Iterative query to sum a colum relating to dates.
-
Hi,
I have a simple table with 5 columns as follows with about 80,000 rows, I wish to sum the Hours for each Client at 2 week intervals.
In other words starting at a particular EndDate, sum the Hours for each client for 2 week period.
ID, ClientID, EndDate, Hours
1 , 1234, 01/7/24, 10
2, 1234, 07/7/24, 5
3, 2222, 01/7/24, 4
4, 2222, 07/7/24, 6
5, 1234, 14/7/24, 12
6, 1234, 21/7/24, 2
Result
ClientID, EndDate, Hours
1234, 7/7/24, 15
2222, 7/7/24, 10
1234, 21/7/24, 14
I am not sure the best way to start, to either use a loop, which I was told was not the best way in sql or extract the 2nd date and sum where EndDate and the EndDate 1 week before matches for each client.
I am open to suggestions and I am sure there maybe an even simpler/smarter way of doing it without iterating?
-
one way is to use a Calendar table (which could be overkill) so you know which weeks go together.
DATEPART(week,[date Column])
will give you the week of the year, and since it returns an integer, you can use integer division to create even bins
SELECT DATEPART(week,GETDATE())/2
It'll round down the closest integer. Then group by that.
-
No directly usable sample data, so I can't test it, but maybe this:
DECLARE @first_week_ending_date date;
SET @first_week_ending_date = '20240707';
SELECT
ClientID,
DATEADD(DAY, @first_week_ending_date, CASE WHEN EndDate > @first_week_ending_date
THEN 14 ELSE 0 END) AS EndDate,
SUM(Hours) AS Hours
FROM dbo.your_table
WHERE EndDate >= DATEADD(DAY, -13, @first_week_ending_date) AND EndDate <= DATEADD(DAY, 14, @first_week_ending_date)
GROUP BY ClientID, DATEADD(DAY, @first_week_ending_date, CASE WHEN EndDate > @first_week_ending_date
THEN 14 ELSE 0 END)SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
So I tried this suggestion and it worked perfectly, except for the first row for each Client which is one less than the row above skewing all the data.
I tired different starting dates to see if I can sort it out but it didn't work!
See below, any ideas?
ClientID, EndDate, NewWk, Hours
22001672 2022-07-10 14 17.75
22001672 2022-07-17 15 21.25
22001672 2022-07-24 15 8.25
22001672 2022-07-31 16 22.25
22001672 2022-08-07 16 7.00 5
-
Hi Scott,
My mistake I didnt explain it has to run for all months and years after the July too!
I tired you query and it works (had to rearrange the dateadd params), but works but only for the month of July does not continue for the rest of the months!
That why iteration seems to be the answer.
Any suggestions !
-
I have developed Scotts query using a loop but still not getting the resutls I need. I have supplied better data for testing below...
CREATE TABLE Client( ID int, ClienID int, EndDate Date, Hours int);
INSERT INTO Client
VALUES
(1, 1234, 07/7/24, 10),
(2, 1234, 14/7/24, 5),
(3, 2222, 07/7/24, 4),
(4, 2222, 14/7/24, 6),
(5, 1234, 12/7/24, 12),
(6, 1234, 28/7/24, 2),
(7, 2222, 21/7/24, 4),
(8, 2222, 28/7/24, 4),
(9, 1234, 04/8/24, 9),
(10, 1234, 11/8/24, 2)
(11, 2222, 04/8/24, 6),
(12, 2222, 11/8/24, 7)
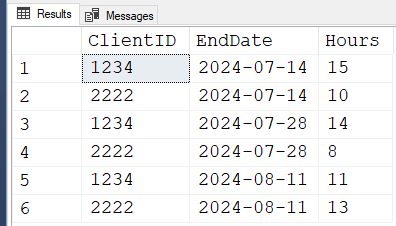
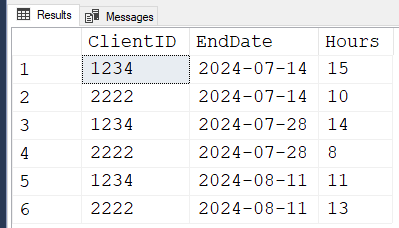
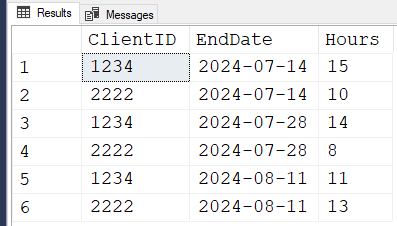
RESULTS
ClientID, EndDAte, HOurs
1234, 14/7/24, 15
2222, 14/7/24, 10
1234, 28/7/24, 14
2222, 28/7/24, 8
1234, 11/8/24, 11
2222, 11/8/24, 13
SET @first_week_ending_date = '2022-07-17';
While @first_week_ending_date <'2024-10-15'
BEGIN
INSERT INTO SampleTable (ClientID, EndDate, Hours)
SELECT ClientID,
DATEADD(DAY, CASE WHEN EndDate > @first_week_ending_date THEN 14 ELSE 0 END, @first_week_ending_date) AS EndDate, SUM(Hours) AS Hours
FROM MyTable
WHERE EndDate >= DATEADD(DAY, -13, @first_week_ending_date) --AND Weekending <= DATEADD(DAY, 14, @first_week_ending_date)
GROUP BY ClientID, EndDate,
DATEADD(DAY, CASE WHEN [EndDate] > @first_week_ending_date THEN 14 ELSE 0 END, @first_week_ending_date)
SET @first_week_ending_date = DATEADD(DAY, 14, @first_week_ending_date)
END
SELECT * FROM SampleTable
ORDER BY ClientID, EndDate
-
Sorry... made a mistake... will repost in, hopefully, a couple of minutes.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Sorry... made a mistake... will repost in, hopefully, a couple of minutes.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
It turns out that I simply misread the dd/mm/yyyy format of the expected answer and the original code that I posted was just fine. Here's that post again...
Apparently, you didn't actually try the creation of data script that you posted. 😉
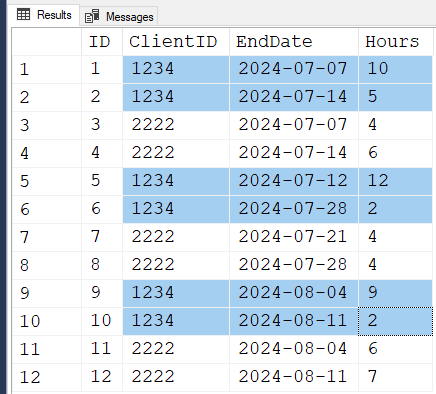
Here's one that works. I used a Temp Table to prevent any accidents on a real table.
SET DATEFORMAT DMY;
--DROP TABLE IF EXISTS #Client; --Uncomment to make reruns easier.
GO
CREATE TABLE #Client( ID int, ClientID int, EndDate Date, Hours int);
INSERT INTO #Client WITH (TABLOCK)
VALUES ( 1, 1234, '07/7/24', 10)
,( 2, 1234, '14/7/24', 5)
,( 3, 2222, '07/7/24', 4)
,( 4, 2222, '14/7/24', 6)
,( 5, 1234, '12/7/24', 12)
,( 6, 1234, '28/7/24', 2)
,( 7, 2222, '21/7/24', 4)
,( 8, 2222, '28/7/24', 4)
,( 9, 1234, '04/8/24', 9)
,(10, 1234, '11/8/24', 2)
,(11, 2222, '04/8/24', 6)
,(12, 2222, '11/8/24', 7)
;The following code uses the "Difference between sequential numbers to form group numbers" trick that Itzik Ben-gan posted an article about long ago. Notice that I don't trust the ID column because there's no guarantee that it will always be sequential.
WITH
cteCreateGroups AS
(
SELECT Grp = ROW_NUMBER() OVER (ORDER BY ID) --In case ID is not sequential
- ROW_NUMBER() OVER (PARTITION BY ClientID ORDER BY ID)
,*
FROM #Client
)
SELECT ClientID
,EndDate = MAX(EndDate)
,Hours = SUM(Hours)
FROM cteCreateGroups
GROUP BY Grp, ClientID
ORDER BY EndDate,ClientID
;Here are the results:

--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Thanks Jeff, that worked well.
Can I ask you to explain how it works, as reading it does nto make a lot of sense.
Kind regards.
- Tallboy wrote:
Thanks Jeff, that worked well.
Can I ask you to explain how it works, as reading it does nto make a lot of sense.
Kind regards.
Sure...
If we look at the original data...
SELECT *
FROM #Client
ORDER BY ID
;We see groups of rows that you'd already sorted by two week periods by client. Your request boiled down to returning the ClientID, the MAX EndDate, and the SUM of the hours for each 2 week group. The trick is to identify some Group Numbers (Grp) so that we can do the aggregations for each Grp for each ClientID.
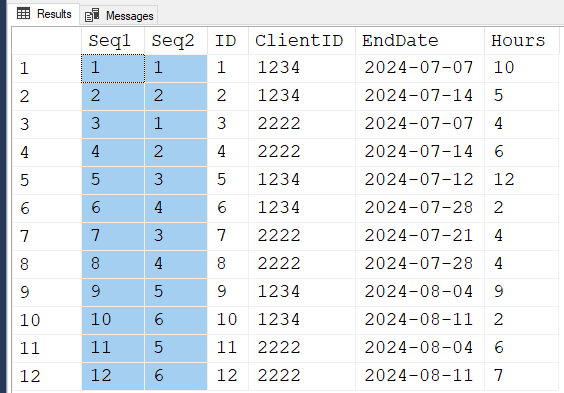
To start with, we need a sequence of numbers to guarantee the order. You have that in the ID column but there's no guarantee that the ID column has no missing values and so we need to make a new sequence that guarantees a perfect sequence. We'll call that "Seq1" in the following code.
Then, we need a perfect sequence that will restart at 1 for each ClientID. We'll call that "Seq2" in the code. Notice that it's "partitioned" by the ClientID and ordered by the original ID.
Here's the code so far, followed by the results.
SELECT Seq1 = ROW_NUMBER() OVER (ORDER BY ID) --In case ID is not sequential
,Seq2 = ROW_NUMBER() OVER (PARTITION BY ClientID ORDER BY ID)
,*
FROM #Client
ORDER BY Seq1
;OMG! That looks horrible! What in grand tarnation are we going to do with that?
The answer is that we have two sequences now. 1 that starts at 1 and continues to increment for all the rows (Seq1). Although it's hard to tell, the other sequence (Seq2) is also an ever increasing number but it starts at 1 for each ClientID.
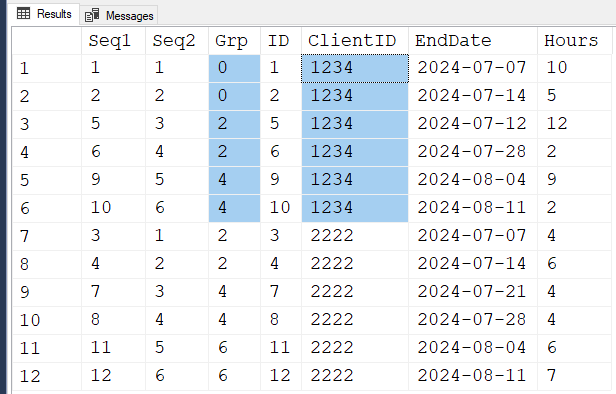
Guess what happens when you subtract Seq2 from Seq1 because they're both incrementing by 1 and Seq2 starts at 1 for each ClientID? You get unique GROUP numbers for each group for each ClientID.
Here's the result sorted so that you can see how the subtraction of Seq1-Seq2 formed the "Grp" numbers for each ClientID. (I used the original formula for the long ROW_NUMBER() form for each of the 2 sequences). Notice that ClientID 1234 has Grp's of 0, 2, and 4 and ClientID has it's own groups of 2, 4, and 6. That's perfect for a GROUP BY Grp and ClientID for our MAX(EndDate) and our SUM(Hours). And, take a look at how the two increasing sequences work out a group number by subtracting Seq2 from Seq1, which are both ever increasing and create the same group numbers for the pairs of weeks.
SELECT Seq1 = ROW_NUMBER() OVER (ORDER BY ID) --In case ID is not sequential
,Seq2 = ROW_NUMBER() OVER (PARTITION BY ClientID ORDER BY ID)
,Grp = ROW_NUMBER() OVER (ORDER BY ID)
- ROW_NUMBER() OVER (PARTITION BY ClientID ORDER BY ID)
,*
FROM #Client
ORDER BY ClientID,GRP
;And that's how grouping by taking the difference between two sequences works.
If we just keep the Grp column, dust the Seq1 and Seq2 columns, put it all in a CTE and then do the right kind of GROUP BY on the cte, we ended up with our final answer.
WITH
cteCreateGroups AS
(
SELECT Grp = ROW_NUMBER() OVER (ORDER BY ID) --In case ID is not sequential
- ROW_NUMBER() OVER (PARTITION BY ClientID ORDER BY ID)
,*
FROM #Client
)
SELECT ClientID
,EndDate = MAX(EndDate)
,Hours = SUM(Hours)
FROM cteCreateGroups
GROUP BY Grp, ClientID
ORDER BY EndDate,ClientID
;I didn't come up with this idea. Itzik Ben-Gan used to have challenges on SQLMag.com, which no longer exists, and someone came up with the method for a challenge. They moved all his stuff over to ItPro and that didn't map any of the original URLs. I gave up looking for the original article I got this technique from.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Here's another method. I got this idea for Piet Linden's post above. We could work on the dates as he suggested because your latest data has overlapping date ranges but the integer math worked fine. I haven't tried it with more than 2 ClientIDs. I'll leave that bit of testing to you. The first method above is good for 1 to many different weeks for 1 to many clients as long as you have the ID in the order that you want them to be processed/grouped in.
--===== This works if the order of the original data is
-- guaranteed and there are always 2 dates per group.
WITH cteCreateGroups AS
(
SELECT *,Grp = (ROW_NUMBER() OVER (ORDER BY ID)-1)/2
FROM #Client
)
SELECT ClientID
,EndDate = MAX(EndDate)
,Hours = SUM(Hours)
FROM cteCreateGroups
GROUP BY Grp, ClientID
ORDER BY EndDate,ClientID
;Results:
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)
Viewing 12 posts - 1 through 12 (of 12 total)
You must be logged in to reply to this topic. Login to reply