from Jeff Moden's fnTally function which includes a
parameter for determining if the "row-number" (RN) should begin with 0 or 1.
I used the name "RangeAB" because it functions and performs almost identically to
the Range function built into Python and Clojure. RANGE is a reserved SQL keyword so I
went with "RangeAB". Functions/Algorithms developed using rangeAB can be easilty ported
over to Python, Clojure or any other programming language that leverages a lazy sequence.
The two major differences between RangeAB and the Python/Clojure versions are:
1. RangeAB is *Inclusive* where the other two are *Exclusive". range(0,3) in Python and
Clojure return [0 1 2], core.rangeAB(0,3) returns [0 1 2 3].
2. RangeAB has a fourth Parameter (@Row1) to determine if RN should begin with 0 or 1.
[Author]:
Alan Burstein
[Compatibility]:
SQL Server 2008+
[Syntax]:
SELECT r.RN, r.OP, r.N1, r.N2
FROM core.rangeAB(@Low,@High,@Gap,@Row1) AS r;
[Parameters]:
@Low = BIGINT; represents the lowest value for N1.
@High = BIGINT; represents the highest value for N1.
@Gap = BIGINT; represents how much N1 and N2 will increase each row. @Gap is also the
difference between N1 and N2.
@Row1 = BIT; represents the base (first) value of RN. When @Row1 = 0, RN begins with 0,
when @row = 1 then RN begins with 1.
[Returns]:
Inline Table Valued Function returns:
RN = BIGINT; a row number that works just like T-SQL ROW_NUMBER() except that it can
start at 0 or 1 which is dictated by @Row1. If you need the numbers:
(0 or 1) through @High, then use RN as your "N" value, ((@Row1=0 for 0, @Row1=1),
otherwise use N1.
OP = BIGINT; returns the "finite opposite" of RN. When RN begins with 0 the first number
in the set will be 0 for RN, the last number in will be 0 for OP. When returning the
numbers 1 to 10, 1 to 10 is retrurned in ascending order for RN and in descending
order for OP.
Given the Numbers 1 to 3, 3 is the opposite of 1, 2 the opposite of 2, and 1 is the
opposite of 3. Given the numbers -1 to 2, the opposite of -1 is 2, the opposite of 0
is 1, and the opposite of 1 is 0.
The best practie is to only use OP when @Gap > 1; use core.O instead. Doing so will
improve performance by 1-2% (not huge but every little bit counts)
N1 = BIGINT; This is the "N" in your tally table/numbers function. this is your *Lazy*
sequence of numbers starting at @Low and incrimenting by @Gap until the next number
in the sequence is greater than @High.
N2 = BIGINT; a lazy sequence of numbers starting @Low+@Gap and incrimenting by @Gap. N2
will always be greater than N1 by @Gap. N2 can also be thought of as:
LEAD(N1,1,N1+@Gap) OVER (ORDER BY RN)
[Dependencies]:
core.rowz() (iTVF)
[Developer Notes]:
Removed for brevity
-----------------------------------------------------------------------------------------
[Revision History]:
Rev 00.0 - 20140518 - Initial Development - AJB
Rev 04.0 - 20200329 - 1. Removed startup predicate that dicatated that:
@High >= @Low AND @Gap > 0 AND @Row1 = @Row1.
That means that this must be handled outside the function
2. Removed the ISNULL Logic from the TOP statement. This will make
errors possible if you provide bad parameters.
3. Now using core.rowz() to build the rows - AJB
*****************************************************************************************/
RETURNS TABLE WITH SCHEMABINDING AS RETURN
WITH iTally(RN) AS
(
SELECT ROW_NUMBER() OVER (ORDER BY (SELECT 1))
FROM core.rowz() AS a -- 1024
CROSS JOIN core.rowz() AS b -- 1,048,576 rows (1024*1024)
CROSS JOIN core.rowz() AS c -- 1,073,741,824 rows (1024*1024*1024)
)
SELECT r.RN, r.OP, r.N1, r.N2
FROM
(
SELECT
RN = 0,
OP = (@High-@Low)/@Gap,
N1 = @Low,
N2 = @Gap+@Low
WHERE @Row1 = 0
UNION ALL
SELECT TOP (ABS((ISNULL(@high,0)-ISNULL(@low,0))/ISNULL(@gap,0)+ISNULL(@row1,1)))
RN = i.RN,
OP = (@High-@Low)/@Gap+(2*@Row1)-i.RN,
N1 = (i.rn-@Row1)*@Gap+@Low,
N2 = (i.rn-(@Row1-1))*@Gap+@Low
FROM iTally AS i
ORDER BY i.RN
) AS r;
GO
IF OBJECT_ID('samd.lcssApprox8K','IF') IS NOT NULL DROP FUNCTION samd.lcssApprox8K;
GO
IF OBJECT_ID('samd.bernie8K','IF') IS NOT NULL
DROP FUNCTION samd.bernie8K;
GO
CREATE FUNCTION samd.bernie8K
(
@s1 VARCHAR(8000),
@s2 VARCHAR(8000)
)
/*****************************************************************************************
[Purpose]:
This function allows developers to optimize and simplify how they fuzzy comparisons
between two strings (@s1 and @s2).
bernie8K returns:
S1 = short string - LEN(S1) will always be <= LEN(S2); The formula to calculate S1 is:
S1 = CASE WHEN LEN(@s1) > LEN(@s2) THEN @s2, ELSE @s1 END;
S2 = long string - LEN(S1) will always be <= LEN(S2); The formula to calculate S1 is:
S2 = CASE WHEN LEN(@s1) > LEN(@s2) THEN @s1, ELSE @s2;
L1 = short string length = LEN(S1)
L2 = long string length = LEN(S2)
D = distance = L2-L1; how many characters needed to make L1=L2; D tells us:
1. D is the *minimum* Levenshtein distance between S1 and S2
2. L2/D is the *maximum* similarity between S1 and S2
I = index = CHARINDEX(S1,S2);
B = bernie distance = When B is not NULL then:
1. B = The Levenshtein Distance between S1 and S2
2. B = The Damarau-Levenshtein Distance bewteen S1 and S2
3. B = The Longest Common Substring & Longest Common Subsequence of S1 and S2
4. KEY! = The similarity between L1 and L2 is L1/l2
MS = Max Similarity = Maximum similarity
S = Minimum Similarity = When B isn't null S is the same Similarity value returned by
mdq.Similarity: https://msdn.microsoft.com/en-us/library/ee633878(v=sql.105).aspx
[Author]:
Alan Burstein
[Compatibility]:
SQL Server 2005+, Azure SQL Database, Azure SQL Data Warehouse & Parallel Data Warehouse
[Parameters]:
@s1 = varchar(8000); First of two input strings to be compared
@s2 = varchar(8000); Second of two input strings to be compared
[Returns]:
S1 = VARCHAR(8000); The shorter of @s1 and @s2; returns @s1 when LEN(@s1)=LEN(@s2)
S2 = VARCHAR(8000); The longer of @s1 and @s2; returns @s2 when LEN(@s1)=LEN(@s2)
L1 = INT; The length of the shorter of @s1 and @s2 (or both when they're of equal length)
L2 = INT; The length of the longer of @s1 and @s2 (or both when they're of equal length)
D = INT; L2-L1; The "distance" between L1 and L2
I = INT; The location (position) of S1 inside S2; Note that when 1>0 then S1 is both:
1. a substring of S2
2. a subsequence of S2
B = INT; The Bernie Distance between @s1 and @s1; When B is not null then:
1. B = The Levenshtein Distance between S1 and S2
2. B = The Damarau-Levenshtein Distance bewteen S1 and S2
3. B = The Longest Common Substring & Longest Common Subsequence of S1 and S2
4. KEY! = The similarity between L1 and L2 is L1/l2
MS = DECIMAL(6,4); Returns the same simlarity score as mdq.Similarity would if S1 where a
substring of S2
S = DECIMAL(6,4); When B isn't null then S is the same Similarity value returned by
mdq.Similarity
For more about mdq.Similarity visit:
https://msdn.microsoft.com/en-us/library/ee633878(v=sql.105).aspx
[Syntax]:
--===== Autonomous
SELECT b.TX, b.S1, b.S2, b.L1, b.L2, b.D, b.I, b.B, b.MS, b.S
FROM samd.bernie8K('abc123','abc12') AS b;
--===== CROSS APPLY example
SELECT b.TX, b.S1, b.S2, b.L1, b.L2, b.D, b.I, b.B, b.MS, b.S
FROM dbo.SomeTable AS t
CROSS APPLY samd.bernie8K(t.S1,t.S2) AS b;
[Dependencies]:
N/A
[Developer Notes]:
X. Bernie ignores leading and trailing spaces trailing, and returns trimmed strings!
1. When @s1 is NULL then S2 = @s2, L2 = LEN(@s2);
When @s2 is NULL then S1 = @s1, L1 = LEN(@s1)
2. bernie8K ignores leading and trailing whitespace on both input strings (@s1 and @s2).
In other words LEN(@s1)=DATALENGTH(@s1), LEN(@s2)=DATALENGTH(@s2)
3. bernie8K is deterministic; for more about deterministic and nondeterministic
functions see https://msdn.microsoft.com/en-us/library/ms178091.aspx
[Examples]:
--==== 1. BASIC USE:
-- 1.1. When b.I > 0
SELECT b.TX, b.S1, b.S2, b.L1, b.L2, b.D, b.I, b.B, b.MS, b.S
FROM samd.bernie8K('abc1234','bc123') AS b;
-- 1.2. When b.I = 0
SELECT b.TX, b.S1, b.S2, b.L1, b.L2, b.D, b.I, b.B, b.MS, b.S
FROM samd.bernie8K('abc123','xxx') AS b;
-- 1.3. When @s1 and/or @s2 are blank or a space
SELECT b.TX, b.S1, b.S2, b.L1, b.L2, b.D, b.I, b.B, b.MS, b.S
FROM samd.bernie8K('abc123','') AS b;
-- 1.4. When @s1 and/or @s2 are blank are NULL
SELECT b.TX, b.S1, b.S2, b.L1, b.L2, b.D, b.I, b.B, b.MS, b.S
FROM samd.bernie8K('abc123',NULL) AS b;
--==== 2. bernie8K behaivior
-- 2.1. Equality
SELECT b.* FROM samd.bernie8K('abc','abc') AS b; -- equal strings
SELECT b.* FROM samd.bernie8K('','') AS b; -- blank S1 & S2
-- 2.2. Empty strings
SELECT b.* FROM samd.bernie8K('','abc') AS b; -- blank S1
SELECT b.* FROM samd.bernie8K('abc','') AS b; -- blank S2
-- 2.3. NULL values: Note the behavior difference vs blank (explain real-world example)
SELECT b.* FROM samd.bernie8K('abc',NULL) AS b;
SELECT b.* FROM samd.bernie8K(NULL,'abc') AS b;
-- 2.4. Note what happens when an Inner Match occures
-- (when one string is blank or S1 is a substring of S2)
SELECT b.* FROM samd.bernie8K('abc123','abc12') AS b;
SELECT b.* FROM samd.bernie8K('abc123','bc123') AS b;
SELECT b.* FROM samd.bernie8K('abc123','bc') AS b;
-- 2.5 No inner match
SELECT b.* FROM samd.bernie8K('abc123','abcd') AS b;
--==== 3. Understanding Similarity
-- 3.1. Using mdq.similarity:
SELECT l.* FROM SQLDevToolbox.samd.levenshteinAB('Maine','Mai',.01) l -- 3/5 = 0.6
SELECT l.* FROM SQLDevToolbox.samd.levenshteinAB('Mississippi','Mississipp',0) AS l
-- 3.2. Using bernie8k:
SELECT b.* FROM samd.bernie8K('Maine','mai') AS b -- 4/5 = 0.8
SELECT b.* FROM samd.bernie8K('Mississippi','Mississipp') b
--==== 4. Understanding the Lazy evaluation
-- Run each with "show actual execution plan" ON then examine the Constant Scan operator
SELECT b.D
FROM samd.bernie8K('abc123','abc12') AS b;
SELECT b.S1, b.S2, b.L1, b.L2, b.D
FROM samd.bernie8K('abc123','abc12') AS b;
SELECT b.S1, b.S2, b.L1, b.L2, b.D, b.I, b.B, b.S
FROM samd.bernie8K('abc123','abc12') AS b;
-----------------------------------------------------------------------------------------
[Revision History]:
Rev 00 - 20180708 - Inital Creation - Alan Burstein
Rev 01 - 20181231 - Added Boolean logic for transpositions (TX column) - Alan Burstein
*****************************************************************************************/
RETURNS TABLE WITH SCHEMABINDING AS RETURN
SELECT
TX = base.TX, -- transposed? boolean - were S1 and S2 transposed?
S1 = base.S1, -- short string >> IIF(LEN(@s1)>LEN(@s2),@s2,@s1)
S2 = base.S2, -- long string >> IIF(LEN(@s1)>LEN(@s2),@s1,@s2)
L1 = base.L1, -- short string length >> IIF(LEN(@s1)>LEN(@s2),LEN(@s2),LEN(@s1))
L2 = base.L2, -- long string length >> IIF(LEN(@s1)>LEN(@s2),LEN(@s1),LEN(@s2))
D = base.D, -- bernie string distance >> # of characters needed to make L1=L2
I = iMatch.idx, -- bernie index >> position of S1 within S2
B = bernie.D, -- bernie distance >> IIF(CHARINDEX(S1,S2)>0,L2-L1,NULL)
MS = CAST(maxSim.D AS DECIMAL(6,4)), -- maximum similarity
S = CAST(similarity.D AS DECIMAL(6,4))-- (minimum) similarity
FROM
(
SELECT
TX = IIF(ls.L=1,1,0),
S1 = IIF(ls.L=1,s.S2,s.S1),
S2 = IIF(ls.L=1,s.S1,s.S2),
L1 = IIF(ls.L=1,l.S2,l.S1),
L2 = IIF(ls.L=1,l.S1,l.S2),
D = ABS(l.S1-l.S2)
FROM (VALUES(LEN(@S1),LEN(@S2))) AS l(S1,S2) -- LEN(S1,S2)
CROSS APPLY (VALUES(@S1,@S2)) AS s(S1,S2) -- S1 and S2 trimmed
CROSS APPLY (VALUES(SIGN(l.S1-l.S2))) AS ls(L) -- LeftLength
) AS base
CROSS APPLY (VALUES(ABS(SIGN(base.L1)-1),ABS(SIGN(base.L2)-1))) AS blank(S1,S2)
CROSS APPLY (VALUES(CHARINDEX(base.S1,base.S2))) AS iMatch(idx)
CROSS APPLY (VALUES(IIF(SIGN(iMatch.idx|blank.S1)=1,base.D,NULL))) AS bernie(D)
CROSS APPLY (VALUES(IIF(blank.S1=1,1.*blank.S2,1.*base.L1/base.L2))) AS maxSim(D)
CROSS APPLY (VALUES(1.*NULLIF(SIGN(iMatch.idx),0)*maxSim.D)) AS similarity(D);
GO
IF OBJECT_ID('samd.ngrams8k', 'IF') IS NOT NULL DROP FUNCTION samd.ngrams8k;
GO
CREATE FUNCTION samd.ngrams8k
(
@String VARCHAR(8000), -- Input string
@N INT -- requested token size
)
/*****************************************************************************************
[Purpose]:
A character-level N-Grams function that outputs a contiguous stream of @N-sized tokens
based on an input string (@String). Accepts strings up to 8000 varchar characters long.
For more information about N-Grams see: http://en.wikipedia.org/wiki/N-gram.
[Author]:
Alan Burstein
[Compatibility]:
SQL Server 2008+, Azure SQL Database
[Syntax]:
--===== Autonomous
SELECT ng.Position, ng.Token
FROM samd.ngrams8k(@String,@N) AS ng;
--===== Against a table using APPLY
SELECT s.SomeID, ng.Position, ng.Token
FROM dbo.SomeTable AS s
CROSS APPLY samd.ngrams8k(s.SomeValue,@N) AS ng;
[Parameters]:
@String = The input string to split into tokens.
@N = The size of each token returned.
[Returns]:
Position = BIGINT; the position of the token in the input string
token = VARCHAR(8000); a @N-sized character-level N-Gram token
[Dependencies]:
1. core.rangeAB (iTVF)
[Developer Notes]:
1. ngrams8k is not case sensitive;
2. Many functions that use ngrams8k will see a huge performance gain when the optimizer
creates a parallel execution plan. One way to get a parallel query plan (if the
optimizer does not choose one) is to use make_parallel by Adam Machanic which can be
found here:
sqlblog.com/blogs/adam_machanic/archive/2013/07/11/next-level-parallel-plan-porcing.aspx
3. When @N is less than 1 or greater than the datalength of the input string then no
tokens (rows) are returned. If either @String or @N are NULL no rows are returned.
This is a debatable topic but the thinking behind this decision is that: because you
can't split 'xxx' into 4-grams, you can't split a NULL value into unigrams and you
can't turn anything into NULL-grams, no rows should be returned.
For people who would prefer that a NULL input forces the function to return a single
NULL output you could add this code to the end of the function:
UNION ALL
SELECT 1, NULL
WHERE NOT(@N > 0 AND @N <= DATALENGTH(@String)) OR (@N IS NULL OR @String IS NULL)
4. ngrams8k is deterministic. For more about deterministic functions see:
https://msdn.microsoft.com/en-us/library/ms178091.aspx
[Examples]:
--===== 1. Split the string, "abcd" into unigrams, bigrams and trigrams
SELECT ng.Position, ng.Token FROM samd.ngrams8k('abcd',1) AS ng; -- unigrams (@N=1)
SELECT ng.Position, ng.Token FROM samd.ngrams8k('abcd',2) AS ng; -- bigrams (@N=2)
SELECT ng.Position, ng.Token FROM samd.ngrams8k('abcd',3) AS ng; -- trigrams (@N=3)
--===== 2. Counting Characters
-- 2.1. How many times the substring "AB" appears in each record
DECLARE @table TABLE(stringID int identity primary key, string varchar(100) UNIQUE);
INSERT @table(string) VALUES ('AB123AB'),('123ABABAB'),('!AB!AB!'),('AB-AB-AB-AB-AB');
SELECT t.String, Occurances = COUNT(*)
FROM @table AS t
CROSS APPLY samd.ngrams8k(t.String,2) AS ng
WHERE ng.Token = 'AB'
GROUP BY t.String; -- NOTE: to avoid a sort, we need an index on the GROUP BY Key(s)
-- 2.2. Count occurances of the letters A-F in @String - using a sort
DECLARE @String VARCHAR(100) = NEWID();
SELECT ng.Token, Ttl = COUNT(ng.Token)
FROM samd.ngrams8k(@String,1) AS ng
WHERE CHARINDEX(ng.Token,'ABCDEF') > 0
GROUP BY ng.Token;
GO
-- 2.3. Count occurances of the letters A-F in @String - using a virtual index (sortless)
DECLARE @String VARCHAR(100) = NEWID();
SELECT Token = CHAR(r.RN+64), ttl = COUNT(ng.Token)
FROM core.rangeAB(1,26,1,1) AS r
JOIN samd.ngrams8k(@String,1) AS ng
ON r.RN = ASCII(ng.Token)-64
GROUP BY r.RN
OPTION (RECOMPILE);
-- NOTE ^^: OPTION (RECOMPILE) required to avoid a sort
[Revision History]:
------------------------------------------------------------------------------------------
Rev 00 - 20140310 - Initial Development - Alan Burstein
Rev 01 - 20150522 - Removed DQS N-Grams functionality, improved iTally logic. Also Added
conversion to bigint in the TOP logic to remove implicit conversion
to bigint - Alan Burstein
Rev 03 - 20150909 - Added logic to only return values if @N is greater than 0 and less
than the length of @String. Updated comment section. - Alan Burstein
Rev 04 - 20151029 - Added ISNULL logic to the TOP clause for the @String and @N
parameters to prevent a NULL string or NULL @N from causing "an
improper value" being passed to the TOP clause. - Alan Burstein
Rev 05 - 20171228 - Small simplification; changed:
(ABS(CONVERT(BIGINT,(DATALENGTH(ISNULL(@String,''))-(ISNULL(@N,1)-1)),0)))
to:
(ABS(CONVERT(BIGINT,(DATALENGTH(ISNULL(@String,''))+1-ISNULL(@N,1)),0)))
Rev 06 - 20180612 - Using CHECKSUM(N) in the to convert N in the token output instead of
using (CAST N as int). CHECKSUM removes the need to convert to int.
Rev 07 - 20200329 - re-designed to: Use core.rangeAB
Removed startup predicate: WHERE @N > 0 AND @N <= LEN(@String)
This must now be handled outside the function - Alan Burstein
*****************************************************************************************/
RETURNS TABLE WITH SCHEMABINDING AS RETURN
SELECT
Position = r.RN,
Token = SUBSTRING(@String,CHECKSUM(r.RN),@N)
FROM core.rangeAB(1,LEN(@String)+1-@N,1,1) AS r;
GO
IF OBJECT_ID('core.tally','U') IS NOT NULL DROP TABLE core.tally;
GO
CREATE TABLE core.tally(N INT NOT NULL)
GO
ALTER TABLE core.tally ADD CONSTRAINT pk_cl__core_tally__N PRIMARY KEY CLUSTERED(N);
GO
CREATE UNIQUE NONCLUSTERED INDEX uq_nc__core_tally__N ON core.tally(N);
GO
INSERT core.tally SELECT r.RN FROM core.rangeAB(1,1000000,1,1) AS r;
GO
/********************************* PART #2 - LCSS SETUP *********************************/
CREATE FUNCTION samd.lcssApprox8K
(
@s1 VARCHAR(8000),
@s2 VARCHAR(8000),
@high BIGINT,
@gap BIGINT
)
RETURNS TABLE WITH SCHEMABINDING AS RETURN
SELECT
TX = b.TX,
S1 = b.S1,
S2 = b.S2,
L1 = b.L1,
L2 = b.L2,
BaseDist = b.D,
BIndex = B.I,
S1Index = f.P,
S2Index = f.Ix,
itemLen = f.L,
item = f.I,
SimMin = CAST(1.*f.L/b.L2 AS DECIMAL(6,4)), -- !!! add SUM OVER for ties
SimMax = b.MS
FROM samd.bernie8K(@s1,@s2) AS b
OUTER APPLY
(
SELECT TOP (1)
ng.position,i.Ix,n1.Op,ng.token
FROM core.rangeAB(1,@high,@gap,1) AS r -- 1-@high/@gap
CROSS APPLY (VALUES(ISNULL(NULLIF(@Gap*(r.Op-1),0),1))) AS n1(Op) -- FinOp for r.N1
CROSS APPLY samd.ngrams8K(b.S1,n1.Op) AS ng -- n1.Op > NGrams8K
CROSS APPLY (VALUES(CHARINDEX(ng.token,b.S2))) AS i(Ix) -- ng.token.pos > b.S2
WHERE r.OP <= @high AND i.ix > 0
ORDER BY r.RN, ng.position -- NOTE THE 2-Dimensional Virtual Index leveraging B-GR & FinOps
) AS f(P,Ix,L,I);
GO
IF OBJECT_ID('samd.lcssWindowAB', 'IF') IS NOT NULL DROP FUNCTION samd.lcssWindowAB;
GO
CREATE FUNCTION samd.lcssWindowAB
(
@S1 VARCHAR(8000),
@S2 VARCHAR(8000),
@Window INT,
@NoDupes BIT
)
RETURNS TABLE WITH SCHEMABINDING AS RETURN
/*****************************************************************************************
[Purpose]:
Calculates the longest common substring between two varchar(n) strings up to 8000
characters each.
[Author]:
Alan Burstein
[Compatibility]:
SQL Server 2005+
[Syntax]:
--===== Autonomous
SELECT f.*
FROM samd.lcssWindowAB(@s1,@s2,@window,@noDupes) AS f
[Parameters]:
[Returns]:
[Dependencies]:
NA
[Developer Notes]:
0. @window must be 2 or higher
1. Optimal performance gains will be seen on longer strings. All Longest Common Substring
functions I have seen in SQL Server begin to choke at 500-1000. Set based Brute force
solutions that use a tally table are very fast for up to 1000 characters but begin to
slow dramatically after.
With N as the length of a string, The number of substrings is: N(N+1)/2
For 1,000 character string: 1000(1000+1)/2 = 500,500 substrings
For 2,000 characters: 2000(2000+1)/2 = 2,001,000 substrings
2. Requires a materialized tally table beginning with 1 containing at least 8000 numbers;
as written, this function will slow to a crawl using a cte tally table. This is due to
the WHERE x.n BETWEEN 2 AND 10 clause. A CTE tally table will struggle with this but a
correctly indexed materialized tally table will not.
For optimal performance your tally table should have a unique nonclustered index.
THE DDL TO BUILD THE REQUIRED TALLY TABLE IS BELOW.
3. Performance optimizations:
3.1. The first major optimization is that the *shorter* of the two strings is broken up
into substrings which are then searched for in the larger string using CHARINDEX.
This reduces the number of substrings generated by:
abs(len(@s1)-len(@s2)) * (abs(len(@s1)-len(@s2)) + 1) / 2
For example, if one is 20 characters longer than the other, 210 fewer substrings
will be evaluated; for 100 it's 5,050 fewer substrings, etc.
3.2. The second optimization is a technique I developed that I call "windowing". I use
a @window parameter to break up the search specific windows for the presense of a
matching substring. 1-10 legnth substrings in the smaller string are searched for
in the longer string. After that, only tokens with sizes evenly divisible by the
@window parameter are evaluated. For example, say the short string length is 100
and I set @window 20. All tokens sized 1-10 are searched for, the 20-grams, then
40, 60... 100. This reduces the number of substrings from 5,050 to somewhere
beween 480 & 500 (depending on the size of the longest common substring.)
3.3 Used this logic on 20190702 to get a FORWARD scan (instead of BACKWARD) on
dbo.tally AS p. It worked but there were no performance gains (serial got worse.)
SELECT TOP (1) WITH TIES p.N, Op.N, ng.Token
FROM samd.bernie8k(@s1,@s2) AS b
CROSS JOIN dbo.tally AS l
CROSS JOIN dbo.tally AS p
CROSS APPLY (VALUES(IIF(LEN(b.S1)>@window, @window+(b.L1/@window)-1,b.L1))) AS f(N)
CROSS APPLY dbo.O(1,f.N,l.N+1) AS o
CROSS APPLY (VALUES(IIF(o.Op<@window, o.Op+1, @window*(o.Op+2-@window)))) AS Op(N)
CROSS APPLY (VALUES(SUBSTRING(b.S1,p.N,Op.N))) AS ng(Token)
WHERE l.N < f.N --<< create "window-sized" tokens (no OP here)
AND (p.N<=b.L1 AND Op.N<=b.L1) -- all substrings (replace l.N with Op.N)
AND b.L1-p.N-(Op.N-1)>=0 -- Filter invalid tokens (replace l.N with Op.N)
AND CHARINDEX(ng.Token,b.S2)>0 -- Filter tokens that don't exist in b.S2
ORDER BY l.N -- Sort Key
4. The window parameter is for optimization only! It does not affect the final result set
in any way. I strongly suggest that testing the function using different window sizes
for different scenarios; the optimal size will vary. I have seen queries execute 3-10
faster when changing the window size. Start with 100, then try windows sizes of
20, 200, 300, 1000...
5. This function sees a performance gain of 10-30% with a parallel execution plan on my
system (8 CPU.)
Required Tally Table DDL (this will build exactly 8000 rows):
------------------------------------------------------------------------------------------
-- (1) Create tally table
IF OBJECT_ID('dbo.tally') IS NOT NULL DROP TABLE dbo.tally;
CREATE TABLE dbo.tally (N int not null);
-- (2) Add numbers to the tally table
WITH DummyRows(V) AS (
SELECT 1 FROM (VALUES -- 100 Dummy Rows
($),($),($),($),($),($),($),($),($),($),($),($),($),($),($),($),($),($),($),($),
($),($),($),($),($),($),($),($),($),($),($),($),($),($),($),($),($),($),($),($)) t(N))
--INSERT dbo.tally
SELECT TOP (8000) ROW_NUMBER() OVER (ORDER BY (SELECT 1))
FROM DummyRows a CROSS JOIN DummyRows b CROSS JOIN DummyRows c;
-- (3) Required constraints (and indexes) for performance
ALTER TABLE dbo.tally ADD CONSTRAINT pk_cl_tally PRIMARY KEY CLUSTERED(N)
WITH FILLFACTOR = 100;
ALTER TABLE dbo.tally ADD CONSTRAINT uq_nc_tally UNIQUE NONCLUSTERED(N);
GO
[Examples]:
SELECT f.* FROM samd.lcssWindowAB('abcxxx', 'yyyabczzz', 2,1) AS f;
SELECT f.* FROM samd.lcssWindowAB('123xxx', '!!123!!xxx!!', 2,1) AS f;
[Revision History]:
-----------------------------------------------------------------------------------------
20171126 - Initial Development - Developed by Alan Burstein
20171127 - updated to return unigrams when longest common substring is 1;
updated to use a materialized tally table; - Alan Burstein
20190103 - Finished complete re-write - Alan Burstein
20190630 - Removed @min (not used); - Alan Burstein
*****************************************************************************************/
SELECT TOP (1) WITH TIES
TX = b.TX,
S1 = b.S1,
S2 = b.S2,
L1 = b.L1,
L2 = b.L2,
BaseDist = b.D,
BIndex = b.I,
S1Index = lcss.ii,
S2Index = CHARINDEX(lcss.item,b.s2),
itemLen = lcss.ln+lcss.ad,
item = lcss.item,
SimMin = CAST(1.*(lcss.ln+lcss.ad)/b.L2 AS DECIMAL(6,4)), -- !!! add SUM OVER for ties
simMax = b.MS
FROM samd.bernie8k(@s1,@s2) AS b
CROSS APPLY
(
SELECT itemLen = gs.itemLen,
itemIndex = MIN(gs.pos) OVER (PARTITION BY gs.Grouper),
lenPlus = gs.pos-MIN(gs.pos) OVER (PARTITION BY gs.Grouper),
item = SUBSTRING(b.s1,MIN(gs.pos) OVER (PARTITION BY gs.Grouper),
gs.itemLen+gs.pos-MIN(gs.pos) OVER (PARTITION BY gs.Grouper))
FROM
(
SELECT grouper = ls.Position - ROW_NUMBER() OVER (ORDER BY ls.Position),
ls.Position, ls.ItemLen, ls.Token
FROM samd.bernie8K(@s1,@s2) AS b -- bernie metrics
CROSS APPLY
(
SELECT TOP (1) WITH TIES p.N, l.N, ng.Token -- TOP (1) to get the "longest" (including ties);
FROM core.tally AS l -- all substring lengths of S1
CROSS JOIN core.tally AS p -- all positions within s.s1
CROSS APPLY (VALUES(SUBSTRING(b.S1,p.N,l.N))) AS ng(Token) -- N-Gram function
WHERE (p.N<=b.L1 AND l.N<=b.L1) -- all substrings
AND b.L1-p.N-(l.N-1)>=0 -- Filter invalid tokens
AND CHARINDEX(ng.Token,b.S2)>0 -- Filter tokens that don't exist in b.S2
ORDER BY l.N DESC
) AS ls(Position,ItemLen,Token)
) AS gs(Grouper,Pos,ItemLen,Item)
) AS lcss(ln,ii,ad,item)
WHERE CHARINDEX(lcss.item,b.s2) > 0 -- string exists in both strings?
ORDER BY lcss.ln DESC, lcss.ad DESC,
ROW_NUMBER() OVER (PARTITION BY lcss.item ORDER BY (SELECT 1))*@noDupes;
-- Fix: (1) Refactor with DESC sort with finite Ops or Infinite Ops
-- (2) use gap logic to eliminate l.N % @window
GO
/**************************** PART #3 - Examples ****************************/;
DECLARE @s1 VARCHAR(8000) = '???ABC123YXZPDQ!!!!!!0000ABC123YXZPDQ',
@s2 VARCHAR(8000) = 'PDQ####ABC123YXZPD???????$$$ABC!!!$$$ABC123YXZPDQ!',
@high INT = 38, -- Length of the longest two strings
@p INT = 1, -- precision
@window INT = 5, -- Window Reduction
@gap INT = 1; -- Gap Reduction
-- 3.1. samd.lcssApprox8K: EXACT (@gap=1, PURE brute force)
SELECT a.S1, a.S2, a.L1, a.L2, a.BaseDist, a.BIndex, a.S1Index, a.S2Index, a.itemLen,
a.item, a.SimMin, a.SimMax, Accuracy = CONCAT(a.itemLen,'-',a.itemLen+@gap-1)
FROM samd.lcssApprox8K(@s1,@s2,@high,@gap) AS a;
-- 3.2. samd.lcssWindowAB: EXACT
SELECT a.*, Accuracy = 'Always Exact' FROM samd.lcssWindowAB(@s1,@s2,@window,1) AS a;
-- APPROXIMATIONS
BEGIN
SET @gap = 2
SELECT a.S1, a.S2, a.L1, a.L2, a.BaseDist, a.BIndex, a.S1Index, a.S2Index, a.itemLen,
a.item, a.SimMin, a.SimMax, Accuracy = CONCAT(a.itemLen,'-',a.itemLen+@gap-1)
FROM samd.lcssApprox8K(@s1,@s2,@high,@gap) AS a;
SET @gap = 3
SELECT a.S1, a.S2, a.L1, a.L2, a.BaseDist, a.BIndex, a.S1Index, a.S2Index, a.itemLen,
a.item, a.SimMin, a.SimMax, Accuracy = CONCAT(a.itemLen,'-',a.itemLen+@gap-1)
FROM samd.lcssApprox8K(@s1,@s2,@high,@gap) AS a;
SET @gap = 6
SELECT a.S1, a.S2, a.L1, a.L2, a.BaseDist, a.BIndex, a.S1Index, a.S2Index, a.itemLen,
a.item, a.SimMin, a.SimMax, Accuracy = CONCAT(a.itemLen,'-',a.itemLen+@gap-1)
FROM samd.lcssApprox8K(@s1,@s2,@high,@gap) AS a;
END
GO
/**************************** PART #4 - PERFORMANCE TESTING ****************************/;
/* Below we're using Approximations to reduce the search space and opperations WHILE STILL
returning a correct, deterministic result between two 8K strings in 0.00 seconds */;
SET NOCOUNT ON;
BEGIN
SET STATISTICS TIME, IO ON;
DECLARE @s1 VARCHAR(8000) = REPLICATE('!',11)+REPLICATE('Blah...',161)+REPLICATE('!',6860),
@s2 VARCHAR(8000) = REPLICATE('?',34)+REPLICATE('Blah...',162)+REPLICATE('?',6831),
@gap1 INT = 800,
@high INT = 1200, -- CHEATER PARAM
@p INT = 1; -- precision
DECLARE @Fn1 VARCHAR(50) = CHAR(10)+'samd.lcssApprox8K, No Ties - ',
@Fn2 VARCHAR(50) = CHAR(10)+'samd.lcssWindow8K, No Ties - ',
@br VARCHAR(95) = CHAR(10)+REPLICATE('-',90),
@br2 VARCHAR(95) = REPLICATE('-',30);
PRINT @Fn1+CONCAT('Serial(g=',@gap1,',h=',@high,')'+@br);
SELECT LCSS_GapReduced.*
FROM
(
SELECT a.L1, a.L2, a.S1Index, a.S2Index, p.ItemLen, p.Item--, a.SimMax
FROM samd.lcssApprox8K(@s1,@s2,@high,@gap1) AS a --Approx #1
CROSS APPLY (VALUES(a.ItemLen,
IIF(@gap1<@high,@high,a.ItemLen+@gap1-1))) AS tp(L,H) --Tuning Arg #1
CROSS APPLY (VALUES(ISNULL(NULLIF((tp.H-tp.L)/10,0),1))) AS r(G) -- Gap Reducer
CROSS APPLY samd.lcssApprox8K(
SUBSTRING(a.S1,a.S1Index,tp.H),
SUBSTRING(a.S2,a.S2Index,tp.H),tp.H,r.G-1) AS a2
CROSS APPLY (VALUES(a2.itemLen+r.G-1)) AS f2(H)
CROSS APPLY samd.lcssApprox8K(
SUBSTRING(a2.S1,a2.S1Index,f2.H),
SUBSTRING(a2.S2,a2.S2Index,f2.H),f2.H,@p) AS p -- Precision (@p=1=Exact)
) AS LCSS_GapReduced
OPTION(MAXDOP 1); --OPTION(QUERYTRACEON 8649); << No benefit
PRINT @Fn2+CONCAT('Serial(g=',@gap1,',h=',@high,')'+@br);
SELECT LCSS_IslandReduced.*
FROM
(
SELECT a.L1, a.L2, a.S1Index, a.S2Index, lcss.ItemLen, lcss.Item--, a.SimMax
FROM samd.lcssApprox8K(@s1,@s2,@high,@gap1) AS a -- Approx #1
CROSS APPLY (VALUES(a.ItemLen,
IIF(@gap1<@high,@high,a.ItemLen+@gap1-1))) AS tp(L,H) -- Tuning Prm #1
CROSS APPLY (VALUES(ISNULL(NULLIF((tp.H-tp.L)/10,0),1))) AS r(G) -- Gap Reducer
CROSS APPLY samd.lcssApprox8K(
SUBSTRING(a.S1,a.S1Index,tp.H),
SUBSTRING(a.S2,a.S2Index,tp.H),tp.H,r.G-1) AS a2
CROSS APPLY (VALUES(a2.itemLen+r.G-1)) AS f2(H) -- Approx #2
CROSS APPLY samd.lcssWindowAB(a2.S1,a2.S2,@high,1) AS lcss -- Exact Results
) AS LCSS_IslandReduced
OPTION(MAXDOP 1); --OPTION(QUERYTRACEON 8649); << No benefit
SET STATISTICS TIME, IO OFF;
END;
GO
/**************************** PART #5 - FINAL TEST RESULTS ****************************/;
/*
samd.lcssApprox8K, No Ties - Serial(g=800,h=1200)
------------------------------------------------------------------------------------------
SQL Server Execution Times: CPU time = 0 ms, elapsed time = 6 ms.
samd.lcssWindow8K, No Ties - Serial(g=800,h=1200)
------------------------------------------------------------------------------------------
Table 'Worktable'. Scan count 4, logical reads 2789
Table 'tally'. Scan count 2, logical reads 8...
SQL Server Execution Times: CPU time = 1593 ms, elapsed time = 1587 ms.
Completion time: 2020-07-31T13:32:03.9359718-05:00
*/;
GO
/*************************** PART #6- TEST WITH OTHER PARAMS ***************************/;
-- TEST #1 -------------------------------------------------------------------------------
/*****************************************************************************************
@s1 VARCHAR(8000) = REPLICATE('!',11)+REPLICATE('Blah...',161)+REPLICATE('!',6830),
@s2 VARCHAR(8000) = REPLICATE('?',34)+REPLICATE('Blah...',162)+REPLICATE('?',6830),
@gap1 INT = 100,
@gap2 INT = 1000,
@high INT = 3000
------------------------------ NO TIES ------------------------------
------------------------------------------------------------------------------------------
samd.lcssApprox8K - Serial(g=100,h=3000)
----------------------------------------------------------------------------------------
SQL Server Execution Times: CPU time = 9547 ms, elapsed time = 9564 ms.
samd.lcssApprox8K - Parallel(@gap=100,h=3000)
----------------------------------------------------------------------------------------
SQL Server Execution Times: CPU time = 19797 ms, elapsed time = 3099 ms.
samd.lcssApprox8K - Parallel(@gap=1000,h=3000)
----------------------------------------------------------------------------------------
SQL Server Execution Times: CPU time = 500 ms, elapsed time = 573 ms.
*****************************************************************************************/;
-- TEST #2 -------------------------------------------------------------------------------
/*****************************************************************************************
@s1 VARCHAR(8000) = REPLICATE('!',11)+REPLICATE('Blah...',161)+REPLICATE('!',6830),
@s2 VARCHAR(8000) = REPLICATE('?',34)+REPLICATE('Blah...',162)+REPLICATE('?',6830),
@gap1 INT = 100,
@gap2 INT = 1000,
@high INT = 3000
------------------------------ NO TIES ------------------------------
samd.lcssApprox8K, No Ties - Serial(g=50,h=3000)
------------------------------------------------------------------------------------------
SQL Server Execution Times: CPU time = 21844 ms, elapsed time = 21863 ms.
samd.lcssApprox8K, No Ties - Parallel(@gap=50,h=3000)
------------------------------------------------------------------------------------------
SQL Server Execution Times: CPU time = 41531 ms, elapsed time = 5725 ms.
samd.lcssApprox8K, No Ties - Parallel(@gap=500,h=3000)
------------------------------------------------------------------------------------------
SQL Server Execution Times:
CPU time = 2250 ms, elapsed time = 819 ms.
------------------------------ TIES ------------------------------
samd.lcssApprox8K, Ties - Serial(g=50,h=3000)
------------------------------------------------------------------------------------------
Table 'Worktable'. Scan count 0, logical reads 441291...
SQL Server Execution Times: CPU time = 22313 ms, elapsed time = 22466 ms.
samd.lcssApprox8K, Ties - Parallel(@gap=50,h=3000)
------------------------------------------------------------------------------------------
SQL Server Execution Times:
CPU time = 55580 ms, elapsed time = 7051 ms.
samd.lcssApprox8K, Ties - Parallel(@gap=500,h=3000)
------------------------------------------------------------------------------------------
SQL Server Execution Times: CPU time = 5827 ms, elapsed time = 1103 ms.
Completion time: 2020-07-30T12:29:22.6204050-05:00
*****************************************************************************************/;
-- TEST #3 -------------------------------------------------------------------------------
/*****************************************************************************************
@s1 VARCHAR(8000) = REPLICATE('!',11)+REPLICATE('Blah...',161)+REPLICATE('!',6830),
@s2 VARCHAR(8000) = REPLICATE('?',34)+REPLICATE('Blah...',162)+REPLICATE('?',6830),
@gap1 INT = 800,
@gap2 INT = 1100,
@high INT = 1200;
------------------------------ NO TIES ------------------------------
samd.lcssApprox8K, No Ties - Serial(g=800,h=1200)
------------------------------------------------------------------------------------------
SQL Server Execution Times: CPU time = 0 ms, elapsed time = 10 ms.
samd.lcssApprox8K, No Ties - Parallel(g=800,h=1200)
------------------------------------------------------------------------------------------
SQL Server Execution Times: CPU time = 0 ms, elapsed time = 84 ms.
samd.lcssApprox8K, No Ties - Parallel(g=1100,h=1200)
------------------------------------------------------------------------------------------
SQL Server Execution Times: CPU time = 0 ms, elapsed time = 99 ms.
------------------------------ TIES ------------------------------
samd.lcssApprox8K, Ties - Serial(g=800,h=1200)
------------------------------------------------------------------------------------------
SQL Server Execution Times: CPU time = 0 ms, elapsed time = 94 ms.
Table 'Worktable'. Scan count 0, logical reads 27...
samd.lcssApprox8K, Ties - Parallel(@gap=100,h=3000)
------------------------------------------------------------------------------------------
SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms.
samd.lcssApprox8K, No Ties - Serial(g=800,h=1200)
------------------------------------------------------------------------------------------
SQL Server Execution Times: CPU time = 220 ms, elapsed time = 110 ms.
samd.lcssApprox8K, Ties - Parallel(g=1100,h=1200)
------------------------------------------------------------------------------------------
SQL Server Execution Times: CPU time = 1187 ms, elapsed time = 738 ms.
-
Completion time: 2020-07-30T12:59:53.0265358-05:00
*****************************************************************************************/;"I cant stress enough the importance of switching from a sequential files mindset to set-based thinking. After you make the switch, you can spend your time tuning and optimizing your queries instead of maintaining lengthy, poor-performing code."-- Itzik Ben-Gan 2001
-
This is a most interesting topic, and I just have to toss a hat in the ring. Decided to try to make the code as simple as possible and see what comes out of it. I decided to try and generate all the possible sub-strings of the shorter string that are at least 2 characters long, and then find the longest one of those that appears in the longer string. I then chose for my string values, sections of the Aaron Copland text that appeared in one of the above posts. The result on my Core i3 Windows 10 Pro laptop (Dell) was completed in 21 seconds. It was an 18 character substring that was in common between both strings and was the longest such sub-string. Here's the code:
DECLARE @String1 AS varchar(8000) = 'When Aaron Copland boarded a ship for Paris in June 1921, a few months short of his twenty-first birthday, he already had a good musical training thanks to his conservative but thorough American teacher, Rubin Goldmark. He carried in his luggage the manuscript of what was to be his first published piece, the "scherzo humoristique" The Cat and the Mouse, which played with the progressive techniques of whole-tone scale and black-note versus white-note alternation. Nevertheless, it was in France, under the encouragement of his teacher Nadia Boulanger, that Copland produced his first large-scale works: the ballet Grohg (now known principally through the excerpt Dance Symphony, and the Symphony for Organ and Orchestra, with which he introduced himself to American audiences.
Grohg and the Symphony for Organ and Orchestra were written in a style suggested by European modernism (Copland confessed that Grohg was written under the spell of Florent Schmitt''s La Tragédie de Salomé). In the works that followed Copland sought to discover a particularly American style, an interest that continued for the remainder of his career as a composer. Yet Copland did not seek to establish a single "American" style, nor did he ask that an American work contain particular references to American idioms: it was of Roger Sessions''s 1927-30Sonata for Piano, a very un-Coplandish work with no audible Americanisms, that he said "To know [this] work well is to have the firm conviction that Sessions has presented us with a cornerstone upon which to base an American music."',
@String2 AS varchar(8000) = 'At first Copland sought for Americanism in the influence of jazz—"jazz" as he had played it (see letter from Copland to Nadia Boulanger, August 1924) as part of a hotel orchestra in the summer of 1924. The Concerto for Piano and Orchestra, the Music for the Theatre, and the Two Pieces for Violin and Piano contrast jazzy portions with slow introspective sections that use bluesy lines over atmospheric ostinati—the latter sometimes suggesting Charles Ives''s song "The Housatonic at Stockbridge," a work Copland could not have known during the 1920s.
No later Copland works rely on jazz textures as these works do, though many are infused with rhythms suggesting jazz. (Copland''s one mature work with a seeming jazz reference in its title, the 1949 Four Piano Blues, uses "blues" to suggest an informal music of American sound, his equivalent of intermezzior impromptus.)';
WITH N1(N) AS (
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
),
N8 AS (
SELECT TOP (8000) ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS RN
FROM N1 AS A, N1 AS B, N1 AS C, N1 AS D
),
STRINGS AS (
SELECT
CASE
WHEN DATALENGTH(@String1) > DATALENGTH(@String2) THEN @String2
ELSE @String1
END AS SHORTER_STRING,
CASE
WHEN DATALENGTH(@String1) > DATALENGTH(@String2) THEN @String1
ELSE @String2
END AS LONGER_STRING
),
SUBSTRINGS_SHORTER AS (
SELECT SUBSTRING(S.SHORTER_STRING, N81.RN, N82.RN) AS SUB_STRING_SHORT
FROM STRINGS AS S
CROSS APPLY N8 AS N81
CROSS APPLY N8 AS N82
WHEREN82.RN > 1
AND N82.RN <= DATALENGTH(S.SHORTER_STRING)
)
SELECT TOP (1) WITH TIES
SS.SUB_STRING_SHORT,
DATALENGTH(SS.SUB_STRING_SHORT) AS DLEN
FROM STRINGS AS S
INNER JOIN SUBSTRINGS_SHORTER AS SS
ON S.LONGER_STRING LIKE '%' + SS.SUB_STRING_SHORT + '%'
ORDER BY
DATALENGTH(SS.SUB_STRING_SHORT) DESC;Any and all feedback appreciated. The execution plan file was renamed to .txt from .sqlplan before uploading. EDIT: And now I need to include it as text instead of uploading it... here it is...
<?xml version="1.0" encoding="utf-16"?>
<ShowPlanXML xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema" Version="1.6" Build="14.0.2027.2" xmlns="http://schemas.microsoft.com/sqlserver/2004/07/showplan">
<BatchSequence>
<Batch>
<Statements>
<StmtSimple StatementCompId="2" StatementEstRows="946465" StatementId="1" StatementOptmLevel="FULL" CardinalityEstimationModelVersion="140" StatementSubTreeCost="162.489" StatementText="WITH N1(N) AS ( SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 ), N8 AS ( SELECT TOP (8000) ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS RN FROM N1 AS A, N1 AS B, N1 AS C, N1 AS D ), STRINGS AS ( SELECT CASE WHEN DATALENGTH(@String1) > DATALENGTH(@String2) THEN @String2 ELSE @String1 END AS SHORTER_STRING, CASE WHEN DATALENGTH(@String1) > DATALENGTH(@String2) THEN @String1 ELSE @String2 END AS LONGER_STRING ), SUBSTRINGS_SHORTER AS ( SELECT SUBSTRING(S.SHORTER_STRING, N81.RN, N82.RN) AS SUB_STRING_SHORT FROM STRINGS AS S CROSS APPLY N8 AS N81 CROSS APPLY N8 AS N82 WHEREN82.RN > 1 AND N82.RN <= DATALENGTH(S.SHORTER_STRING) ) SELECT TOP (1) WITH TIES SS.SUB_STRING_SHORT, DATALENGTH(SS.SUB_STRING_SHORT) AS DLEN FROM STRINGS AS S INNER JOIN SUBSTRINGS_SHORTER AS SS ON S.LONGER_STRING LIKE '%' + SS.SUB_STRING_SHORT + '%' ORDER BY DATALENGTH(SS.SUB_STRING_SHORT) DESC" StatementType="SELECT" QueryHash="0x2205FF12EF0EA35D" QueryPlanHash="0x96BAC8ADF0A2C272" RetrievedFromCache="true" SecurityPolicyApplied="false">
<StatementSetOptions ANSI_NULLS="true" ANSI_PADDING="true" ANSI_WARNINGS="true" ARITHABORT="true" CONCAT_NULL_YIELDS_NULL="true" NUMERIC_ROUNDABORT="false" QUOTED_IDENTIFIER="true" />
<QueryPlan DegreeOfParallelism="4" MemoryGrant="80128" CachedPlanSize="56" CompileTime="22" CompileCPU="22" CompileMemory="1592">
<ThreadStat Branches="2" UsedThreads="5">
<ThreadReservation NodeId="0" ReservedThreads="8" />
</ThreadStat>
<MemoryGrantInfo SerialRequiredMemory="512" SerialDesiredMemory="78112" RequiredMemory="2528" DesiredMemory="80128" RequestedMemory="80128" GrantWaitTime="0" GrantedMemory="80128" MaxUsedMemory="80128" MaxQueryMemory="692464" />
<OptimizerHardwareDependentProperties EstimatedAvailableMemoryGrant="416836" EstimatedPagesCached="104209" EstimatedAvailableDegreeOfParallelism="2" MaxCompileMemory="12576" />
<WaitStats>
<Wait WaitType="IO_COMPLETION" WaitTimeMs="14" WaitCount="50" />
<Wait WaitType="PAGEIOLATCH_UP" WaitTimeMs="88" WaitCount="7" />
</WaitStats>
<QueryTimeStats CpuTime="70652" ElapsedTime="18603" />
<RelOp AvgRowSize="4015" EstimateCPU="0.0946465" EstimateIO="0" EstimateRebinds="0" EstimateRewinds="0" EstimatedExecutionMode="Row" EstimateRows="946465" LogicalOp="Compute Scalar" NodeId="0" Parallel="false" PhysicalOp="Compute Scalar" EstimatedTotalSubtreeCost="162.489">
<OutputList>
<ColumnReference Column="Expr1098" />
<ColumnReference Column="Expr1099" />
</OutputList>
<ComputeScalar>
<DefinedValues>
<DefinedValue>
<ColumnReference Column="Expr1098" />
<ScalarOperator ScalarString="substring(CASE WHEN datalength([@String1])>datalength([@String2]) THEN [@String2] ELSE [@String1] END,CONVERT_IMPLICIT(int,[Expr1050],0),CONVERT_IMPLICIT(int,[Expr1097],0))">
<Intrinsic FunctionName="substring">
<ScalarOperator>
<IF>
<Condition>
<ScalarOperator>
<Compare CompareOp="GT">
<ScalarOperator>
<Intrinsic FunctionName="datalength">
<ScalarOperator>
<Identifier>
<ColumnReference Column="@String1" />
</Identifier>
</ScalarOperator>
</Intrinsic>
</ScalarOperator>
<ScalarOperator>
<Intrinsic FunctionName="datalength">
<ScalarOperator>
<Identifier>
<ColumnReference Column="@String2" />
</Identifier>
</ScalarOperator>
</Intrinsic>
</ScalarOperator>
</Compare>
</ScalarOperator>
</Condition>
<Then>
<ScalarOperator>
<Identifier>
<ColumnReference Column="@String2" />
</Identifier>
</ScalarOperator>
</Then>
<Else>
<ScalarOperator>
<Identifier>
<ColumnReference Column="@String1" />
</Identifier>
</ScalarOperator>
</Else>
</IF>
</ScalarOperator>
<ScalarOperator>
<Convert DataType="int" Style="0" Implicit="true">
<ScalarOperator>
<Identifier>
<ColumnReference Column="Expr1050" />
</Identifier>
</ScalarOperator>
</Convert>
</ScalarOperator>
<ScalarOperator>
<Convert DataType="int" Style="0" Implicit="true">
<ScalarOperator>
<Identifier>
<ColumnReference Column="Expr1097" />
</Identifier>
</ScalarOperator>
</Convert>
</ScalarOperator>
</Intrinsic>
</ScalarOperator>
</DefinedValue>
</DefinedValues>
<RelOp AvgRowSize="27" EstimateCPU="0.0946465" EstimateIO="0" EstimateRebinds="0" EstimateRewinds="0" EstimatedExecutionMode="Row" EstimateRows="946465" LogicalOp="Top" NodeId="1" Parallel="false" PhysicalOp="Top" EstimatedTotalSubtreeCost="162.394">
<OutputList>
<ColumnReference Column="Expr1050" />
<ColumnReference Column="Expr1097" />
<ColumnReference Column="Expr1099" />
</OutputList>
<RunTimeInformation>
<RunTimeCountersPerThread Thread="0" ActualRows="1" Batches="0" ActualEndOfScans="1" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="18598" ActualCPUms="0" />
</RunTimeInformation>
<Top RowCount="false" IsPercent="false" WithTies="true">
<TieColumns>
<ColumnReference Column="Expr1099" />
</TieColumns>
<TopExpression>
<ScalarOperator ScalarString="(1)">
<Const ConstValue="(1)" />
</ScalarOperator>
</TopExpression>
<RelOp AvgRowSize="27" EstimateCPU="6.62702" EstimateIO="0" EstimateRebinds="0" EstimateRewinds="0" EstimatedExecutionMode="Row" EstimateRows="946465" LogicalOp="Gather Streams" NodeId="2" Parallel="true" PhysicalOp="Parallelism" EstimatedTotalSubtreeCost="162.299">
<OutputList>
<ColumnReference Column="Expr1050" />
<ColumnReference Column="Expr1097" />
<ColumnReference Column="Expr1099" />
</OutputList>
<RunTimeInformation>
<RunTimeCountersPerThread Thread="0" ActualRows="2" Batches="0" ActualEndOfScans="0" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="18598" ActualCPUms="0" />
</RunTimeInformation>
<Parallelism>
<OrderBy>
<OrderByColumn Ascending="false">
<ColumnReference Column="Expr1099" />
</OrderByColumn>
</OrderBy>
<RelOp AvgRowSize="27" EstimateCPU="43.1217" EstimateIO="0.00563063" EstimateRebinds="0" EstimateRewinds="0" EstimatedExecutionMode="Row" EstimateRows="946465" LogicalOp="Sort" NodeId="3" Parallel="true" PhysicalOp="Sort" EstimatedTotalSubtreeCost="155.672">
<OutputList>
<ColumnReference Column="Expr1050" />
<ColumnReference Column="Expr1097" />
<ColumnReference Column="Expr1099" />
</OutputList>
<Warnings>
<SpillToTempDb SpillLevel="1" SpilledThreadCount="4" />
<SortSpillDetails GrantedMemoryKb="79648" UsedMemoryKb="79648" WritesToTempDb="20761" ReadsFromTempDb="20761" />
</Warnings>
<MemoryFractions Input="1" Output="1" />
<RunTimeInformation>
<RunTimeCountersPerThread Thread="4" ActualRebinds="1" ActualRewinds="0" ActualRows="2245" Batches="0" ActualEndOfScans="0" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="18598" ActualCPUms="17642" ActualScans="0" ActualLogicalReads="0" ActualPhysicalReads="0" ActualReadAheads="146" ActualLobLogicalReads="0" ActualLobPhysicalReads="0" ActualLobReadAheads="0" InputMemoryGrant="19912" OutputMemoryGrant="19528" UsedMemoryGrant="19912" />
<RunTimeCountersPerThread Thread="3" ActualRebinds="1" ActualRewinds="0" ActualRows="2245" Batches="0" ActualEndOfScans="0" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="18598" ActualCPUms="17872" ActualScans="0" ActualLogicalReads="0" ActualPhysicalReads="0" ActualReadAheads="101" ActualLobLogicalReads="0" ActualLobPhysicalReads="0" ActualLobReadAheads="0" InputMemoryGrant="19912" OutputMemoryGrant="19528" UsedMemoryGrant="19912" />
<RunTimeCountersPerThread Thread="2" ActualRebinds="1" ActualRewinds="0" ActualRows="2245" Batches="0" ActualEndOfScans="0" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="18599" ActualCPUms="17634" ActualScans="0" ActualLogicalReads="0" ActualPhysicalReads="0" ActualReadAheads="167" ActualLobLogicalReads="0" ActualLobPhysicalReads="0" ActualLobReadAheads="0" InputMemoryGrant="19912" OutputMemoryGrant="19528" UsedMemoryGrant="19912" />
<RunTimeCountersPerThread Thread="1" ActualRebinds="1" ActualRewinds="0" ActualRows="816" Batches="0" ActualEndOfScans="0" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="18597" ActualCPUms="17487" ActualScans="0" ActualLogicalReads="0" ActualPhysicalReads="0" ActualReadAheads="36" ActualLobLogicalReads="0" ActualLobPhysicalReads="0" ActualLobReadAheads="0" InputMemoryGrant="19912" OutputMemoryGrant="19528" UsedMemoryGrant="19912" />
<RunTimeCountersPerThread Thread="0" ActualRebinds="0" ActualRewinds="0" ActualRows="0" Batches="0" ActualEndOfScans="0" ActualExecutions="0" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" ActualScans="0" ActualLogicalReads="0" ActualPhysicalReads="0" ActualReadAheads="0" ActualLobLogicalReads="0" ActualLobPhysicalReads="0" ActualLobReadAheads="0" InputMemoryGrant="0" OutputMemoryGrant="0" UsedMemoryGrant="0" />
</RunTimeInformation>
<Sort Distinct="false">
<OrderBy>
<OrderByColumn Ascending="false">
<ColumnReference Column="Expr1099" />
</OrderByColumn>
</OrderBy>
<RelOp AvgRowSize="27" EstimateCPU="0.0473232" EstimateIO="0" EstimateRebinds="0" EstimateRewinds="0" EstimatedExecutionMode="Row" EstimateRows="946465" LogicalOp="Compute Scalar" NodeId="4" Parallel="true" PhysicalOp="Compute Scalar" EstimatedTotalSubtreeCost="112.545">
<OutputList>
<ColumnReference Column="Expr1050" />
<ColumnReference Column="Expr1097" />
<ColumnReference Column="Expr1099" />
</OutputList>
<ComputeScalar>
<DefinedValues>
<DefinedValue>
<ColumnReference Column="Expr1099" />
<ScalarOperator ScalarString="datalength(substring(CASE WHEN datalength([@String1])>datalength([@String2]) THEN [@String2] ELSE [@String1] END,CONVERT_IMPLICIT(int,[Expr1050],0),CONVERT_IMPLICIT(int,[Expr1097],0)))">
<Intrinsic FunctionName="datalength">
<ScalarOperator>
<Intrinsic FunctionName="substring">
<ScalarOperator>
<IF>
<Condition>
<ScalarOperator>
<Compare CompareOp="GT">
<ScalarOperator>
<Intrinsic FunctionName="datalength">
<ScalarOperator>
<Identifier>
<ColumnReference Column="@String1" />
</Identifier>
</ScalarOperator>
</Intrinsic>
</ScalarOperator>
<ScalarOperator>
<Intrinsic FunctionName="datalength">
<ScalarOperator>
<Identifier>
<ColumnReference Column="@String2" />
</Identifier>
</ScalarOperator>
</Intrinsic>
</ScalarOperator>
</Compare>
</ScalarOperator>
</Condition>
<Then>
<ScalarOperator>
<Identifier>
<ColumnReference Column="@String2" />
</Identifier>
</ScalarOperator>
</Then>
<Else>
<ScalarOperator>
<Identifier>
<ColumnReference Column="@String1" />
</Identifier>
</ScalarOperator>
</Else>
</IF>
</ScalarOperator>
<ScalarOperator>
<Convert DataType="int" Style="0" Implicit="true">
<ScalarOperator>
<Identifier>
<ColumnReference Column="Expr1050" />
</Identifier>
</ScalarOperator>
</Convert>
</ScalarOperator>
<ScalarOperator>
<Convert DataType="int" Style="0" Implicit="true">
<ScalarOperator>
<Identifier>
<ColumnReference Column="Expr1097" />
</Identifier>
</ScalarOperator>
</Convert>
</ScalarOperator>
</Intrinsic>
</ScalarOperator>
</Intrinsic>
</ScalarOperator>
</DefinedValue>
</DefinedValues>
<RelOp AvgRowSize="23" EstimateCPU="21.979" EstimateIO="0" EstimateRebinds="0" EstimateRewinds="0" EstimatedExecutionMode="Row" EstimateRows="946465" LogicalOp="Inner Join" NodeId="5" Parallel="true" PhysicalOp="Nested Loops" EstimatedTotalSubtreeCost="112.498">
<OutputList>
<ColumnReference Column="Expr1050" />
<ColumnReference Column="Expr1097" />
</OutputList>
<RunTimeInformation>
<RunTimeCountersPerThread Thread="4" ActualRows="1554139" Batches="0" ActualEndOfScans="1" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="16315" ActualCPUms="15509" />
<RunTimeCountersPerThread Thread="3" ActualRows="1554403" Batches="0" ActualEndOfScans="1" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="16590" ActualCPUms="15890" />
<RunTimeCountersPerThread Thread="2" ActualRows="1561825" Batches="0" ActualEndOfScans="1" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="16486" ActualCPUms="15673" />
<RunTimeCountersPerThread Thread="1" ActualRows="1553988" Batches="0" ActualEndOfScans="1" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="16544" ActualCPUms="15491" />
<RunTimeCountersPerThread Thread="0" ActualRows="0" Batches="0" ActualEndOfScans="0" ActualExecutions="0" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
</RunTimeInformation>
<NestedLoops Optimized="false">
<Predicate>
<ScalarOperator ScalarString="CASE WHEN datalength([@String1])>datalength([@String2]) THEN [@String1] ELSE [@String2] END like '%'+substring(CASE WHEN datalength([@String1])>datalength([@String2]) THEN [@String2] ELSE [@String1] END,CONVERT_IMPLICIT(int,[Expr1050],0),CONVERT_IMPLICIT(int,[Expr1097],0))+'%'">
<Intrinsic FunctionName="like">
<ScalarOperator>
<IF>
<Condition>
<ScalarOperator>
<Compare CompareOp="GT">
<ScalarOperator>
<Intrinsic FunctionName="datalength">
<ScalarOperator>
<Identifier>
<ColumnReference Column="@String1" />
</Identifier>
</ScalarOperator>
</Intrinsic>
</ScalarOperator>
<ScalarOperator>
<Intrinsic FunctionName="datalength">
<ScalarOperator>
<Identifier>
<ColumnReference Column="@String2" />
</Identifier>
</ScalarOperator>
</Intrinsic>
</ScalarOperator>
</Compare>
</ScalarOperator>
</Condition>
<Then>
<ScalarOperator>
<Identifier>
<ColumnReference Column="@String1" />
</Identifier>
</ScalarOperator>
</Then>
<Else>
<ScalarOperator>
<Identifier>
<ColumnReference Column="@String2" />
</Identifier>
</ScalarOperator>
</Else>
</IF>
</ScalarOperator>
<ScalarOperator>
<Arithmetic Operation="ADD">
<ScalarOperator>
<Arithmetic Operation="ADD">
<ScalarOperator>
<Const ConstValue="'%'" />
</ScalarOperator>
<ScalarOperator>
<Intrinsic FunctionName="substring">
<ScalarOperator>
<IF>
<Condition>
<ScalarOperator>
<Compare CompareOp="GT">
<ScalarOperator>
<Intrinsic FunctionName="datalength">
<ScalarOperator>
<Identifier>
<ColumnReference Column="@String1" />
</Identifier>
</ScalarOperator>
</Intrinsic>
</ScalarOperator>
<ScalarOperator>
<Intrinsic FunctionName="datalength">
<ScalarOperator>
<Identifier>
<ColumnReference Column="@String2" />
</Identifier>
</ScalarOperator>
</Intrinsic>
</ScalarOperator>
</Compare>
</ScalarOperator>
</Condition>
<Then>
<ScalarOperator>
<Identifier>
<ColumnReference Column="@String2" />
</Identifier>
</ScalarOperator>
</Then>
<Else>
<ScalarOperator>
<Identifier>
<ColumnReference Column="@String1" />
</Identifier>
</ScalarOperator>
</Else>
</IF>
</ScalarOperator>
<ScalarOperator>
<Convert DataType="int" Style="0" Implicit="true">
<ScalarOperator>
<Identifier>
<ColumnReference Column="Expr1050" />
</Identifier>
</ScalarOperator>
</Convert>
</ScalarOperator>
<ScalarOperator>
<Convert DataType="int" Style="0" Implicit="true">
<ScalarOperator>
<Identifier>
<ColumnReference Column="Expr1097" />
</Identifier>
</ScalarOperator>
</Convert>
</ScalarOperator>
</Intrinsic>
</ScalarOperator>
</Arithmetic>
</ScalarOperator>
<ScalarOperator>
<Const ConstValue="'%'" />
</ScalarOperator>
</Arithmetic>
</ScalarOperator>
</Intrinsic>
</ScalarOperator>
</Predicate>
<RelOp AvgRowSize="15" EstimateCPU="0.00672" EstimateIO="0" EstimateRebinds="0" EstimateRewinds="0" EstimatedExecutionMode="Row" EstimateRows="1314.53" LogicalOp="Filter" NodeId="6" Parallel="true" PhysicalOp="Filter" EstimatedTotalSubtreeCost="0.100025">
<OutputList>
<ColumnReference Column="Expr1097" />
</OutputList>
<RunTimeInformation>
<RunTimeCountersPerThread Thread="4" ActualRows="218" Batches="0" ActualEndOfScans="1" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="94" ActualCPUms="1" />
<RunTimeCountersPerThread Thread="3" ActualRows="218" Batches="0" ActualEndOfScans="1" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="205" ActualCPUms="1" />
<RunTimeCountersPerThread Thread="2" ActualRows="219" Batches="0" ActualEndOfScans="1" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="4" ActualCPUms="1" />
<RunTimeCountersPerThread Thread="1" ActualRows="218" Batches="0" ActualEndOfScans="1" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="67" ActualCPUms="1" />
<RunTimeCountersPerThread Thread="0" ActualRows="0" Batches="0" ActualEndOfScans="0" ActualExecutions="0" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
</RunTimeInformation>
<Filter StartupExpression="false">
<RelOp AvgRowSize="15" EstimateCPU="0.045696" EstimateIO="0" EstimateRebinds="0" EstimateRewinds="0" EstimatedExecutionMode="Row" EstimateRows="8000" LogicalOp="Distribute Streams" NodeId="7" Parallel="true" PhysicalOp="Parallelism" EstimatedTotalSubtreeCost="0.0933052">
<OutputList>
<ColumnReference Column="Expr1097" />
</OutputList>
<RunTimeInformation>
<RunTimeCountersPerThread Thread="4" ActualRows="2000" Batches="0" ActualEndOfScans="1" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="93" ActualCPUms="0" />
<RunTimeCountersPerThread Thread="3" ActualRows="2000" Batches="0" ActualEndOfScans="1" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="205" ActualCPUms="0" />
<RunTimeCountersPerThread Thread="2" ActualRows="2000" Batches="0" ActualEndOfScans="1" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="3" ActualCPUms="0" />
<RunTimeCountersPerThread Thread="1" ActualRows="2000" Batches="0" ActualEndOfScans="1" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="66" ActualCPUms="0" />
<RunTimeCountersPerThread Thread="0" ActualRows="0" Batches="0" ActualEndOfScans="0" ActualExecutions="0" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
</RunTimeInformation>
<Parallelism PartitioningType="RoundRobin">
<RelOp AvgRowSize="15" EstimateCPU="0.0008" EstimateIO="0" EstimateRebinds="0" EstimateRewinds="0" EstimatedExecutionMode="Row" EstimateRows="8000" LogicalOp="Top" NodeId="8" Parallel="false" PhysicalOp="Top" EstimatedTotalSubtreeCost="0.0476092">
<OutputList>
<ColumnReference Column="Expr1097" />
</OutputList>
<RunTimeInformation>
<RunTimeCountersPerThread Thread="1" ActualRows="8000" Batches="0" ActualEndOfScans="1" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="4" ActualCPUms="4" />
<RunTimeCountersPerThread Thread="0" ActualRows="0" Batches="0" ActualEndOfScans="0" ActualExecutions="0" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
</RunTimeInformation>
<Top RowCount="false" IsPercent="false" WithTies="false">
<TopExpression>
<ScalarOperator ScalarString="(8000)">
<Const ConstValue="(8000)" />
</ScalarOperator>
</TopExpression>
<RelOp AvgRowSize="15" EstimateCPU="0.0008" EstimateIO="0" EstimateRebinds="0" EstimateRewinds="0" EstimatedExecutionMode="Row" EstimateRows="8000" LogicalOp="Compute Scalar" NodeId="9" Parallel="false" PhysicalOp="Sequence Project" EstimatedTotalSubtreeCost="0.0468092">
<OutputList>
<ColumnReference Column="Expr1097" />
</OutputList>
<RunTimeInformation>
<RunTimeCountersPerThread Thread="1" ActualRows="8000" Batches="0" ActualEndOfScans="0" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="4" ActualCPUms="4" />
<RunTimeCountersPerThread Thread="0" ActualRows="0" Batches="0" ActualEndOfScans="0" ActualExecutions="0" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
</RunTimeInformation>
<SequenceProject>
<DefinedValues>
<DefinedValue>
<ColumnReference Column="Expr1097" />
<ScalarOperator ScalarString="row_number">
<Sequence FunctionName="row_number" />
</ScalarOperator>
</DefinedValue>
</DefinedValues>
<RelOp AvgRowSize="15" EstimateCPU="0.0002" EstimateIO="0" EstimateRebinds="0" EstimateRewinds="0" EstimatedExecutionMode="Row" EstimateRows="8000" LogicalOp="Segment" NodeId="10" Parallel="false" PhysicalOp="Segment" EstimatedTotalSubtreeCost="0.0461692">
<OutputList>
<ColumnReference Column="Segment1100" />
</OutputList>
<RunTimeInformation>
<RunTimeCountersPerThread Thread="1" ActualRows="8000" Batches="0" ActualEndOfScans="0" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="2" ActualCPUms="2" />
<RunTimeCountersPerThread Thread="0" ActualRows="0" Batches="0" ActualEndOfScans="0" ActualExecutions="0" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
</RunTimeInformation>
<Segment>
<GroupBy />
<SegmentColumn>
<ColumnReference Column="Segment1100" />
</SegmentColumn>
<RelOp AvgRowSize="9" EstimateCPU="0.0418" EstimateIO="0" EstimateRebinds="0" EstimateRewinds="0" EstimatedExecutionMode="Row" EstimateRows="8000" LogicalOp="Inner Join" NodeId="11" Parallel="false" PhysicalOp="Nested Loops" EstimatedTotalSubtreeCost="0.0460092">
<OutputList />
<Warnings NoJoinPredicate="true" />
<RunTimeInformation>
<RunTimeCountersPerThread Thread="1" ActualRows="8000" Batches="0" ActualEndOfScans="0" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="1" ActualCPUms="1" />
<RunTimeCountersPerThread Thread="0" ActualRows="0" Batches="0" ActualEndOfScans="0" ActualExecutions="0" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
</RunTimeInformation>
<NestedLoops Optimized="false">
<RelOp AvgRowSize="9" EstimateCPU="0.00418" EstimateIO="0" EstimateRebinds="0" EstimateRewinds="0" EstimatedExecutionMode="Row" EstimateRows="800" LogicalOp="Inner Join" NodeId="12" Parallel="false" PhysicalOp="Nested Loops" EstimatedTotalSubtreeCost="0.004568">
<OutputList />
<Warnings NoJoinPredicate="true" />
<RunTimeInformation>
<RunTimeCountersPerThread Thread="1" ActualRows="800" Batches="0" ActualEndOfScans="0" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
<RunTimeCountersPerThread Thread="0" ActualRows="0" Batches="0" ActualEndOfScans="0" ActualExecutions="0" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
</RunTimeInformation>
<NestedLoops Optimized="false">
<RelOp AvgRowSize="9" EstimateCPU="0.000418" EstimateIO="0" EstimateRebinds="0" EstimateRewinds="0" EstimatedExecutionMode="Row" EstimateRows="80" LogicalOp="Inner Join" NodeId="13" Parallel="false" PhysicalOp="Nested Loops" EstimatedTotalSubtreeCost="0.000422896">
<OutputList />
<Warnings NoJoinPredicate="true" />
<RunTimeInformation>
<RunTimeCountersPerThread Thread="1" ActualRows="80" Batches="0" ActualEndOfScans="0" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
<RunTimeCountersPerThread Thread="0" ActualRows="0" Batches="0" ActualEndOfScans="0" ActualExecutions="0" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
</RunTimeInformation>
<NestedLoops Optimized="false">
<RelOp AvgRowSize="9" EstimateCPU="1.0157E-05" EstimateIO="0" EstimateRebinds="0" EstimateRewinds="0" EstimatedExecutionMode="Row" EstimateRows="8" LogicalOp="Constant Scan" NodeId="14" Parallel="false" PhysicalOp="Constant Scan" EstimatedTotalSubtreeCost="8.157E-06">
<OutputList />
<RunTimeInformation>
<RunTimeCountersPerThread Thread="1" ActualRows="8" Batches="0" ActualEndOfScans="0" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
<RunTimeCountersPerThread Thread="0" ActualRows="0" Batches="0" ActualEndOfScans="0" ActualExecutions="0" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
</RunTimeInformation>
<ConstantScan />
</RelOp>
<RelOp AvgRowSize="9" EstimateCPU="1.0157E-05" EstimateIO="0" EstimateRebinds="0" EstimateRewinds="7.2" EstimatedExecutionMode="Row" EstimateRows="10" LogicalOp="Constant Scan" NodeId="15" Parallel="false" PhysicalOp="Constant Scan" EstimatedTotalSubtreeCost="8.2157E-05">
<OutputList />
<RunTimeInformation>
<RunTimeCountersPerThread Thread="1" ActualRows="80" Batches="0" ActualEndOfScans="7" ActualExecutions="8" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
<RunTimeCountersPerThread Thread="0" ActualRows="0" Batches="0" ActualEndOfScans="0" ActualExecutions="0" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
</RunTimeInformation>
<ConstantScan />
</RelOp>
</NestedLoops>
</RelOp>
<RelOp AvgRowSize="9" EstimateCPU="1.0157E-05" EstimateIO="0" EstimateRebinds="0" EstimateRewinds="79.2" EstimatedExecutionMode="Row" EstimateRows="10" LogicalOp="Constant Scan" NodeId="16" Parallel="false" PhysicalOp="Constant Scan" EstimatedTotalSubtreeCost="0.000802157">
<OutputList />
<RunTimeInformation>
<RunTimeCountersPerThread Thread="1" ActualRows="800" Batches="0" ActualEndOfScans="79" ActualExecutions="80" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
<RunTimeCountersPerThread Thread="0" ActualRows="0" Batches="0" ActualEndOfScans="0" ActualExecutions="0" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
</RunTimeInformation>
<ConstantScan />
</RelOp>
</NestedLoops>
</RelOp>
<RelOp AvgRowSize="9" EstimateCPU="1.0157E-05" EstimateIO="0" EstimateRebinds="0" EstimateRewinds="799.2" EstimatedExecutionMode="Row" EstimateRows="10" LogicalOp="Constant Scan" NodeId="17" Parallel="false" PhysicalOp="Constant Scan" EstimatedTotalSubtreeCost="0.00800216">
<OutputList />
<RunTimeInformation>
<RunTimeCountersPerThread Thread="1" ActualRows="8000" Batches="0" ActualEndOfScans="799" ActualExecutions="800" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
<RunTimeCountersPerThread Thread="0" ActualRows="0" Batches="0" ActualEndOfScans="0" ActualExecutions="0" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
</RunTimeInformation>
<ConstantScan />
</RelOp>
</NestedLoops>
</RelOp>
</Segment>
</RelOp>
</SequenceProject>
</RelOp>
</Top>
</RelOp>
</Parallelism>
</RelOp>
<Predicate>
<ScalarOperator ScalarString="[Expr1097]<=datalength(CASE WHEN datalength([@String1])>datalength([@String2]) THEN [@String2] ELSE [@String1] END) AND [Expr1097]>(1)">
<Logical Operation="AND">
<ScalarOperator>
<Compare CompareOp="LE">
<ScalarOperator>
<Identifier>
<ColumnReference Column="Expr1097" />
</Identifier>
</ScalarOperator>
<ScalarOperator>
<Intrinsic FunctionName="datalength">
<ScalarOperator>
<IF>
<Condition>
<ScalarOperator>
<Compare CompareOp="GT">
<ScalarOperator>
<Intrinsic FunctionName="datalength">
<ScalarOperator>
<Identifier>
<ColumnReference Column="@String1" />
</Identifier>
</ScalarOperator>
</Intrinsic>
</ScalarOperator>
<ScalarOperator>
<Intrinsic FunctionName="datalength">
<ScalarOperator>
<Identifier>
<ColumnReference Column="@String2" />
</Identifier>
</ScalarOperator>
</Intrinsic>
</ScalarOperator>
</Compare>
</ScalarOperator>
</Condition>
<Then>
<ScalarOperator>
<Identifier>
<ColumnReference Column="@String2" />
</Identifier>
</ScalarOperator>
</Then>
<Else>
<ScalarOperator>
<Identifier>
<ColumnReference Column="@String1" />
</Identifier>
</ScalarOperator>
</Else>
</IF>
</ScalarOperator>
</Intrinsic>
</ScalarOperator>
</Compare>
</ScalarOperator>
<ScalarOperator>
<Compare CompareOp="GT">
<ScalarOperator>
<Identifier>
<ColumnReference Column="Expr1097" />
</Identifier>
</ScalarOperator>
<ScalarOperator>
<Const ConstValue="(1)" />
</ScalarOperator>
</Compare>
</ScalarOperator>
</Logical>
</ScalarOperator>
</Predicate>
</Filter>
</RelOp>
<RelOp AvgRowSize="15" EstimateCPU="0.0015401" EstimateIO="0.01" EstimateRebinds="0" EstimateRewinds="1313.53" EstimatedExecutionMode="Row" EstimateRows="8000" LogicalOp="Lazy Spool" NodeId="18" Parallel="true" PhysicalOp="Table Spool" EstimatedTotalSubtreeCost="2.08199">
<OutputList>
<ColumnReference Column="Expr1050" />
</OutputList>
<RunTimeInformation>
<RunTimeCountersPerThread Thread="4" ActualRebinds="1" ActualRewinds="217" ActualRows="1744000" ActualRowsRead="1736000" Batches="0" ActualEndOfScans="218" ActualExecutions="218" ActualExecutionMode="Row" ActualElapsedms="1100" ActualCPUms="1100" ActualScans="1" ActualLogicalReads="21762" ActualPhysicalReads="0" ActualReadAheads="0" ActualLobLogicalReads="0" ActualLobPhysicalReads="0" ActualLobReadAheads="0" />
<RunTimeCountersPerThread Thread="3" ActualRebinds="1" ActualRewinds="217" ActualRows="1744000" ActualRowsRead="1736000" Batches="0" ActualEndOfScans="218" ActualExecutions="218" ActualExecutionMode="Row" ActualElapsedms="1137" ActualCPUms="1137" ActualScans="1" ActualLogicalReads="21762" ActualPhysicalReads="0" ActualReadAheads="0" ActualLobLogicalReads="0" ActualLobPhysicalReads="0" ActualLobReadAheads="0" />
<RunTimeCountersPerThread Thread="2" ActualRebinds="1" ActualRewinds="218" ActualRows="1752000" ActualRowsRead="1744000" Batches="0" ActualEndOfScans="219" ActualExecutions="219" ActualExecutionMode="Row" ActualElapsedms="1179" ActualCPUms="1159" ActualScans="1" ActualLogicalReads="21788" ActualPhysicalReads="0" ActualReadAheads="0" ActualLobLogicalReads="0" ActualLobPhysicalReads="0" ActualLobReadAheads="0" />
<RunTimeCountersPerThread Thread="1" ActualRebinds="1" ActualRewinds="217" ActualRows="1744000" ActualRowsRead="1736000" Batches="0" ActualEndOfScans="218" ActualExecutions="218" ActualExecutionMode="Row" ActualElapsedms="1201" ActualCPUms="1201" ActualScans="1" ActualLogicalReads="21762" ActualPhysicalReads="0" ActualReadAheads="0" ActualLobLogicalReads="0" ActualLobPhysicalReads="0" ActualLobReadAheads="0" />
<RunTimeCountersPerThread Thread="0" ActualRebinds="0" ActualRewinds="0" ActualRows="0" Batches="0" ActualEndOfScans="0" ActualExecutions="0" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" ActualScans="0" ActualLogicalReads="0" ActualPhysicalReads="0" ActualReadAheads="0" ActualLobLogicalReads="0" ActualLobPhysicalReads="0" ActualLobReadAheads="0" />
</RunTimeInformation>
<Spool>
<RelOp AvgRowSize="15" EstimateCPU="0.0008" EstimateIO="0" EstimateRebinds="0" EstimateRewinds="0" EstimatedExecutionMode="Row" EstimateRows="8000" LogicalOp="Top" NodeId="19" Parallel="true" PhysicalOp="Top" EstimatedTotalSubtreeCost="0.0476092">
<OutputList>
<ColumnReference Column="Expr1050" />
</OutputList>
<RunTimeInformation>
<RunTimeCountersPerThread Thread="4" ActualRows="8000" Batches="0" ActualEndOfScans="1" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="6" ActualCPUms="6" />
<RunTimeCountersPerThread Thread="3" ActualRows="8000" Batches="0" ActualEndOfScans="1" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="6" ActualCPUms="6" />
<RunTimeCountersPerThread Thread="2" ActualRows="8000" Batches="0" ActualEndOfScans="1" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="5" ActualCPUms="5" />
<RunTimeCountersPerThread Thread="1" ActualRows="8000" Batches="0" ActualEndOfScans="1" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="6" ActualCPUms="6" />
<RunTimeCountersPerThread Thread="0" ActualRows="0" Batches="0" ActualEndOfScans="0" ActualExecutions="0" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
</RunTimeInformation>
<Top RowCount="false" IsPercent="false" WithTies="false">
<TopExpression>
<ScalarOperator ScalarString="(8000)">
<Const ConstValue="(8000)" />
</ScalarOperator>
</TopExpression>
<RelOp AvgRowSize="15" EstimateCPU="0.0008" EstimateIO="0" EstimateRebinds="0" EstimateRewinds="0" EstimatedExecutionMode="Row" EstimateRows="8000" LogicalOp="Compute Scalar" NodeId="20" Parallel="true" PhysicalOp="Sequence Project" EstimatedTotalSubtreeCost="0.0468092">
<OutputList>
<ColumnReference Column="Expr1050" />
</OutputList>
<RunTimeInformation>
<RunTimeCountersPerThread Thread="4" ActualRows="8000" Batches="0" ActualEndOfScans="0" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="5" ActualCPUms="5" />
<RunTimeCountersPerThread Thread="3" ActualRows="8000" Batches="0" ActualEndOfScans="0" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="5" ActualCPUms="5" />
<RunTimeCountersPerThread Thread="2" ActualRows="8000" Batches="0" ActualEndOfScans="0" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="4" ActualCPUms="4" />
<RunTimeCountersPerThread Thread="1" ActualRows="8000" Batches="0" ActualEndOfScans="0" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="4" ActualCPUms="4" />
<RunTimeCountersPerThread Thread="0" ActualRows="0" Batches="0" ActualEndOfScans="0" ActualExecutions="0" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
</RunTimeInformation>
<SequenceProject>
<DefinedValues>
<DefinedValue>
<ColumnReference Column="Expr1050" />
<ScalarOperator ScalarString="row_number">
<Sequence FunctionName="row_number" />
</ScalarOperator>
</DefinedValue>
</DefinedValues>
<RelOp AvgRowSize="15" EstimateCPU="0.0002" EstimateIO="0" EstimateRebinds="0" EstimateRewinds="0" EstimatedExecutionMode="Row" EstimateRows="8000" LogicalOp="Segment" NodeId="21" Parallel="true" PhysicalOp="Segment" EstimatedTotalSubtreeCost="0.0461692">
<OutputList>
<ColumnReference Column="Segment1101" />
</OutputList>
<RunTimeInformation>
<RunTimeCountersPerThread Thread="4" ActualRows="8000" Batches="0" ActualEndOfScans="0" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="3" ActualCPUms="3" />
<RunTimeCountersPerThread Thread="3" ActualRows="8000" Batches="0" ActualEndOfScans="0" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="3" ActualCPUms="3" />
<RunTimeCountersPerThread Thread="2" ActualRows="8000" Batches="0" ActualEndOfScans="0" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="2" ActualCPUms="2" />
<RunTimeCountersPerThread Thread="1" ActualRows="8000" Batches="0" ActualEndOfScans="0" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="2" ActualCPUms="2" />
<RunTimeCountersPerThread Thread="0" ActualRows="0" Batches="0" ActualEndOfScans="0" ActualExecutions="0" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
</RunTimeInformation>
<Segment>
<GroupBy />
<SegmentColumn>
<ColumnReference Column="Segment1101" />
</SegmentColumn>
<RelOp AvgRowSize="9" EstimateCPU="0.0418" EstimateIO="0" EstimateRebinds="0" EstimateRewinds="0" EstimatedExecutionMode="Row" EstimateRows="8000" LogicalOp="Inner Join" NodeId="22" Parallel="true" PhysicalOp="Nested Loops" EstimatedTotalSubtreeCost="0.0460092">
<OutputList />
<Warnings NoJoinPredicate="true" />
<RunTimeInformation>
<RunTimeCountersPerThread Thread="4" ActualRows="8000" Batches="0" ActualEndOfScans="0" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="1" ActualCPUms="1" />
<RunTimeCountersPerThread Thread="3" ActualRows="8000" Batches="0" ActualEndOfScans="0" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="2" ActualCPUms="2" />
<RunTimeCountersPerThread Thread="2" ActualRows="8000" Batches="0" ActualEndOfScans="0" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="1" ActualCPUms="1" />
<RunTimeCountersPerThread Thread="1" ActualRows="8000" Batches="0" ActualEndOfScans="0" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="1" ActualCPUms="1" />
<RunTimeCountersPerThread Thread="0" ActualRows="0" Batches="0" ActualEndOfScans="0" ActualExecutions="0" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
</RunTimeInformation>
<NestedLoops Optimized="false">
<RelOp AvgRowSize="9" EstimateCPU="0.00418" EstimateIO="0" EstimateRebinds="0" EstimateRewinds="0" EstimatedExecutionMode="Row" EstimateRows="800" LogicalOp="Inner Join" NodeId="23" Parallel="true" PhysicalOp="Nested Loops" EstimatedTotalSubtreeCost="0.004568">
<OutputList />
<Warnings NoJoinPredicate="true" />
<RunTimeInformation>
<RunTimeCountersPerThread Thread="4" ActualRows="800" Batches="0" ActualEndOfScans="0" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
<RunTimeCountersPerThread Thread="3" ActualRows="800" Batches="0" ActualEndOfScans="0" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
<RunTimeCountersPerThread Thread="2" ActualRows="800" Batches="0" ActualEndOfScans="0" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
<RunTimeCountersPerThread Thread="1" ActualRows="800" Batches="0" ActualEndOfScans="0" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
<RunTimeCountersPerThread Thread="0" ActualRows="0" Batches="0" ActualEndOfScans="0" ActualExecutions="0" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
</RunTimeInformation>
<NestedLoops Optimized="false">
<RelOp AvgRowSize="9" EstimateCPU="0.000418" EstimateIO="0" EstimateRebinds="0" EstimateRewinds="0" EstimatedExecutionMode="Row" EstimateRows="80" LogicalOp="Inner Join" NodeId="24" Parallel="true" PhysicalOp="Nested Loops" EstimatedTotalSubtreeCost="0.000422896">
<OutputList />
<Warnings NoJoinPredicate="true" />
<RunTimeInformation>
<RunTimeCountersPerThread Thread="4" ActualRows="80" Batches="0" ActualEndOfScans="0" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
<RunTimeCountersPerThread Thread="3" ActualRows="80" Batches="0" ActualEndOfScans="0" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
<RunTimeCountersPerThread Thread="2" ActualRows="80" Batches="0" ActualEndOfScans="0" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
<RunTimeCountersPerThread Thread="1" ActualRows="80" Batches="0" ActualEndOfScans="0" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
<RunTimeCountersPerThread Thread="0" ActualRows="0" Batches="0" ActualEndOfScans="0" ActualExecutions="0" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
</RunTimeInformation>
<NestedLoops Optimized="false">
<RelOp AvgRowSize="9" EstimateCPU="1.0157E-05" EstimateIO="0" EstimateRebinds="0" EstimateRewinds="0" EstimatedExecutionMode="Row" EstimateRows="8" LogicalOp="Constant Scan" NodeId="25" Parallel="true" PhysicalOp="Constant Scan" EstimatedTotalSubtreeCost="8.157E-06">
<OutputList />
<RunTimeInformation>
<RunTimeCountersPerThread Thread="4" ActualRows="8" Batches="0" ActualEndOfScans="0" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
<RunTimeCountersPerThread Thread="3" ActualRows="8" Batches="0" ActualEndOfScans="0" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
<RunTimeCountersPerThread Thread="2" ActualRows="8" Batches="0" ActualEndOfScans="0" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
<RunTimeCountersPerThread Thread="1" ActualRows="8" Batches="0" ActualEndOfScans="0" ActualExecutions="1" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
<RunTimeCountersPerThread Thread="0" ActualRows="0" Batches="0" ActualEndOfScans="0" ActualExecutions="0" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
</RunTimeInformation>
<ConstantScan />
</RelOp>
<RelOp AvgRowSize="9" EstimateCPU="1.0157E-05" EstimateIO="0" EstimateRebinds="0" EstimateRewinds="7.2" EstimatedExecutionMode="Row" EstimateRows="10" LogicalOp="Constant Scan" NodeId="26" Parallel="true" PhysicalOp="Constant Scan" EstimatedTotalSubtreeCost="8.2157E-05">
<OutputList />
<RunTimeInformation>
<RunTimeCountersPerThread Thread="4" ActualRows="80" Batches="0" ActualEndOfScans="7" ActualExecutions="8" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
<RunTimeCountersPerThread Thread="3" ActualRows="80" Batches="0" ActualEndOfScans="7" ActualExecutions="8" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
<RunTimeCountersPerThread Thread="2" ActualRows="80" Batches="0" ActualEndOfScans="7" ActualExecutions="8" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
<RunTimeCountersPerThread Thread="1" ActualRows="80" Batches="0" ActualEndOfScans="7" ActualExecutions="8" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
<RunTimeCountersPerThread Thread="0" ActualRows="0" Batches="0" ActualEndOfScans="0" ActualExecutions="0" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
</RunTimeInformation>
<ConstantScan />
</RelOp>
</NestedLoops>
</RelOp>
<RelOp AvgRowSize="9" EstimateCPU="1.0157E-05" EstimateIO="0" EstimateRebinds="0" EstimateRewinds="79.2" EstimatedExecutionMode="Row" EstimateRows="10" LogicalOp="Constant Scan" NodeId="27" Parallel="true" PhysicalOp="Constant Scan" EstimatedTotalSubtreeCost="0.000802157">
<OutputList />
<RunTimeInformation>
<RunTimeCountersPerThread Thread="4" ActualRows="800" Batches="0" ActualEndOfScans="79" ActualExecutions="80" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
<RunTimeCountersPerThread Thread="3" ActualRows="800" Batches="0" ActualEndOfScans="79" ActualExecutions="80" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
<RunTimeCountersPerThread Thread="2" ActualRows="800" Batches="0" ActualEndOfScans="79" ActualExecutions="80" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
<RunTimeCountersPerThread Thread="1" ActualRows="800" Batches="0" ActualEndOfScans="79" ActualExecutions="80" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
<RunTimeCountersPerThread Thread="0" ActualRows="0" Batches="0" ActualEndOfScans="0" ActualExecutions="0" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
</RunTimeInformation>
<ConstantScan />
</RelOp>
</NestedLoops>
</RelOp>
<RelOp AvgRowSize="9" EstimateCPU="1.0157E-05" EstimateIO="0" EstimateRebinds="0" EstimateRewinds="799.2" EstimatedExecutionMode="Row" EstimateRows="10" LogicalOp="Constant Scan" NodeId="28" Parallel="true" PhysicalOp="Constant Scan" EstimatedTotalSubtreeCost="0.00800216">
<OutputList />
<RunTimeInformation>
<RunTimeCountersPerThread Thread="4" ActualRows="8000" Batches="0" ActualEndOfScans="799" ActualExecutions="800" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
<RunTimeCountersPerThread Thread="3" ActualRows="8000" Batches="0" ActualEndOfScans="799" ActualExecutions="800" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
<RunTimeCountersPerThread Thread="2" ActualRows="8000" Batches="0" ActualEndOfScans="799" ActualExecutions="800" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
<RunTimeCountersPerThread Thread="1" ActualRows="8000" Batches="0" ActualEndOfScans="799" ActualExecutions="800" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
<RunTimeCountersPerThread Thread="0" ActualRows="0" Batches="0" ActualEndOfScans="0" ActualExecutions="0" ActualExecutionMode="Row" ActualElapsedms="0" ActualCPUms="0" />
</RunTimeInformation>
<ConstantScan />
</RelOp>
</NestedLoops>
</RelOp>
</Segment>
</RelOp>
</SequenceProject>
</RelOp>
</Top>
</RelOp>
</Spool>
</RelOp>
</NestedLoops>
</RelOp>
</ComputeScalar>
</RelOp>
</Sort>
</RelOp>
</Parallelism>
</RelOp>
</Top>
</RelOp>
</ComputeScalar>
</RelOp>
<ParameterList>
<ColumnReference Column="@String2" ParameterDataType="varchar(8000)" ParameterRuntimeValue="'At first Copland sought for Americanism in the influence of jazz—"jazz" as he had played it (see letter from Copland to Nadia Boulanger, August 1924) as part of a hotel orchestra in the summer of 1924. The Concerto for Piano and Orchestra, the Music for th'" />
<ColumnReference Column="@String1" ParameterDataType="varchar(8000)" ParameterRuntimeValue="'When Aaron Copland boarded a ship for Paris in June 1921, a few months short of his twenty-first birthday, he already had a good musical training thanks to his conservative but thorough American teacher, Rubin Goldmark. He carried in his luggage the manusc'" />
</ParameterList>
</QueryPlan>
</StmtSimple>
</Statements>
</Batch>
</BatchSequence>
</ShowPlanXML>Steve (aka sgmunson) 🙂 🙂 🙂
Rent Servers for Income (picks and shovels strategy) -
What you posted is similar to my first version of this except that I use my ngrams function to generate the tally table. Here's a simplified version of what you posted followed a slightly modified version which gets rid of the sort.
DECLARE
@S1 VARCHAR(8000) = '???-ABC123XYZ...!!!',
@S2 VARCHAR(8000) = '!!!???ABC123XYZ----------------';
SELECT TOP(1)
L1 = b.L1, -- Shorter String
L2 = b.L2, -- Equal or longer len than L1
ItemLength = t.N,
S1_Index = ng.Position,
S2_Index = s2.Idx,
Item = SUBSTRING(b.S1,ng.Position,t.N)
FROM dbo.bernie8K(@S1,@S2) AS b
CROSS APPLY dbo.fnTally(1,b.L1) AS t
CROSS APPLY dbo.ngrams8k(b.S1,t.N) AS ng
CROSS APPLY (VALUES(CHARINDEX(ng.Token,b.S2))) AS s2(Idx)
WHERE s2.Idx > 0 -- same logic as S.LONGER_STRING LIKE '%'+SS.SUB_STRING_SHORT+'%'
ORDER BY t.N DESC;
SELECT TOP(1)
L1 = b.L1, -- Shorter String
L2 = b.L2, -- Equal or longer len than L1
ItemLength = n.Op, -- How we get a descending sort
S1_Index = ng.Position, -- Where the longest matching string is in S1
S2_Index = s2.Idx, -- Where the longest matching string is in S2
Item = SUBSTRING(b.S1,ng.Position,t.N)
FROM dbo.bernie8K(@S1,@S2) AS b
CROSS APPLY dbo.fnTally(1,b.L1) AS t
CROSS APPLY (VALUES(b.L1+1-t.N)) AS n(Op) -- Jeff's Max+@ZeroOrOne-N formula
CROSS APPLY dbo.ngrams8k(b.S1,N.Op) AS ng
CROSS APPLY (VALUES(CHARINDEX(ng.Token,b.S2))) AS s2(Idx)
WHERE s2.Idx > 0
ORDER BY t.N;I'll expand on this tomorrow. Cheers.
"I cant stress enough the importance of switching from a sequential files mindset to set-based thinking. After you make the switch, you can spend your time tuning and optimizing your queries instead of maintaining lengthy, poor-performing code."-- Itzik Ben-Gan 2001
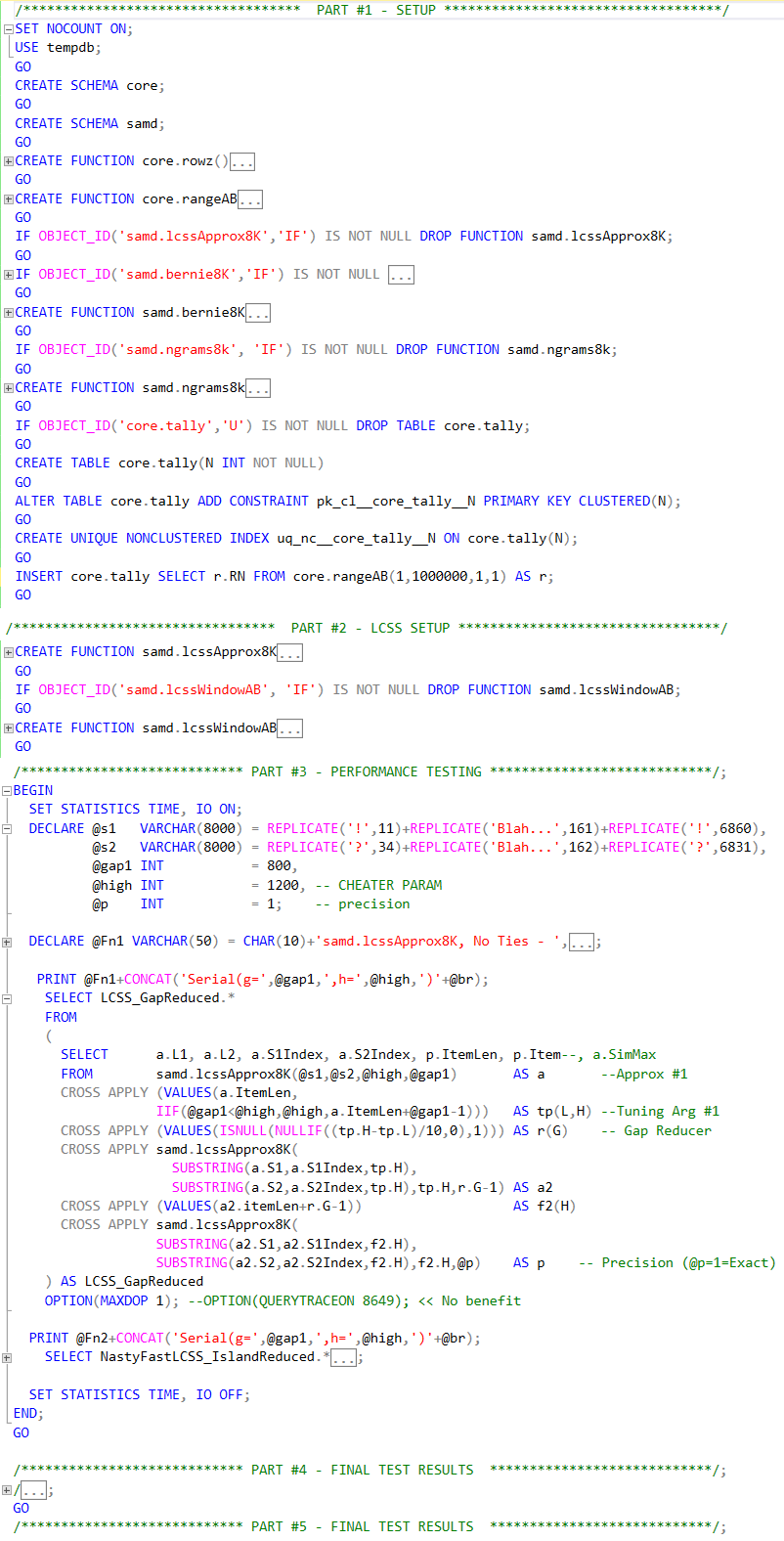
Viewing 13 posts - 1 through 13 (of 13 total)
You must be logged in to reply to this topic. Login to reply